强化学习(二):贪心策略(ε-greedy & UCB)

夏栀的博客——王嘉宁的个人网站 正式上线,欢迎访问和关注:http://www.wjn1996.cn
强化学习是当前人工智能比较火爆的研究内容,作为机器学习的一大分支,强化学习主要目标是让智能体学习如何在给定的一个环境状态下做出合适的决策。强化学习相关概念请点击:强化学习(一):概述
强化学习任务中有两个非常重要的概念——开发(exploit)和探索(explore),有时也分别叫做利用和试探。简单理解一下两者的概念:
- 开发:在强化学习中,开发指智能体在已知的所有(状态-动作)二元组分布中,本着“最大化动作价值”的原则选择最优的动作。换句话说,当智能体从已知的动作中进行选择时,我们称此为开发(或利用);
- 探索:指智能体在已知的(状态-动作)二元组分布之外,选择其他未知的动作。
开发与探索是强化学习中非常突出的一个问题,也是决定这个强化学习系统能否获得最优解的重点。我们试想一下,当在执行多臂赌博机任务时,你会事先选择其中几个拉杆来进行试探,当试探一定程度时,你会发现有一拉杆所获得的收益或比较多,因此在一定时间内,你会每次都选择这个拉杆。但是事实上,这个拉杆只是在你所选动作范围内是最优的(也就是局部最优),并不一定是全局最优,因此你还需要在开发的过程中,逐步去探索其他的拉杆。
开发对于最大化当前时刻期望收益是正确的做法,而探索则是从长远角度讲可能带来最大化总收益。然而不幸的是,在某一个状态下,智能体只能执行一个动作,要么开发,要么探索,二者无法同时进行,因此这就是强化学习重点突出的矛盾——权衡开发与探索。
下面介绍两个用于权衡开发与探索的策略——
ϵ
−
epsilon-
ϵ−贪心和UCB(最大置信度上界)
1、 ϵ − epsilon- ϵ−贪心
在权衡开发与探索二者之间,
ϵ
−
epsilon-
ϵ−贪心是一种常用的策略。其表示在智能体做决策时,有一很小的正数
ϵ
(
<
1
)
epsilon(<1)
ϵ(<1)的概率随机选择未知的一个动作,剩下
1
−
ϵ
1-epsilon
1−ϵ的概率选择已有动过中动作价值最大的动作。
假设当前智能体所处的状态为
s
t
∈
S
s_tin S
st∈S,其可以选择的动作集合为
A
A
A。在多臂赌博机中,每一个拉杆可以代表一个动作,智能体在执行某一个动作
a
t
∈
A
a_tin A
at∈A之后,将会达到下一个状态
s
t
+
1
s_{t+1}
st+1,此时也会得到对应的收益
r
t
r_t
rt。在决策过程中,有
ϵ
epsilon
ϵ概率选择非贪心的动作,即,每个动作被选择的概率为
ϵ
/
∣
A
∣
epsilon/|A|
ϵ/∣A∣,其中
∣
A
∣
|A|
∣A∣表示动作数量;也就是说,每个动作都有同样
ϵ
/
∣
A
∣
epsilon/|A|
ϵ/∣A∣ 概率的被非贪心的选择。另外还有
1
−
ϵ
1-epsilon
1−ϵ的概率选择一个贪心策略,因此这个贪心策略被选择的概率则为
1
−
ϵ
+
ϵ
/
∣
A
∣
1-epsilon + epsilon/|A|
1−ϵ+ϵ/∣A∣。有人会问为什么是两项的和,其实很简单,在所有的动作集合
A
A
A中,在某一个时刻,总会有一个动作是智能体认为的最优动作,即
a
∗
=
a
r
g
m
a
x
(
Q
(
a
,
s
)
)
a^*=argmax(Q(a,s))
a∗=argmax(Q(a,s)),因此这个动作本身有
ϵ
/
∣
A
∣
epsilon/|A|
ϵ/∣A∣的概率在探索阶段被选择,还有
1
−
ϵ
1-epsilon
1−ϵ概率在开发阶段被选择。
其实我们在后面的学习中,还会遇到一个问题:比如在蒙特卡洛采用中,如何保证对所有动作价值空间都能有至少一次被访问?换句话说,如果我们每次都选择开发,那会有很多动作没有被选择,
ϵ
−
epsilon-
ϵ−贪心则可以解决这个问题,思考会发现,所有的动作被选择的概率都满足
π
(
a
∣
s
)
≥
ϵ
/
∣
A
∣
pi (a|s)geq epsilon/|A|
π(a∣s)≥ϵ/∣A∣,这就保证了每个(状态-动作)二元组都会有一定概率被访问到。
下面给出一个例子:同轨策略的首次访问型蒙特卡洛控制算法。首先简单解释一下:蒙特卡洛策略是一种采样策略,根据待估计的策略
π
pi
π来生成一幕序列:
S
0
,
A
0
,
R
1
,
S
1
,
A
1
,
R
2
,
.
.
.
,
S
T
−
1
,
A
T
−
1
,
R
T
S_0,A_0,R_1,S_1,A_1,R_2,...,S_{T-1},A_{T-1},R_{T}
S0,A0,R1,S1,A1,R2,...,ST−1,AT−1,RT。首次访问型表示某一个(状态-动作)二元组只在第一次被访问到时加入到average计算,与之相反的是每次访问型。

在对每一幕进行遍历的时候,首先根据策略
π
pi
π生成一幕序列,蒙特卡洛方法则是需要对整个幕进行采样之后,才能进行策略评估和控制。如上图所示,通常从最后一个时刻往前倒序,对应某一时刻
t
t
t,获得的实际收益为
G
t
=
γ
G
t
+
R
t
+
1
G_t=gamma G_t+R_{t+1}
Gt=γGt+Rt+1,根据当前(状态-动作)二元组中所有的收益进行取平均,得到动作价值
Q
(
S
t
,
S
t
)
Q(S_t,S_t)
Q(St,St),根据
ϵ
−
epsilon-
ϵ−贪心策略,则有:
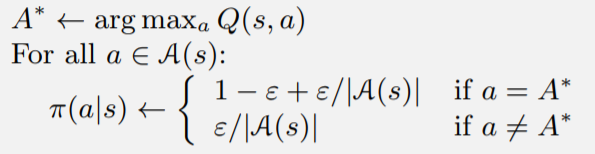
事实上,对于局部最优的动作
a
∗
a^*
a∗,其被选择的概率最大,其余的动作概率都为
ϵ
/
∣
A
∣
epsilon/|A|
ϵ/∣A∣。
这种贪心策略有一个问题:虽然每个动作都有被选择的概率,但是这种选择太过于随机,有一些(状态-动作)二元组应该是可以达到全局最优,但由于初始化的原因,使得它被访问的概率很低,这并不能有助于智能体很大概率的发现最优动作,UCB算法则改进这一点。
2、UCB 最大置信度上界
置信区间是概率统计和统计推断比较重要的概念,其衡量一个随机变量分布的置信水平。置信区间越大,越说明这个随机变量不确定因素更大。UCB则是采用置信水平来实现对开发与探索之间的平衡。首先引入一个思想:不确定行为优先
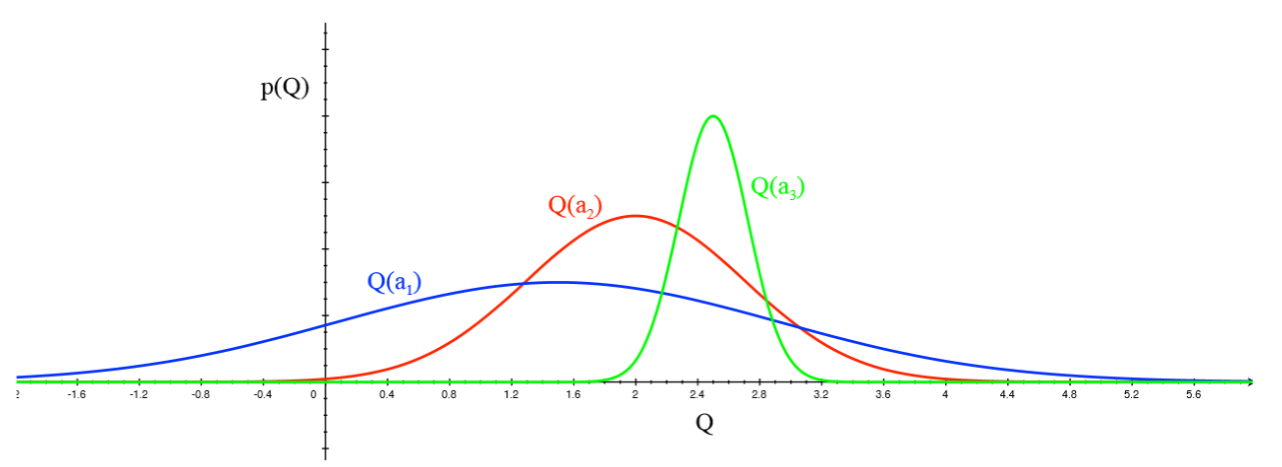
如图所示,假设多臂赌博机已知的几个拉杆动作-奖励分布曲线,我们会发现对应绿色曲线,动作 a 3 a_3 a3可以达到最大收益,但我们并不会去选择它,而是优先选择跨度最大的动作 a 1 a_1 a1(蓝色曲线),从置信区间角度讲,其置信区间大,从概率统计角度讲,这种分布跨度越大,方差越大,说明对应的采样样本数量相对少,不确定性越大,而UCB正是一种偏向于对不确定性大的动作进行试探的算法。
UCB值主要包括两项,为 Q t ( a ) + U t ( a ) Q_t(a)+U_t(a) Qt(a)+Ut(a),前者表示当前动作-收益的实际分布,也就是实际的Q函数,后者则是对该动作不确定的一种度量。UCB的目标则是最大化动作的置信度,也就是置信区间,即表示为 a t = arg max a ∈ A ( Q t ( a ) + U t ( a ) ) a_t=argmax_{ain A}(Q_t(a) + U_t(a)) at=a∈Aargmax(Qt(a)+Ut(a)),通常 U t ( a ) = c l n t N t ( a ) U_t(a)=csqrt{frac{ln t}{N_t(a)}} Ut(a)=cNt(a)lnt,其中 N t ( a ) N_t(a) Nt(a)表示动作 a a a被选择的次数, l n t lnt lnt表示选择动作总次数的对数, c c c是一个权值。简单地说, Q t ( a ) Q_t(a) Qt(a)代表着开发, U t ( a ) U_t(a) Ut(a)代表着探索。当当前动作被采样的次数很低时, N t ( a ) N_t(a) Nt(a)不变,而 l n t lnt lnt在增加, U t ( a ) U_t(a) Ut(a)值变大,不确定性越高,使得其被选择的概率越大;反之亦然。对于 U t ( a ) U_t(a) Ut(a)的推导可参考文章:https://blog.csdn.net/xyk_hust/article/details/86702700
我们以10-臂赌博机例子,当首先开始进行动作选择时,由于初始化的置信度都为0,因此是随机选择一个动作(拉杆),并获得相关的收益,第二次进行动作选择时,由于之前的动作已经被选择一次,其不确定性降低,不会被选择,智能体将会从剩下的9个动作中选择,直到第10次,所有动作都被选择一遍。因此这10次选择基本以探索为主,同样也获得了一个全局最优。从第11次开始,由于每个动作都被执行至少一次,此时 U t ( a ) U_t(a) Ut(a)的值大家都一样,而 Q t ( a ) Q_t(a) Qt(a)不一样,因此偏向于开发(以为此时动作的选择取决于谁的动作价值大),但是当执行几次之后,有的动作被多次选择,其 U t ( a ) U_t(a) Ut(a)反倒下降,其他的动作也会相应被再次选择。经过一次次的迭代,每个动作的置信区间都会得到收敛,从而实现对所有动作的一个遍历,平衡了开发与探索。下图为UCB与 ϵ − epsilon- ϵ−贪心的对比:
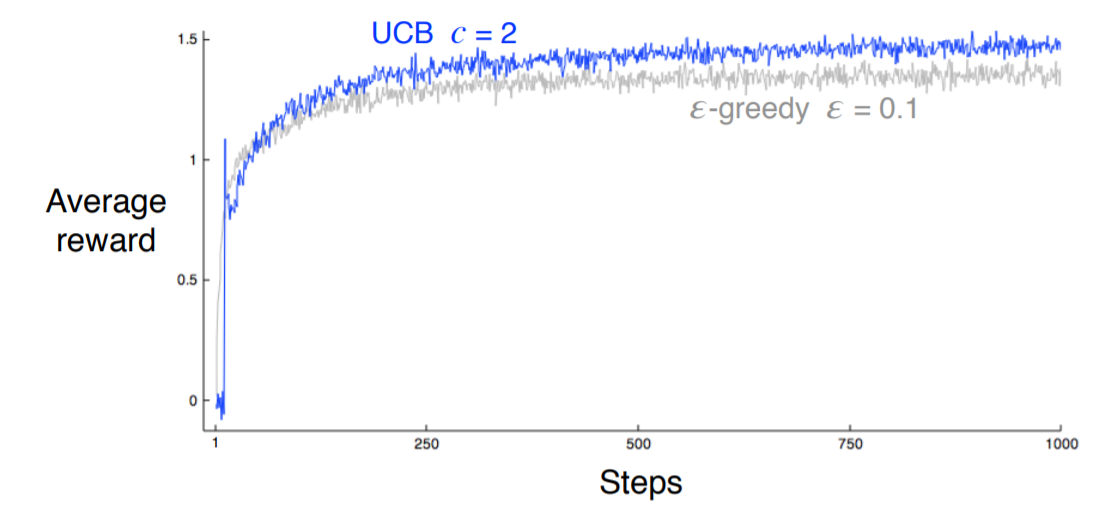
有意思的是,UCB在一开始的迭代步骤,不一定比 ϵ − epsilon- ϵ−贪心好,这是由于在一开始,UCB主要以探索为主,因此其在一开始获得的平均收益不一定好。另外UCB在刚开始的时候,在 c < 1 c<1 c<1的条件下会出现尖峰,其是由于前几步基本是以探索为主,因此很快将所有的动作都执行了一次,由于每个动作被执行次数少,因此期望收益短期内会出现峰值,但当进行接下来的开发与探索时,随着动作选择次数增加,期望收益会下降。
UCB也存在一些问题,例如UCB收敛速度慢,这一点在上图也发现了;其次UCB不一定能够解决一些复杂的问题,其依赖于一些静态分布,而对于类似象棋、围棋等概率分布是动态变化的不一定适用,相比 ϵ − epsilon- ϵ−贪心来讲,其普适性更强一点。
最后
以上就是健康长颈鹿最近收集整理的关于强化学习(二):贪心策略(ε-greedy & UCB)强化学习(二):贪心策略(ε-greedy & UCB)的全部内容,更多相关强化学习(二):贪心策略(ε-greedy内容请搜索靠谱客的其他文章。








发表评论 取消回复