作者:Irain
QQ:2573396010
微信:18802080892
手写体数字识别
- 1 下载数据包
- 2 解压数据包
- 3 打开代码文件
- 4 图片转为文本代码
- 5 训练数据
- 6 抽某一个文件进行测试
- 7 测试数据
1 下载数据包
GitHub链接(速度慢):k近邻(knn)算法之手写体数字识别
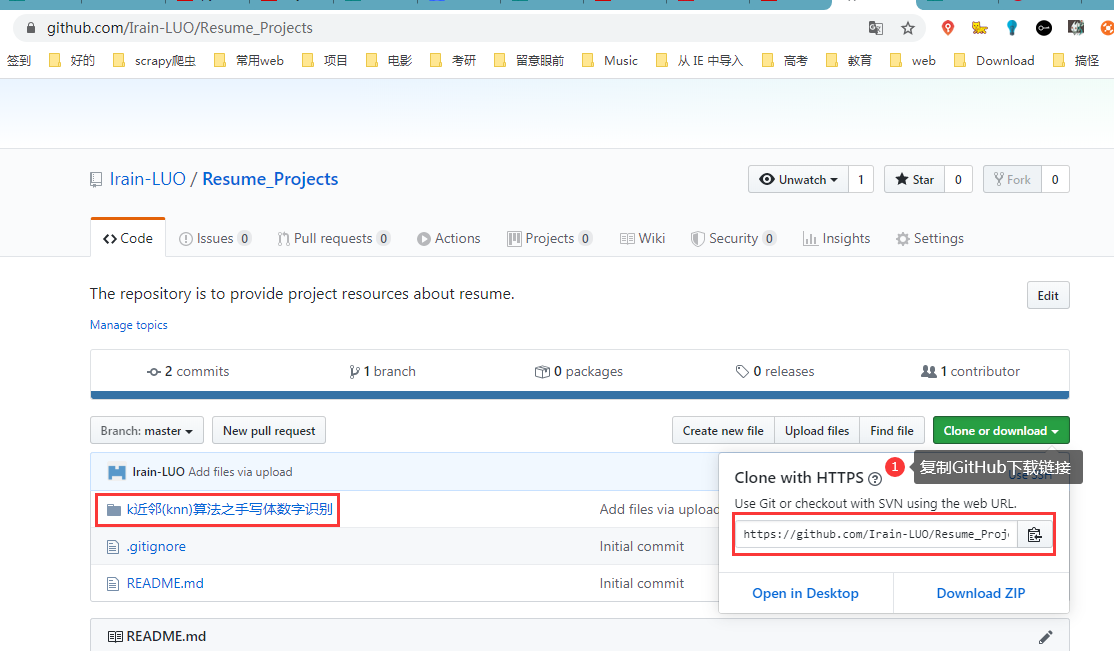

码云链接(速度快):k近邻(knn)算法之手写体数字识别
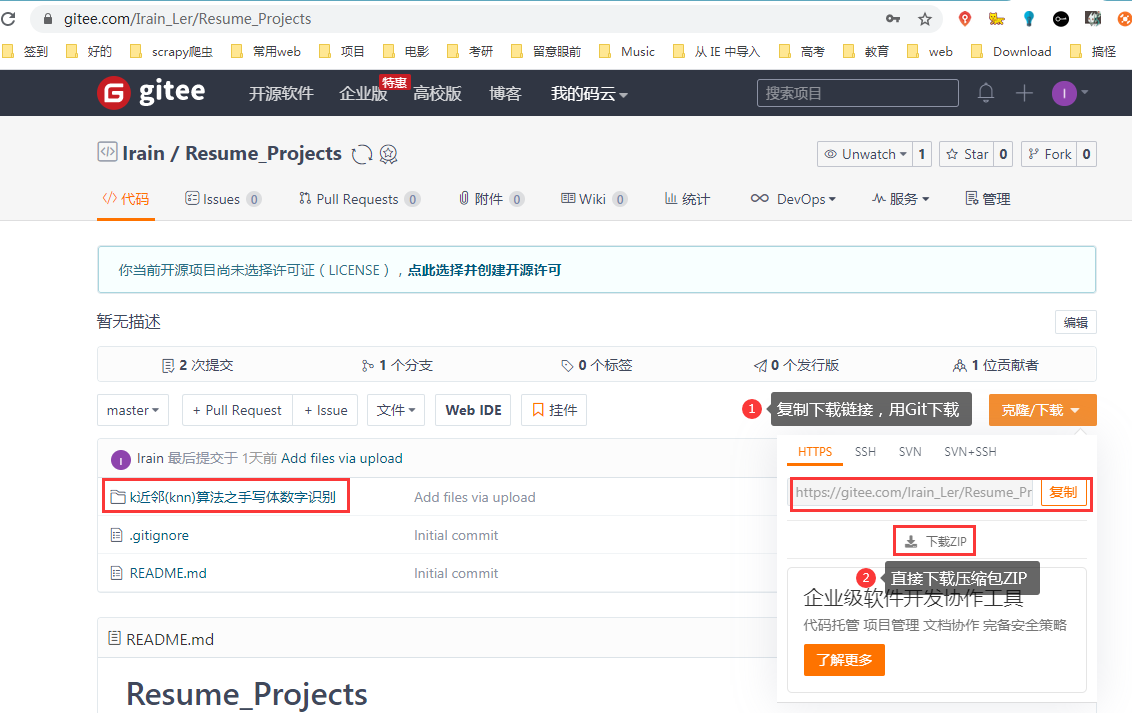
2 解压数据包
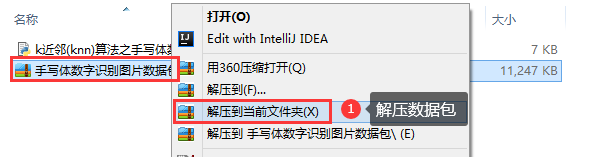
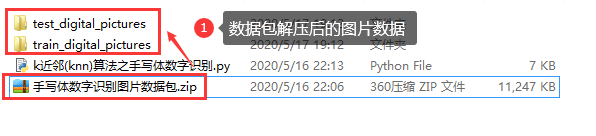
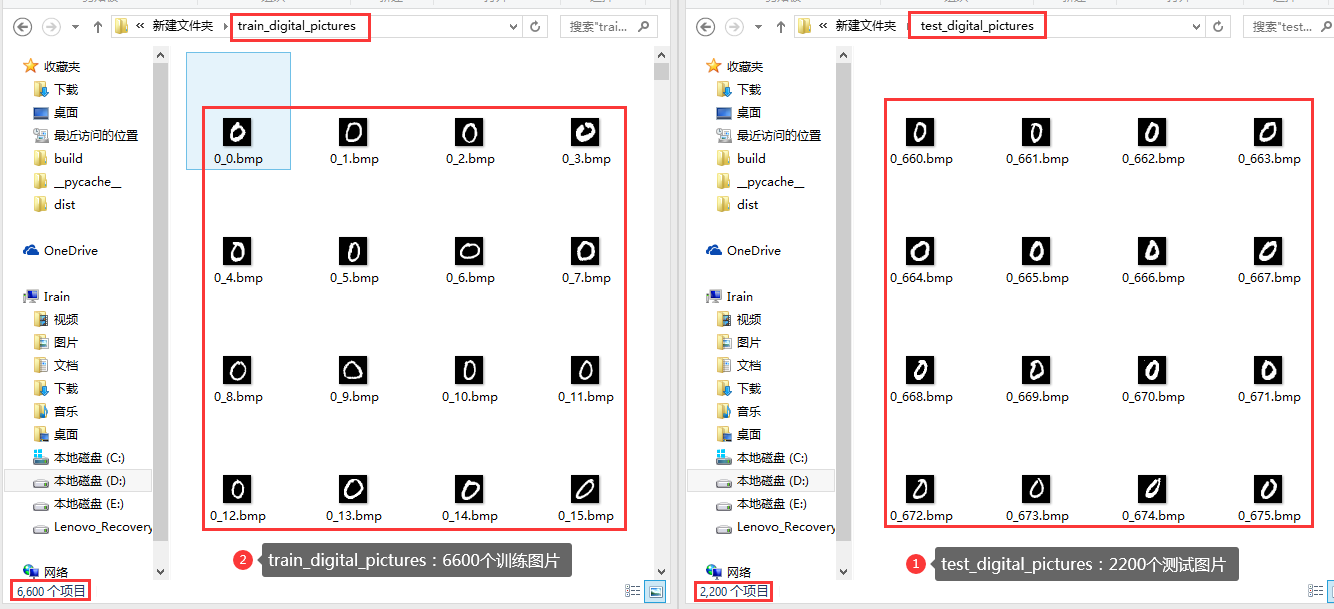
3 打开代码文件
4 图片转为文本代码

import os
from PIL import Image
def pictureTotxt(data_name):
'''
处理bmp图片转为txt文本
Args:
data_name: 数据类型名称
Return: None
'''
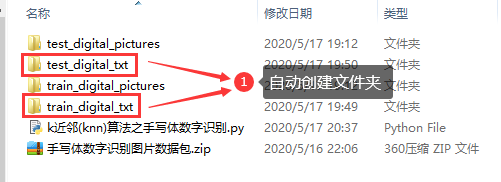
if not os.path.exists("%s_digital_txt" %(data_name)): # 创建txt文本文件夹
os.mkdir("%s_digital_txt" %(data_name))
lists = os.listdir("%s_digital_pictures" %(data_name)) # 获取所有手写体图片名称
for list in lists: # 图片转换文本
im = Image.open("%s_digital_pictures/%s" % (data_name,list)) # 打开手写体图片
fh = open("%s_digital_txt/%s.txt" % (data_name,list.split(".")[0]),"a") # 打开txt文本
width = im.size[0] # 图片宽
height = im.size[1] # 图片高
for k in range(0,width): # 存入txt文本
for j in range(0,height):
cl = im.getpixel((k,j)) # bmp图片的像素只有一个数
if(cl == 0): # 0:黑色
fh.write("0") # 黑色为0
else:
fh.write("1") # 白色为1
fh.write("n")
fh.close() # 关闭文件
5 训练数据

def datatoarray(fname):
'''
加载txt文本数据
Args:
fname: 文本名称
Return: None
'''
arr = []
fh = open(fname) # 打开txt文本
for i in range(0,28):
thisline = fh.readline() # 读取文本内容
for j in range(0,28):
arr.append(int(thisline[j]))
fh.close()
return arr
def seplabel(fname):
'''
获取文本类别
Args:
fname: 文本名称、名称格式例子:0_0.txt
Return: None
'''
filestr = fname.split(".")[0]
label = int(filestr.split("_")[0])
return label
def traindata():
'''
建立训练数据
Return: None
'''
labels = []
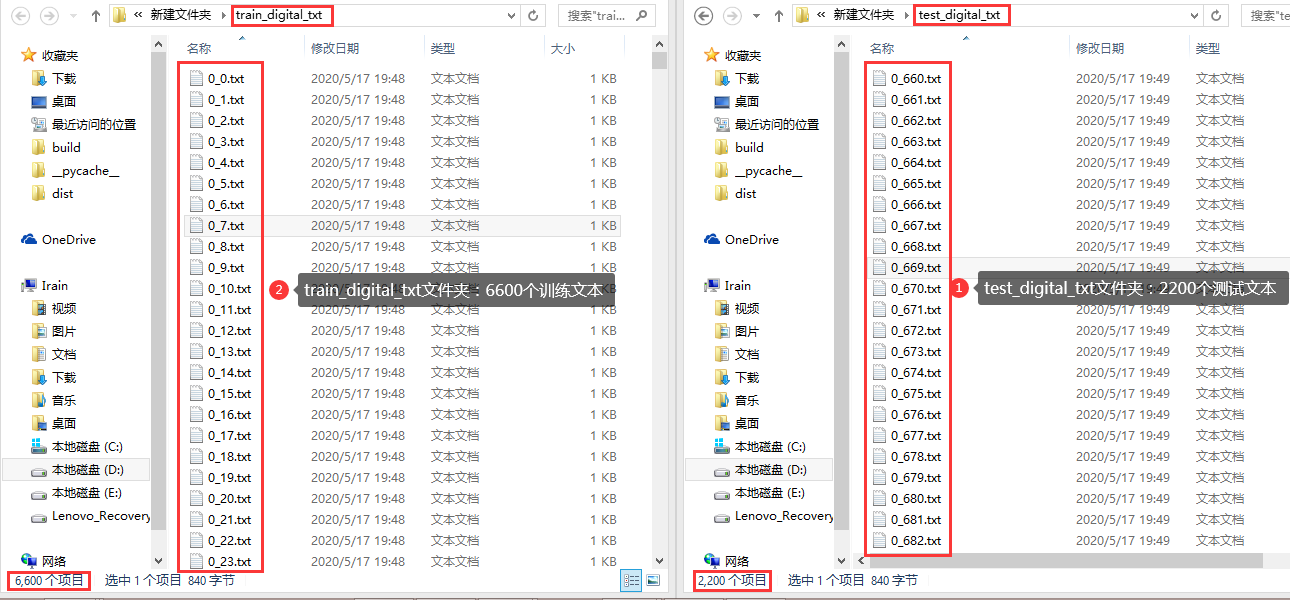
trainfile = os.listdir("train_digital_txt/") # 获取手写体图片名
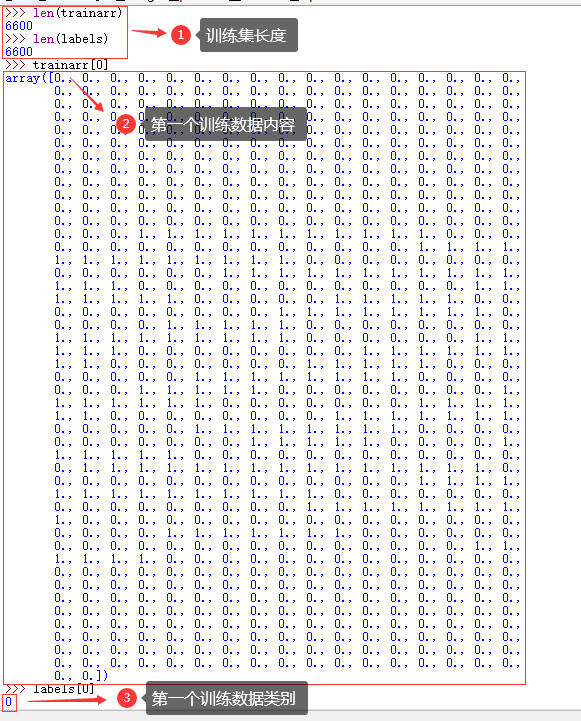
num = len(trainfile)
# 长度784列,每一行存储一个文本
trainarr = np.zeros((num ,784)) # 数组存储训练数据,行:文件总数,列:784=28*28
print("相对路径:train_digital_pictures/") # 转换数据目录
print("所有训练txt文本数量:",num) # num:所有txt文本数量
for i in range(0,num):
thisfname = trainfile[i]
thislabel = seplabel(thisfname)
labels.append(thislabel) # 记录txt文本对应的数字编号
trainarr[i,:] = datatoarray("train_digital_txt/%s" %(thisfname)) # 加载txt文本数据
num = 0
for arrs in trainarr: # 统计有用数据数量
for arr in arrs:
if arr == 1:
num += 1
break
print("统计有用数据数量 :",num)
return trainarr, labels
6 抽某一个文件进行测试


测试结果与KNN算法的近邻数相关联:不同的近邻数,预测结果可能不一样。
def test_one(trainarr,labels,testfile):
'''
抽某一个文件进行测试
Args:
trainarr: 训练集
labels: 训练集类别
testfile: 文本名称
Return: None
'''
testarr=datatoarray("test_digital_txt/" + testfile)) # 获取测试样本
rknn=knn(21,testarr,trainarr,labels) # knn算法进行测试
print("%s的测试结果:%s"%(testfile,rknn))
7 测试数据
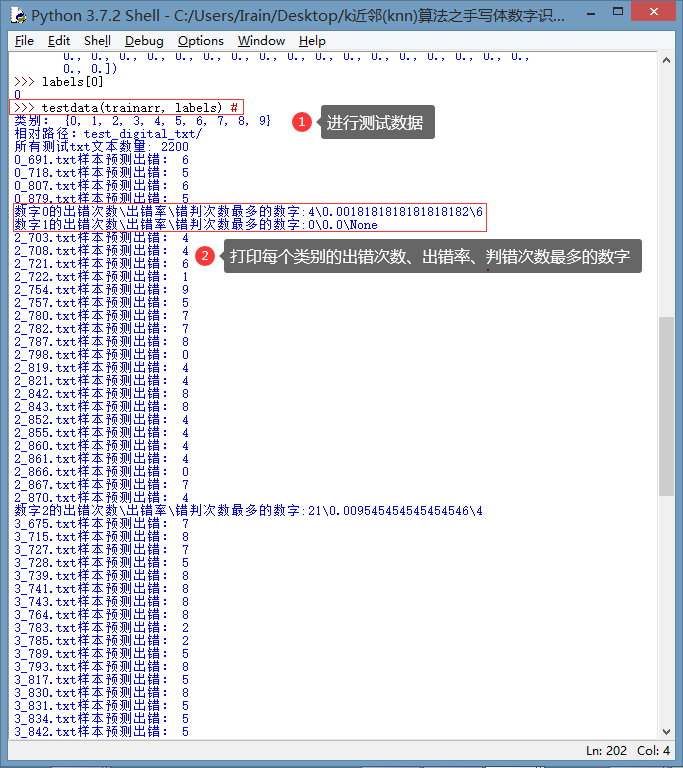
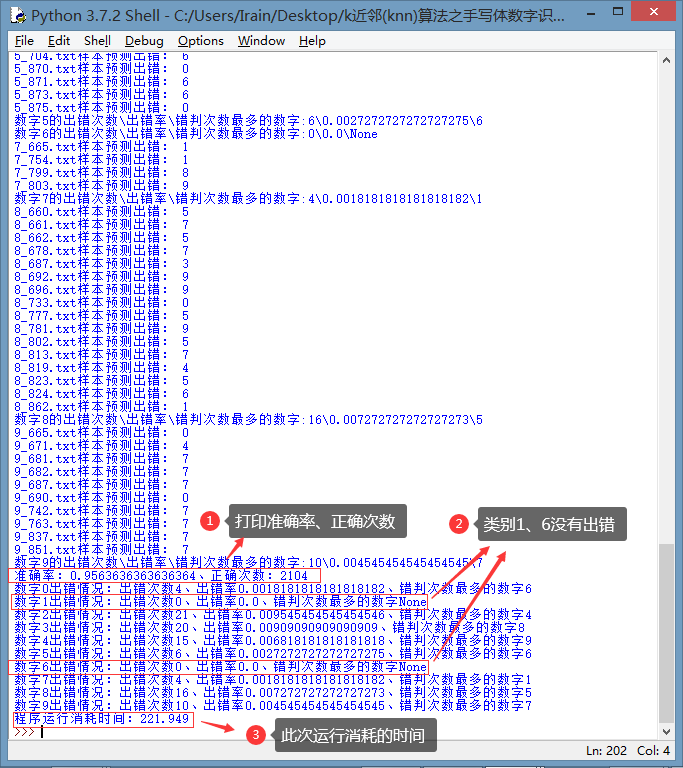
测试结果:
准确率:0.9563636363636364、正确次数:2104
没有出错的数字:1、6;出错率高的数字:2、3、4、8.
数字2出错次数最多21、出错率0.95%、错判次数最多的数字4
程序运行消耗时间:221.949s

测试结果与KNN算法的近邻数相关联:不同的近邻数,预测结果可能不一样,最终导致每个类别的出错率、出错次数、错判次数最多的数字,以及正确率和正确次数都不一样。
def knn(k, testdata, traindata, labels):
'''
k近邻算法预测测试集
Args:
k: 近邻节点数
testdata:测试样本
traindata:训练集
labels:测试集对应类别
Return: None
'''
traindatasize = traindata.shape[0] # 获得测试集行数
dif = np.tile(testdata, (traindatasize, 1)) - traindata # 扩展数组行,训练集与测试样本行数相等
sqdif = dif**2 # 差值平方
sumsqdif = sqdif.sum(axis=1) # 平方求和
distance = sumsqdif**0.5 # 求出距离
sortdistance = distance.argsort() # 排序,返回的是索引
sortdistance
count = {}
for i in range(0,k):
vote = labels[sortdistance[i]] # 显示当前类
count[vote] = count.get(vote,0) + 1 # 统计各类别次数
sortcount = sorted(count.items(),key=operator.itemgetter(1),reverse=True) # 按照降序排列字典
return sortcount[0][0] # 返回预测结果
def testdata(trainarr, labels):
'''
knn算法测试
Args:
trainarr: 训练集
labels: 训练集类别
Return: None
'''
start = time.time()
errors = [] # 所有出错的数字类别
errors_num = [] # 每个数字类别出错的次数
errors_rating = [] # 每个数字类别的错误率
errors_maxdigital = [] # 每个数字类别错判次数最多的数字
maxdigital = [] # 每个数字类别所有错判的数字
print("类别:",set(labels))
print("相对路径:test_digital_txt/") # 转换数据目录
testlist = os.listdir("test_digital_txt/") # 获取测试样本名
num = len(testlist)
print("所有测试txt文本数量:",num) # num:所有txt文本数量
ten = 0
for i in range(0,num):
thisfname = testlist[i]
testarr = datatoarray("test_digital_txt/%s" %(thisfname)) # 获取测试样本
rknn = knn(21,testarr,trainarr,labels) # knn算法进行测试
if str(rknn) != thisfname.split("_")[0]: # 预测错误
print("%s样本预测出错:" %(thisfname),rknn)
errors.append(int(thisfname.split("_")[0])) # 记录出错数字类别
maxdigital.append(rknn) # 判错数字
if (i+1)%220 == 0: # 某个数字类别预测结束
errors_num.append(errors.count(ten)) # 计算某数字类别的出错次数
errors_rating.append(errors_num[ten]/2200) # 计算某数字类别出错率
if maxdigital: # 某数字类别判错次数最大的数字
errors_maxdigital.append(max(maxdigital, key=maxdigital.count))
else:
errors_maxdigital.append("None") # 没有,存入None
print("数字%s的出错次数出错率错判次数最多的数字:%s%s%s" %(ten,errors_num[ten],errors_rating[ten],errors_maxdigital[ten]))
maxdigital = [] # 清空,记录下一个数字类别
ten += 1
accuracy = (2200 - len(errors)) # 预测正确的所有次数
accuracy_rating = accuracy/2200 # 正确率
elapsed = (time.time() - start)
print("准确率:%s、正确次数:%s" %(accuracy_rating,accuracy))
for k in range(0,10):
print("数字%s出错情况:出错次数%s、出错率%s、错判次数最多的数字%s" %(k,errors_num[k],errors_rating[k],errors_maxdigital[k]))
print("程序运行消耗时间:%.3f" %elapsed)
### 8 附录:(实现细节讲解)
最后
以上就是鳗鱼红酒最近收集整理的关于k近邻(knn)算法之手写体数字识别的全部内容,更多相关k近邻(knn)算法之手写体数字识别内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复