K近邻算法的一般流程:
1、收集数据
2、准备结构化数据
3、分析数据
4、测试算法并计算错误率。
5、使用算法:首先需要输入样本数据和结构化的输出结果,然后运行K 近邻算法判定输入数据分别属于哪个分类,最后应用对计算出的分类执行后续的处理。
K 近邻算法的工作原理:
1.存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。
2.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前 k 个最相似的数据,通常 k 是不大于 20 的整数。最后,选择 k 个最相似数据中出现次数最多的分类,作为新数据的分类。
代码:
import numpy as np import operator from os import listdir
def handwritingClassTest():
#测试集的Labels
hwLabels = []
#返回trainingDigits目录下的文件名
trainingFileList = listdir('trainingDigits')
#返回文件夹下文件的个数
m = len(trainingFileList)
#初始化训练的Mat矩阵,测试集
trainingMat = np.zeros((m, 1024))
#从文件名中解析出训练集的类别
for i in range(m):
#获得文件的名字
fileNameStr = trainingFileList[i]
#获得分类的数字
classNumber = int(fileNameStr.split('_')[0])
#将获得的类别添加到hwLabels中
hwLabels.append(classNumber)
#将每一个文件的1x1024数据存储到trainingMat矩阵中
trainingMat[i,:] = img2vector('trainingDigits/%s' % (fileNameStr))
#返回testDigits目录下的文件名
testFileList = listdir('testDigits')
#错误检测计数
errorCount = 0.0
#测试数据的数量
mTest = len(testFileList)
#从文件中解析出测试集的类别并进行分类测试
for i in range(mTest):
#获得文件的名字
fileNameStr = testFileList[i]
#获得分类的数字
classNumber = int(fileNameStr.split('_')[0])
#获得测试集的1x1024向量,用于训练
vectorUnderTest = img2vector('testDigits/%s' % (fileNameStr))
#获得预测结果
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print("分类返回结果为%dt真实结果为%d" % (classifierResult, classNumber))
if(classifierResult != classNumber):
errorCount += 1.0
print("总共错了%d个数据n错误率为%f%%" % (errorCount, errorCount/mTest))
def classify0(inX, dataSet, labels, k):
#numpy函数shape[0]返回dataSet的行数
dataSetSize = dataSet.shape[0]
#在列向量方向上重复inX共1次(横向),行向量方向上重复inX共dataSetSize次(纵向)
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
#二维特征相减后平方
sqDiffMat = diffMat**2
#sum()所有元素相加,sum(0)列相加,sum(1)行相加
sqDistances = sqDiffMat.sum(axis=1)
#开方,计算出距离
distances = sqDistances**0.5
#返回distances中元素从小到大排序后的索引值
sortedDistIndices = distances.argsort()
#定一个记录类别次数的字典
classCount = {}
for i in range(k):
#取出前k个元素的类别
voteIlabel = labels[sortedDistIndices[i]]
#dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。
#计算类别次数
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#python3中用items()替换python2中的iteritems()
#key=operator.itemgetter(1)根据字典的值进行排序
#key=operator.itemgetter(0)根据字典的键进行排序
#reverse降序排序字典
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#返回次数最多的类别,即所要分类的类别
return sortedClassCount[0][0]
def img2vector(filename):
#创建1x1024零向量
returnVect = np.zeros((1, 1024))
#打开文件
fr = open(filename)
#按行读取
for i in range(32):
#读一行数据
lineStr = fr.readline()
#每一行的前32个元素依次添加到returnVect中
for j in range(32):
returnVect[0, 32*i+j] = int(lineStr[j])
#返回转换后的1x1024向量
return returnVect
结果:
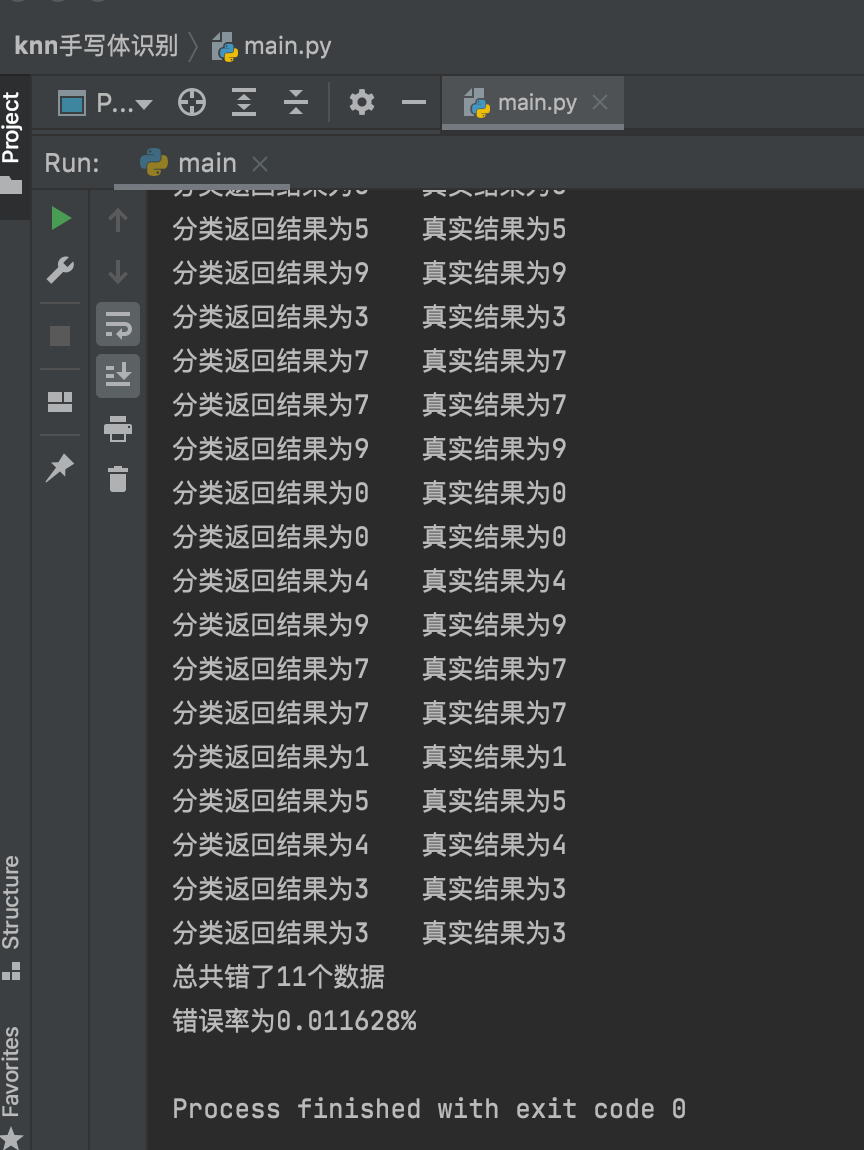
存在问题:
1.运算效率不高,实际使用时可能非常耗时
2.必须保存全部数据集,如果训练数据集很大,必须使用大量的存储空间
3.本例中只进行了单一数字的识别,如果是在例如验证图片中包含多个杂乱顺序的数字或者符号,预计将变得难以识别,可能要借鉴格式塔的理论进行改良
最后
以上就是现代秋天最近收集整理的关于k-近邻算法实现手写体识别的全部内容,更多相关k-近邻算法实现手写体识别内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复