离散空间和连续空间
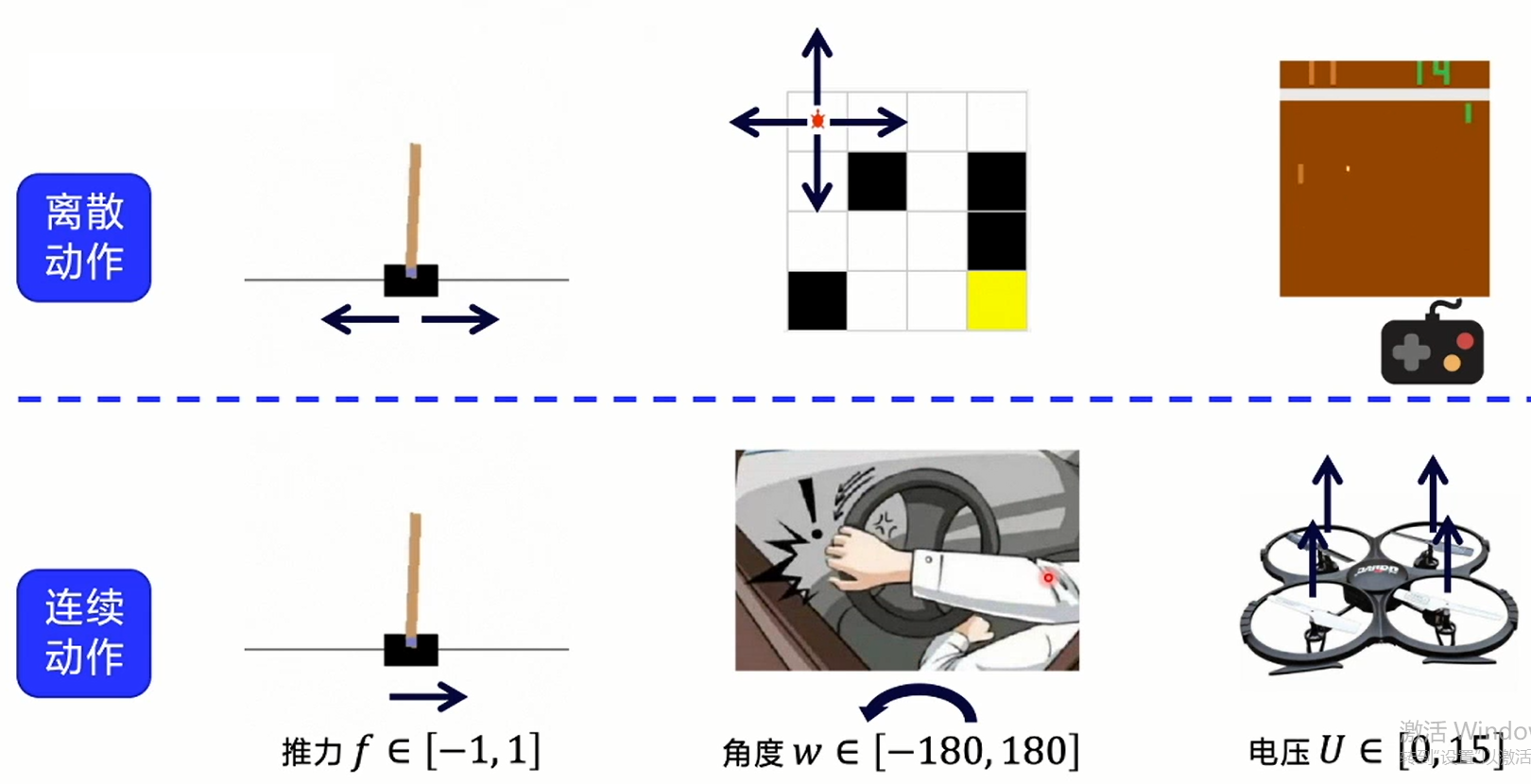
之前我们做出的决策都是基于离散状态的,简单来说是类似于在做“选择题”。而连续的动作,我们输出的将不是某个动作,而是更加细致的动作的程度,类比深度学习的分类任务与回归任务。当然,具体选何种模型可以根据具体情况灵活选择,有时离散动作和连续动作之间是可以灵活转换的。
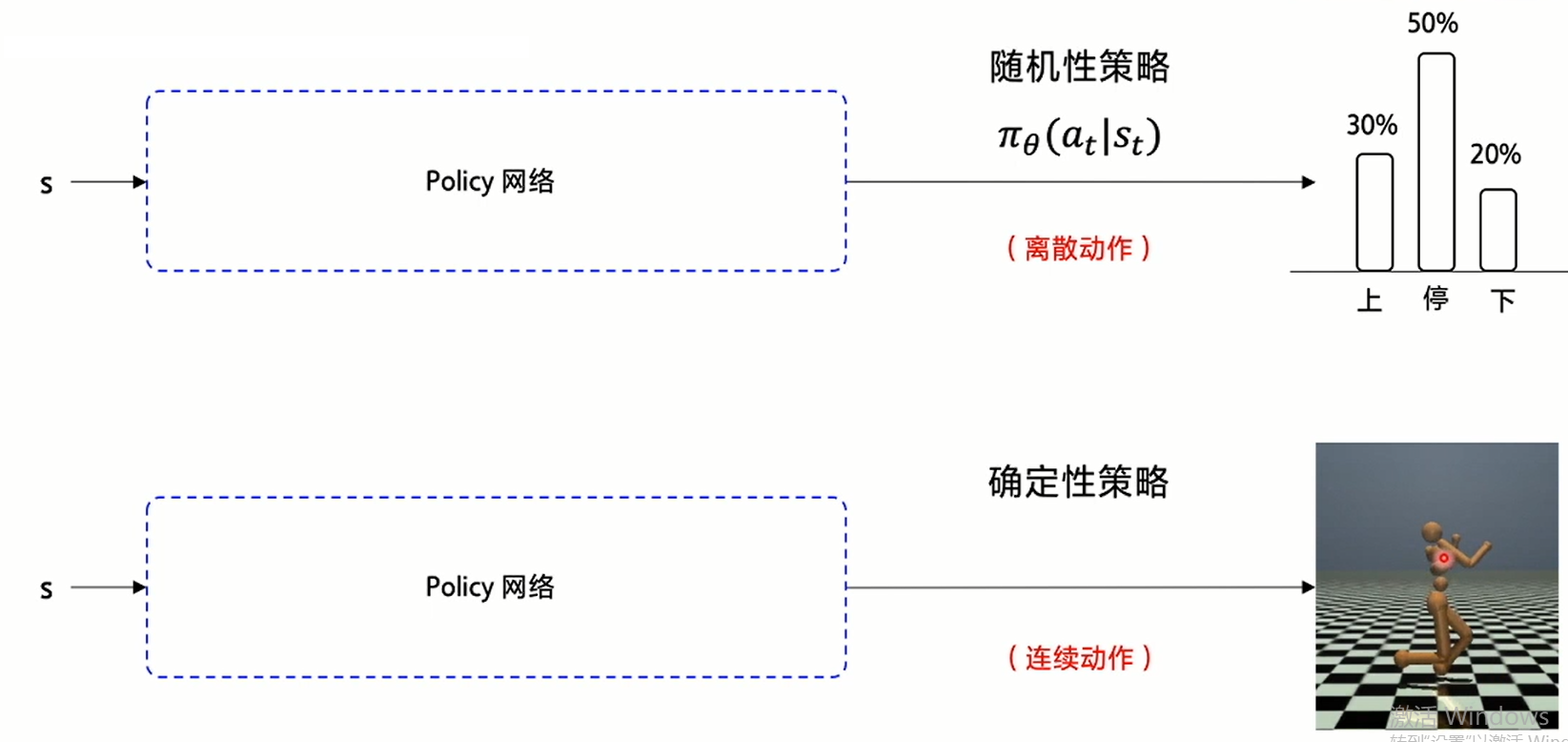
选择回归模型,那么意味着输出动作种类是无限多的,因此为了减少不确定性,使用连续动作输出的模型时,使用的是确定性策略,即同样的输入会得到同样的输出,而随即策略是有一定的概率得到不同的输出结果的。
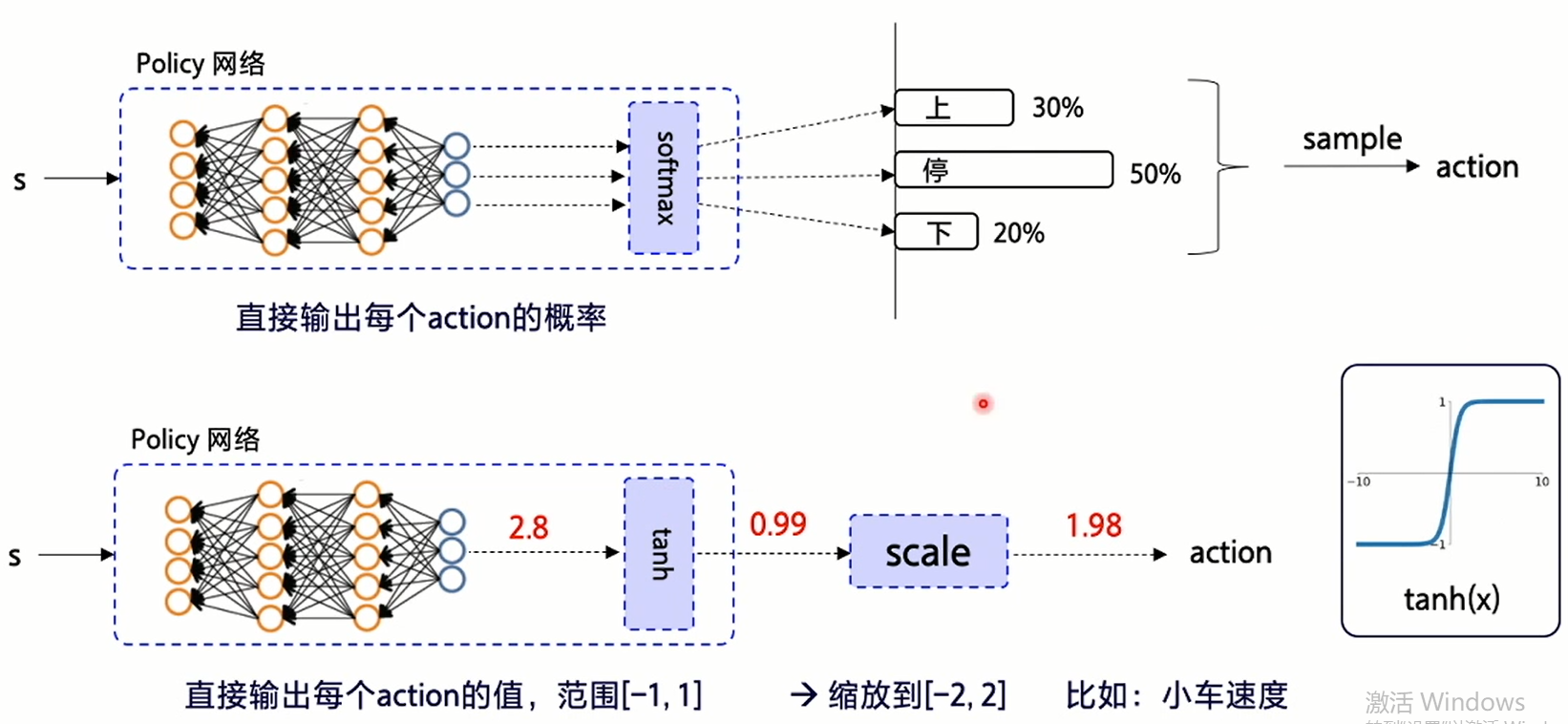
用于连续动作输出的值我们需要通过tanh将其收敛至[-1,1]后,再缩放道相应的动作程度之中:
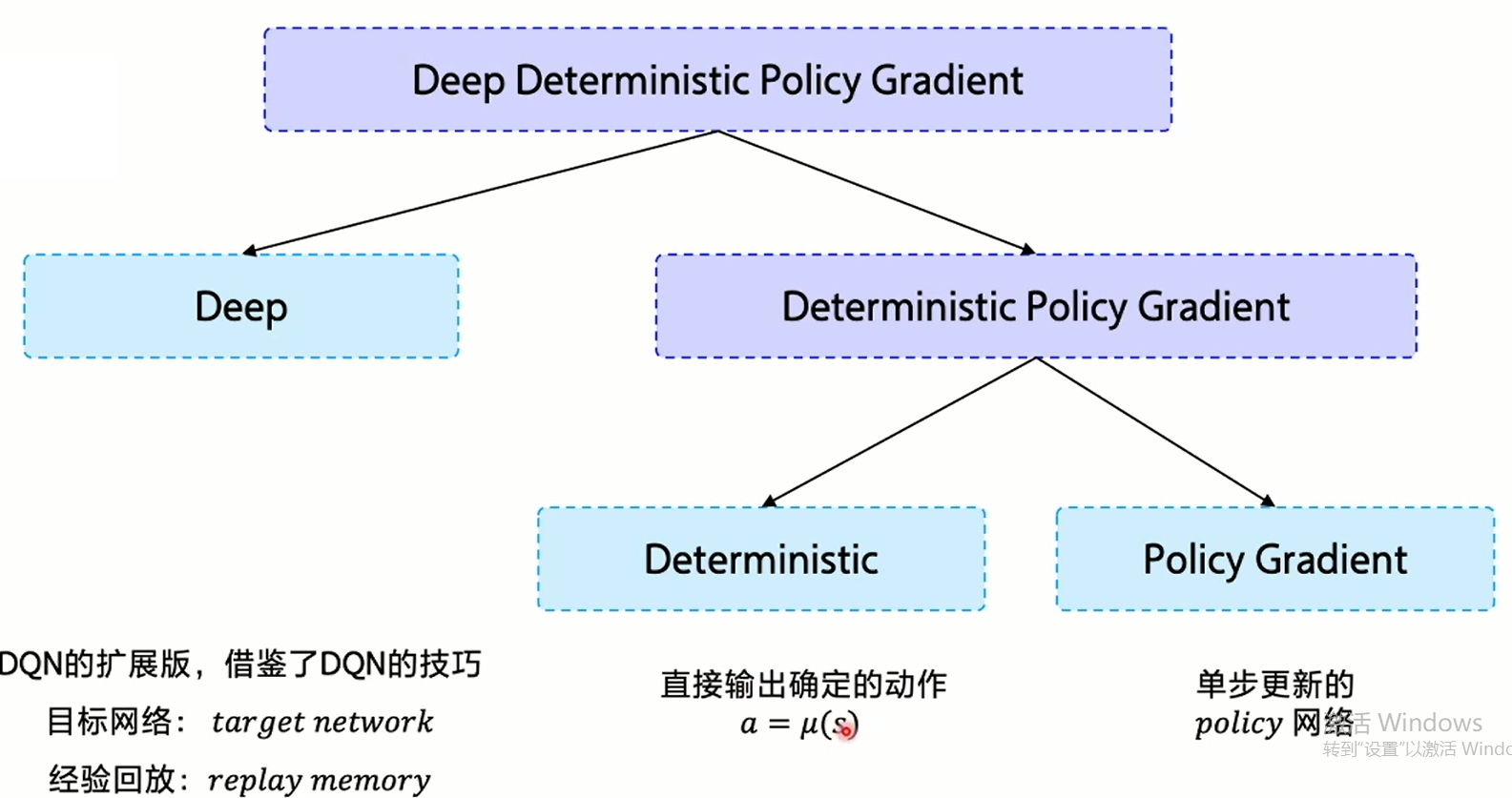
DDPG算法
在上一节中,我们了解道了reinforce采用的梯策略是MC采样,而DDPG使用的是TD的梯度策略,这二者的具体区别可以查看https://blog.csdn.net/wqy20140101/article/details/89598464。总结性地来说:TD有偏差,但方差小;MC无偏差,但方差大。
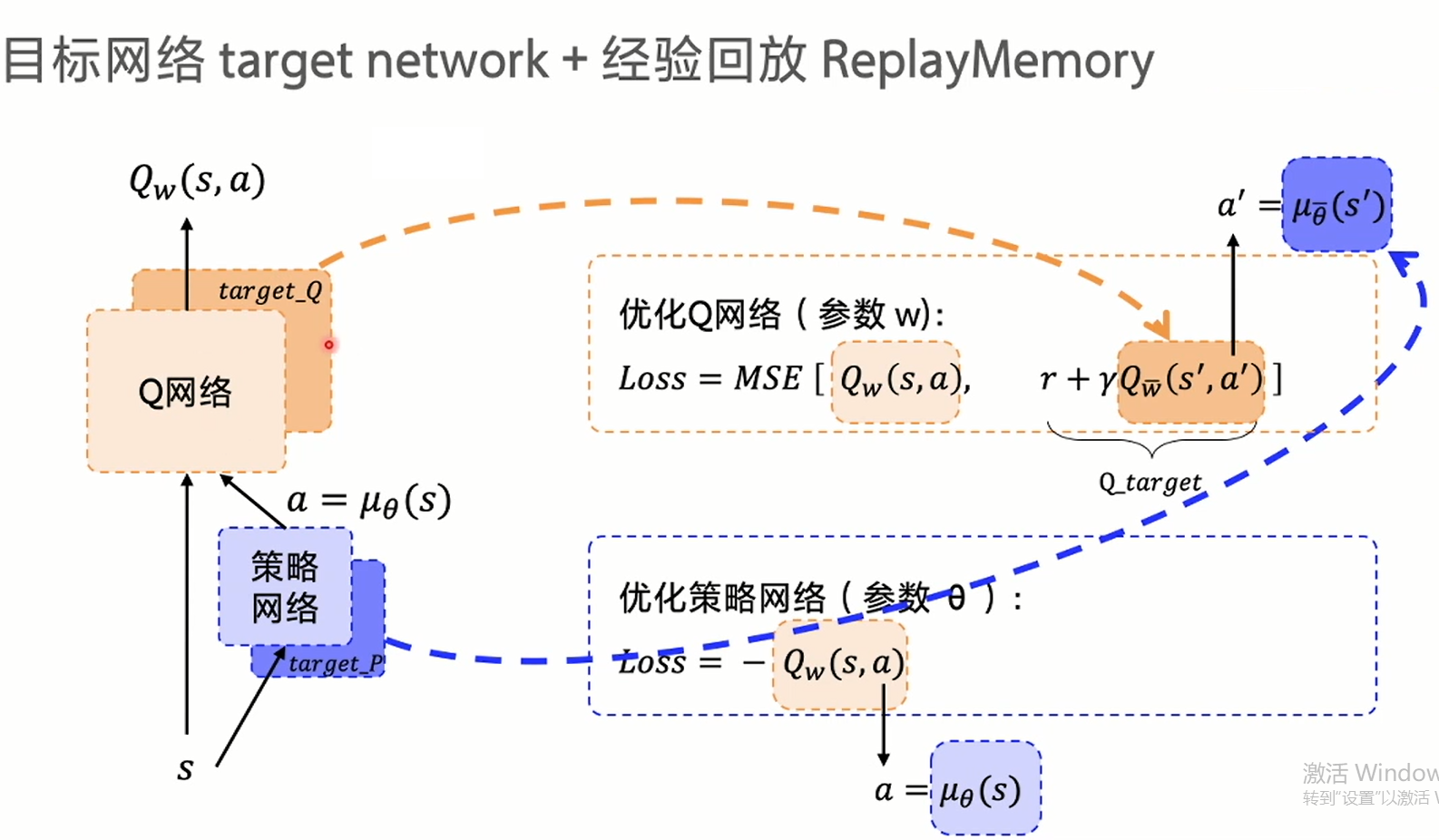
其具体的梯度策略借鉴了DQN的结构,采用目标网络与经验回放的结构
在此基础上,DDPG还引入了A-C结构,即先用A来感知环境,C根据感知的情况做出决策:
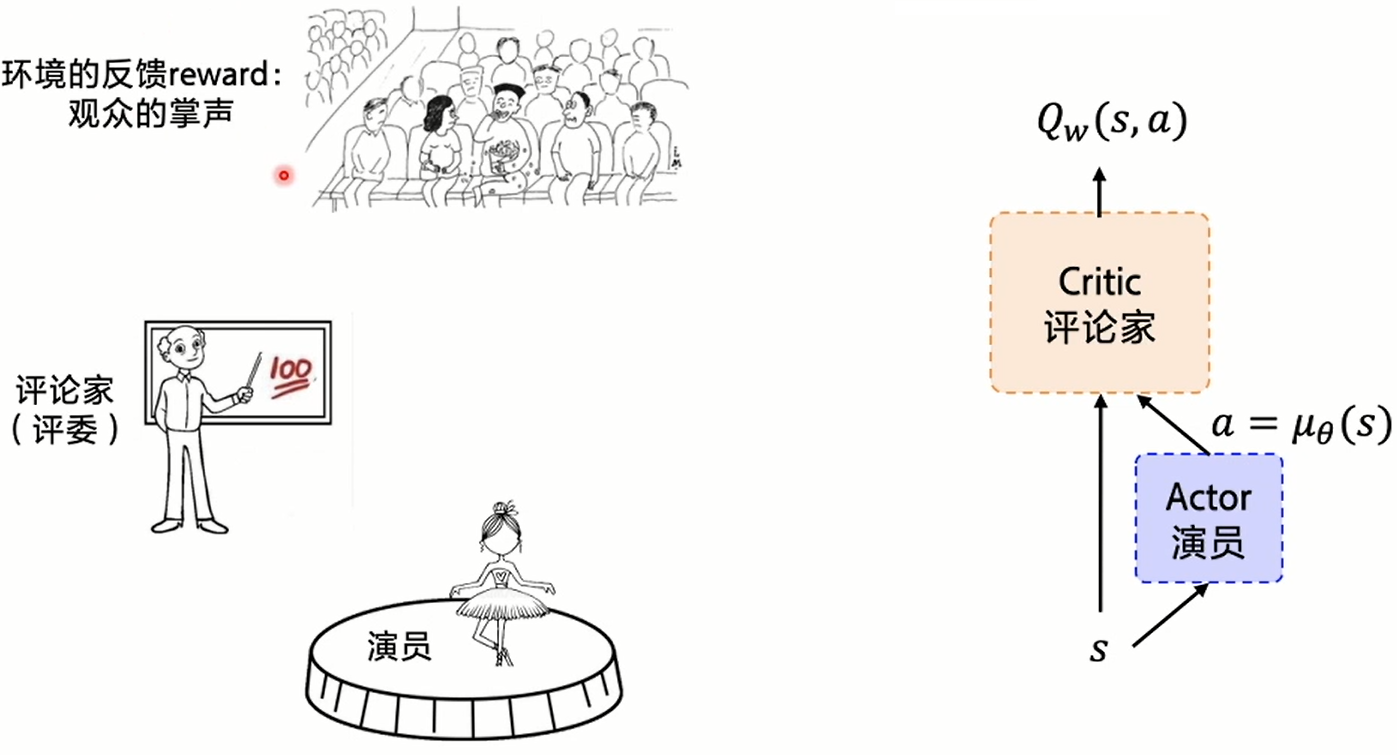
再将目标网络与经验回放的结构与其融合后,DDPG的核心深度学模块就变为了:
代码与实践结果
A-C模型定义
class ActorModel(parl.Model):
def __init__(self, act_dim):
hid_size = 100
self.fc1 = layers.fc(size=hid_size, act='relu')
self.fc2 = layers.fc(size=act_dim, act='tanh')
def policy(self, obs):
hid = self.fc1(obs)
means = self.fc2(hid)
return means
class CriticModel(parl.Model):
def __init__(self):
hid_size = 256
self.fc1 = layers.fc(size=hid_size, act='relu')
self.fc2 = layers.fc(size=1, act=None)
def value(self, obs, act):
concat = layers.concat([obs, act], axis=1)
hid = self.fc1(concat)
Q = self.fc2(hid)
Q = layers.squeeze(Q, axes=[1])
return
class QuadrotorModel(parl.Model):
def __init__(self, act_dim):
self.actor_model = ActorModel(act_dim)
self.critic_model = CriticModel()
def policy(self, obs):
return self.actor_model.policy(obs)
def value(self, obs, act):
return self.critic_model.value(obs, act)
def get_actor_params(self):
return self.actor_model.parameters()DDPG算法
class DDPG(parl.Algorithm):
def __init__(self,
model,
gamma=None,
tau=None,
actor_lr=None,
critic_lr=None):
""" DDPG algorithm
Args:
model (parl.Model): actor and critic 的前向网络.
model 必须实现 get_actor_params() 方法.
gamma (float): reward的衰减因子.
tau (float): self.target_model 跟 self.model 同步参数 的 软更新参数
actor_lr (float): actor 的学习率
critic_lr (float): critic 的学习率
"""
assert isinstance(gamma, float)
assert isinstance(tau, float)
assert isinstance(actor_lr, float)
assert isinstance(critic_lr, float)
self.gamma = gamma
self.tau = tau
self.actor_lr = actor_lr
self.critic_lr = critic_lr
self.model = model
self.target_model = deepcopy(model)
def predict(self, obs):
""" 使用 self.model 的 actor model 来预测动作
"""
return self.model.policy(obs)
def learn(self, obs, action, reward, next_obs, terminal):
""" 用DDPG算法更新 actor 和 critic
"""
actor_cost = self._actor_learn(obs)
critic_cost = self._critic_learn(obs, action, reward, next_obs,
terminal)
return actor_cost, critic_cost
def _actor_learn(self, obs):
action = self.model.policy(obs)
Q = self.model.value(obs, action)
cost = layers.reduce_mean(-1.0 * Q)
optimizer = fluid.optimizer.AdamOptimizer(self.actor_lr)
optimizer.minimize(cost, parameter_list=self.model.get_actor_params())
return cost
def _critic_learn(self, obs, action, reward, next_obs, terminal):
next_action = self.target_model.policy(next_obs)
next_Q = self.target_model.value(next_obs, next_action)
terminal = layers.cast(terminal, dtype='float32')
target_Q = reward + (1.0 - terminal) * self.gamma * next_Q
target_Q.stop_gradient = True
Q = self.model.value(obs, action)
cost = layers.square_error_cost(Q, target_Q)
cost = layers.reduce_mean(cost)
optimizer = fluid.optimizer.AdamOptimizer(self.critic_lr)
optimizer.minimize(cost)
return cost
def sync_target(self, decay=None, share_vars_parallel_executor=None):
""" self.target_model从self.model复制参数过来,可设置软更新参数
"""
if decay is None:
decay = 1.0 - self.tau
self.model.sync_weights_to(
self.target_model,
decay=decay,
share_vars_parallel_executor=share_vars_parallel_executor)Agent
class Agent(parl.Agent):
def __init__(self, algorithm, obs_dim, act_dim):
assert isinstance(obs_dim, int)
assert isinstance(act_dim, int)
self.obs_dim = obs_dim
self.act_dim = act_dim
super(Agent, self).__init__(algorithm)
# 注意:最开始先同步self.model和self.target_model的参数.
self.alg.sync_target(decay=0)
def build_program(self):
self.pred_program = fluid.Program()
self.learn_program = fluid.Program()
with fluid.program_guard(self.pred_program):
obs = layers.data(
name='obs', shape=[self.obs_dim], dtype='float32')
self.pred_act = self.alg.predict(obs)
with fluid.program_guard(self.learn_program):
obs = layers.data(
name='obs', shape=[self.obs_dim], dtype='float32')
act = layers.data(
name='act', shape=[self.act_dim], dtype='float32')
reward = layers.data(name='reward', shape=[], dtype='float32')
next_obs = layers.data(
name='next_obs', shape=[self.obs_dim], dtype='float32')
terminal = layers.data(name='terminal', shape=[], dtype='bool')
_, self.critic_cost = self.alg.learn(obs, act, reward, next_obs,
terminal)
def predict(self, obs):
obs = np.expand_dims(obs, axis=0)
act = self.fluid_executor.run(
self.pred_program, feed={'obs': obs},
fetch_list=[self.pred_act])[0]
act = np.squeeze(act)
return act
def learn(self, obs, act, reward, next_obs, terminal):
feed = {
'obs': obs,
'act': act,
'reward': reward,
'next_obs': next_obs,
'terminal': terminal
}
critic_cost = self.fluid_executor.run(
self.learn_program, feed=feed, fetch_list=[self.critic_cost])[0]
self.alg.sync_target()
return critic_cost经验回放
import random
import collections
import numpy as np
class ReplayMemory(object):
def __init__(self, max_size):
self.buffer = collections.deque(maxlen=max_size)
def append(self, exp):
self.buffer.append(exp)
def sample(self, batch_size):
mini_batch = random.sample(self.buffer, batch_size)
obs_batch, action_batch, reward_batch, next_obs_batch, done_batch = [], [], [], [], []
for experience in mini_batch:
s, a, r, s_p, done = experience
obs_batch.append(s)
action_batch.append(a)
reward_batch.append(r)
next_obs_batch.append(s_p)
done_batch.append(done)
return np.array(obs_batch).astype('float32'),
np.array(action_batch).astype('float32'), np.array(reward_batch).astype('float32'),
np.array(next_obs_batch).astype('float32'), np.array(done_batch).astype('float32')
def __len__(self):
return len(self.buffer)训练与测试
def run_episode(agent, env, rpm):
obs = env.reset()
total_reward = 0
steps = 0
while True:
steps += 1
batch_obs = np.expand_dims(obs, axis=0)
action = agent.predict(batch_obs.astype('float32'))
# 增加探索扰动, 输出限制在 [-1.0, 1.0] 范围内
action = np.clip(np.random.normal(action, NOISE), -1.0, 1.0)
next_obs, reward, done, info = env.step(action)
action = [action] # 方便存入replaymemory
rpm.append((obs, action, REWARD_SCALE * reward, next_obs, done))
if len(rpm) > MEMORY_WARMUP_SIZE and (steps % 5) == 0:
(batch_obs, batch_action, batch_reward, batch_next_obs,
batch_done) = rpm.sample(BATCH_SIZE)
agent.learn(batch_obs, batch_action, batch_reward, batch_next_obs,
batch_done)
obs = next_obs
total_reward += reward
if done or steps >= 200:
break
return total_reward
def evaluate(env, agent, render=False):
eval_reward = []
for i in range(5):
obs = env.reset()
total_reward = 0
steps = 0
while True:
batch_obs = np.expand_dims(obs, axis=0)
action = agent.predict(batch_obs.astype('float32'))
action = np.clip(action, -1.0, 1.0)
steps += 1
next_obs, reward, done, info = env.step(action)
obs = next_obs
total_reward += reward
if render:
env.render()
if done or steps >= 200:
break
eval_reward.append(total_reward)
return np.mean(eval_reward)环境配置、超参与流程
ACTOR_LR = 0.0002 # Actor网络更新的 learning rate
CRITIC_LR = 0.0005 # Critic网络更新的 learning rate
GAMMA = 0.99 # reward 的衰减因子,一般取 0.9 到 0.999 不等
TAU = 0.001 # target_model 跟 model 同步参数 的 软更新参数
MEMORY_SIZE = 1e6 # replay memory的大小,越大越占用内存
MEMORY_WARMUP_SIZE = 1e4 # replay_memory 里需要预存一些经验数据,再从里面sample一个batch的经验让agent去learn
REWARD_SCALE = 0.01 # reward 的缩放因子
BATCH_SIZE = 512 # 每次给agent learn的数据数量,从replay memory随机里sample一批数据出来
TRAIN_TOTAL_STEPS = 1e6 # 总训练步数
TEST_EVERY_STEPS = 1e4 # 每个N步评估一下算法效果,每次评估5个episode求平均reward
# 创建飞行器环境
env = ContinuousCartPoleEnv()
env.reset()
obs_dim = env.observation_space.shape[0]
act_dim = env.action_space.shape[0]
act_dim = 4
model = QuadrotorModel(act_dim=act_dim)
alg = DDPG(model,gamma=GAMMA,tau=TAU, actor_lr=ACTOR_LR, critic_lr=CRITIC_LR)
agent = QuadrotorAgent(alg,obs_dim = obs_dim,act_dim =act_dim)
#ckpt = 'model_dir/steps_990602.ckpt'
agent.restore(ckpt)
# parl库也为DDPG算法内置了ReplayMemory,可直接从 parl.utils 引入使用
rpm = ReplayMemory(int(MEMORY_SIZE), obs_dim, act_dim)
# 启动训练
test_flag = 0
total_steps = 0
while total_steps < TRAIN_TOTAL_STEPS:
train_reward, steps = run_episode(env, agent, rpm)
total_steps += steps
#logger.info('Steps: {} Reward: {}'.format(total_steps, train_reward)) # 打印训练reward
if total_steps // TEST_EVERY_STEPS >= test_flag: # 每隔一定step数,评估一次模型
while total_steps // TEST_EVERY_STEPS >= test_flag:
test_flag += 1
evaluate_reward = evaluate(env, agent)
logger.info('Steps {}, Test reward: {}'.format(
total_steps, evaluate_reward)) # 打印评估的reward
# 每评估一次,就保存一次模型,以训练的step数命名
ckpt = 'model_dir/steps_{}.ckpt'.format(total_steps)
agent.save(ckpt)实验结果
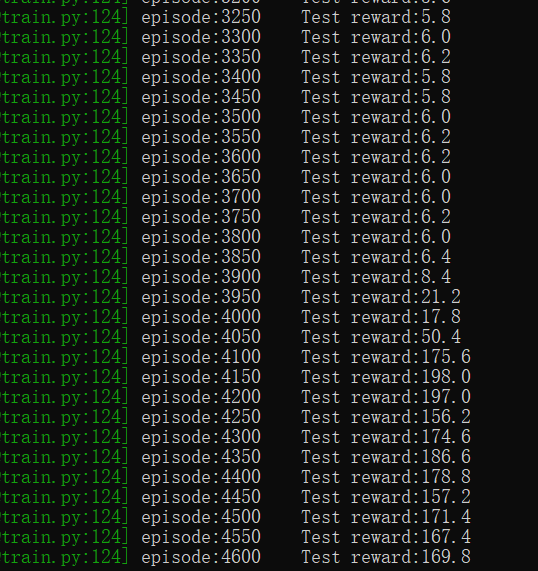
训练过程相对稳定,在一段时间后分数会突然上涨:

最后
以上就是精明白猫最近收集整理的关于Paddle强化学习从入门到实践 (Day5):连续动作空间的求解离散空间和连续空间DDPG算法代码与实践结果的全部内容,更多相关Paddle强化学习从入门到实践内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复