声明:本文来自于微信公众号 量子位(ID:QbitAI),作者:鱼羊,授权热心网友转载发布。
把AlphaGo的核心算法用在大模型上,“高考”成绩直接提升了20多分。
在MATH数据集上,甚至让7B模型得分超过了GPT-4。
一项来自阿里的新研究引发关注:
研究人员用蒙特卡洛树搜索(MCTS)给大语言模型来了把性能增强,无需人工标注解题步骤,也能生成高质量数据,有效提升大模型的数学成绩。
论文发布,让不少网友重新关注到了蒙特卡洛树搜索这个在前大模型时代的明星算法。
有人直言:
蒙特卡洛树搜索+LLM是通往超级智能之路。

因为“树搜索本身更接近人类思维”。
用蒙特卡洛树搜索增强大模型
具体来说,阿里的研究人员提出了一种名为AlphaMath的方法,用大语言模型+MCTS来自动生成数学推理数据,并提升大模型在完成数学推理任务时的性能表现。
嗯,名字就很有蒙特卡洛树搜索内味儿了。
这里有个前情提要:
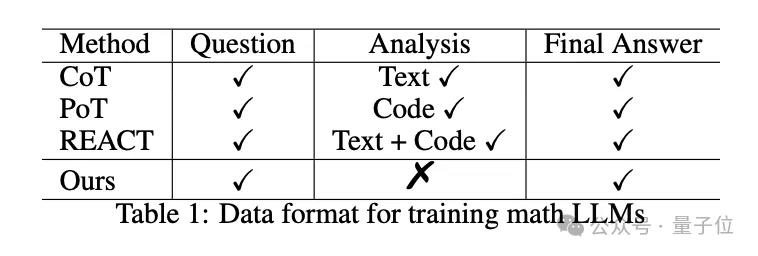
思维链(CoT)、思维程序(PoT)等方法已经被证明能够有效提高大模型的数学能力,但问题在于,它们都需要人类手动喂详细的解题步骤,即训练当中需要用到人工标注的高质量数学推理数据。
AlphaMath的一个核心目的就在于,在这个步骤中去人工化——数据格式就是简单的数学问题-答案对。
AlphaMath的技术路线主要涵盖三个阶段:
首先,研究人员收集了一个数学数据集,其中包含数学问题及其对应的正确答案。
然后,利用预训练的大模型(即策略模型)根据问题生成初始的解题路径,并通过MCTS对解题路径进行探索和改进,搜索更优的解题思路。
在MCTS过程中,同时训练一个价值模型来预测解题路径的质量,引导搜索方向。
最后,第二阶段获得的数据会被用来优化策略模型和价值模型。
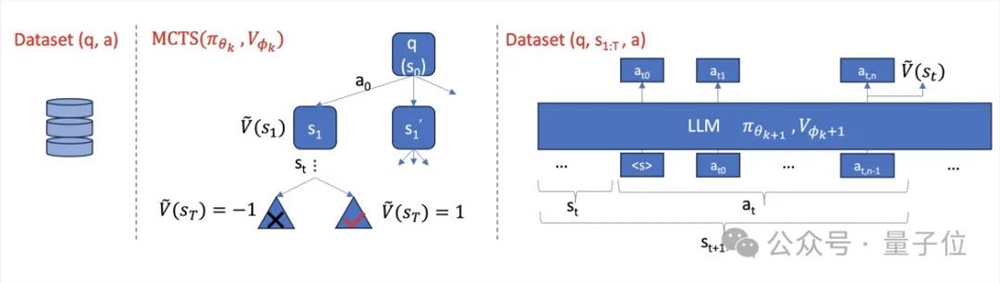
这三个阶段会通过迭代优化地方式执行,以实现无需人工标注的自动数据生成和模型数学能力优化。
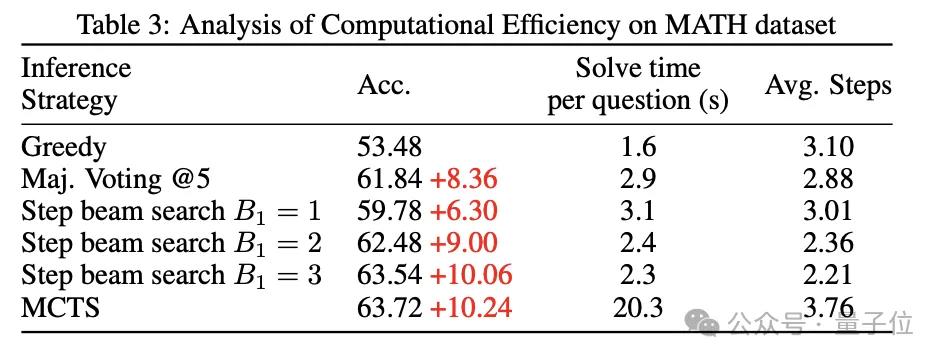
另外,研究人员还基于价值模型提出了Step-level Beam Search方法,以提高大模型的数学推理效率,平衡推理时的解题质量和运行时间。
简单来说,Step-level Beam Search是将MCTS推理过程做了个简化:
利用价值模型对候选路径进行评估,以更准确地选择高质量的解题路径。
通过逐步扩展和剪枝,在搜索过程中动态调整候选路径集合,提高搜索效率。
搜索过程中考虑了完整的解题路径,而不仅仅是局部的下一步动作,可以得到更全局优化的解题方案。
MATH成绩超GPT-4
为了验证AlphaMath的效果,研究人员设计了这样的实验:
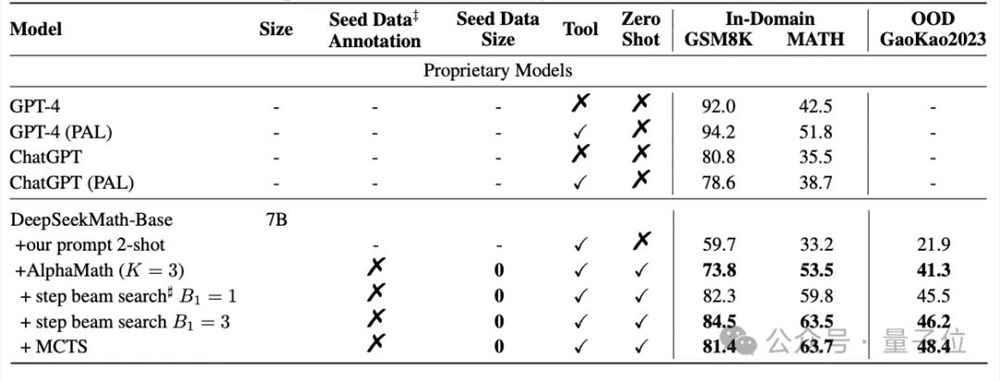
对开源的数学大模型DeepSeekMath-Base-7B,用AlphaMath方法进行训练,并在GSM8K、MATH和Gaokao2023基准上,与GPT-4为代表的闭源模型、Llama2为代表的开源模型,以及专门做过数学SFT的MathCoder等模型进行对比。
结果显示,不依赖于人类(或GPT-4)标注的高质量数据,AlphaMath调教下的7B数学大模型,已经能在MATH上取得63%的分数,超过了GPT-4原版的42.5%和外挂代码解释器版的51.8%。
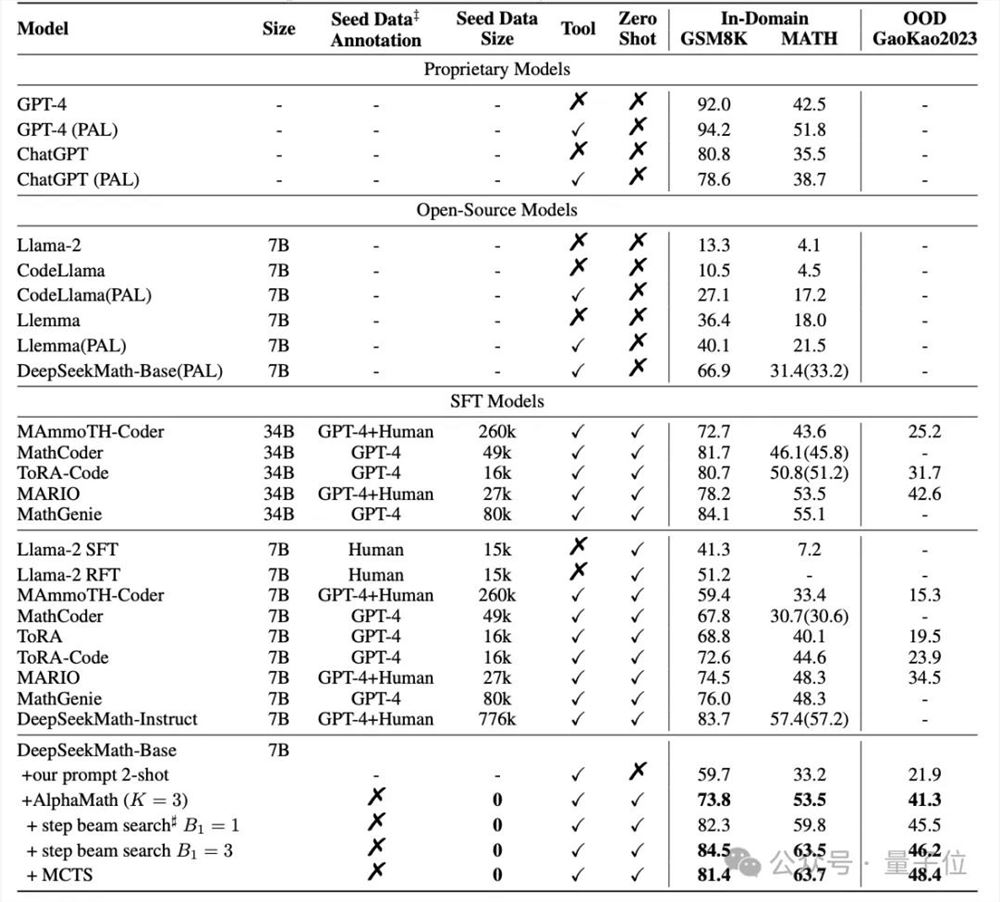
另外,在执行3轮MCTS并训练策略模型和价值模型的情况下,AlphaMath能让大模型在涵盖小学数学题的GSM8K上提升10多分,在MATH和Gaokao2023上提升20多分。
还可以看到,Step-level Beam Search在MATH数据集上取得了良好的效率和准确率平衡。
论文的共同一作是Guoxin Chen、Mingpeng liao、Chengxi Li和Kai Fan。
通讯作者Kai Fan本硕毕业于北京大学,2017年从杜克大学博士毕业,2018年加入阿里巴巴达摩院。
论文地址:
https://arxiv.org/abs/2405.03553
(举报)








发表评论取消回复