前言
大体上,周博磊的课+李宏毅的课+莫凡的课就够入门了,本文是在看课过程中对一些不理解的概念进行梳理和总结过程中搜集到的一些比较好的资料。
总纲:图不错,概念;代码流程;调参;高斯过程;强化学习中的数学基础;Boostrapping(感觉和统计学的并没有什么卵关系);总结
几个学习的网址:Spinning up;basline;强化学习笔记
Q值和V值的互相转换:Q和V本质上可以通过Bellman方程相互转化
贪心策略:UCB和e贪心;Thomson采样
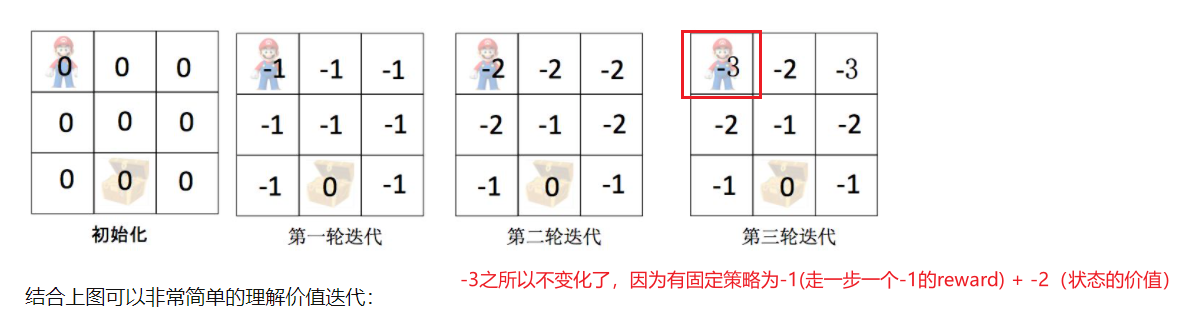
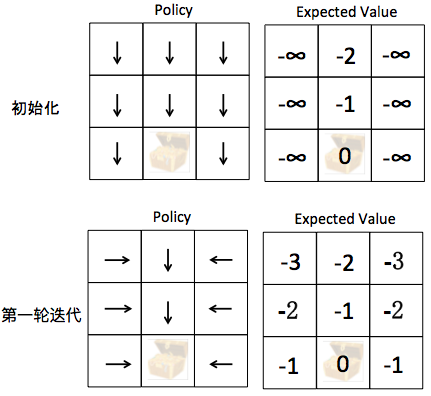
Policy-Iteration & Value iteration:还是结合例子看比较直观;策略迭代(选定策略,更新策略),价值迭代(多次迭代直至收敛)
DP,MC,TD:Model-Free Prediction,无需进行Policy/Value这样的Model-based的方法
On policy,Off policy:其实on policy会按着既定策略去走(Sarsa),而off policy会随机epsilon贪心策略(QLearning);几个重要问题
价值函数近似:近似
强化学习收敛:强化学习训练收敛性
State-of-Art的一些算法
下面是Policy Based的算法(Policy Gradient,A3C的改进)
Policy gradient:MC数学推导;直观理解,异同;减少Varience

重要性采样:原理;实现;例子
TRPO:Fisher Information;先了解Natural Gradient Decent,讲解,其实直观理解就是新策略不能相比老策略变化过大,使用KL散度进行限制。
PPO:其实就是把KL散度使用拉格朗日放入优化目标
下面的是无需importance sampling的Value Based,直接用Bellman方程进行优化。(对于Qlearning的改进)
DDPG:DDPG
TD3: 白话强化学习
SAC:SAC(可以系统学习这个专栏笔记)
重参数Trick:就是从另一个可微的分布采样,从而实现对不可微分布的期望的估计
Other Topics
Model-based:预测下一个state
逆强化学习:逆强化学习;模仿学习
最后
以上就是拉长苗条最近收集整理的关于强化学习中的一些疑惑与求解的全部内容,更多相关强化学习中内容请搜索靠谱客的其他文章。







![[密码学基础][每个信息安全博士生应该知道的52件事][Bristol Cryptography][第17篇]述和比较DES和AES的轮结构](https://www.shuijiaxian.com/files_image/reation/bcimg18.png)
发表评论 取消回复