声明:本文来自于微信公众号 新智元,作者:新智元,授权热心网友转载发布。
Midjourney之后,从未见人们对某个AI生图应用,如此疯狂着迷。
Flux的横空出世,意味着AI图像生成迈入了一个全新的阶段。
马斯克本人表示,真假已经傻傻分不清。

先是,一张TED演讲者逼真照片席卷了整个互联网。再之后,集成Flux模型的Grok2破除护栏限制,被网友玩疯。
最近,Flux开发者们也纷纷入坑,开启微调自己的LoRA模型。
HuggingFace联创惊叹道,Flux已经完全席卷了开源AI界,从未见过一个模型,同时有如此多的衍生模型/在线平台/demo占据热榜。

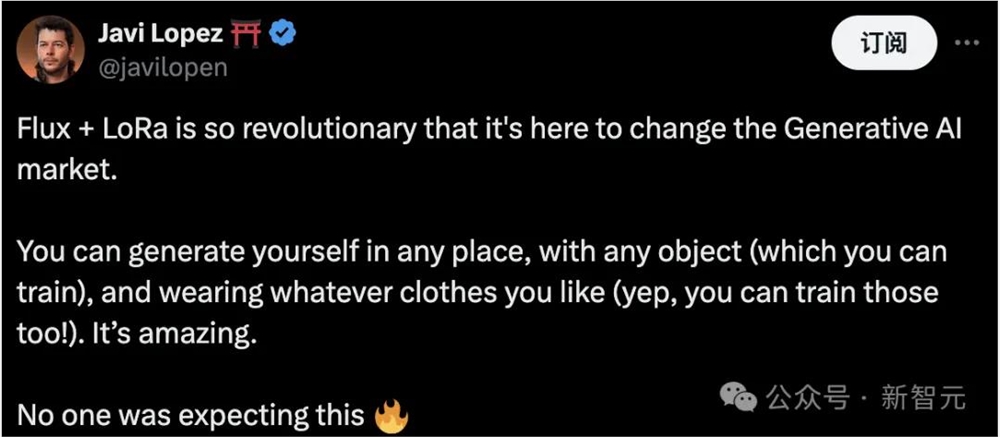
一手微调的开发者表示,「Flux+LoRA将颠覆生成式AI市场。你可以在任何地方,戴着任何东西,穿着任何你喜欢的衣服,生成不同的自己」。
比如,让自己变身超人。

拿上伸缩光影剑,变身绝地武士,愿原力与你同在。

不仅如此,冰雕,拿着switch游戏机,精灵耳,时装走秀等各种形象的照片,都是动动嘴皮子的事。
微调自己的LoRA,现已经成为许多开发者的新玩物。
这不,全网都被Flux+LoRA淹没了。

一个人就能组成「复仇者联盟」
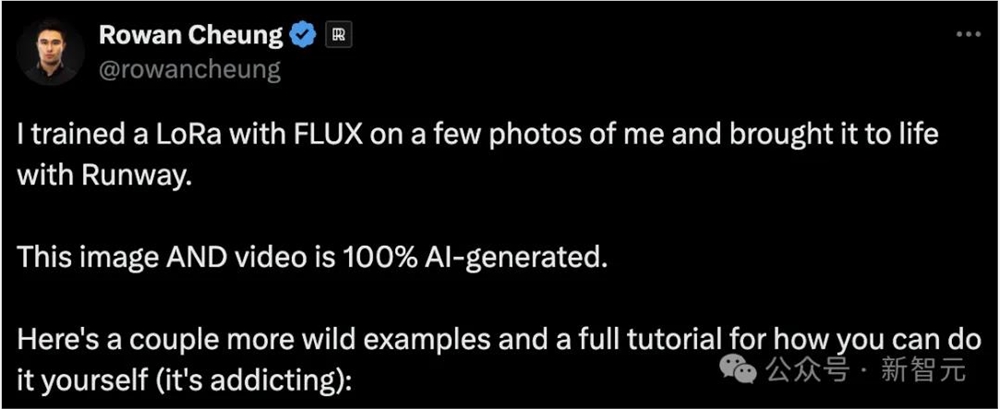
Rundown AI的创始人Rowan Cheung将自己的照片作为数据,用Flux训练了一个LoRA模型,然后联动Runway让其动起来。
如下,生成了一张类似TED演讲者的图片。
做成视频后,照片中的自己真的活灵活现了,很有演讲者范儿。唯一不足的是,右手到后面指头就变成了2-3根。
另一张,生成了以超人身份拯救世界的自己。

配上动画,终于做了一回漫威中的英雄。

再生成一张身穿时装,走秀现场的照片。

两边观众热烈鼓掌,也算是体验了一把T台走秀。

此外,Rowan Cheung还生成了不同风格的自己,和场景融合自洽,毫无违和感。




左右滑动查看
他认为,虽然AI生图依旧不能替代完整的电影/商业广告,但其已经有很多重要的用途,尤其对内容创作者来说。
比如,这些AI图片制作用于新闻的预览图和配图,以及短片中的补充素材(B-roll)。
网友Min Choi看后表示,自己可以组建一支「复仇者联盟」了。

前英特尔CTO在A100上,同样微调了一个自己的LoRA模型,75分钟花费了7美金(约50元)。




左右滑动查看
还有开发者硬是把自己拍成了恐怖片。


分不清AI还是现实
要说最火的,还是「超现实主义」的微调版本——让人越来越分不清想象和现实的边界了。


是真实的照片,还是AI画出来的人?


在Flux-Dev中用LoRA训练后,无论是场景复杂性还是真实感,都取得了不可思议的进展。

什么风格都能微调
除此之外,各种不同风格的微调也层出不穷。
像素风格
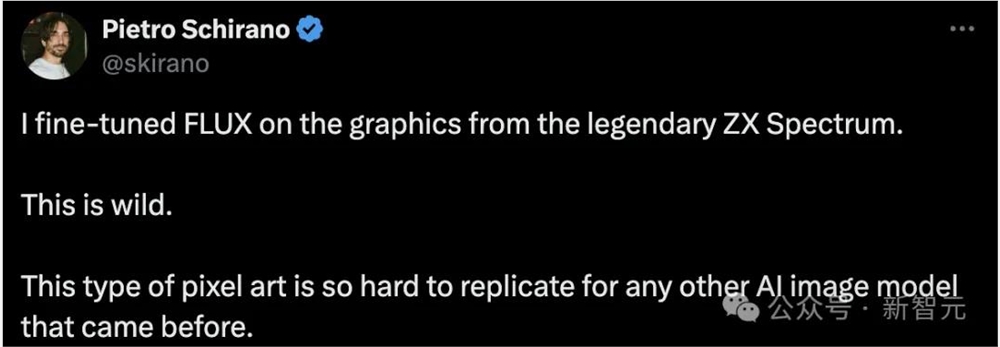
开发者以传奇的ZX Spectrum中的风格为例,微调出类似像素的图片生成LoRA。
下面生成图像中,有龙珠孙悟空、漫威钢铁侠、川建国(貌似)等形象。









左右滑动查看
动画涂鸦
PS生成式AI产品设计人Davis Brown基于Flux,微调出了一个half_illustration模型。
它生成的图片,有一部分是真实照片的画风,一部分是动画涂鸦的风格。

每次生图前,只需要在提示开头加上——In the style of TOK。
然后,具体描述想要的效果,就能立即出片。
以后感觉不一定非得用PS,直接AI生图就可以了。

prompt:In the style of TOK, a photo editorial avant-garde dramatic action pose of a woman short blue hair wearing70s round wacky sunglasses pulling glasses down looking forward, in Tokyo with large marble structures and bonsai trees at sunset with a vibrant illustrated jacket surrounded by illustrations of flowers, smoke, flames, ice cream, sparkles, rock and roll

prompt:In the style of TOK, a photo editorial dramatic action pose of a person piercing eyes, tattoos on face, with creative bucket hat, standing in Tokyo with large marble structures and white purple trees in a Basketball court, with a vibrant illustrated street wear puffy vintage jacket, black shirt, volcano in the background, surrounded by illustrations of smoke, flames, and flowers, fog, exclamation marks, lines shooting outwards, minion characters, butterflies
还有其他涂鸦风格的照片。





左右滑动查看
九宫格
开源数据集平台LAION用Flux模型,训出了一个可以生成3x3九宫格照片,还是不同角度的自己。

以后自拍一张,就够了。



左右滑动查看
不同年龄
一个人一生的样貌,透过Flux+LoRA便可看到。





左右滑动查看
另一个例子:





左右滑动查看
可玩性超强
今天的主角——FLUX.1,采用了一种全新的「流匹配」技术。
以前的扩散模型是通过逐步去除从随机起点开始的噪声来创建图像,而流匹配则采用更直接的方法,学习将噪声转换为真实图像所需的精确变化。
这种方法上的差异带来了独特的美学风格,并在速度和控制方面具备极大的优势。
文本:大部分都能get到
文本到图像生成的挑战之一是准确地将文字转化为视觉表现。FLUX.1在这方面处理得相当好,即使是在像表情包这样复杂的场景中。
prompt:
Thisisfine dog meme underwater. Text: ‘Climate change is fine’
这是一个在水下的「fine dog」表情包。文字:「气候变化问题不大」

prompt:
A meme of a famous actor making a funny face with the text ‘When you forget your lines’ in a quirky font
一位著名演员做鬼脸的表情包,上面用古怪的字体写着「当你忘词的时候」

光线和质感都不错
FLUX.1对光线、阴影和纹理有敏锐的理解,能始终如一地生成高质量的图像。
prompt:
A detailed image of a garden where the flowers are made of delicate glass, reflecting the sunlight beautifully
一个花园的详细图像,其中的花朵由精致的玻璃制成,阳光下反射出美丽的光芒

在这幅图里,重点不仅在于玻璃的质感,还在于光线如何通过花瓣折射和传递,创造出一种发光的效果。
prompt:
Owl feathers merging with autumn leaves in wind
猫头鹰的羽毛与秋叶在风中融合

艺术风格:不止是模仿
FLUX.1似乎掌握了各种艺术风格背后的原理,使得创造性的重新诠释成为可能。
prompt:
watercolor of famous wave painting
著名波浪画的水彩画

这幅《神奈川冲浪里》的「水彩」版本不仅暗示着标志性波浪是模型训练数据的一部分,还突出了「流」技术如何近似颜料在水、纸和墨水中的运动。
构图:让场景有意义
FLUX.1擅长构建复杂的场景,以一种既真实又有视觉吸引力的方式放置物体和角色。
prompt:
A realistic image of an enchanted library where books float in mid-air and the shelves are made of ancient, twisted roots
一个现实主义的魔法图书馆图像,书籍在空中漂浮,书架由古老扭曲的根制成

「流」:一种新的视觉语言
FLUX.1所采用的流匹配技术,赋予了图像一种独特的有机运动感和流动性,仿佛像素本身在流动。
prompt:
Dog with swirling, Van Gogh-style fur patterns
狗身上有旋转的梵高风格的毛发图案

总有一款工具,能帮你搞定
我们可以把图像的生成过程概括为:获取一些输入像素,将它们从噪声中稍微移开,朝着由你的文本输入创建的模式移动,并重复这一过程,直到达到设定的步骤数。
而微调过程则是从数据集中获取每个图像/标注对,并稍微更新其内部映射。
只要可以通过图像-标题对表示,你就可以通过这种方式教会模型任何内容:角色、场景、媒介、风格、流派。

左:使用原始FLUX.1模型生成;右:使用相同提示和种子,在fofr/flux-bad-70s-food模型上生成
在训练中,模型将会学习如何把这些概念与特定的文本字符串关联起来。而在提示中,则需要加入这个字符串来激活这种关联。
比如,你想微调一个「漫画风超级英雄」的模型。
首先,需要收集大量关于角色的图像作为数据集,包括但不限于:不同的场景、服装、灯光,甚至可能是不同的艺术风格
然后,选择一个简短且不常见的词或短语作为你的触发词:一种不会与其他概念或微调冲突的独特内容。你可能会选择像「糟糕的70年代食物」或「JELLOMOLD」这样的词。
在训练完成之后,你只需给出一个包含触发词的提示,如「在旧金山的聚会上拍摄糟糕的70年代食物的场景」,模型就会调用你之前微调时加入的特定概念。
就这么简单。
在了解了原理之后,我们就可以任选一个工具来微调模型了。

左:使用原始FLUX.1模型生成;右:使用相同提示和种子,在fofr/flux-bad-70s-food模型上生成
比如一位叫Matt Wolfe的小哥,在看到上面这些酷炫的生成之后,也好奇地上手试了一把。
结果,他翻车了……
做出的AI图像,堪称买家秀和卖家秀的区别。
这是他生成的——

这是别人的——

两张图片高下立判,区别就在于用没用LoRA微调。
被刺激到的小哥,立刻去研究了一番,他惊喜地发现,LoRA模型很小,只有2到500MB,可以轻易地和现有的模型结合。

更令人惊喜的是,并不需要额外的算力,也不需要全面的再训练,就可以让AI模型提高画质,产生独特的风格,或者生成特殊的人物,比如马里奥或者海绵宝宝。

遗憾的是,在小哥用得顺手的Glif上,Flux中并不能使用LoRA。

他发现,能使用Flux的其中一种方法,是用ComfyUI。

这张图,相信很多人都很熟悉了
或者,也可以使用Replicate、HuggingFace Spaces或Fal AI之类的平台。

小哥在Fal平台上试用后,发现每百万像素花费0.035美元,所以,只要花1美元,就可以运行模型29次,还是比较划算的。

在这里FLUX.1dev、Flux Realism LoRA、FLUX.1pro等等,都是可以使用的。
小哥二话不说,选择了Flux Realism LoRA。
经过精心调试后,小哥将推理步长设置在了28,CFG设置在了2。

产生的图像,效果非常惊喜!
如果说有什么瑕疵,就是额头皱纹处的打光仍然不自然。

接下来,小哥兴奋地将图像导到Gen-3Alpha中,根据他输入的prompt,Gen-3Alpha生成了视频。
除了在某一刻,手中的麦克风突然「飘浮」了起来,视频的其余部分,挑不出太大毛病了。
小哥又尝试了一遍,生成了第二个视频。

这一次,麦克风又显得太过静止了,仿佛定在了原地。
另外,小哥也加入了全网爆改自己的大潮,生成一系列爆笑的照片。


最后,小哥再用Gen-3Alpha把它变成视频,就让自己和死侍走在了同一部电影的画面中。

参考资料:
https://x.com/dr_cintas/status/1824480995317350401
https://x.com/Gorden_Sun/status/1824843049421484309
https://replicate.com/blog/fine-tune-flux
https://x.com/laion_ai/status/1824814210758459548
https://www.youtube.com/watch?v=_rjto4ix3rA
https://www.youtube.com/watch?v=rDu481JFwqM
(举报)








发表评论取消回复