链接:https://muxuezi.github.io/posts/7-dimensionality-reduction-with-pca.html
官网链接:
1.PCA:
PCA(principal component analysis,主成分分析):主要解决三类问题:
1.降维可以缓解维度灾难问题;
2.降维可以在压缩数据的同时让信息损失最小化;
3.理解几百个维度的数据结构很困难,两三个维度的数据通过可视化更容易理解
主成分分析也称为卡尔胡宁-勒夫变换(Karhunen-Loeve Transform),是一种用于探索高维数据结构的技术。PCA通常用于高维数据集的探索与可视化。还可以用于数据压缩,数据预处理等。PCA可以把可能具有相关性的高维变量合成线性无关的低维变量,称为主成分( principal components)。
新的低维数据集会经可能的保留原始数据的变量。
PCA将数据投射到一个低维子空间实现降维。例如,二维数据集降维就是把点投射成一条线,数据集的每个样本都可以用一个值表示,不需要两个值。三维数据集可以降成二维,就是把变量映射成一个平面。一般情况下, 维数据集可以通过映射降成 维子空间,
2.相关术语:
方差和协方差:
方差(Variance)是度量一组数据分散的程度。方差是各个样本与样本均值的差的平方和的均值;
协方差(Covariance)是度量两个变量的变动的同步程度,也就是度量两个变量线性相关性程度。
如果两个变量的协方差为0,则统计学上认为二者线性无关。注意两个无关的变量并非完全独立,只是没有线性相关性而已。
如果协方差不为0,如果大于0表示正相关,小于0表示负相关。当协方差大于0时,一个变量增大是另一个变量也会增大。当协方差小于0时,一个变量增大是另一个变量会减小。
协方差矩阵(Covariance matrix)由数据集中两两变量的协方差组成。 numpy.cov()
特征向量和特征值:
特征向量(eigenvector)是一个矩阵的满足如下公式的非零向量:
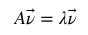
其中,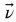 是特征向量, A是方阵,
是特征向量, A是方阵,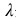 是特征值。经过 变换之后,特征向量的方向保持不变,只是其大
是特征值。经过 变换之后,特征向量的方向保持不变,只是其大
小发生了特征值倍数的变化。也就是说,一个特征向量左乘一个矩阵之后等于等比例放缩(scaling)特征向量。
特征向量和特征值只能由方阵得出,且并非所有方阵都有特征向量和特征值。如果一个矩阵有特征向
量和特征值,那么它的每个维度都有一对特征向量和特征值。
矩阵的主成分是其协方差矩阵的特征向量,按照对应的特征值大小排序。最大的特征值就是第一主成分,第二大的特征值就是第二主成分,
以此类推。
2.PCA求解过程:
2.1 一般做法:
def pca_m (dataMat, topNfeat=999999):
meanVals = mean(dataMat, axis=0)
DataAdjust = dataMat - meanVals #减去平均值
covMat = cov(DataAdjust, rowvar=0)
eigVals,eigVects = linalg.eig(mat(covMat)) #计算特征值和特征向量
print('特征值:{}n特征向量:{}'.format(eigVals,eigVects))
eigValInd = argsort(eigVals)
eigValInd = eigValInd[:-(topNfeat+1):-1] #保留最大的前K个特征值
redEigVects = eigVects[:,eigValInd] #对应的特征向量
lowDDataMat = DataAdjust * redEigVects #将数据转换到低维新空间
reconMat = (lowDDataMat * redEigVects.T) + meanVals #重构数据,用于调试
return lowDDataMat, reconMat
dataMat=array([[0.9,1],[2.4,2.6],[1.2,2.7],[0.5,0.7],[0.3,0.7],[1.8,1.4],[0.5,0.6],[0.3,0.6],[2.5,2.6],[1.3,1.1]])
lowDMat, reconMat = pca_m(dataMat,2)
#输出结果:
lowDMat, reconMat = pca_m(dataMat,2)
特征值:[ 0.0490834 1.28402771]
特征向量:[[-0.73517866 -0.6778734 ]
[ 0.6778734 -0.73517866]]
lowDMat
Out[175]:
matrix([[-0.82797019, -0.17511531],
[ 1.77758033, 0.14285723],
[-0.99219749, 0.38437499],
[-0.27421042, 0.13041721],
[-1.67580142, -0.20949846],
[-0.9129491 , 0.17528244],
[ 0.09910944, -0.3498247 ],
[ 1.14457216, 0.04641726],
[ 0.43804614, 0.01776463],
[ 1.22382056, -0.16267529]])2.2 sklearn pca求法:
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
reduced_X = pca.fit_transform(dataMat)
#结果:
print('特征值:{}n特征向量:{}'.format(pca.explained_variance_,pca.components_))
特征值:[ 1.15562494 0.04417506]
特征向量:[[-0.6778734 -0.73517866]
[ 0.73517866 -0.6778734 ]]
reduced_X
Out[184]:
array([[-0.82797019, 0.17511531],
[ 1.77758033, -0.14285723],
[-0.99219749, -0.38437499],
[-0.27421042, -0.13041721],
[-1.67580142, 0.20949846],
[-0.9129491 , -0.17528244],
[ 0.09910944, 0.3498247 ],
[ 1.14457216, -0.04641726],
[ 0.43804614, -0.01776463],
[ 1.22382056, 0.16267529]])
上面两种方法得到的特征向量和主成分中第二成分方向不同,不过重构后结果都是一样的。
为什么不同?及不同有什么影响?(仍想不通)
3.一些应用例子:
3.1.用PCA实现高维数据可视化
二维或三维数据更容易通过可视化发现模式。一个高维数据集是无法用图形表示的,但是我们可以通
过降维方法把它降成二维或三维数据来可视化。
Fisher1936年收集了三种鸢尾花分别50个样本数据(Iris Data):Setosa、Virginica、Versicolour。
解释变量是花瓣(petals)和萼片(sepals)长度和宽度的测量值,响应变量是花的种类。鸢尾花数
据集经常用于分类模型测试,scikit-learn中也有。让我们把iris数据集降成方便可视化的二维数
据:
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
#PCA类把主成分的数量作为超参数,和其他估计器一样,PCA也用fit_transform()返回降维的数据矩阵
data = load_iris()
y = data.target
X = data.data
pca = PCA(n_components=2)
reduced_X = pca.fit_transform(X)
#把图形画出来
red_x, red_y = [], []
blue_x, blue_y = [], []
green_x, green_y = [], []
for i in range(len(reduced_X)):
if y[i] == 0:
red_x.append(reduced_X[i][0])
red_y.append(reduced_X[i][1])
elif y[i] == 1:
blue_x.append(reduced_X[i][0])
blue_y.append(reduced_X[i][1])
else:
green_x.append(reduced_X[i][0])
green_y.append(reduced_X[i][1])
plt.scatter(red_x, red_y, c='r', marker='x')
plt.scatter(blue_x, blue_y, c='b', marker='D')
plt.scatter(green_x, green_y, c='g', marker='.')
plt.show() 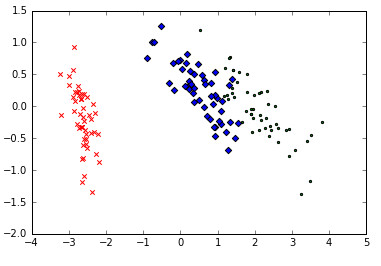
降维的数据如上图所示。每个数据集中三个类都用不同的符号标记。从这个二维数据图中可以明显看
出,有一个类与其他两个重叠的类完全分离。这个结果可以帮助我们选择分类模型。
3.2 PCA人脸识别
脸部识别是一个监督分类任务,用于从照片中认出某个人。本例中,我们用剑桥大学AT&T实验室的Our Database of Faces数据集(http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html),这个数据集包含40个人每个人10张照片。这些照片是在不同的光照条件下拍摄的,每张照片的表情也不同。照片都是黑白的,尺寸为92 x 112像素。虽然这些图片都不大,但是每张图片的按像素强度排列的特征向量也有10304维。这些高维数据的训练可能需要很多样本才能避免拟合过度。而我们样本量并不大,所有我们用
PCA计算一些主成分来表示这些照片。
可以把照片的像素强度矩阵转换成向量,然后用所有的训练照片的向量建一个矩阵。每个照片都是数据集主成分的线性组合。在脸部识别理论中,这些主成分称为特征脸(eigenfaces)。特征脸可以看成是脸部的标准化组成部分。数据集中的每张脸都可以通过一些标准脸的组合生成出来,或者说是最重要的特征脸线性组合的近似值。
from os import walk, path
import numpy as np
import mahotas as mh
from sklearn.cross_validation import train_test_split
from sklearn.cross_validation import cross_val_score
from sklearn.preprocessing import scale
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
X = []
y = []
#把照片导入Numpy数组,然后把它们的像素矩阵转换成向量:
for dir_path, dir_names, file_names in walk('mlslpic/att-faces/'):
for fn in file_names:
if fn[-3:] == 'pgm':
image_filename = path.join(dir_path, fn)
X.append(scale(mh.imread(image_filename, as_grey=True).reshape(10304).astype('float32')))
y.append(dir_path)
X = np.array(X)
#用交叉检验建立训练集和测试集,在训练集上用PCA
X_train, X_test, y_train, y_test = train_test_split(X, y)
pca = PCA(n_components=150)
#把所有样本降到150维,然后训练一个逻辑回归分类器。数据集包括40个类;scikit-learn底层会自动用one versus all策略创建二元分类器:
X_train_reduced = pca.fit_transform(X_train)
X_test_reduced = pca.transform(X_test)
print('训练集数据的原始维度是:{}'.format(X_train.shape))
print('PCA降维后训练集数据是:{}'.format(X_train_reduced.shape))
classifier = LogisticRegression()
accuracies = cross_val_score(classifier, X_train_reduced, y_train)
#结果
训练集数据的原始维度是:(300, 10304)
PCA降维后训练集数据是:(300, 150)
#最后,用交叉验证和测试集评估分类器的性能。分类器的平均综合评价指标(F1 score)是0.88,但是需要花费更多的时间训练,在更多训练实例的应用中可能会更慢。
print('交叉验证准确率是:{}n{}'.format(np.mean(accuracies), accuracies))
classifier.fit(X_train_reduced, y_train)
predictions = classifier.predict(X_test_reduced)
print(classification_report(y_test, predictions))
#结果
交叉验证准确率是:0.823104855161
[ 0.84210526 0.79 0.8372093 ]
precision recall f1-score support
mlslpic/att-faces/s1 1.00 1.00 1.00 1
mlslpic/att-faces/s10 1.00 1.00 1.00 2
mlslpic/att-faces/s11 1.00 0.83 0.91 6
mlslpic/att-faces/s12 1.00 1.00 1.00 2
mlslpic/att-faces/s13 1.00 1.00 1.00 3
mlslpic/att-faces/s14 0.33 1.00 0.50 2
mlslpic/att-faces/s15 1.00 1.00 1.00 4
mlslpic/att-faces/s17 1.00 1.00 1.00 2
mlslpic/att-faces/s18 1.00 1.00 1.00 2
mlslpic/att-faces/s19 1.00 1.00 1.00 2
mlslpic/att-faces/s2 0.00 0.00 0.00 0
mlslpic/att-faces/s20 1.00 1.00 1.00 2
mlslpic/att-faces/s21 1.00 1.00 1.00 3
mlslpic/att-faces/s22 1.00 1.00 1.00 3
mlslpic/att-faces/s23 1.00 1.00 1.00 1
mlslpic/att-faces/s24 1.00 1.00 1.00 3
mlslpic/att-faces/s25 1.00 1.00 1.00 4
mlslpic/att-faces/s26 1.00 1.00 1.00 4
mlslpic/att-faces/s27 1.00 1.00 1.00 3
mlslpic/att-faces/s28 0.00 0.00 0.00 1
mlslpic/att-faces/s29 1.00 0.50 0.67 2
mlslpic/att-faces/s3 1.00 1.00 1.00 3
mlslpic/att-faces/s30 1.00 1.00 1.00 3
mlslpic/att-faces/s31 0.75 1.00 0.86 3
mlslpic/att-faces/s32 1.00 0.75 0.86 4
mlslpic/att-faces/s33 0.00 0.00 0.00 1
mlslpic/att-faces/s34 0.75 1.00 0.86 3
mlslpic/att-faces/s35 1.00 1.00 1.00 2
mlslpic/att-faces/s36 0.50 1.00 0.67 1
mlslpic/att-faces/s37 1.00 0.17 0.29 6
mlslpic/att-faces/s38 1.00 1.00 1.00 2
mlslpic/att-faces/s39 1.00 1.00 1.00 2
mlslpic/att-faces/s4 1.00 1.00 1.00 1
mlslpic/att-faces/s40 0.00 0.00 0.00 1
mlslpic/att-faces/s5 0.80 0.80 0.80 5
mlslpic/att-faces/s6 1.00 1.00 1.00 2
mlslpic/att-faces/s7 1.00 1.00 1.00 2
mlslpic/att-faces/s8 1.00 1.00 1.00 4
mlslpic/att-faces/s9 1.00 1.00 1.00 3
avg / total 0.93 0.88 0.88 100
最后
以上就是可靠枫叶最近收集整理的关于python sklearn-07:降维-PCA的全部内容,更多相关python内容请搜索靠谱客的其他文章。








发表评论 取消回复