主要技术:Mfcc+GMM
达到目的 : 识别音频中说话人的性别是男还是女的效果
项目的来源:国外(数据集是谷歌的,讲解资料来源于印度的两个哥们)
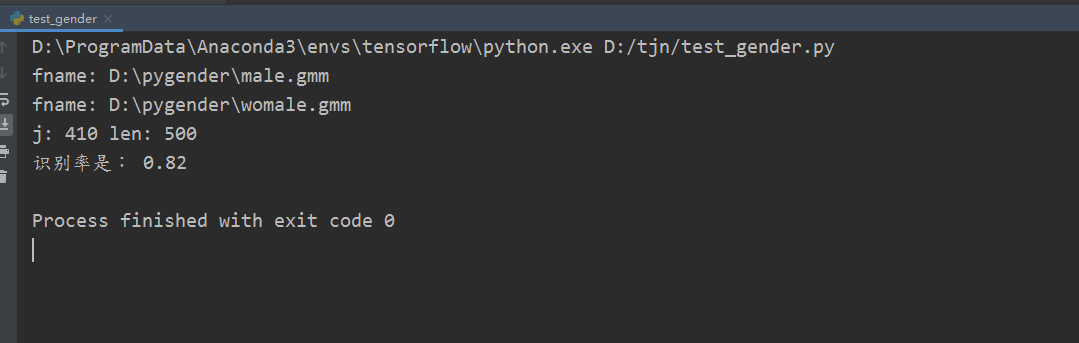
不足:识别率不高;男性大概是82%左右,女性是90%
数据集下载的地址://download.csdn.net/download/tian_jiangnan/12251687
代码讲解
第一部分、先后训练男、女模型
以下代码运行两次,第一次是source="D:\pygender\train\male" 第二次是source="D:\pygender\train\womale"
这个代码就是提取某类性别的音频的mfcc特征,然后注入GMM中生成模型就可以了;代码重点在于提取mfcc特征
import os
import pickle
import numpy as np
from scipy.io.wavfile import read
from sklearn.mixture import GaussianMixture
import python_speech_features as mfcc
from sklearn import preprocessing
import warnings
warnings.filterwarnings("ignore")
def get_Mfcc(sr,audio):
features=mfcc.mfcc(audio,sr,0.025,0.01,13,appendEnergy=False)
features=preprocessing.scale(features)
return features
#path to training data
source="D:\pygender\train\male"
##source="D:\pygender\train\male" 训练男的模型以后,再训练女的模型;
dest="D:\pygender\"
##如果有.wav文件那么就获取它的文件路径
files=[os.path.join(source,f) for f in os.listdir(source) if f.endswith('.wav')]
features=np.asarray(());
for f in files:
sr,audio=read(f)
vector=get_Mfcc(sr,audio)
if features.size==0:
features=vector
else:
features=np.vstack((features,vector))
#GMM模型
gmm=GaussianMixture(n_components=8,covariance_type='diag',max_iter=200,n_init=3)
gmm.fit(features)
#获取male这个名称
picklefile=source.split("\")[-1]+".gmm"
#写模型
pickle.dump(gmm,open(dest+picklefile,'wb'))
两次运行结束以后;会生成.gmm文件
现在运行测试文件
可以先检测测试集中女性的识别率,如果男女音频都放在一起,就很难看得出来检测的识别率的高低
import os
import pickle
import numpy as np
from scipy.io.wavfile import read
import python_speech_features as mfcc
from sklearn import preprocessing
import warnings
warnings.filterwarnings("ignore")
def get_Mfcc(sr,audio):
features=mfcc.mfcc(audio,sr,0.025,0.01,13,appendEnergy=False)
features=preprocessing.scale(features)
return features
##path to testing data
sourcepath="D:\pygender\test\womale"
##sourcepath="D:\pygender\test\male"
realsex=sourcepath.split("\")[-1]
#path to saved models
modelpath="D:\pygender\"
j=0
gmm_files=[os.path.join(modelpath,fname) for fname in os.listdir(modelpath) if fname.endswith('.gmm')]
models=[pickle.load(open(fname,'rb')) for fname in gmm_files]
for fname in gmm_files:
print("fname:",fname)
genders=[fname.split("\")[-1].split(".gmm")[0] for fname in gmm_files]
files=[os.path.join(sourcepath,f) for f in os.listdir(sourcepath) if f.endswith('.wav')]
for f in files:
sr,audio=read(f)
features=get_Mfcc(sr,audio)
scores=None
##2个模型,所以长度是2
log_likelihood=np.zeros(len(models))
##循环加载这两个模型
for i in range(len(models)):
gmm=models[i]
##求概率
scores=np.array(gmm.score(features).reshape(1,-1))
log_likelihood[i]=scores.sum()
winner=np.argmax(log_likelihood)
if (realsex==genders[winner]):
j = j + 1
print("j:",j,"len:",len(files))
print("识别率是:",j/len(files))女性识别率到达90%,
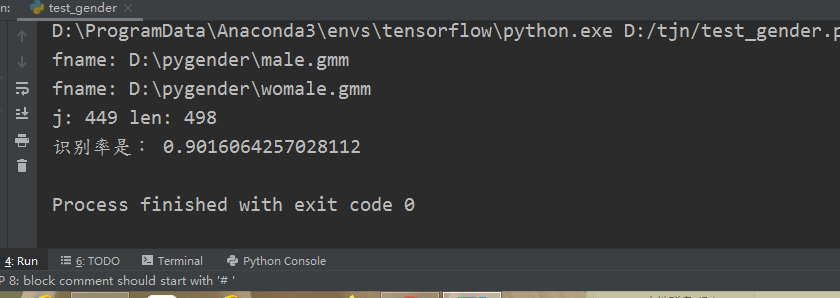
但是男性仅仅达到82%而已 ;官方教程中也是如此,对女性声音辨识度高
我找了的mfcc+GMM性别识别的代码是一模一样的,但是当你运行测试的时候,就会出现一种很奇怪的现象,男性一般高达90%多;女性只能达到12%;很极端的现象,后来我做了15次实验发现,测试里面的提取mfcc特征代码不对,我也不知道那些得出结果的博主们是怎么实现的?
我做了16次实验,不断的改变参数,改变代码,才发现提取mfcc特征的代码不对,不用担心,我提供的代码都是修正过后的!


最后
以上就是愤怒蚂蚁最近收集整理的关于Mfcc+GMM训练性别检测器模型,达到识别音频性别的效果的全部内容,更多相关Mfcc+GMM训练性别检测器模型,达到识别音频性别内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复