我是靠谱客的博主 舒服小松鼠,这篇文章主要介绍机器学习分类问题指标——Accuracy,Precision、Recall、F1,P-R,ROC,AUC(以鸢尾花为例),现在分享给大家,希望可以做个参考。
文章目录
- 1、基本属性:TP、TN、FP、FN
- 2、精确率(Precision),召回率(Recall),准确率(Accuracy)
- 3、F1-Score(精确率和召回率的调和平均数)
- 4、P-R Curve(精确率-召回率 曲线)
- 5、ROC曲线,AUC面积(FPR - FPR 曲线)
- 附:代码
1、基本属性:TP、TN、FP、FN
分类的结果有的四个基本属性,其他各种属性都是在此基础上计算而来的。
- TP(True Positive, 真正):将好西瓜预测为好西瓜, 即预测答案正确
- TN(True Negative,真负):将坏西瓜预测为坏西瓜,也是预测答案正确的意思。
- FP(False Positive,假正):将坏西瓜预测为好西瓜,错将其他类预测为本类
- FN(False Negative,假负):将好西瓜预测为坏西瓜,错将本类预测为其他类
# 鸢尾花数据集的特点
鸢尾花的特征有4个:
1. Sepal Length(花萼长度)
2. Sepal Width(花萼宽度)
3. Petal Length(花瓣长度)
4. Petal Width(花瓣宽度)
鸢尾花的种类有3种:
1. Iris Setosa(山鸢尾)
2. Iris Versicolour(杂色鸢尾)
3. Iris Virginica(维吉尼亚鸢尾)
| 预测为维吉尼亚鸢尾 | 预测为杂色鸢尾 | 预测为山鸢尾 | |
|---|---|---|---|
| 实际为维吉尼亚鸢尾 | 49 | 1 | 0 |
| 实际为杂色鸢尾 | 4 | 46 | 0 |
| 实际为山鸢尾 | 1 | 0 | 49 |
那么以维吉尼亚鸢尾为例
TP = 49
FP = 4+1 = 5
FN = 1+0 = 1
2、精确率(Precision),召回率(Recall),准确率(Accuracy)
精确率(Precision)
- 定义:实际的好西瓜数 / 最终预测出来的好西瓜数
- 公式:
P
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
Precision = frac{TP}{TP+FP}
Precision=TP+FPTP
其中TP+FP表示最终预测出来的好西瓜的数量。(将将好西瓜预测为好西瓜+坏西瓜预测为好西瓜) - 即当前划分到正样本类别中,被正确分类的比例(即正式正样本所占比例)。
召回率(Recall)
- 定义:预测为好西瓜且实际是好西瓜的数量 / 实际的好西瓜数
- 公式:
R
e
c
a
l
l
=
T
P
T
P
+
F
N
Recall=frac{TP}{TP+FN}
Recall=TP+FNTP
其中TP+FN为样本总数(将好西瓜预测为好西瓜+预测为坏西瓜) - 即TPR,当前分到正样本中真实的正样本所占所有正样本的比例。
准确率(Accuracy)
- 定义:正确分类的样本数 / 总样本数
- 公式:
A
c
c
u
r
a
c
y
=
T
P
+
T
N
T
P
+
T
N
+
F
P
+
F
N
Accuracy=frac{TP+TN}{TP+TN+FP+FN}
Accuracy=TP+TN+FP+FNTP+TN
其中分子为成功分类的个数,分母为所有分类的个数。
3、F1-Score(精确率和召回率的调和平均数)
F1分数(F1-score)是分类问题的一个衡量指标 。一些多分类问题的机器学习竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。
Precision和Recall的关系
- Precision 和 Recall 的值我们预期是越高越好,因为他们都代表了正确被分类的比例。
- 但是这两个值在某些场景下是存在互斥的。
比如仅仅取一个样本,并且这个样本也确实是正样本,那么Precision = 1.0, 然而 Recall 可能就会比较低(在该样本集中可能存在多个样本);
相反,如果取所有样本,那么Recall = 1.0,而Precision就会很低了。所以在这个意义上,该两处值需要有一定的约束变量来控制。 - 所以F-Score就是 Precision和 Recall的加权调和平均:
其中,当 α = 1时,则 F-Score 即为F1:
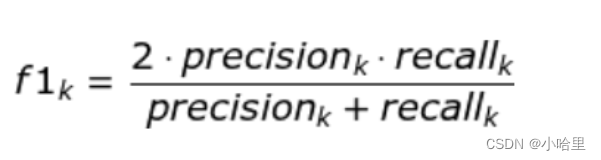
- 当有多个类别时,我们对各个类别的F1-Score求均值,就是最后的F1-score
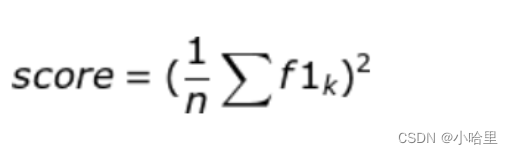
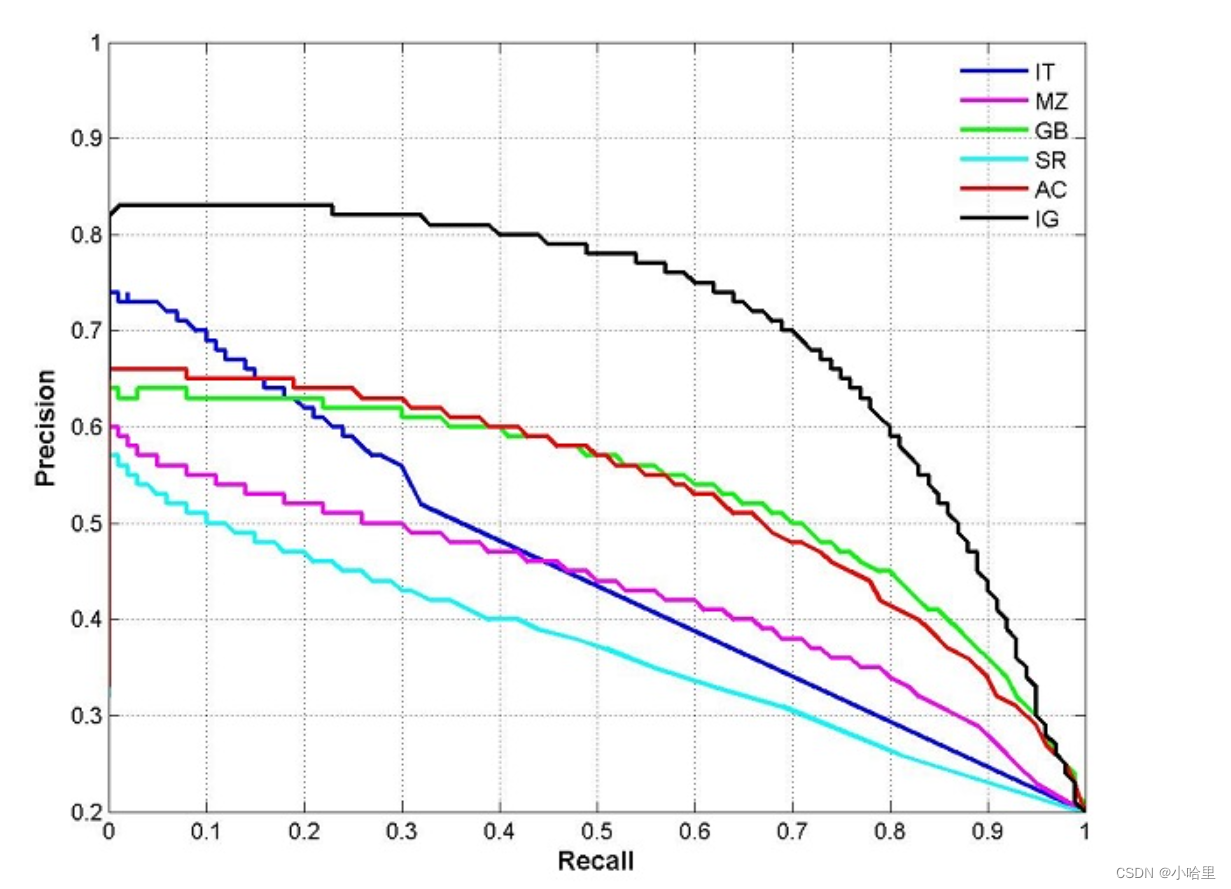
4、P-R Curve(精确率-召回率 曲线)
在P-R曲线中,横坐标是recall,纵坐标是precision。下图就是一个P-R曲线的例子:
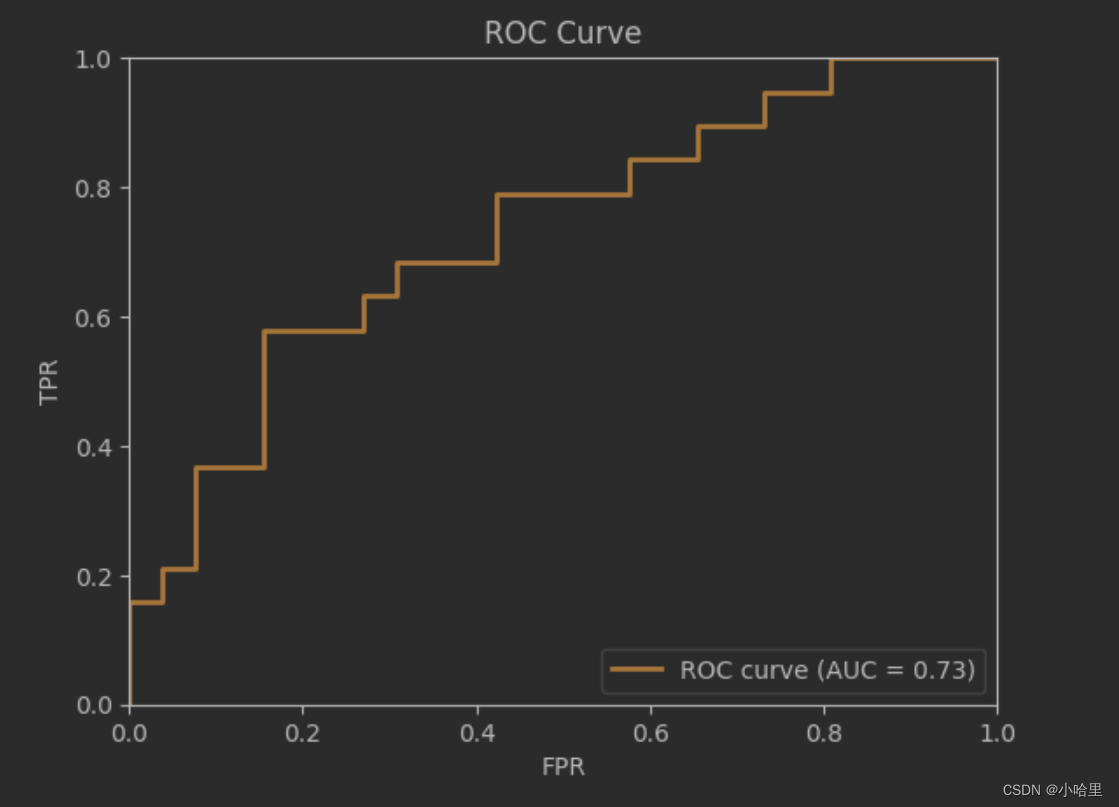
5、ROC曲线,AUC面积(FPR - FPR 曲线)
- 真正率(True Positive Rate, TPR)
公式:TPR = TP / (TP+FN)
定义:表示当前被正确分到正样本中真实的正样本 / 所有正样本的比例; - 假正率(False Positive Rate, FPR),即Recall值
公式:FPR = FP / (FP + TN)
定义:表示当前被错误分到正样本类别中真实的负样本 / 所有负样本总数的比例;
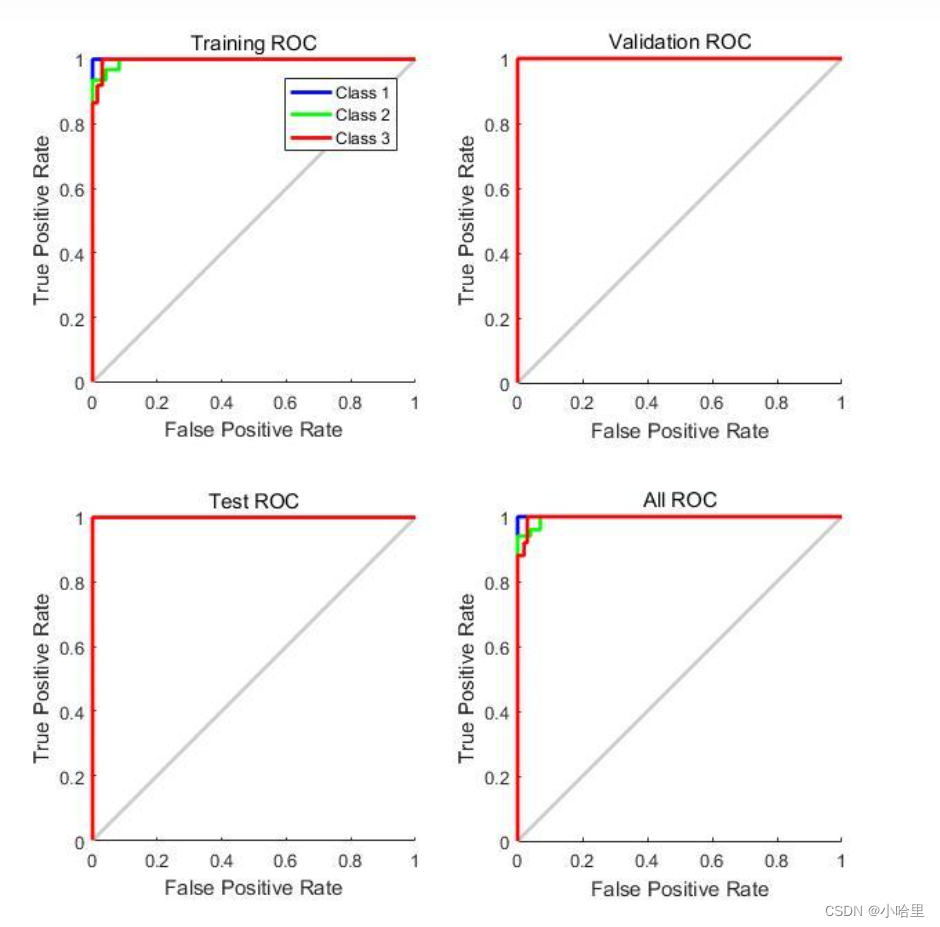
在ROC曲线中
- 横坐标是FPR(假正率),纵坐标是TPR(真正率)。
- 显然,FPR越低越好,TPR越高越好。
- 下图就是一个ROC曲线的例子
AUC 即ROC曲线下的面积。
- 计算方式即为ROC Curve的微积分值。
- 其物理意义可以表示为:随机给定一正一负两个样本,将正样本排在负样本之前的概率。
- 因此AUC越大,说明正样本越有可能被排在负样本之前,即分类额结果越好。
ROC和AUC的用处
- ROC 可以反映二分类器的总体分类性能,但是无法直接从图中识别出分类最好的阈值,事实上最好的阈值也是视具体的场景所定。
- ROC Curve 对应的AUC越大(或者说对于连续凸函数的ROC曲线越接近(0,1) )说明分类性能越好
- ROC曲线一定是需要在 y = x之上的,否则就是一个不理想的分类器。
附:代码
from sklearn.datasets import load_iris
from sklearn import tree, svm, datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
import numpy as np
# 加载数据集
iris = load_iris()
X = iris.data # 特征
y = iris.target # 标签
n_samples, n_features = X.shape
# 清洗数据集
random_state = np.random.RandomState(0)
X = np.c_[X, random_state.randn(n_samples, 200 * n_features)] # 引入random
y = label_binarize(y, classes=[0, 1, 2]) # 标签二值化, 把yes和no转化为0和1
n_classes = y.shape[1]
# 分割数据集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=33)
# 引入训练模型
# clf = tree.DecisionTreeClassifier() # 决策树
clf = OneVsRestClassifier(svm.SVC(kernel='linear', probability=True)) # 线性分类svm
# 开始训练
# clf.fit(X_train,y_train)
y_score = clf.fit(X_train, y_train).decision_function(X_test)
# 预测
y_predict=clf.predict(X_test)
# 计算F1-Score值
from sklearn.metrics import classification_report
print(clf.score(X_test,y_test)) # 使用均方误差对其进行打分,输出精确度,输出结果为0.9111, 随机后0.3555
print(classification_report(y_predict,y_test)) # F1-Score
# 输出结果为(012 分别表示3个标签的值)
'''
precision recall f1-score support
0 0.64 0.88 0.74 8
1 0.13 0.29 0.18 7
2 0.37 0.70 0.48 10
micro avg 0.36 0.64 0.46 25
macro avg 0.38 0.62 0.47 25
weighted avg 0.39 0.64 0.48 25
samples avg 0.36 0.36 0.36 25
'''
# 计算fpr和tpr
from sklearn.metrics import roc_curve, auc
fpr = dict()
tpr = dict()
roc_auc = dict()
# 用一个分类器对应一个类别,每个分类器都把其他全部的类别作为相反类别看待。
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test[:, i], y_score[:, i]) # 取当前类这一列的实际标签和预测标签
roc_auc[i] = auc(fpr[i], tpr[i]) # 计算AUC面积
# 绘制ROC曲线
import matplotlib.pyplot as plt
plt.figure()
plt.title("ROC Curve")
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.plot(fpr[2], tpr[2], color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc[2])
plt.legend(loc="lower right")
plt.show()
最后
以上就是舒服小松鼠最近收集整理的关于机器学习分类问题指标——Accuracy,Precision、Recall、F1,P-R,ROC,AUC(以鸢尾花为例)的全部内容,更多相关机器学习分类问题指标——Accuracy内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复