循环神经网络(RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络(recursive neural network)。循环神经网络具有记忆性、参数共享并且图灵完备(Turing completeness),因此在对序列的非线性特征进行学习时具有一定优势。
一般的神经网络,在训练数据足够、算法模型优越的情况下,给定输入,就能得到期望的输出。其前一个输入和后一个输入无关,输出只取决于当前输入。但实际应用中,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。 这时就要用到RNN网络,它的输出就依赖于当前的输入和记忆。
eg.当人们在理解一句话的意思时,孤立的理解这句话中的每个词是不够的,我们需要关注词语之间的顺序和联系,将所有词语看成一个完整的序列来进行理解。
RNN基本结构
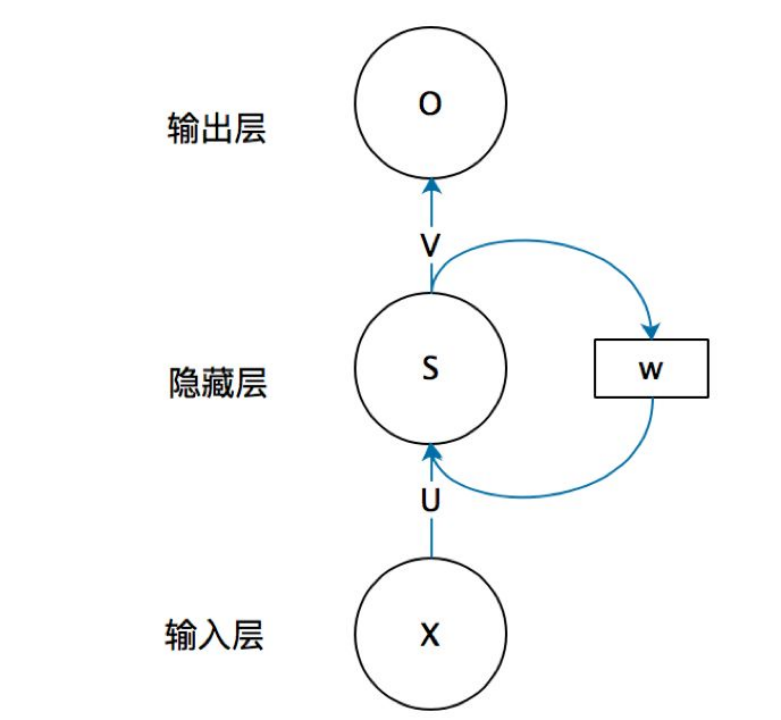
如上图所示,为RNN的基本结构,x是输入向量,它表示输入层的值。s是一个隐层向量,它表示隐层的值(隐层有多个节点,节点数与向量s的维度相同)。o是输出向量,它表示输出层的值。U是输入层到隐藏层的权重矩阵。V是隐藏层到输出层的权重矩阵。循环神经网络的隐层的值s不仅仅取决于当前的输入x,还取决于上一次隐层的值s。权重矩阵 W就是隐层上一次的值作为这一次的输入的权重。
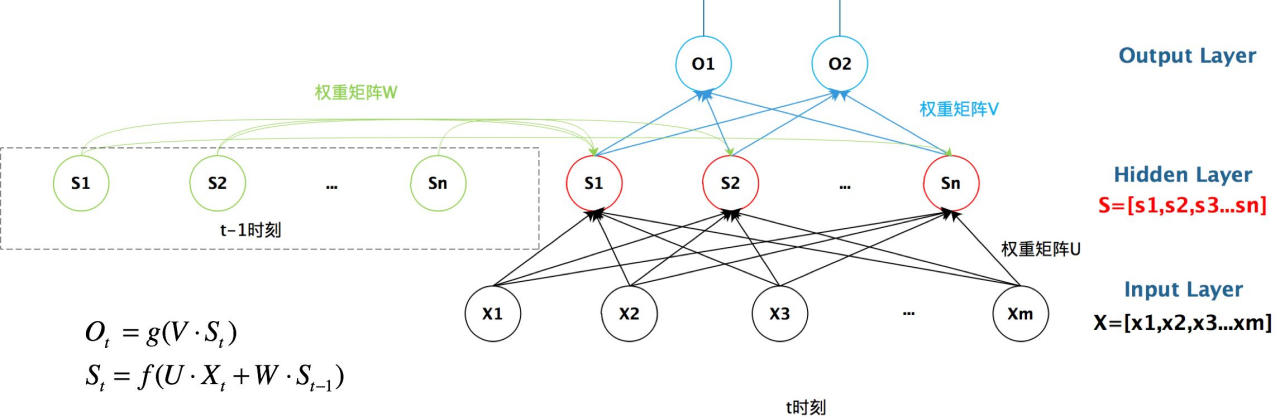
更详细如上图所示。t时刻的隐层向量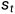 由当前t时刻的输入向量
由当前t时刻的输入向量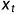 和前一时刻t-1的隐层向量
和前一时刻t-1的隐层向量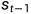 同时决定。
同时决定。
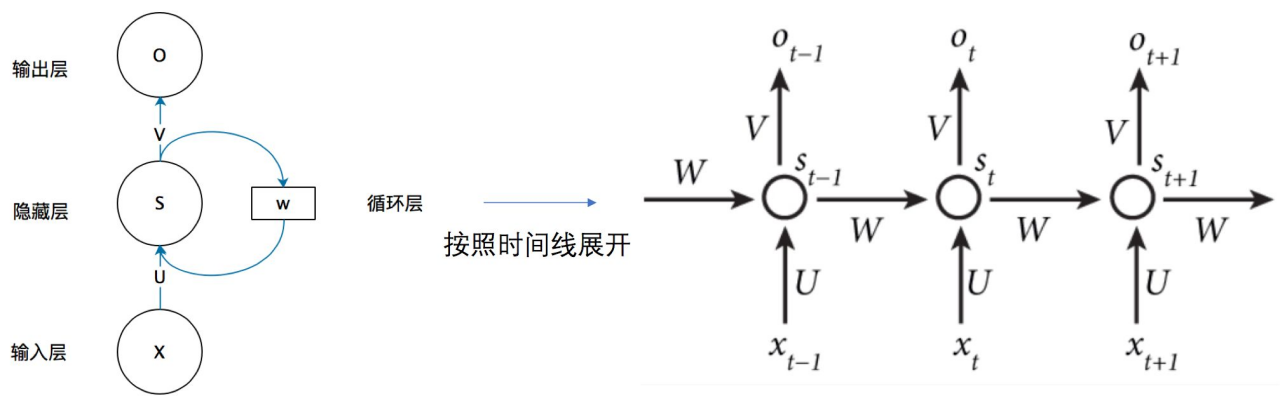
按时间线展开,如上图所示,对应的输出为:
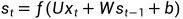
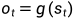
其中f常为tanh函数,g为softmax函数。
RNN工作流程
首先,将单词或词语转换成机器可读的向量,RNN逐个处理向量。
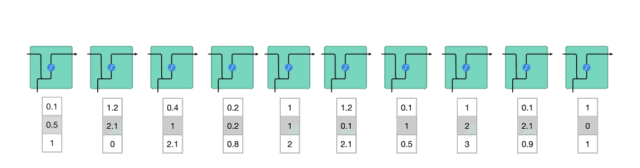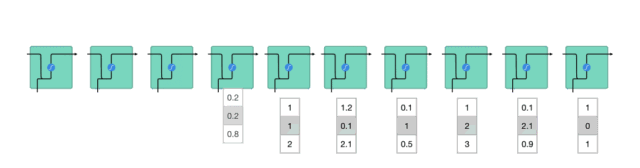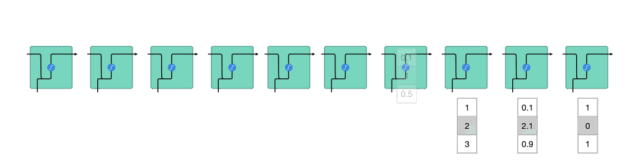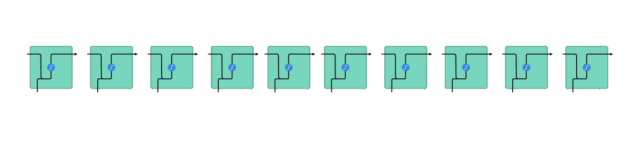
在处理过程中,它将前一个隐藏状态传递给序列的下一个步骤,隐藏状态充当神经网络存储器,它保存网络以前看到的数据的信息。
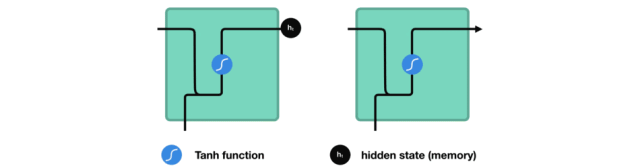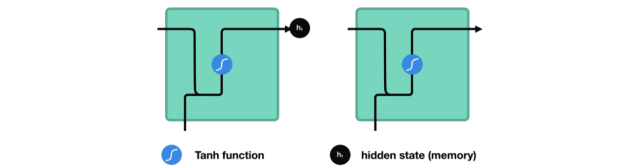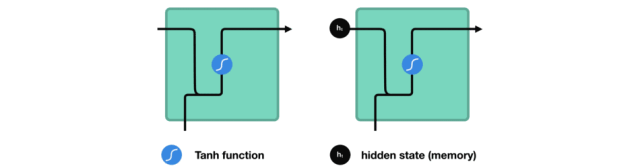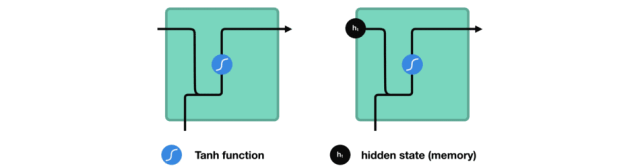
如何来计算隐藏状态?首先,将输入向量和前一时刻的隐藏状态向量组合成一个向量。这个向量和当前输入和以前输入的信息均有关。该向量经过tanh激活,输出新的向量,即当前时刻的隐藏状态向量,同时也是网络的记忆。
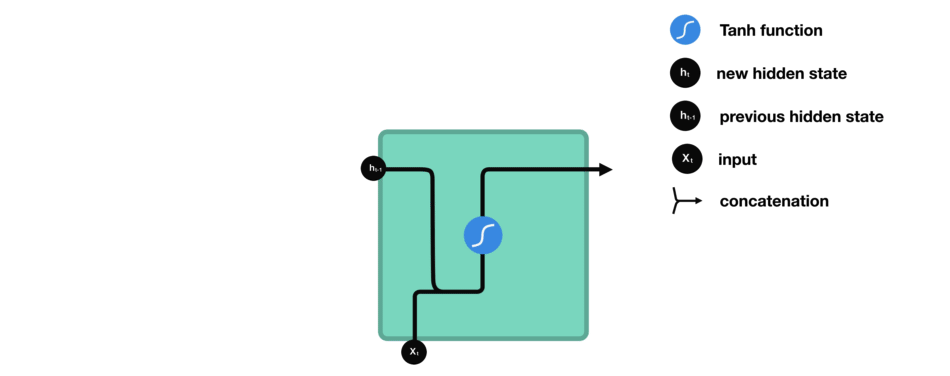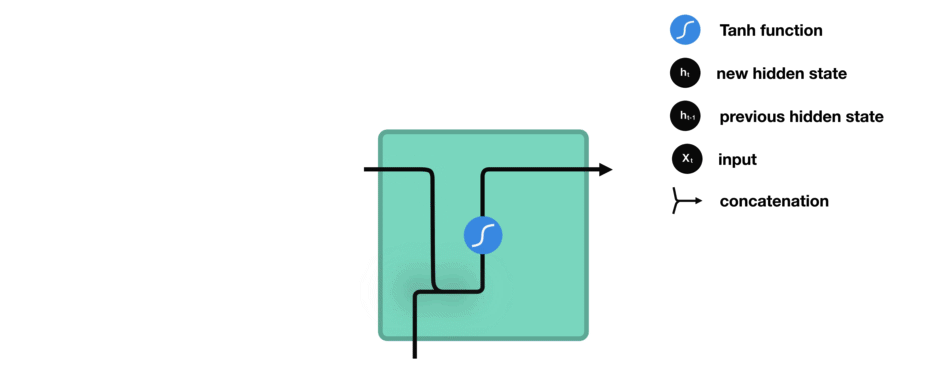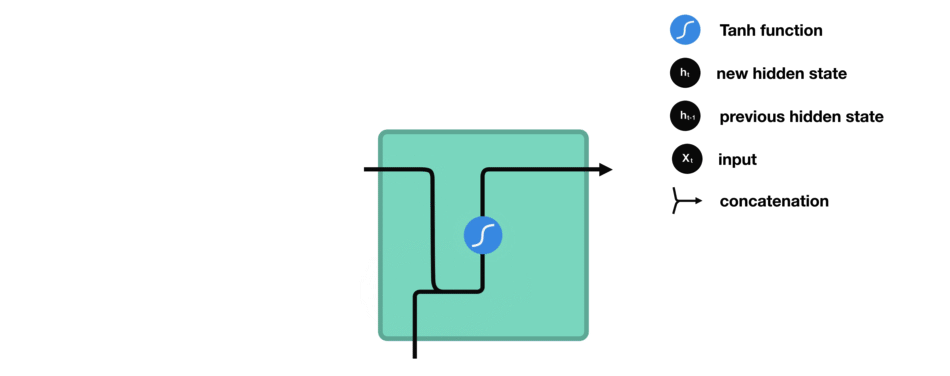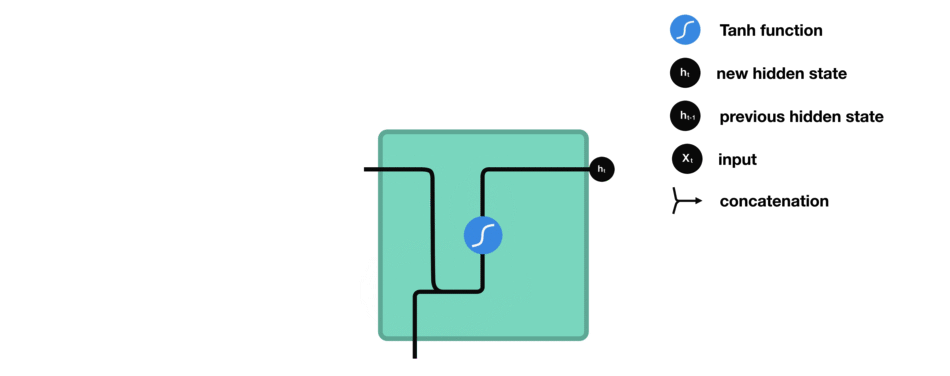
tanh激活函数用于调节流经网络的值,tanh函数压缩后值在-1和1之间。
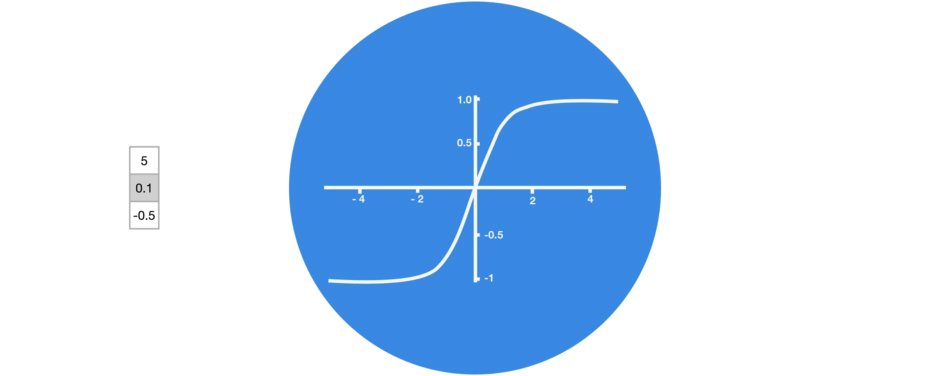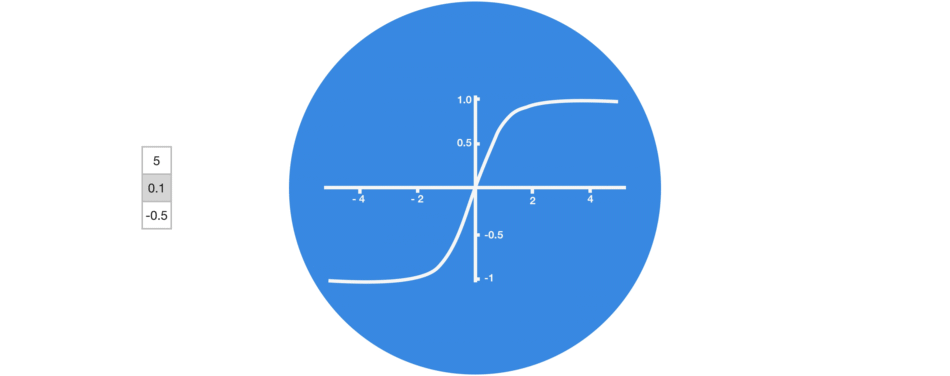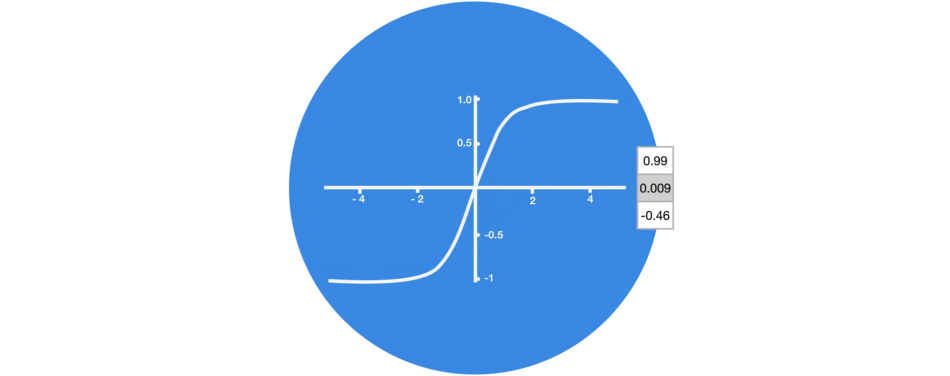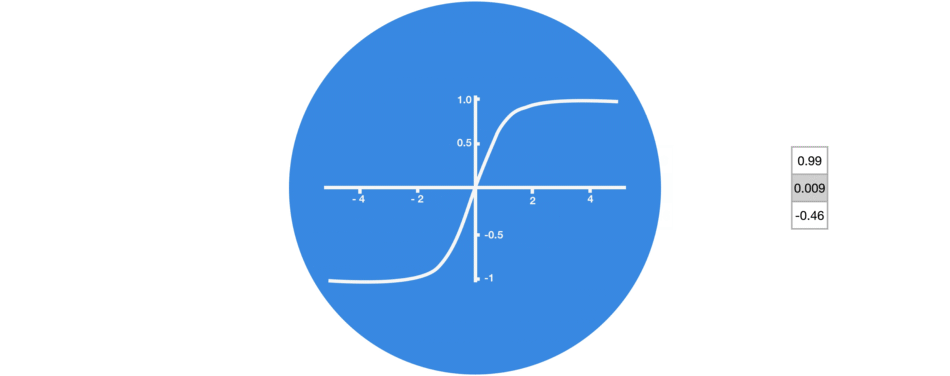
多层tanh激活函数的处理:

RNN网络,在时间上是串联关系,离当前时间越远的隐藏层的输出,对当前隐藏层的输出影响越小。RNN无法根据不同词本身的重要性来对当前的输出产生影响。
RNN对所有输入具有同等的特征提取的能力,对于一句话中的所有单词,都会提取他们的特征 ,并作为下一特征的输入。也就是说RNN网络,记住了所有的信息,并没有区分哪些是有用信息,哪些是无用信息,哪些是辅助信息。
然而,实际语言文字中,不同单词虽然有特征,但对目标的作用是不同的,有些词,对于最终的目标,其实没有任何意义,就是修饰词而已。而有些词的特征,起着决定性对的作用,这些词,就需要通篇文章范围内进行记忆,也就是说,不同词的重要性,不仅仅取决于词之间的物理距离,而且取决于词本身的意义。
梯度消失问题
梯度消失的原因:sigmoid函数的导数范围是(0,0.25],tanh函数的导数范围是(0,1],它们的导数最大都不大于1,如果取tanh或sigmoid函数作为激活函数嵌套到RNN中,那么反向传播的过程中必然是一堆小数在做乘法,结果就是越乘越小。随着时间序列的不断深入,小数的累乘就会导致梯度越来越小直到接近于0,这就是“梯度消失“现象。
实际使用中,会优先选择tanh函数,原因是tanh函数相对于sigmoid函数来说梯度较大,收敛速度更快且引起梯度消失更慢。
解决RNN中的梯度消失方法主要有:
1.选取更好的激活函数,如Relu激活函数。ReLU函数的左侧导数为0,右侧导数恒为1,这就避免了梯度消失的发生。但恒为1的导数容易导致梯度爆”,但设定合适的阈值可以解决这个问题。
2.加入BN层,其优点包括可加速收敛、控制过拟合,可以少用或不用Dropout和正则、降低网络对初始化权重不敏感,且能允许使用较大的学习率等。
3.改变传播结构,选择更高级的模型,例如:LSTM结构可以有效解决这个问题。
梯度消失的出现,使得RNN对早期的学习逐渐遗忘,可以说梯度消失问题是RNN对长序列存在遗忘的罪魁祸首。
最后
以上就是愉快小懒猪最近收集整理的关于深度学习-RNNRNN基本结构RNN工作流程梯度消失问题的全部内容,更多相关深度学习-RNNRNN基本结构RNN工作流程梯度消失问题内容请搜索靠谱客的其他文章。








发表评论 取消回复