最近一直在看机器学习的书,索性从网上买了一本《机器学习实战》,现在开始用这本书边看边学吧,我也是刚刚开始写博客,希望自己可以一直坚持下去。
因为本人平时比较懒散,天天坐在实验室里不是打dota就是看直播,哎。。。所以就想通过写博客来激励自己,不要浪费大好的光阴啊。。。。。希望大家共同进步吧!!!好了,下面进入我们的正题,K-近邻算法识别手写数字。用的当然是强大的python语言啦!!!
首先简单的介绍一下K-近邻算法吧:
简单的说,K-近邻算法采用测量不通特征值之间的距离方法进行分类(所以K-近邻算法就是一种分类的算法,其实很多算法都是有一些很高大上的名字,在我们了解之后会发现,原来这么简单啊。。哈哈。。有点扯远了)。它的工作原理是:存在一个样本数据集合,也叫做训练样本集,并且样本集中每个样本都存在标签,也就是我们所说的每个样本属于那一类。输入没有标签的数据之后,将新数据的每一个特征与样本集中数据对应的特征进行比较然后算法提取样本集中特征最相似数据(就是最近邻,中国人喜欢把这些东西翻译的高大上一点)的分类标签。一般来说我们只选择样本数据集中前K个最相似的数据,这就是K-近邻算法中K的出处。。。
如果你没有看懂它的工作原理,那么我举一个简单的例子你肯定就懂啦,如下图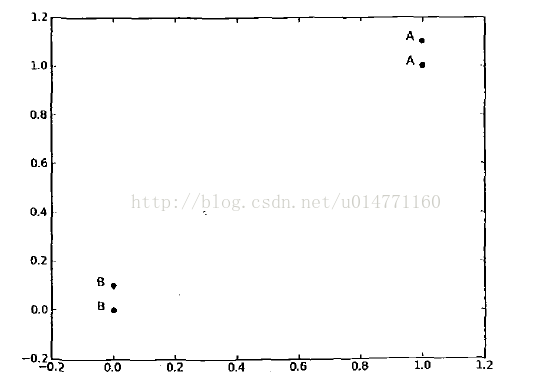
坐标轴上有四个点,从下到上分别为甲(0,0)乙(0,0.1)丙(1,1)丁(1,1.1)。又上角的两个点属于类型A,左下角的两个点属于类型B。此时如果有一个点D(0.9,0.9),那么我们判断D点属于类型A还是类型B呢(此时只有两个类型:A和B)。聪明的你肯定一下就能看得出来是类型A,那么为什么呢?猜的?那你太厉害了吧,其实在不经意中你已经用到了K-近邻算法的思想,好了我们下面就用K-近邻的思想来解释一下为什么属于类型A吧。
我们这里假设K=3,什么时候用等会再说,做题总得有题目吧,所以先设再说吧。算一下D点和这四个点的距离。
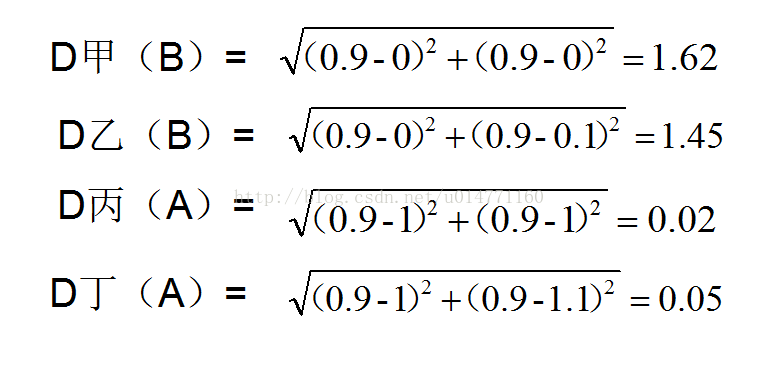
根据原理我们要对这四个距离进行排序(就是对D点的近邻点进行排序):D丁,D丙,D乙,D甲。好啦,近邻已经用了,接下来我们要在这里面取前K个,我们之前设了K =3的。所以取两个A类型的和一个B类型的,行啦!A类型占这K个数据的比例最大,那么K-近邻算法就判断D是属于A类型的。
想一想:这是不是就是用到要给我们初中(还是高中,忘记了)学过的两个距离,就这么简单。
原理我们已经讲完了,接下来就是开始讲实战了。根据《机器学习实战》这本书,把K-近邻算法应用在手写数字识别系统上(是不是感觉很高大上的感觉)!!!好了,先写到这了,接下来的我会尽快补上。
今天开始写接下来的编码部分。
正所谓识别手写数字(这里仅限0-9,因为我们的数据有限),就是说我们在一块画布上面,然后让这个算法识别这个数字是多少。想一想,这是不是就是我们想要的机器学习的效果呢?举个例子,我们经常用手机上面的手写功能,为什么我们在手机上面写一个歪歪扭扭的字,输入法就可以猜到我们想要的字到底是什么呢?其实是一个道理,当然了,我们这个小系统没有手写输入法那么强大,但是如果理解了这个,那么其他的不就是一个道理了嘛。如果我们也想要做的话,那就得学习更多的算法,并且改进、测试,要做的工作很多呀。好了,我们开始说系统的部分。
我们选取的是一张32*32像素的画布(就是打开windows画图,把网格调成32*32的,然后以bmp单色位图存储就可以了),然后在这个画布上面写上0-9。写后上后如下图
那么有了这么一张bmp图片对于我们现在来说没有任何用处啊,因为我们是要编程的,总不能告诉计算机说:这就是9的样子,你记住他就行了,其他和它像的都叫9。计算机可没有那么聪明,因为它只认识0和1,所以人类大脑是比计算机聪明的多滴!接下来的工作就是把这张图片变成计算机可以认识的文件了,什么样子呢?看下面

是的,就是这个样子,但是这些原始数据我们是可以从网上下下来的,所以我会在本文的最后给上下载链接。当我们拿到这些数据之后,就可以直接对这些数据操作啦。那么为什么已经有了这些数据了,我还有说这些数据是怎么来的呢?不是多此一举吗???也是。。。。我这个比较唠叨啦。希望可以写的明白一点。因为比较K-近邻是机器学习的开始嘛。
下面就是代码部分了。。。(终于到了=_=)
第一部分,我们要把这些0101改成另外一种形式,之前我们说过,我们的画布是32*32像素的。那么其实这个txt文件中的0101也是一个32*32的矩阵,但是我们在计算距离的时候通常多少一维的,也就是说是(x1,x2,x3.....xn)这种形式的,所以我们首先应该把32*32的矩阵变成1*1024的形式才方便我们计算距离啊。代码如下(注释我写的很清楚了):
<pre name="code" class="python">def img2vector(filename):
"""
filename代表文件名称
"""
returnVector = zeros((1,1024))##声明一个0矩阵
fr = open(filename)
for i in range(32):
lineStr = fr.readline()##°每一行文件
for j in range(32):
returnVector[0,32*i+j] = int(lineStr[j])##一共32行,全部存储到returnVector里面
fr.close()
return returnVector第二部分:把所有的图片文件编程1*1024的数组之后是不是就应该计算每个测试样本和原始训练样本的距离了:
这里用两个函数计算
def classify(inX,dataSet,labels,k):
"""
四个参数,inX是测试向量,dataSet样本向量数据,labels是标签,k是选取前k个做评测
tile(A,n)用于重复A矩阵n次
argsort()返回的是数组值从小到大的索引
list.get(k,d)
get()相当于一条if...else...语句,参数k在字典中,字典将返回list[k];如果参数k不在字典中则返回参数d,如果K在字典中则返回k对应的value值;
例子:
l = {5:2,3:4}
print l.get(3,0)返回的值是4;
Print l.get(1,0)返回值是0;(该例来源于网络)
"""
dataSetSize = dataSet.shape[0]##shpe函数用于返回矩阵的长度,如shape[0]返回第一维矩阵长度,shape[1]返回第二维矩阵长度以此类推,还有其他功能执行查阅
diffMat = tile(inX,(dataSetSize,1)) - dataSet##tile函数主要功能是重复矩阵多少次,重复了测试向量,与每一个样本相减
sqDiffMat = diffMat**2##计算平方
sqDistances = sqDiffMat.sum(axis = 1)##计算矩阵横轴的和
distances = sqDistances**0.5##平方
sortedDistIndicies = distances.argsort()##用argsort排序
classCount = {}
for i in range(k):
voteLabel = labels[sortedDistIndicies[i]]##通过索引得到前该距离所属的类型
classCount[voteLabel] = classCount.get(voteLabel,0)+1##相应的类型+1
sortedClassCount = sorted(classCount.iteritems(),key = operator.itemgetter(1),reverse = True)
return sortedClassCount[0][0]
"""
classTest()函数用于处理32*32的数据,
"""
def classTest():
file_object = open('result.txt', 'w')
Labels = []
trainingFileList = os.listdir("./digits/trainingDigits/")##listdir函数用于获取该目录下的文件列表,并且以数组的方式存储
length = len(trainingFileList)##获取数组长度
trainingMat = zeros((length,1024))##声明一个length*1024的矩阵用于存储所有样本的向量形式
for i in range(length):
fileNameStr = trainingFileList[i]##获取列表中每一个文件名(包含扩展名)
fileName = fileNameStr.split('.')[0]##获取列表中每一个文件名(不包含扩展名)
numClass = fileName.split('_')[0]##获取该文件所属的类别(因为文件名都是以‘数字类别_第几个样本.txt’形式的,所以需要进行两次的split函数)
Labels.append(numClass)##以队列的形式加入到Labels的队尾
trainingMat[i,:] = img2vector("./digits/trainingDigits/"+ fileNameStr)##用img2vector()函数处理32*32的图片矩阵,存入trainingMat中
testFileList = os.listdir("./digits/testDigits/")##测试组的文件列表,下面的代码意思如上,多余的就不写了
##erreCount = 0.0
lengthTest = len(testFileList)
for i in range(lengthTest):
fileNameStr = testFileList[i]
fileName = fileNameStr.split('.')[0]
numClass = fileName.split('_')[0]
vectorUnderTest = img2vector("./digits/testDigits/"+fileNameStr)
classifierResult = classify(vectorUnderTest,trainingMat,Labels,3)
file_object.write(str(classifierResult)+" "+str(numClass)+'n')
##print "come back result is %s.......real result is %s" %(classifierResult,numClass)
file_object.close()虽然成功率是高了,但是在测试的时候我发现K-近邻的耗时非常高!因为你想想,我们的样本是接近2000个点,测试样本是接近1000个点,也就是说,每个测试样本要和每个原始样本都要计算一下距离,时间复杂度为O(M*N),如果把这样的算法应用到我们之前所说的手写输入法中去,那不是要等急死了。。。。
总结:K-近邻算法是分类数据最简单最有效的算法,但是如果训练数据集很大,就必须要使用大量的存储空间,同时也需要大量的时间去计算,因此为了更好的研究更有效更高效的算法,就得继续向下学习啊。我们共同进步吧!!!
最后补充一下:在我把代码调试完成的时候发现了这么一个问题,系统报错:UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xe5 in position 108: ordinal not in range(128 后来从网上查了一下,找到了这个帖子http://blog.csdn.net/mindmb/article/details/7898528。大家如果遇到此类问题的时候也可以照此解决。
最后贴上代码和原始数据的下载链接http://download.csdn.net/detail/u014771160/8508715
最后
以上就是超级故事最近收集整理的关于基于K-近邻算法识别手写数字的实现的全部内容,更多相关基于K-近邻算法识别手写数字内容请搜索靠谱客的其他文章。








发表评论 取消回复