前言
之前我们花费了很长时间介绍SVM的工作原理,本节将介绍如何使用SVM。
线性SVM分类
sklearn.svm.LinearSVC(penalty=’l2’, loss=’squared_hinge’, dual=True, tol=0.0001, C=1.0, multi_class=’ovr’, fit_intercept=True, intercept_scaling=1, class_weight=None, verbose=0, random_state=None, max_iter=1000)
一一介绍:
penalty:惩罚项,l1和l2,默认l2,使用l1会得到稀疏解
loss:损失函数,‘hinge’ 和’‘squared_hinge’
dual:利用对偶还是原始问题求解,当样本数大于特征数,dual=False效果好
tol:容忍误差
C:错误惩罚项,C越小,间隔越大,违例越多
multi_class:多分类策略,‘ovr’ or ‘crammer_singer’ ,ovr:一对多;crammer_singer:实际很少使用
fit_intercept:是否计算偏置项
intercept_scaling:当self.fit_intercept为True时,实例向量x变为[x,self.intercept_scaling]
class_weight :权重
max_iter:最大迭代次数
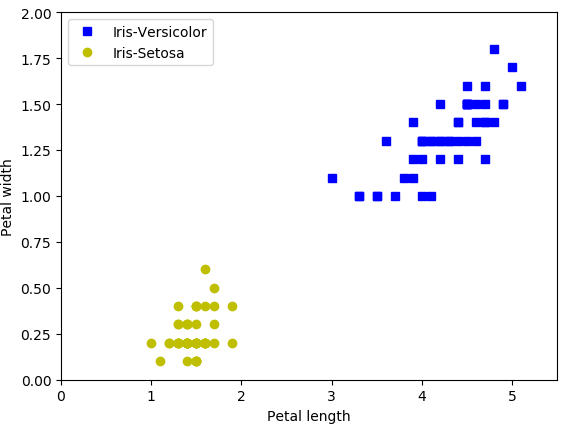
以鸢尾花数据集为例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
#花瓣长度宽度
x = iris['data'][:,(2,3)]
y = iris['target']
setosa_or_versicolor = (y==0)|(y==1)
#创建只有setosa和versicolor的数据集
X = x[setosa_or_versicolor]
y = y[setosa_or_versicolor]
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs", label="Iris-Versicolor")
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo", label="Iris-Setosa")
plt.xlabel("Petal length")
plt.ylabel("Petal width")
plt.legend(loc="best")
plt.axis([0, 5.5, 0, 2])
plt.show()结果:
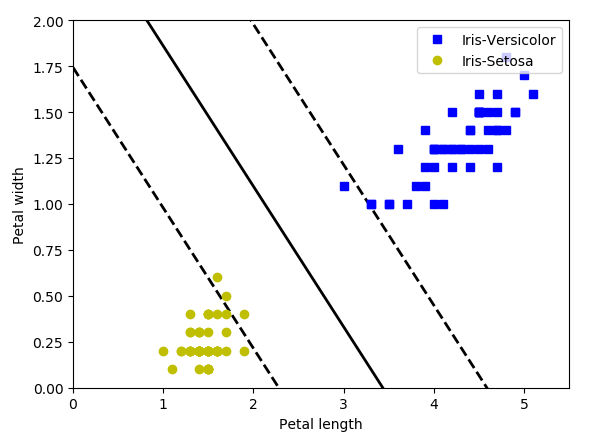
使用LinearSVC进行分类:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.svm import LinearSVC
iris = datasets.load_iris()
#花瓣长度宽度
x = iris['data'][:,(2,3)]
y = iris['target']
setosa_or_versicolor = (y==0)|(y==1)
#创建只有setosa和versicolor的数据集
X = x[setosa_or_versicolor]
y = y[setosa_or_versicolor]
#绘制SVM的决策边界和决策面
def plot_svc_decision_boundary(svm_clf,xmin,xmax):
w = svm_clf.coef_[0]
b = svm_clf.intercept_[0]
#决策面为 wTx+b=0
x0 = np.linspace(xmin,xmax,200)
x1 = -w[0]*x0/w[1] - b/w[1]
#决策边界
margin = 1/np.sqrt(w[0]**2+w[1]**2)
up = x1+margin
down = x1-margin
#绘制决策面和边界
plt.plot(x0,x1,'k-',linewidth=2)
plt.plot(x0,up,'k--',linewidth=2)
plt.plot(x0,down,'k--',linewidth=2)
plt.show()
#SVM线性分类器
svm_clf = LinearSVC(C=2,random_state=42)
svm_clf.fit(X,y)
plt.figure()
plot_svc_decision_boundary(svm_clf,0,5.5)
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs", label="Iris-Versicolor")
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo", label="Iris-Setosa")
plt.xlabel("Petal length")
plt.ylabel("Petal width")
plt.legend(loc="best")
plt.axis([0, 5.5, 0, 2])
plt.show()结果:
非线性分类
class sklearn.svm.SVC(C=1.0, kernel=’rbf’, degree=3, gamma=’auto_deprecated’, coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=’ovr’, random_state=None)
- C:错误惩罚项,C越小,间隔越大,违例越多
- kernel:核函数类型,默认为'rbf'。可选参数为:
- 'linear':线性核函数
- 'poly':多项式核函数
- 'rbf':径像核函数/高斯核
- 'sigmod':sigmod核函数
- 'precomputed':核矩阵
- precomputed表示自己提前计算好核函数矩阵,这时候算法内部就不再用核函数去计算核矩阵,而是直接用你给的核矩阵,核矩阵需要为n*n的。
- degree:多项式核函数的阶数,默认为3。这个参数只对多项式核函数有用,是指多项式核函数的阶数n,如果给的核函数参数是其他核函数,则会自动忽略该参数。
- gamma:核函数系数,默认为auto。只对'rbf' ,'poly' ,'sigmod'有效。如果gamma为auto,代表其值为样本特征数的倒数,即1/n_features。gamma越大,拟合程度越大
- coef0:核函数中的独立项,默认为0.0。只有对'poly' 和,'sigmod'核函数有用,是指其中的参数c。
- probability:是否启用概率估计,bool类型,可选参数,默认为False,这必须在调用fit()之前启用,并且会fit()方法速度变慢。
- shrinking:是否采用启发式收缩方式,bool类型,可选参数,默认为True。
- tol:容忍误差
- cache_size:内存大小,float类型,可选参数,默认为200。指定训练所需要的内存,以MB为单位,默认为200MB。
- class_weight:类别权重
- max_iter:最大迭代次数,int类型,默认为-1,表示不限制。
- decision_function_shape:多分类策略,可选参数'ovo'和'ovr',默认为'ovr'。'ovo'表示one vs one,'ovr'表示one vs rest。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
#创建数据集
X,y = make_moons(n_samples=100,noise=0.15,random_state=42)
#数据集可视化
def plot_dataset(X,y,axes):
plt.plot(X[:,0][y==1],X[:,1][y==1],'bs')
plt.plot(X[:,0][y==0],X[:,1][y==0],'g^')
plt.axis(axes)
plt.show()
#绘制划分区域
def plot_predict(clf,axes):
x0s = np.linspace(axes[0], axes[1], 100)
x1s = np.linspace(axes[2], axes[3], 100)
#生成网络状数据
x0, x1 = np.meshgrid(x0s, x1s)
X = np.c_[x0.ravel(), x1.ravel()]
y_pred = clf.predict(X).reshape(x0.shape)
#填充等高线
plt.contourf(x0, x1, y_pred,alpha=0.2)
plt.show()
#高斯核
gamma1,gamma2=0.1,5
C1,C2 = 0.001,1000
hyperparams = (gamma1,C1),(gamma1,C2),(gamma2,C1),(gamma2,C2)
svm_clfs = []
for gamma,C in hyperparams:
rbf_kernel_svm = Pipeline([('scaler',StandardScaler()),
('svc_clf',SVC(kernel='rbf',gamma=gamma,C=C))])
rbf_kernel_svm.fit(X,y)
svm_clfs.append(rbf_kernel_svm)
plt.figure(figsize=(11, 7))
for i ,svm_clf in enumerate(svm_clfs):
plt.subplot(221+i)
plot_dataset(X,y,[-1.5,2.5,-1,1.5])
plot_predict(svm_clf,[-1.5,2.5,-1,1.5])
gamma,C = hyperparams[i]
plt.title('gamma ={},C ={}' .format(gamma, C))
plt.show()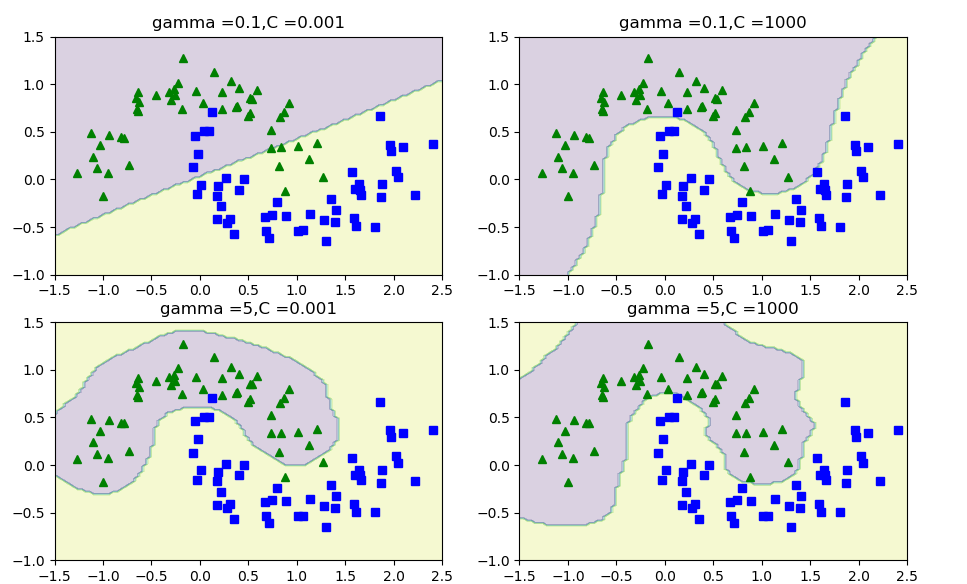
SVM回归
class sklearn.svm.LinearSVR(epsilon=0.0, tol=0.0001, C=1.0, loss=’epsilon_insensitive’, fit_intercept=True, intercept_scaling=1.0, dual=True, verbose=0, random_state=None, max_iter=1000)
多了一个重要的超参数epsilon来控制松弛程度,epsilon越大,间隔越大。
对于非线性回归,同样有对应的SVR
class sklearn.svm.SVR(kernel=’rbf’, degree=3, gamma=’auto_deprecated’, coef0=0.0, tol=0.001, C=1.0, epsilon=0.1, shrinking=True, cache_size=200, verbose=False, max_iter=-1)
最后
以上就是优雅百褶裙最近收集整理的关于机器学习8 SVM的应用的全部内容,更多相关机器学习8内容请搜索靠谱客的其他文章。








发表评论 取消回复