每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~
———————————————————————————
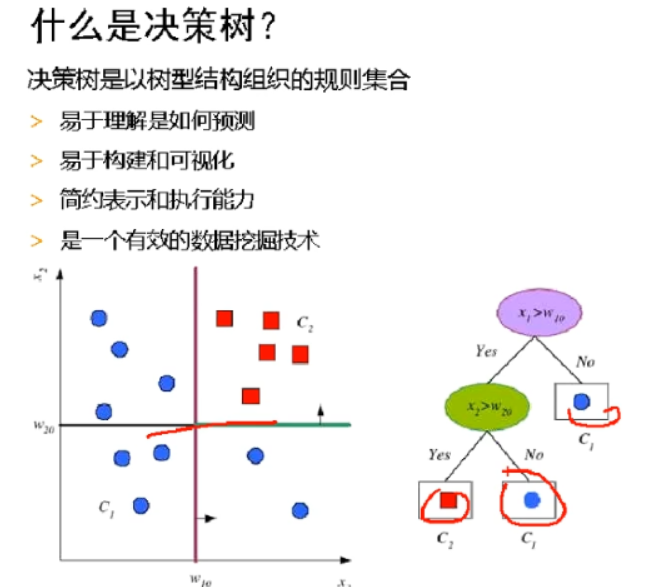
为了区分红蓝模块,先将能分的先划分开来(中间的红线,分为了一遍全蓝),然后再来细分(绿线)。
决策树优势:为什么业务人喜欢,可以给你决策场景,因为模型可视化高,可以讲故事。
一、起源
决策树模型,通过对训练样本的学习,建立分类规则;依据分类规则,实现对新样本的分类;属于有指导(监督)式的学习方法,有两类变量:目标变量(输出变量),属性变量(输入变量)。
决策树模型与一般统计分类模型的主要区别:决策树的分类是基于逻辑的,一般统计分类模型是基于非逻辑的。
常见的算法有CHAID、CART、Quest和C5.0。对于每一个决策要求分成的组之间的“差异”最大。各种决策树算法之间的主要区别就是对这个“差异”衡量方式的区别。
决策树很擅长处理非数值型数据,这与神经网络智能处理数值型数据比较而言,就免去了很多数据预处理工作。[[[] 小白学数据,http://www.cnblogs.com/yuyang-DataAnalysis/archive/2011/10/12/2205742.html]]
概念
CHAID
卡方自动交互检验 (Chi-squared Automatic Interaction) 1、计算节点中类别的p值。根据p值的大小决定决策树是否生长不需要修剪(与前两者的区别)
2、CHAID只能处理类别型的输入变量,因此连续型的输入变量首先要进行离散处理,而目标变量可以定距或定类
3、可产生多分枝的决策树
4、从统计显著性角度确定分支变量和分割值,进而优化树的分枝过程
5、建立在因果关系探讨中,依据目标变量实现对输入变量众多水平划分
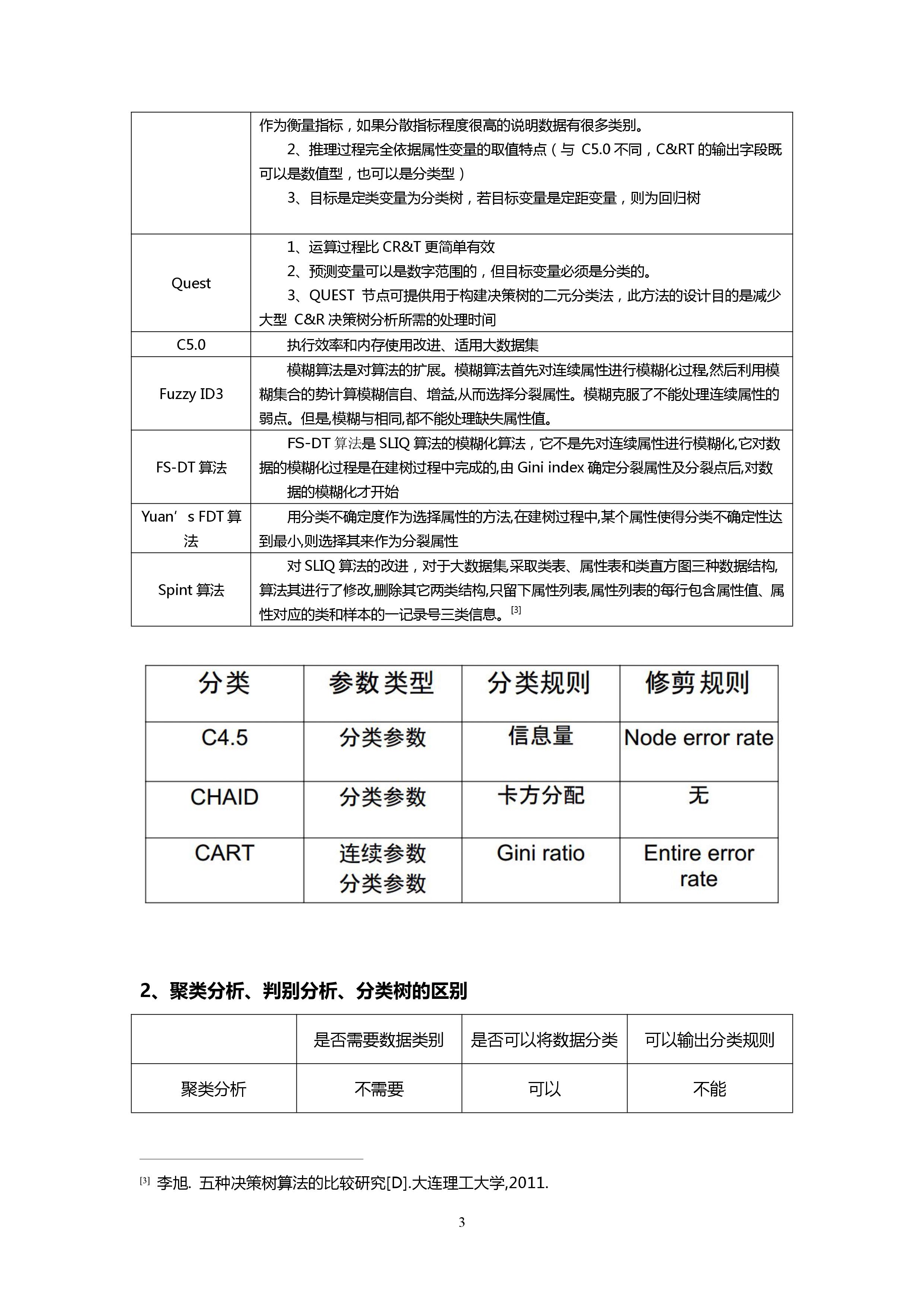
CART 1、节点采用二分法(与C4.5最大的区别,c4.5可以有很多分支);用Gini Ratio作为衡量指标,如果分散指标程度很高的说明数据有很多类别。
2、推理过程完全依据属性变量的取值特点(与 C5.0不同,C&RT的输出字段既可以是数值型,也可以是分类型)
3、目标是定类变量为分类树,若目标变量是定距变量,则为回归树
Quest 1、运算过程比CR&T更简单有效
2、预测变量可以是数字范围的,但目标变量必须是分类的。
3、QUEST 节点可提供用于构建决策树的二元分类法,此方法的设计目的是减少大型 C&R决策树分析所需的处理时间
C5.0 执行效率和内存使用改进、适用大数据集
Fuzzy ID3 模糊算法是对算法的扩展。模糊算法首先对连续属性进行模糊化过程,然后利用模糊集合的势计算模糊信自、增益,从而选择分裂属性。模糊克服了不能处理连续属性的弱点。但是,模糊与相同,都不能处理缺失属性值。
FS-DT算法 FS-DT算法是SLIQ算法的模糊化算法,它不是先对连续属性进行模糊化,它对数据的模糊化过程是在建树过程中完成的,由Gini index确定分裂属性及分裂点后,对数
据的模糊化才开始
Yuan’s FDT算法 用分类不确定度作为选择属性的方法,在建树过程中,某个属性使得分类不确定性达到最小,则选择其来作为分裂属性
Spint算法 对SLIQ算法的改进,对于大数据集,采取类表、属性表和类直方图三种数据结构,算法其进行了修改,删除其它两类结构,只留下属性列表,属性列表的每行包含属性值、属性对应的类和样本的一记录号三类信息。[[[] 李旭. 五种决策树算法的比较研究[D].大连理工大学,2011.]]
2、聚类分析、判别分析、分类树的区别
是否需要数据类别 是否可以将数据分类 可以输出分类规则
聚类分析 不需要 可以 不能
判别分析 需要 可以 不能
分类树 需要 可以 能
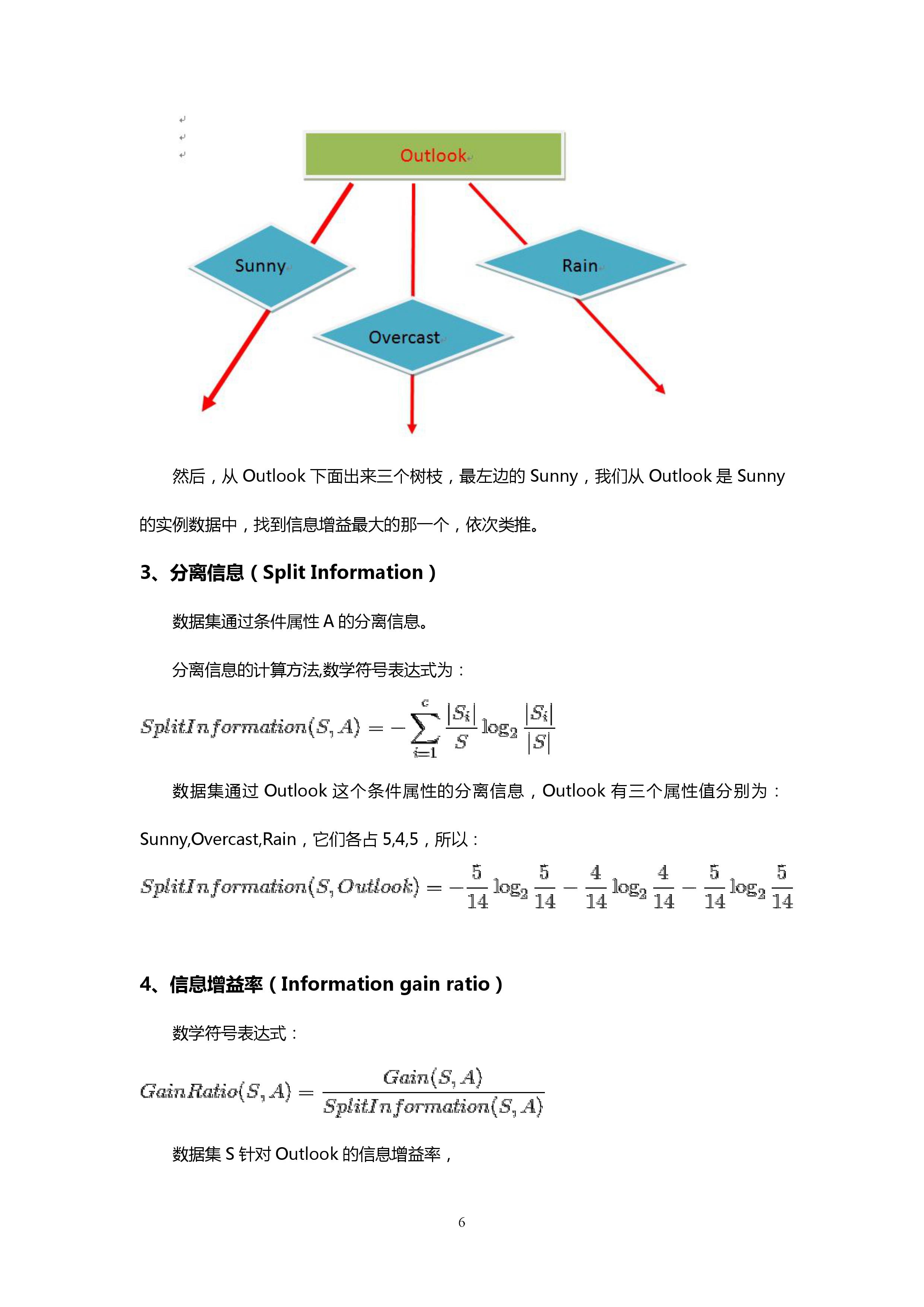
其中四个条件属性,一个决策属性(playTennis)。
1、信息熵(Entropy)
信息量的数学期望,是心愿发出信息前的平均不确定性,也称先验熵。
决策属性的Entropy(熵):
=0.940286
2、信息增益
例如outlook里面有三个属性sunny、OverCas、Rain,每个属性在决策属性中,sunny有2个yes,3个no。
=0.97095
=0
=0.97095
outlook信息增益:
=0.940286-5/14*0.97095-0-5/14*0.97095=0.24675
以下其他属性同理。
Outlook=0.24675
我们看到Outlook的信息增益是最大的,所以作为决策树的一个根节点。即:
然后,从Outlook下面出来三个树枝,最左边的Sunny,我们从Outlook是Sunny的实例数据中,找到信息增益最大的那一个,依次类推。
3、分离信息(Split Information)
数据集通过条件属性A的分离信息。
分离信息的计算方法,数学符号表达式为:
数据集通过Outlook这个条件属性的分离信息,Outlook有三个属性值分别为:Sunny,Overcast,Rain,它们各占5,4,5,所以:
4、信息增益率(Information gain ratio)
数学符号表达式:
数据集S针对Outlook的信息增益率,
分子和分母这两个值都已经求出来,选择信息增益率最大的那个属性,作为节点。
5、剪枝
剪枝一般分两种方法:先剪枝和后剪枝。
(1)先剪枝
先剪枝方法中通过提前停止树的构造(比如决定在某个节点不再分裂或划分训练元组的子集)而对树剪枝。
先剪枝有很多方法,比如(1)当决策树达到一定的高度就停止决策树的生长;(2)到达此节点的实例具有相同的特征向量,而不必一定属于同一类,也可以停止生长(3)到达此节点的实例个数小于某个阈值的时候也可以停止树的生长,不足之处是不能处理那些数据量比较小的特殊情况(4)计算每次扩展对系统性能的增益,如果小于某个阈值就可以让它停止生长。先剪枝有个缺点就是视野效果问题,也就是说在相同的标准下,也许当前扩展不能满足要求,但更进一步扩展又能满足要求。这样会过早停止决策树的生长。
(2)后剪枝
它由完全成长的树剪去子树而形成。通过删除节点的分枝并用树叶来替换它。树叶一般用子树中最频繁的类别来标记。
(3)悲观剪枝法
使用训练集生成决策树又用它来进行剪枝,不需要独立的剪枝集。
悲观剪枝法的基本思路是:设训练集生成的决策树是T,用T来分类训练集中的N的元组,设K为到达某个叶子节点的元组个数,其中分类错误地个数为J。由于树T是由训练集生成的,是适合训练集的,因此J/K不能可信地估计错误率。所以用(J+0.5)/K来表示。设S为T的子树,其叶节点个数为L(s), 为到达此子树的叶节点的元组个数总和, 为此子树中被错误分类的元组个数之和。在分类新的元组时,则其错误分类个数为 ,其标准错误表示为: 。当用此树分类训练集时,设E为分类错误个数,当下面的式子成立时,则删掉子树S,用叶节点代替,且S的子树不必再计算。
。
三、ID3、C4.5、C5.0对比
ID3算法 C4.5 C5.0
缺点 ID3是非递增算法,单变量决策树(在分枝节点上只考虑单个属性)
只考虑属性变量是离散型 1、在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效
2、大数据集乏力。C4.5只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行
优点 1、属性变量可以是连续型的
在树构造过程中进行剪枝 1、应用于大数据集上的分类算法,主要在执行效率和内存使用方面进行了改进
2、在面对数据遗漏和输入字段很多的问题时非常稳健
3、提供强大技术以提高分类的精度
4、比一些其他类型的模型易于理解,模型退出的规则有非常直观的解释[[[] 小白学数据,http://www.cnblogs.com/yuyang-DataAnalysis/archive/2011/10/12/2205742.html]]
节点选择 信息增益最大 信息增益率最大 采用Boosting方式提高模型准确率,又称为BoostingTrees,在软件上计算速度比较快,占用的内存资源较少
剪枝 C4.5采用悲观剪枝法,它使用训练集生成决策树又用它来进行剪枝,不需要独立的剪枝集。
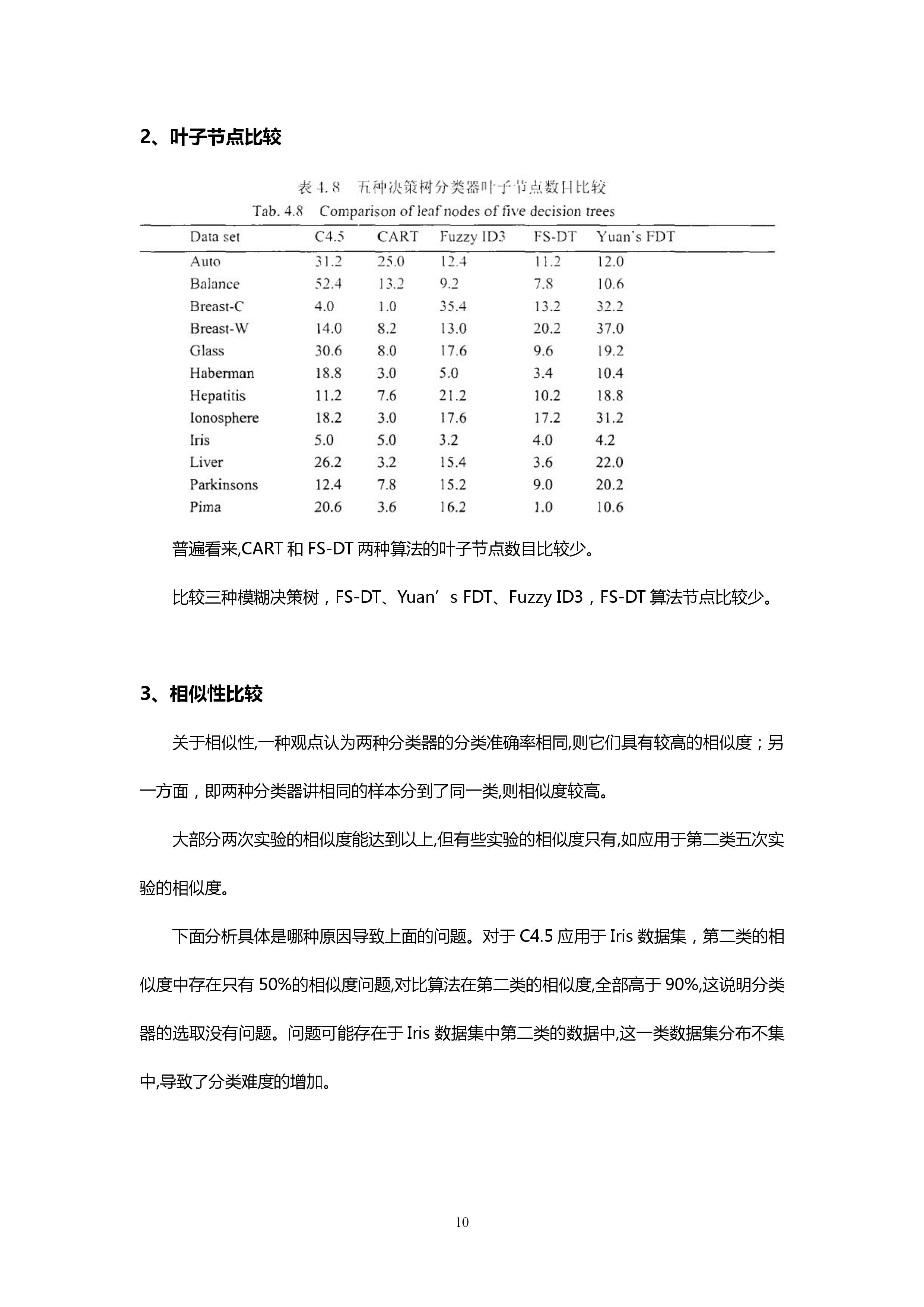
通过十七个公开数据集,对比FS-DT、Yuan’s、FDT、C4.5、Fuzzy ID3、CART五种决策树方法。
CD值,临界差值,在Nemenyi检验和Tukey检验方法两种检验方法用差异时可以用CD值来衡量。得分越低,表示相应的算法的准确率越高。
Fuzzy ID3比FS-DT表现优秀。
普遍看来,CART和FS-DT两种算法的叶子节点数目比较少。
比较三种模糊决策树,FS-DT、Yuan’s FDT、Fuzzy ID3,FS-DT算法节点比较少。
3、相似性比较
大部分两次实验的相似度能达到以上,但有些实验的相似度只有,如应用于第二类五次实验的相似度。
下面分析具体是哪种原因导致上面的问题。对于C4.5应用于Iris数据集,第二类的相似度中存在只有50%的相似度问题,对比算法在第二类的相似度,全部高于90%,这说明分类器的选取没有问题。问题可能存在于Iris数据集中第二类的数据中,这一类数据集分布不集中,导致了分类难度的增加。






——————————————————————————————————————
python scikit-learn决策树
写一个用iris数据进行案例练习的内容:
from sklearn.datasets import load_iris
from sklearn import tree
import sys
import os
iris = load_iris()
clf = tree.DecisionTreeClassifier()
clf = clf.fit(iris.data, iris.target)载入iris数据,之后是画图函数。
from IPython.display import Image as Images
import pydotplus
from PIL import Image, ImageDraw, ImageFont
from io import BytesIO
import numpy as np
dot_data = tree.export_graphviz(clf, out_file=None, feature_names=iris.feature_names, class_names=iris.target_names, filled=True, rounded=True, special_characters=True) graph = pydotplus.graph_from_dot_data(dot_data)Images(graph.create_png()) 在ipython的notebook生成的图如下:
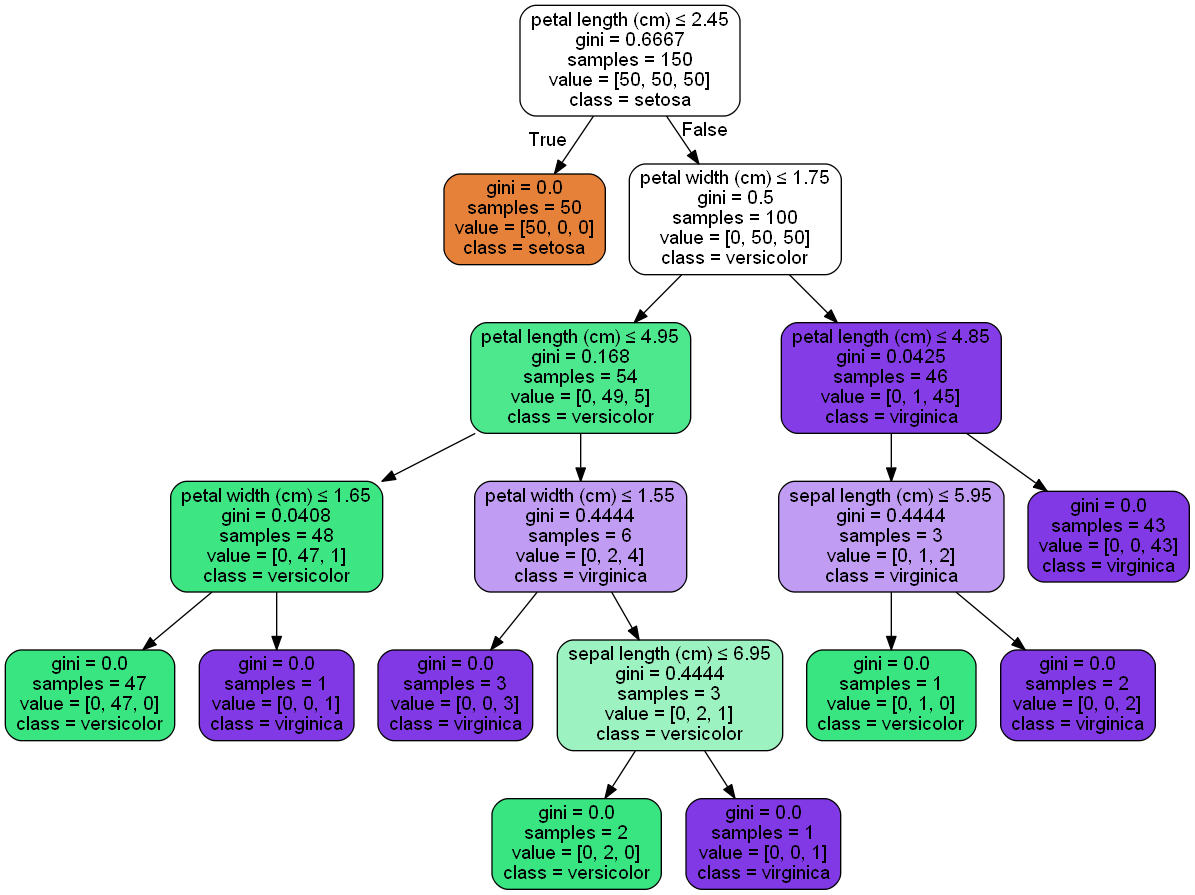
其中解析一下这张图:
通过剪枝,把很多不必要的枝叶进行删减,保留有效节点;根据gini系数来判定节点,划分最优属性,gini越大,分割贡献越大,越容易成为高层节点。
颜色信息,这边virginica——紫色/2;versicolor——绿色/1;setosa——橙色/0。gini系数的大小,代表颜色的深浅,gini越大,颜色越浅。
samples代表这个节点的样本数量,value = [0,2,1]代表三种种类的样本数量分别是多少。
一般来说,紫色越多的分支,分类效力越高。
如果要保存图片,可以使用下面的语句:
Image.open(BytesIO(graph.create_png())).save('roi.png')如何选择最优路径的一些准则,笔者自己整理,勿怪:
紫色扎堆、链路较短、而且完整链路上只有紫色会更好;链路最低端最好是gini = 0
该篇博客有调参心得【scikit-learn决策树算法类库使用小结】:
除了这些参数要注意以外,其他在调参时的注意点有:
1)当样本少数量但是样本特征非常多的时候,决策树很容易过拟合,一般来说,样本数比特征数多一些会比较容易建立健壮的模型
2)如果样本数量少但是样本特征非常多,在拟合决策树模型前,推荐先做维度规约,比如主成分分析(PCA),特征选择(Losso)或者独立成分分析(ICA)。这样特征的维度会大大减小。再来拟合决策树模型效果会好。
3)推荐多用决策树的可视化(下节会讲),同时先限制决策树的深度(比如最多3层),这样可以先观察下生成的决策树里数据的初步拟合情况,然后再决定是否要增加深度。
4)在训练模型先,注意观察样本的类别情况(主要指分类树),如果类别分布非常不均匀,就要考虑用class_weight来限制模型过于偏向样本多的类别。
5)决策树的数组使用的是numpy的float32类型,如果训练数据不是这样的格式,算法会先做copy再运行。
6)如果输入的样本矩阵是稀疏的,推荐在拟合前调用csc_matrix稀疏化,在预测前调用csr_matrix稀疏化。
最后
以上就是无限大神最近收集整理的关于决策树之ID3、C4.5、C5.0等五大算法及python实现的全部内容,更多相关决策树之ID3、C4内容请搜索靠谱客的其他文章。






![代码chaid_[转载]经典决策树之SAS实现--CHAID](https://www.shuijiaxian.com/files_image/reation/bcimg25.png)

发表评论 取消回复