学习吴恩达老师的AI课程笔记,详细视频课程请移步https://mooc.study.163.com/smartSpec/detail/1001319001.htm
RNN模型结构:
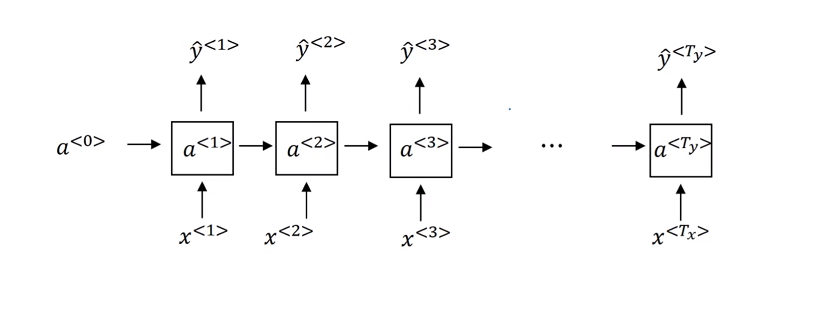
可以看出 如果说有一个非常长的句子(则对应会有一个非常深的网络),这个句子中句尾的某个词严重受句首某些词的影响(英语中的单复数,时态),这时候由于网络非常的深,则在反向传播的过程中极易出现梯度消失或者梯度爆炸的情况(反向传播时)。
* 关于梯度消失的详细解释; --引自知乎 https://zhuanlan.zhihu.com/p/28687529
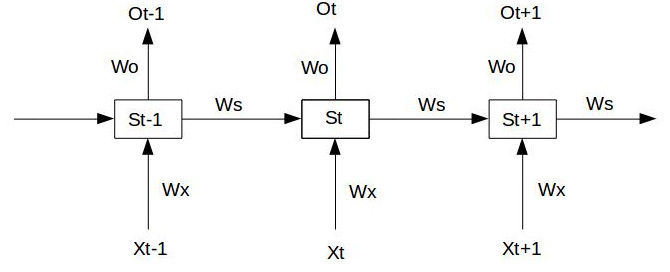
假设我们的时间序列只有三段S0为给定值,神经元没有激活函数,则RNN最简单的前向传播过程如下:
S
1
=
W
x
X
1
+
W
s
S
0
+
b
1
,
O
1
=
W
0
S
1
+
b
2
S_1 = W_xX_1+W_sS_0+b_1,O_1 =W_0S_1+b_2
S1=WxX1+WsS0+b1,O1=W0S1+b2
S
2
=
W
x
X
2
+
W
s
S
1
+
b
1
,
O
2
=
W
0
S
2
+
b
2
S_2 = W_xX_2+W_sS_1+b_1,O_2 =W_0S_2+b_2
S2=WxX2+WsS1+b1,O2=W0S2+b2
S
3
=
W
x
X
3
+
W
s
S
2
+
b
1
,
O
3
=
W
0
S
3
+
b
2
S_3 = W_xX_3+W_sS_2+b_1,O_3 =W_0S_3+b_2
S3=WxX3+WsS2+b1,O3=W0S3+b2假设在t=3时刻,损失函数为
L
3
=
1
2
(
Y
3
−
O
3
)
2
L3 = frac{1}{2}(Y_3-O_3)^2
L3=21(Y3−O3)2。 则对于一次训练任务的损失函数为
L
=
∑
t
=
0
T
L
t
L=sum_{t=0}^{T}{L_t}
L=t=0∑TLt ,即每一时刻损失值的累加。使用随机梯度下降法训练RNN其实就是对Wx、Ws、W0以及b1、b2求偏导,并不断调整它们以使L尽可能达到最小的过程。现在假设我们我们的时间序列只有三段,t1,t2,t3。我们只对t3时刻的Wx、Ws、W0求偏导(其他时刻类似):
δ
L
3
δ
W
0
=
δ
L
3
δ
O
3
δ
O
3
δ
W
0
frac{delta L_3}{delta W_0}=frac{delta L_3}{delta O_3}frac{delta O_3}{delta W_0}
δW0δL3=δO3δL3δW0δO3
δ
L
3
δ
W
x
=
δ
L
3
δ
O
3
δ
O
3
δ
S
3
δ
S
3
δ
W
x
+
δ
L
3
δ
O
3
δ
O
3
δ
S
3
δ
S
3
δ
S
2
δ
S
2
δ
W
x
+
δ
L
3
δ
O
3
δ
O
3
δ
S
3
δ
S
3
δ
S
2
δ
S
2
δ
S
1
δ
S
1
δ
W
x
frac{delta L_3}{delta W_x}=frac{delta L_3}{delta O_3}frac{delta O_3}{delta S_3}frac{delta S_3}{delta W_x}+frac{delta L_3}{delta O_3}frac{delta O_3}{delta S_3}frac{delta S_3}{delta S_2}frac{delta S_2}{delta W_x}+frac{delta L_3}{delta O_3}frac{delta O_3}{delta S_3}frac{delta S_3}{delta S_2}frac{delta S_2}{delta S_1}frac{delta S_1}{delta W_x}
δWxδL3=δO3δL3δS3δO3δWxδS3+δO3δL3δS3δO3δS2δS3δWxδS2+δO3δL3δS3δO3δS2δS3δS1δS2δWxδS1
δ
L
3
δ
W
s
=
δ
L
3
δ
O
3
δ
O
3
δ
S
3
δ
S
3
δ
W
s
+
δ
L
3
δ
O
3
δ
O
3
δ
S
3
δ
S
3
δ
S
2
δ
S
2
δ
W
s
+
δ
L
3
δ
O
3
δ
O
3
δ
S
3
δ
S
3
δ
S
2
δ
S
2
δ
S
1
δ
S
1
δ
W
s
frac{delta L_3}{delta W_s}=frac{delta L_3}{delta O_3}frac{delta O_3}{delta S_3}frac{delta S_3}{delta W_s}+frac{delta L_3}{delta O_3}frac{delta O_3}{delta S_3}frac{delta S_3}{delta S_2}frac{delta S_2}{delta W_s}+frac{delta L_3}{delta O_3}frac{delta O_3}{delta S_3}frac{delta S_3}{delta S_2}frac{delta S_2}{delta S_1}frac{delta S_1}{delta W_s}
δWsδL3=δO3δL3δS3δO3δWsδS3+δO3δL3δS3δO3δS2δS3δWsδS2+δO3δL3δS3δO3δS2δS3δS1δS2δWsδS1 可以看出对于W0求偏导并没有长期依赖,但是对于Wx、Ws求偏导,会随着时间序列产生长期依赖。因为St随着时间序列向前传播,而St又是Wx、Ws的函数。根据上述求偏导的过程,我们可以得出任意时刻对Wx、Ws求偏导的公式:
δ
L
t
δ
W
x
=
∑
k
=
0
t
δ
L
t
δ
O
t
δ
O
t
δ
S
t
(
⋂
j
=
k
+
1
t
δ
S
j
δ
S
j
−
1
)
δ
S
k
δ
W
x
frac{delta L_t}{delta W_x}=sum_{k=0}^{t}{frac{delta L_t}{delta O_t}frac{delta O_t}{delta S_t}(bigcap_{j=k+1}^{t}{frac{delta S_j}{delta S_j-1}})frac{delta S_k}{delta W_x}}
δWxδLt=k=0∑tδOtδLtδStδOt(j=k+1⋂tδSj−1δSj)δWxδSk任意时刻对Ws求偏导的公式同上。如果加上激活函数,
S
j
=
t
a
n
h
(
W
x
X
j
+
W
s
S
j
−
1
+
b
1
)
S_j=tanh(W_xX_j+W_sS_{j-1}+b_1)
Sj=tanh(WxXj+WsSj−1+b1),则
⋂
j
=
k
+
1
t
δ
S
j
δ
S
j
−
1
=
⋂
j
=
k
+
1
t
t
a
n
h
′
W
s
bigcap_{j=k+1}^{t}{frac{delta S_j}{delta S_j-1}}=bigcap_{j=k+1}^{t}{tanh'W_s}
j=k+1⋂tδSj−1δSj=j=k+1⋂ttanh′Ws解决方法:
*** 梯度爆炸:** 容易发现,对梯度设定一个最大的阈值,将梯度设定在阈值范围内
*** 梯度消失:**
GRU:

图中的C为记忆单元,他负责存储可能对后续字节有较大影响的字节,CN(t)则代表每步运行后的C值的候选值(是否需要把C值更新为候选值),Iu是门,用来决定是否需要更新,从上式c(t)可以看出 当lu为1是则代表需要更新,为0则无需更新。实际中的GRU 上述的各个环节都可能是多个元素的 如C(t)里可能有[a,b,c,d,e,g…]等100个元素,则Iu中对应的也应有100个元素[0,0,0,0,1,1,0,1,0…],两者的每个元素相对应,使得候选值被准确的定位是否需要更新。 完整的GRU
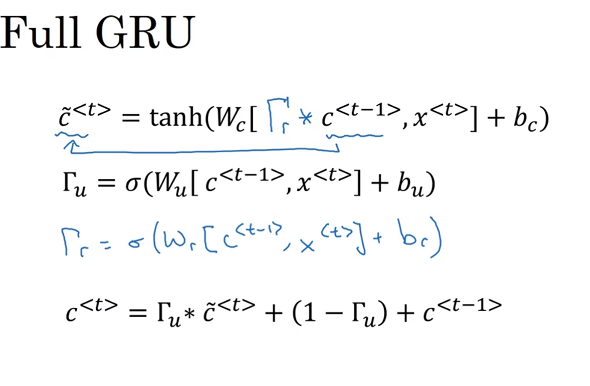
* LSTM: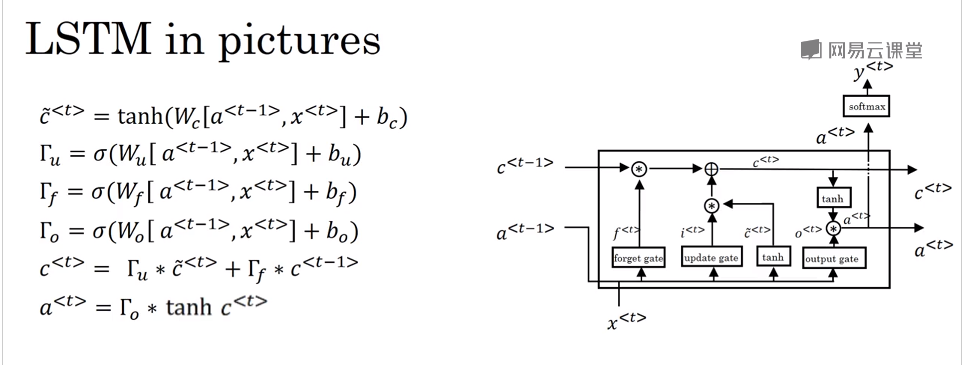
可以看看出LSTM有三个门控单元 分别是更新门Tu,Tf,To 对比GRU可以看出 更新值C(t)直接由更新门Tu和遗忘门Tf控制是否需要更新。
最后
以上就是从容樱桃最近收集整理的关于RNN的梯度消失问题的全部内容,更多相关RNN内容请搜索靠谱客的其他文章。








发表评论 取消回复