1 算法概述
SVM算法是有监督的数据挖掘算法,是一种二分类算法(经过改造后也可以用于多分类,但比较复杂), 在非线性分类方面有明显优势;
训练结果:模型
训练成功后,根据support vector(一组向量)对后续向量进行分类;
输入输出:模型输入的是一堆向量(一般是-1~1之间的浮点数),以及这些向量所属的分类label(一般用-1,1表示);
模型训练是要调整的内容:核函数、核函数的参数、松弛变量等,取决于算法实现的情况
2 算法原理
先说个直观的解释,比如玩个类似水果忍者的游戏,现在有水果和炸弹散乱地放在一起,如何一刀砍下,刀的一侧只有水果,另一侧只有炸弹呢?(也就是二分类)
这时候一个大侠出场了,扎稳马步,用力猛拍桌子,水果和炸弹被弹向空中,由于炸弹和水果的密度、大小等不一样,弹在空中的某个时刻,炸弹在一个区域、水果在另一个区域,这时候大侠在它们之间迅速划了一刀,任务完成!
大概就是这个流程,数学原理有点复杂,下面只是概略地讲一下,写细了可以写本书(有出版的书)
2.1 SVM的求解过程,就是在一个n维向量空间中的点,找到个“超平面”把两种类型分开 ,并且“margin”最大
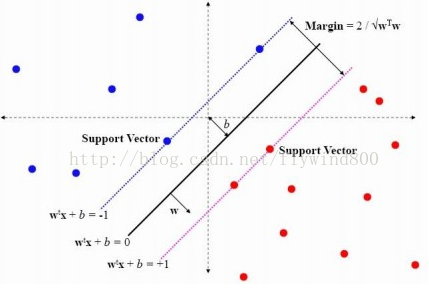
上图显示的是一个二维“线性可分”的情况,图中的那条黑线就是“超平面”,由此决定的两条虚线间的距离最大,而虚线上的2个蓝色点、2个红色点决定了超平面位置,他们被叫做“支持向量” support vector.
2.2 在线性可分的情况下,如何求出这个超平面
目前常用的比较高效的是SMO算法,具体推导过程请参考相关书籍或论文。
2.3 线性不可分的情况下,核函数的作用
处理二维空间线性可分的问题不难,SVM的优点是可以把低维线性不可分的情况,映射到高维线性可分的情况。
这里的维度,大家不要想象成科幻小说里的4维空间什么的,比如要对人进行分类,现在收集到的属性有发色、身高、肤色、年龄这4个属性值,这时候每个人的属性值就是个4维向量,把这个4维向量通过一个函数变换成6维向量,就是向高维的映射。
上面提到的那个变换函数叫“核函数”,核函数的引入是非常巧妙的,它把向量映射到高维,同时避免了向量在高维空间中直接计算的复杂性。
常用的核函数有
线性核,RBF核(径向基)等
3 实例
svm的输入是一组向量以及每个向量对应的分类:
label,一般是-1或1,表示种类
index:value, 向量值,比如 1:0.78, 2:1, 3:-0.52, 4:-0.35, 5:0.56, 一般用一个一维数组表示
数据准备成上述格式后,一般随机分成2份,一份用来训练模型,一份用来测试模型的准确性,以便根据测试结果调整训练参数。
在线性不可分的情况下,使用
RBF核效果比较好,现在很多软件可以自动完成这个对比、选择过程。
比如用svm进行垃圾邮件识别,大概步骤如下:
对邮件进行打标,垃圾邮件标为1,非垃圾邮件标为-1.
对邮件内容进行分词,对每个词计算特征权重,然后通过归一化转化成-1到1之间的值,(这一步很关键,要做好的话得下些功夫)
选择一个svm实现lib或软件,将准备好的这些向量和label带入训练,调整参数得到效果满足要求的模型。
最后
以上就是迷人水池最近收集整理的关于SVM(支持向量机)算法原理和实际应用的全部内容,更多相关SVM(支持向量机)算法原理和实际应用内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。






![[洛谷]P1996 约瑟夫问题一、问题描述二、思路分析三、代码实现](https://www.shuijiaxian.com/files_image/reation/bcimg13.png)

发表评论 取消回复