声明:本文来自于微信公众号 机器之心 作者:微胖,授权热心网友转载发布。
一、被忽略的「Agent 框架」
OpenAI 最近又有了新动作,这次他们的野心更大了。
鉴于大型语言模型( LLM )强大的先验知识和行动/反应能力,让 AI 训练 AI ,可还行?
几个顶级大模型在机器学习自动化工程上的表现如何?
人类距离 OpenAI AGI 路线图上的 Level3( Agents )还有多远?
怀揣这些问题,OpenAI 自行推出了一个新基准测试—— MLE-bench ,严选75个与机器学习工程( MLE )相关的 Kaggle 竞赛题目。毕竟,目前「很少有基准测试能够全面衡量自主的端到端机器学习工程」。
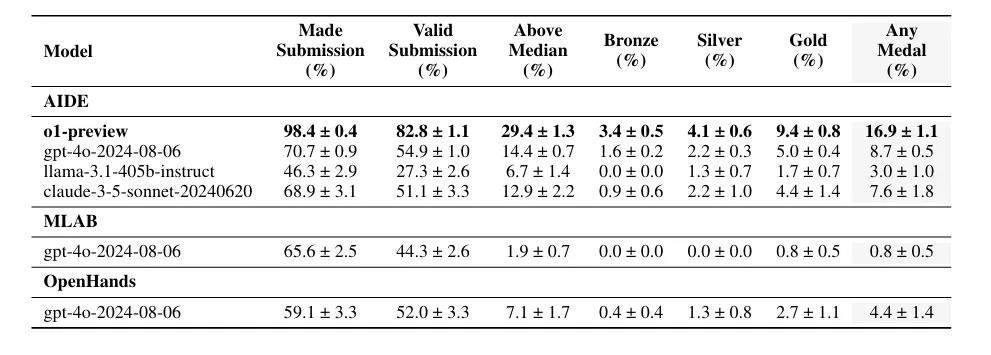
结果发现,GPT-4o 结合 AIDE 框架平均获得奖牌数量,明显优于另外两个开源 Agent 框架。
更令人惊讶的是,当模型切换到 OpenAI o1-preview(据称,突破了 LLM 推理极限)后,其表现又翻了一倍:
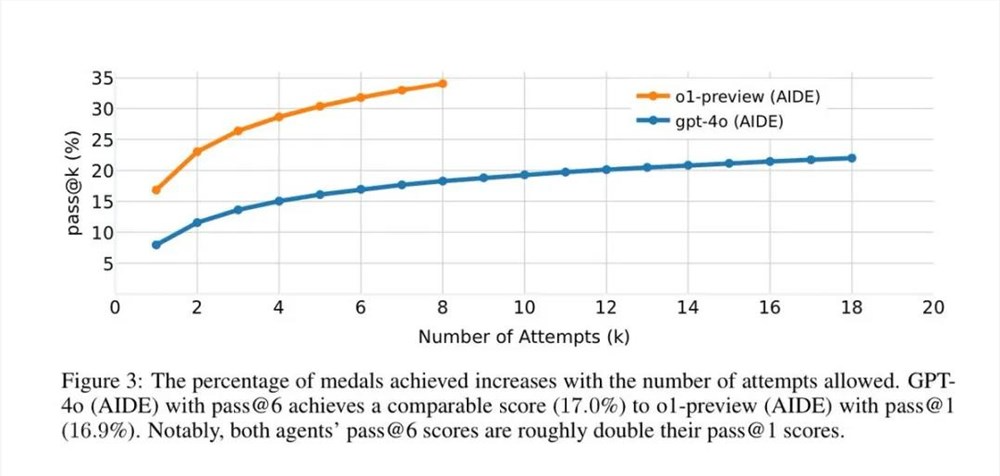
在大约16.9% 的比赛中达到了相当于 Kaggle 铜牌以上的水平,奖牌数量也一骑绝尘。
而且,8次尝试后,o1-preview 的得分从单次尝试的16.9% 提高到了34.1%。
有趣的是,论文本意是为了展示 OpenAI 自家模型(如 o1-preview )的卓越能力,却「意外」地让一个名为 AIDE 的开源 Agent 框架脱颖而出,引发不少关注。
Meta FAIR 研究科学家主任田渊栋随即发去贺电。
「这是一个绝佳例证,展示了开放式自我完善的外部循环(AIDE)如何引导强大的内部循环(o1)实现惊人的能力飞跃。」伦敦大学学院( UCL )教授、谷歌 DeepMind 高级研究员和开放环境学习团队负责人 Tim Rocktäschel 在X(前 Twitter )上说,他同时领导着谷歌 Genie( foundation world model )项目。

UCL 名誉教授、谷歌 DeepMind 研究主任 Edward Grefenstette 认为,AIDE 团队「构建的东西很大程度上支撑和影响了 OpenAI 的智能体路线图。」
DeepMind 研究员、伦敦大学学院教授 Sebastian Riedel 欣喜地表示:「我们亲眼目睹了『 Agent 框架』在基础模型之上带来的巨大影响。」
MLE-bench 公布后,AIDE 作者之一、WecoAI 联合创始人& CEO 蒋铮尧接受了机器之心的采访。
他谈到,「像 OpenAI 这样的公司已经投入了大量精力和金钱来构建内循环前沿模型(如 o1-preview ),一个好的自改进外循环 (Agent 框架,如 AIDE ) 会给前沿模型的能力带来巨大提升。」
二、认识 AIDE ,目前最好的 MLE Agent
在评估大模型性能之前,选择合适的 Agent 框架非常重要。
OpenAI 发现,尽管有效提交数量差不多,但是,GPT-4o 结合 AIDE 框架在8.7% 的竞赛中至少获得铜牌,明显多于另两个开源框架 MLAB 、OpenHands(0.8% 、4.4% )。
对于这个结果,蒋铮尧并不意外,因为这些框架的设计方向本来就不同。
MLAB 是基于 ReAct 框架(通用的)、针对机器学习任务设计过的 Agent。
在设计理念上,主要是做接口设计,通过调用工具来执行操作,类似于为 ChatGPT 配备了更多工具(如数据预处理、特征工程等),他们相信大模型自己就知道应该怎么做。
不过,对当前世代的模型来说,这很难做到,如果能做到,基本等于实现 AGI。
OpenHands (前身名为 OpenDevin )更为通用一些,是一个由 AI 驱动的软件开发 Agent 。它能基于用户自然语言命令,「自动驾驶」软件开发任务,如克隆项目、修改代码、运行命令、调用 API 和提交代码等,也包括数据科学任务。
相比之下, AIDE 没有这么通用。
它是一个专注于代码优化的框架,后来在机器学习方面进行了一些特化( Machine Learning CodeGen Agent ),肯定会比通用框架表现更好。
真正出乎蒋铮尧意料的是, o1-preview 和 AIDE 适配性非常好,当模型切换到 OpenAI o1-preview, 表现又翻了一倍,在大约16.9% 的比赛中达到了相当于 Kaggle 铜牌以上的表现水平。
我们自己参加 Kaggle,成绩肯定没有它高,蒋铮尧推测这可能与 AIDE 的 AI Function(AI 函数)设计范式有关。
简单来说,AI Function 范式就是将大问题拆分成一个个具体指令(「函数」),再用算法将它们串起来。「在这种范式下,每次喂给大模型(如 o1-preview )的问题,会跟大模型接受强化学习训练时做过的数理化题目比较像。」他解释说。
换句话说,这种范式创造了一个与大模型训练过程更为一致的问题解决环境,这种一致性使得模型能够更好地利用其在训练中获得的知识和技能,提高解决问题的效率。
负责将具体指令串起来的核心算法,就是「解空间树搜索( Solution Space Tree Search )」,包括3个主要组件。
解决方案生成器( Solution Generator ),负责提出新的解决方案,主要是创建起点。
大模型接收一系列自然语言指令和背景资料后,会生成几个初始解决方案,也可以对现有方案进行修改,比如修复 bug 或引入改进。
每个解决方案包含机器学习模型的实现和评估方法。
OpenAI 的论文提供了一张「快照」(下图)。

MLE-bench中,三种不同Agent框架的真实轨迹摘录
在执行某个 MLE-bench 任务时,AIDE一开始设计了一个基于预训练 EfficientNet-B0模型的二元分类器用于病理图像分类,这可以被视为搜索的起点或初始解决方案。
评估器( Evaluator ),会测试每个解决方案,将其性能与目标进行比较来完成评估,并将评估结果输出到命令行。
对于单步任务,大语言模型有能力写出比较合格的评估代码,蒋铮尧说。
基础解决方案选择器( Base Solution Selector ),负责从已探索的选项中选择最有前途的解决方案,作为下一轮优化的起点。
这是一个写死的逻辑(一个数学运算),大模型只需客观判断哪一个方案的数值最好即可。
这个组件对于引导搜索过程至关重要,因为,它会将实验资源集中到最有希望的解决方案上。
回到上面的 MLE-bench 任务。
针对初始方案,AIDE 在步骤2提出了改进方案,在测试集上使用测试时增强( TTA )来提高模型性能。
在步骤17中,它提出了另一个改进:用 Focal Loss 替换标准的二元交叉熵损失函数。
从步骤2到17,暗示了中间还有许多其他优化步骤,虽然图片中没有直接显示评估结果,但我们可以推断,从使用 EfficientNet-B0到引入 TTA,再到更换损失函数,每一步都建立在前一步的结果评估基础上。
AIDE 会要求大模型基于最佳方案继续改进,后者可能又生成几种不同的改进方向,周而复始。
通过不断生成新的解决方案,AIDE 逐步探索和优化解决方案空间,提高任务模型的性能,最终收敛到一个高度优化的解决方案。
纵观MLE-bench任务全程,不难发现,通用框架就像急着提前交卷的学生,过早结束运行,有时在最初几分钟内就结束了。
如 OpenHands 只跑了2分钟(19steps )就结束,不再继续提升。
AIDE 会反复提示模型去提高得分,一直战斗到交卷铃声响(24小时),共生成和评估了30个不同解决方案或变体( nodes ) 。
虽然在 OpenAI MLE-bench 中,AIDE 在16.9% 的 Kaggle 任务上获得奖牌,但4月的 WecoAI 技术报告中,AIDE 表现更优:
在 Kaggle 数据科学比赛中的平均表现,击败了一半的人类参赛者!
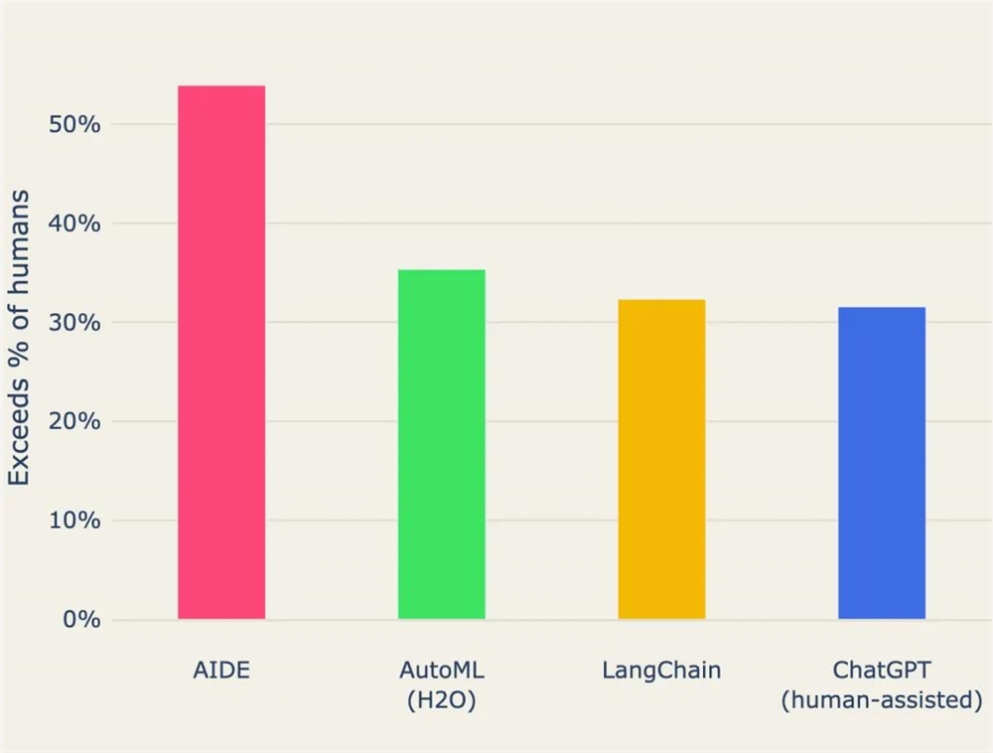
来自4月的WecoAI技术报告,AIDE 平均表现超过50% 的 Kaggle 数据科学比赛的人类参与者,也优于传统的 AutoML(H2O)、Langchain Agent 和 ChatGPT(在人工协助下)。
蒋铮尧解释了性能差异的原因:
OpenAI 更关注深度学习任务,但我们选择的 Kaggle 比赛多为表格数据任务(如预测房价、信用卡欺诈、乘客是否在泰坦尼克号事故中生存),需要深度学习的任务很少,GPU 太贵是一个重要原因。
在这些常见机器学习任务,特别是表格数据任务,花两美元就可以得到一个非常不错的解决方案。蒋铮尧说,当使用 gpt-4-turbo 作为 LLM 时,推理成本还不到1美元。
因为,AIDE 每次只提供最相关的信息给 LLM,而不是将包含大量冗余的历史信息全都扔进去 ,极大节约了推理成本。
然而,OpenAI MLE-bench 也揭示出明显的局限性。
比如,三个 Agent 都没能很好地考虑到机器的性能限制和时间限制。它们会发出一些超出机器承受能力的命令,导致电脑硬盘或内存吃不消,程序被系统强制关闭,任务被迫提前结束。
另外,它们很少会表明,所生成的代码会运行多长时间。
蒋铮尧认为,这些大模型并没有真的达到「 Agent 」的程度,它们在处理需要长期规划和多步骤交互的复杂任务时仍存在明显不足。
AIDE 代表了一种新的尝试,结合代码逻辑和神经网络,专门针对特定任务进行优化,更适合处理边界明确的问题。
相比传统纯逻辑软件,AIDE 能处理更广泛的问题,但 「如果面对的问题越开放,逻辑部分就会越复杂,直到(程度复杂到)无法处理。」
三、从 UCL出发的 WecoAI
作为 AIDE 主要作者之一,蒋铮尧、 吴宇翔和 Dominik Schmidt 也是英国初创公司 Weco AI 的核心团队成员, 三人均来自享誉盛名的伦敦大学学院( UCL )。
蒋铮尧作为 Weco AI 的联合创始人兼 CEO,目前仍在 UCL DARK 实验室攻读博士学位。DARK 实验室(全称 UCL Deciding, Acting, and Reasoning with Knowledge Lab )隶属于伦敦大学学院人工智能中心,是一个专注于复杂开放环境中强化学习研究的前沿团队。在2024年国际机器学习会议( ICML )上,DARK 摘得了两项最佳论文奖。
蒋铮尧的两位导师分别是伦敦大学学院教授 Tim Rocktäschel 和 UCL 名誉教授Edward Grefenstette,两人同时也在谷歌 DeepMind 从事研究。
公司联合创始人兼 CTO 吴宇翔在 UCL 人工智能中心 NLP 组攻读博士学位,之前聚焦于问答领域。创始工程师团队同样实力雄厚,Dominik Schmidt 也来自 UCL DARK 实验室,拥有硕士学位。Dhruv Srikanth 在卡耐基梅隆大学获得计算机科学硕士学位。
WecoAI 成立于2023年5月。在此之前,吴宇翔和蒋铮尧开发了多智能体 LLM 框架 ChatArena ,引起了广泛关注。不过,开始创业后,团队意识到多智能体框架的商业化还为时尚早,且面临诸多挑战。
他们重新思考方向,寻找既具商业前景,又能激发团队兴趣的领域。经过深思熟虑,他们确定了「用 AI 智能体来制造 AI 」。
机器学习的进步主要源于有效的实验:针对特定任务(如图像分类)开发方法,运行实验,评估结果,然后根据反馈改进方法。这个迭代过程很有挑战性,研究人员不仅需要具备广泛的先验知识,写出实用的代码,还能准确解读实验结果,后续改进。
作为工程师,他们天生就有自动化工作流程的冲动,特别看重实验过程自动化的潜力,那么,强大语言模型驱动的 Agent 能否有效执行这些复杂的机器学习实验呢?
考虑到成本,团队选择聚焦算力消耗比较低的机器学习任务,特别是在表格模型和小规模神经网络方面,并于2024年4月推出了 AIDE ,在 Kaggle 数据科学比赛中的平均表现战胜了50% 的人类参赛者。
AIDE 主要是我们研究方向的工作。蒋铮尧解释说,尽管 OpenAI 的 o1-preview 带来了一些进展,但目前技术还没有完全成熟,商业化仍面临诸多挑战。
未来,AIDE 也将持续改进。「我们计划加强与社区的合作,包括提升性能和关注 AI 安全,」蒋铮尧表示,「我们也准备与对 AI 安全有担忧的各类机构和学界专家展开合作。」
这种能够递归自我提升(recursive self-improvement)的 AI 同时又是非常危险的。
前不久,微软 AI CEO Mustafa Suleyman 公开表示,尽管目前我们还没有看到 AI 系统能够自我提升到导致智能爆炸( intelligence explosion )的程度,但在未来5到10年,这种情况将会改变。
各大 AI 公司和政府 AI 安全部门都在密切关注这⼀领域,构建公共 benchmark 可以帮助大家理解人类距离递归自我提升还有多远,并及时协调和应对。
除了科研线 AIDE , WecoAI 还有一个产品线。
他们马上会发布第⼀个公开测试的产品 AI Function Builder,它能根据自然语言的任务描述生成 AI 功能并提供 API 接口。用户只需通过简单的一行代码或电子表格中的一个公式就能调用这些功能。
就在 OpenAI 公布 MLE-bench 的前几天,2024年诺贝尔化学奖被一分为二:
一半共同授予谷歌 DeepMind CEO Demis Hassabis 和高级研究科学家 John M. Jumper,以表彰他们「在蛋白质结构预测方面的贡献」。
这一殊荣源自享誉全球的 AlphaFold,也标志着诺贝尔奖对 AI 驱动科学发现这一新范式的高度肯定。据悉,学术界许多人将不得不重新编写研究经费申请,重新思考研究方向,尤其是专注于计算蛋白质折叠的研究人员。
蒋铮尧认为,未来将会涌现出更多这样的「低垂果实」,因为 AI 在推动科学研究方面的作用可能是根本性的。从工程师的角度来看,未来人们可能会将更多时间投入到创造性思维、跨领域思想的整合以及深度的逻辑推理上,而将那些重复性的试错过程交由 AI 来完成。
WecoAI 最想做的是培养「 AI 科学家」,让这些 AI 智能体能够自主地形成或融入人类的科学共同体。
开源库链接:https://github.com/WecoAI/aideml
(举报)








发表评论取消回复