hive超大数据量优化
- hive超大数据量优化:
- 原理:
- 实现:
hive超大数据量优化:
原理:
左表关联字段key使用随机函数拼接n个整数,打散key,减少每个key生成reduce的个数,右表翻n倍,关联后产生大量key的reduce被分散到n个reduce里面。
实现:
使用随机函数rand(),实例为int(round(rand()))随机生成0和1整数,
左表(总数据量n)关联字段拼接随机数0-1两个,concat(a.nameid,int(round(rand()))),
右表数据量翻1倍(关联字段nameid数据a拼接0为a0(总数据量n),a拼接1为a1(总数据量2n)),on后面的关联为on concat(a.nameid,int(round(rand()))) = b.nameid
--创建测试表
create table test_db.table_test_a(num int,nameid string);
create table test_db.table_test_b(nameid string,name string);
--插入测试表数据 左表
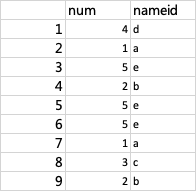
insert into test_db.table_test_a values(1,'a'),(1,'a'),(2,'b'),(2,'b'),(3,'c'),(4,'d'),(5,'e'),(5,'e'),(5,'e');
select * from test_db.table_test_a;
--插入测试表数据 右表
insert into test_db.table_test_b values('a','A'),('b','B'),('c','C'),('d','D'),('e','E');
select * from test_db.table_test_b;

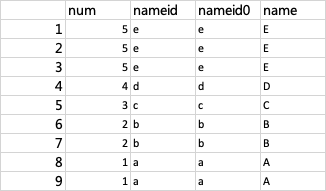
--正常左关联
select * from test_db.table_test_a a
left join test_db.table_test_b b
on a.nameid = b.nameid;
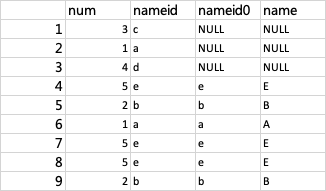
select * from test_db.table_test_a a
left join test_db.table_test_b b
on concat(a.nameid,int(round(rand()))) = concat(b.nameid,int(round(rand())));
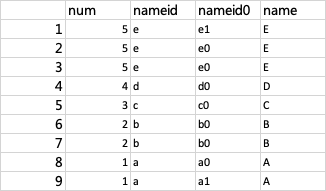
create table test_db.table_test_c(nameid string,name string);
insert into test_db.table_test_c values('a0','A'),('b0','B'),('c0','C'),('d0','D'),('e0','E');
insert into test_db.table_test_c values('a1','A'),('b1','B'),('c1','C'),('d1','D'),('e1','E');
select * from test_db.table_test_c;

select * from test_db.table_test_a a
left join test_db.table_test_c b
on concat(a.nameid,int(round(rand()))) = b.nameid;
最后
以上就是沉静小天鹅最近收集整理的关于hive优化实战的全部内容,更多相关hive优化实战内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复