在强化学习中,智能体(agent)在环境中进行一些随机的抉择,并从很多选择中选择最优的一个来达到目标,实现优于人类的水平。在强化学习中,策略网络和数值网络通常一起使用,比如蒙特卡洛树搜索。这两个网络是探索蒙特卡洛树搜索算法中的一个整体部分。
因为他们在迭代过程中被计算了很多次,所以也被叫做策略迭代和数值迭代,。
接下来我们一起来理解这两个网络在机器学习中为什么如此重要,以及它们之间有什么区别。
什么是策略网络?
考虑这个世界上的任何游戏,玩家在游戏中的输入被认为是行为a,每个输入(行为)导致一个不同的输出,这些输出被认为是游戏的状态s。
从中我们可以得到一个不同状态-行动的配对的列表。
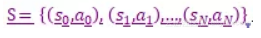
代表哪个行动导致哪个状态。同样的,我们可以说S包括了所有的策略网络中的策略。
策略网络是,给定特定的输入,通过学习给出一个确定输出的网络。
图1 策略网络(动作1,状态1),(动作2,状态2)
比如,在游戏中输入a1导致状态s1(向上移动),输入a2会导致状态s2(向下移动)。
并且,有些行动能增加玩家的分数,产生奖赏r。
图2 状态获得奖赏
来看一些强化学习中常用的符号:

为什么我们使用贴现因子![]()
它是为了防止奖赏r达到无穷大的预防措施(通常小于1)。一个策略无穷大的奖励会忽略掉智能体采取不同行动的区别,导致失去在游戏中探索未知区域和行动的欲望。
但我们在下一次行动到达什么状态才能通往决赛呢?

图3 如何决策下一个动作
什么是数值网络?
通过计算目前状态s的累积分数的期望,数值网络给游戏中的状态赋予一个数值/分数。每个状态都经历了整个数值网络。奖赏更多的状态显然在数值网络中的值更大。
记住奖赏是奖赏期望值,因为我们在从状态的集合中选择一个最优的那个。
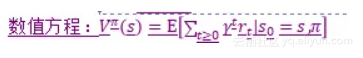
接下来,主要目标是最大化期望(马尔科夫决策过程)。达到好的状态的行动显然比其他行动获得更多奖赏。
因为任何游戏都是通过一系列行动来获胜。游戏中的最优化策略![]() 由一系列的能够帮助在游戏中获胜的状态-行动对组成。
由一系列的能够帮助在游戏中获胜的状态-行动对组成。
获得最多奖赏的状态-行动对是最优化的策略。
最优化的策略的等式通过最大化语句来写出:
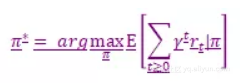
因此,最优化的策略告诉我们采取哪个行动能够最大化累计折扣奖励。
通过策略网络学习到的最优化的政策知道当前状态下应该采取哪个行动来获得最大化的奖赏。
如果你有任何疑问或者需求,在下面评论或者推特我。
鼓掌……分享它!在Medium上关注我来获得相似的有趣内容。
在推特上关注我来获得及时的提醒。
原文发布时间为:2018-11-26
本文来自云栖社区合作伙伴“数据派THU”,了解相关信息可以关注“数据派THU”。
最后
以上就是懵懂红酒最近收集整理的关于独家 | 强化学习中的策略网络vs数值网络(附链接)的全部内容,更多相关独家内容请搜索靠谱客的其他文章。






![[密码学基础][每个信息安全博士生应该知道的52件事][Bristol Cryptography][第17篇]述和比较DES和AES的轮结构](https://www.shuijiaxian.com/files_image/reation/bcimg18.png)
![[密码学基础][每个信息安全博士生应该知道的52件事][Bristol Cryptography][第36篇]Index Calculus算法](https://www.shuijiaxian.com/files_image/reation/bcimg19.png)
发表评论 取消回复