HiveJoin
join_table:
table_reference JOIN table_factor [join_condition] |
table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference
join_condition | table_reference LEFT SEMI JOIN table_reference
join_condition | table_reference CROSS JOIN table_reference
[join_condition]
不同类型的联接:
- JOIN
- LEFT OUTER JOIN
- RIGHT OUTER JOIN
- FULL OUTER JOIN
Hive 只支持等值连接(equality joins)、外连接(outer joins)和(left/right joins)。Hive 不支持所有非等值的连接,因为非等值连接非常难转化到 map/reduce 任务。另外,Hive 支持多于 2 个表的连接。

示例:
表:CUSTOMERS
| ID | NAME | AGE | ADDRESS | SALARY |
|---|---|---|---|---|
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
表:ORDERS
| OID | DATE | CUSTOMER_ID | AMOUNT |
|---|---|---|---|
| 102 | 2009-10-08 00:00:00 | 3 | 3000 |
| 100 | 2009-10-08 00:00:00 | 3 | 1500 |
| 101 | 2009-11-20 00:00:00 | 2 | 1560 |
| 103 | 2008-05-20 00:00:00 | 4 | 2060 |
JOIN
JOIN子句用于合并和检索来自多个表中的记录。 JOIN和SQLOUTER JOIN 类似。连接条件是使用主键和表的外键。
下面的查询执行JOIN的CUSTOMER和ORDER表,并检索记录:
hive> SELECT c.ID, c.NAME, c.AGE, o.AMOUNT
> FROM CUSTOMERS c JOIN ORDERS o
> ON (c.ID = o.CUSTOMER_ID);
成功执行查询后,能看到以下回应:
| ID | NAME | AGE | AMOUNT |
|---|---|---|---|
| 3 | kaushik | 23 | 3000 |
| 3 | kaushik | 23 | 1500 |
| 2 | Khilan | 25 | 1560 |
| 4 | Chaitali | 25 | 2060 |
LEFT OUTER JOIN
HiveQL LEFT OUTER JOIN返回所有行左表,即使是在正确的表中没有匹配。这意味着,如果ON子句匹配的右表0(零)记录,JOIN还是返回结果行,但在右表中的每一列为NULL。 LEFT JOIN返回左表中的所有的值,加上右表,或JOIN子句没有匹配的情况下返回NULL。
hive> SELECT c.ID, c.NAME, o.AMOUNT, o.DATE
> FROM CUSTOMERS c
> LEFT OUTER JOIN ORDERS o
> ON (c.ID = o.CUSTOMER_ID);
成功执行查询后,能看到以下回应:
| ID | NAME | AMOUNT | DATE |
|---|---|---|---|
| 1 | Ramesh | NULL | NULL |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
| 5 | Hardik | NULL | NULL |
| 6 | Komal | NULL | NULL |
| 7 | Muffy | NULL | NULL |
RIGHT OUTER JOIN
HiveQL RIGHT OUTER JOIN返回右边表的所有行,即使有在左表中没有匹配。如果ON子句的左表匹配0(零)的记录,JOIN结果返回一行,但在左表中的每一列为NULL。 RIGHT JOIN返回右表中的所有值,加上左表,或者没有匹配的情况下返回NULL。
hive> SELECT c.ID, c.NAME, o.AMOUNT, o.DATE
> FROM CUSTOMERS c
> RIGHT OUTER JOIN ORDERS o
> ON (c.ID = o.CUSTOMER_ID);
成功执行查询后,能看到以下回应:
| ID | NAME | AMOUNT | DATE |
|---|---|---|---|
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
FULL OUTER JOIN
HiveQL FULL OUTER JOIN结合了左边,并且满足JOIN条件合适外部表的记录。连接表包含两个表的所有记录,或两侧缺少匹配结果那么使用NULL值填补
hive> SELECT c.ID, c.NAME, o.AMOUNT, o.DATE
> FROM CUSTOMERS c
> FULL OUTER JOIN ORDERS o
> ON (c.ID = o.CUSTOMER_ID);
成功执行查询后,能看到以下回应:
| ID | NAME | AMOUNT | DATE |
|---|---|---|---|
| 1 | Ramesh | NULL | NULL |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
| 5 | Hardik | NULL | NULL |
| 6 | Komal | NULL | NULL |
| 7 | Muffy | NULL | NULL |
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
写 join 查询时,需要注意几个关键点:
只支持等值join
eg :
SELECT a.* FROM a JOIN b ON (a.id = b.id)
SELECT a.* FROM a JOIN b
ON (a.id = b.id AND a.department = b.department)
可以join 多于2个表
eg:
SELECT a.val, b.val, c.val FROM a JOIN b
ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
如果join中多个表的 join key 是同一个,则 join 会被转化为单个 map/reduce 任务
eg:
SELECT a.val, b.val, c.val FROM a JOIN b
ON (a.key = b.key1) JOIN c
ON (c.key = b.key1)
被转化为单个 map/reduce 任务,因为 join 中只使用了 b.key1 作为 join key。
eg:
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1)
JOIN c ON (c.key = b.key2)
#join 被转化为 2 个 map/reduce 任务。因为 b.key1 用于第一次 join 条件,而 b.key2 用于第二次 join。
join 时,每次 map/reduce 任务的逻辑
reducer 会缓存 join 序列中除了最后一个表的所有表的记录,再通过最后一个表将结果序列化到文件系统。这一实现有助 于在 reduce 端减少内存的使用量。 实践中,应该把最大的那个表写在最后(否则会因为缓存浪费大量内存)。
eg:
SELECT a.val, b.val, c.val FROM a
JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
'''
所有表都使用同一个 join key(使用 1 次 map/reduce 任务计算)。
Reduce 端会缓存 a 表和 b 表的记录,然后每次取得一个 c 表的记录就计算一次 join 结果
'''
eg:
SELECT a.val, b.val, c.val FROM a
JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
'''
这里用了 2 次 map/reduce 任务。第一次缓存 a 表,用 b 表序列化;
第二次缓存第一次 map/reduce 任务的结果,然后用 c 表序列化。
'''
LEFT,RIGHT 和 FULL OUTER 关键字用于处理 join 中空记录的情况
eg:
SELECT a.val, b.val FROM a LEFT OUTER
JOIN b ON (a.key=b.key)
对应所有 a 表中的记录都有一条记录输出。输出的结果应该是 a.val, b.val,当 a.key=b.key 时,而当 b.key中找不到等值的 a.key 记录时也会输出 a.val, NULL。“FROM a LEFT OUTER JOIN b”这句一定要写在同一行——意思是 a 表在 b 表的左边,所以 a 表中的所有记录都被保留了;“a RIGHT OUTER JOIN b”会保留所有 b 表的记录。OUTER JOIN 语义应该是遵循标准 SQL spec的。
Join 发生在 WHERE 子句之前。如果你想限制 join 的输出,应该在 WHERE 子句中写过滤条件——或是在 join 子句中写。
这里面一个容易混淆的问题是表分区的情况:
eg:
SELECT a.val, b.val FROM a
LEFT OUTER JOIN b ON (a.key=b.key)
WHERE a.ds='2009-07-07' AND b.ds='2009-07-07'
join a 表到 b 表(OUTER JOIN),列出 a.val 和 b.val 的记录。WHERE 从句中可以使用其他列作为过滤条件。但是,如前所述,如果 b 表中找不到对应 a 表的记录,b 表的所有列都会列出 NULL,包括 ds列。也就是说,join 会过滤 b 表中不能找到匹配 a 表 join key 的所有记录。这样的话,LEFT OUTER 就使得查询结果与WHERE 子句无关了。解决的办法是在 OUTER JOIN 时使用以下语法:
eg:
SELECT a.val, b.val FROM a LEFT OUTER JOIN b
ON (a.key=b.key AND
b.ds='2009-07-07' AND
a.ds='2009-07-07')
'''
这一查询的结果是预先在 join 阶段过滤过的,所以不会存在上述问题。这一逻辑也可以应用于 RIGHT 和 FULL 类型的 join 中。
'''
eg:
SELECT a.val1, a.val2, b.val, c.val
FROM a
JOIN b ON (a.key = b.key)
LEFT OUTER JOIN c ON (a.key = c.key)
'''
join a 表到 b 表,丢弃掉所有 join key 中不匹配的记录,然后用这一中间结果和 c 表做 join。
这一表述有一个不太明显的问题,就是当一个 key 在 a 表和 c 表都存在,但是 b 表中不存在的时候:
整个记录在第一次 join,即 a JOIN b 的时候都被丢掉了(包括a.val1,a.val2和a.key),
然后我们再和 c 表 join 的时候,如果 c.key 与 a.key 或 b.key 相等,就会得到这样的结果:
NULL, NULL, NULL, c.val。(不会这样)
'''
LEFT SEMI JOIN 是 IN/EXISTS 子查询的一种更高效的实现。
Hive 当前没有实现 IN/EXISTS 子查询,所以你可以用 LEFT SEMI JOIN 重写你的子查询语句。LEFT SEMI JOIN 的限制是,JOIN 子句中右边的表只能在 ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方过滤都不行。
eg:
SELECT a.key, a.value
FROM a
WHERE a.key in
(SELECT b.key
FROM B);
可以被重写为:
SELECT a.key, a.val
FROM a LEFT SEMI JOIN b on (a.key = b.key)
HSQL中join与left-join区别
Inner Join
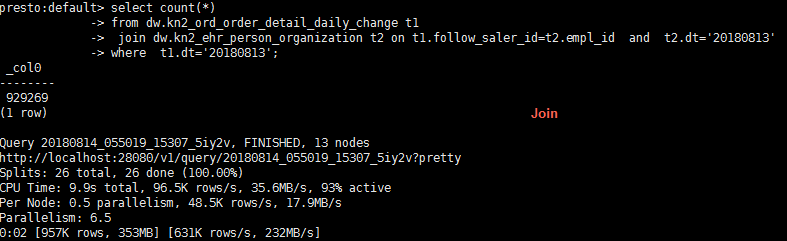
presto:default> select count(*)
-> from dw.kn2_ord_order_detail_daily_change t1
-> join dw.kn2_ehr_person_organization t2 on t1.follow_saler_id=t2.empl_id and t2.dt='20180813'
-> where t1.dt='20180813';
公共部分的数据才会被查询出来;
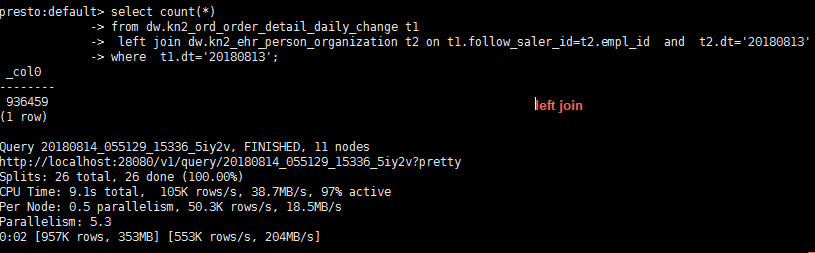
Left Join
presto:default> select count(*)
-> from dw.kn2_ord_order_detail_daily_change t1
-> left join dw.kn2_ehr_person_organization t2 on t1.follow_saler_id=t2.empl_id and t2.dt='20180813'
-> where t1.dt='20180813';
查询出来的结果和前表记录数一样多;
left join on and 与 left join on where的区别
数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户。在使用left jion时,on和where条件的区别如下:
- on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表中的记录
- where条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有left join的含义(必须返回左边表的记录),条件不为真的就全部过滤掉。
示例
表1:tab1
| id | size |
|---|---|
| 1 | 10 |
| 2 | 20 |
| 3 | 30 |
| 4 | 40 |
产生表语句:
create table tab1 as
select 1 as id1,10 as size from dual
union all
select 2 as id1,20 as size from dual
union all
select 3 as id1,30 as size from dual
union all
select 4 as id1,40 as size from dual;
表2:tab2
| size | name |
|---|---|
| 10 | AAA |
| 20 | BBB |
| 30 | CCC |
| 30 | DDD |
| 50 | EEE |
产生表语句:
create table tab2 as
select 10 as size,'AAA' as name from dual
union all
select 20 as size,'BBB' as name from dual
union all
select 30 as size,'CCC' as name from dual
union all
select 30 as size,'DDD' as name from dual
union all
select 50 as size,'EEE' as name from dual;
两条SQL:
select * from tab1 left join tab2 on (tab1.size = tab2.size) where tab2.name='AAA';
select * from tab1 left join tab2 on (tab1.size = tab2.size and tab2.name='AAA');
先看left join on where 选择结果 首先它会关联生成临时表数据;然后在通过where条件进行筛选

接下来我们在分析left join on and处理过程,它的处理过程是先将右侧表以and为条件进行筛选 再和左侧表进行关联查询;最终的结果就是以左侧表为基础 将右侧符合条件的数据置为null 结果如下;

其实以上结果的关键原因就是left join,right join,full join的特殊性,不管on上的条件是否为真都会返回left或right表中的记录,full则具有left和right的特性的并集。而inner jion没这个特殊性,则条件放在on中和where中,返回的结果集是相同的。
left join
presto:default> select t1.id1 ,t1.size,t2.name from tab1 t1 left join tab2 t2 on t1.size=t2.size;
id1 | size | name
-----+------+------
4 | 40 | NULL
3 | 30 | DDD
3 | 30 | CCC
1 | 10 | AAA
2 | 20 | BBB
(5 rows)
right join
presto:default> select t1.id1 ,t1.size,t2.name from tab1 t1 right join tab2 t2 on t1.size=t2.size;
id1 | size | name
------+------+------
2 | 20 | BBB
1 | 10 | AAA
NULL | NULL | EEE
3 | 30 | DDD
3 | 30 | CCC
(5 rows)
join
presto:default> select t1.id1 ,t1.size,t2.name from tab1 t1 join tab2 t2 on t1.size=t2.size;
id1 | size | name
-----+------+------
2 | 20 | BBB
3 | 30 | DDD
3 | 30 | CCC
1 | 10 | AAA
(4 rows)
full join
presto:default> select t1.id1 ,t1.size,t2.name from tab1 t1 full join tab2 t2 on t1.size=t2.size;
id1 | size | name
------+------+------
3 | 30 | DDD
3 | 30 | CCC
1 | 10 | AAA
4 | 40 | NULL
NULL | NULL | EEE
2 | 20 | BBB
(6 rows)
presto:default> select *from tab1;
id1 | size
-----+------
1 | 10
2 | 20
3 | 30
4 | 40
(4 rows)
presto:default> select *from tab2;
size | name
------+------
10 | AAA
20 | BBB
30 | CCC
30 | DDD
50 | EEE
(5 rows)
presto:default> select *from tab1 t1 full join tab2 t2 on t1.size=t2.size;
id1 | size | size | name
------+------+------+------
1 | 10 | 10 | AAA
2 | 20 | 20 | BBB
NULL | NULL | 50 | EEE
3 | 30 | 30 | DDD
3 | 30 | 30 | CCC
4 | 40 | NULL | NULL
(6 rows)
hive (default)> select id1,nvl(t1.size,t2.size) as size,name from tab1 t1 full join tab2 t2 on t1.size=t2.size;
OK
id1 size name
1 10 AAA
2 20 BBB
3 30 DDD
3 30 CCC
4 40 NULL
NULL 50 EEE
检查 逻辑 或 的用法
产生表语句:
create table tab3 as
select t1.id1 ,t1.size,t2.name from tab1 t1 full join tab2 t2 on t1.size=t2.size
| id1 | size | name |
|---|---|---|
| 3 | 30 | DDD |
| 3 | 30 | CCC |
| 1 | 10 | AAA |
| 4 | 40 | NULL |
| NULL | NULL | EEE |
| 2 | 20 | BBB |
create table tab4 as
select id1,size,name from tab3
union all
select 99 as id1,null as size,'TTT' as name from dual
union all
select 8 as id1,null as size,'HHH' as name from dual
union all
select null as id1,76 as size,'HHH' as name from dual
;
| id1 | size | name |
|---|---|---|
| 1 | 10 | AAA |
| 2 | 20 | BBB |
| 3 | 30 | DDD |
| 3 | 30 | CCC |
| 4 | 40 | NULL |
| NULL | NULL | EEE |
| 99 | NULL | TTT |
| 8 | NULL | HHH |
| NULL | 76 | HHH |
presto:default> select *from tab4 where id1 is not null or size is not null;
id1 | size | name
------+------+------
1 | 10 | AAA
2 | 20 | BBB
3 | 30 | DDD
3 | 30 | CCC
4 | 40 | NULL
99 | NULL | TTT
8 | NULL | HHH
NULL | 76 | HHH
(8 rows)
Union all 与Union 的区别
使用DISTINCT关键字与使用UNION 默认值效果一样,都会删除重复行
使用ALL关键字,不会删除重复行,结果集包括所有SELECT语句的匹配行(包括重复行)
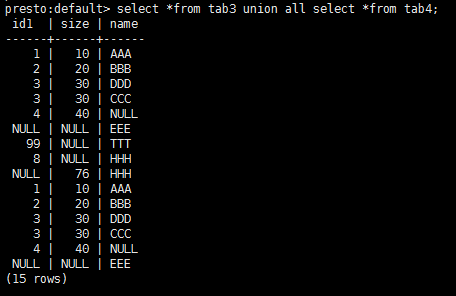
操作 tab3 和 tab4 Union all
操作语句:
select *from tab3 union all select *from tab4;
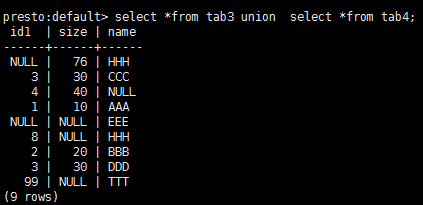
操作 tab3 和 tab4 Union
操作语句:
select *from tab3 union all select *from tab4;
最后
以上就是强健板栗最近收集整理的关于HiveJoin操作HiveJoinHSQL中join与left-join区别left join on and 与 left join on where的区别的全部内容,更多相关HiveJoin操作HiveJoinHSQL中join与left-join区别left内容请搜索靠谱客的其他文章。








发表评论 取消回复