文章目录
- 一、产生Fault 异常的可能原因?
- 1.1 Fault 异常类别
- 1.2 Fault 状态寄存器
- 1.3 Fault 异常初始化配置
- 二、如何分析Fault 异常?
- 三、分析Fault 示例
- 3.1 如何借助IDE 或Ozone 分析fault?
- 3.2 如何设计fault handlers 输出fault log?
- 3.3 如何利用Fault Address Register?
- 更多文章:
我们在开发嵌入式代码时,经常会遇到处理器无法启动或系统停止响应的情况,引起这种症状的原因可能有很多,其中一些可能是硬件问题(比如供电、时钟等),更常见的是处理器触发了Fault 异常,并停留在Fault 异常处理程序内循环(默认情况下,Fault handler 在启动代码中定义为死循环),我们如何分析产生Fault 异常的原因呢?
一、产生Fault 异常的可能原因?
1.1 Fault 异常类别
为了方便我们分析程序产生Fault 的原因,ARM Cortex-M 提供了系统异常处理机制,当Fault 发生时会执行相应的Fault 异常处理程序,我们可以在Fault 异常处理程序中尝试定位或解决相应的Fault 异常。
Cortex-M 提供了哪些Fault 异常类型呢?我们可以从中断向量表中获知(参见博文:中断向量表):
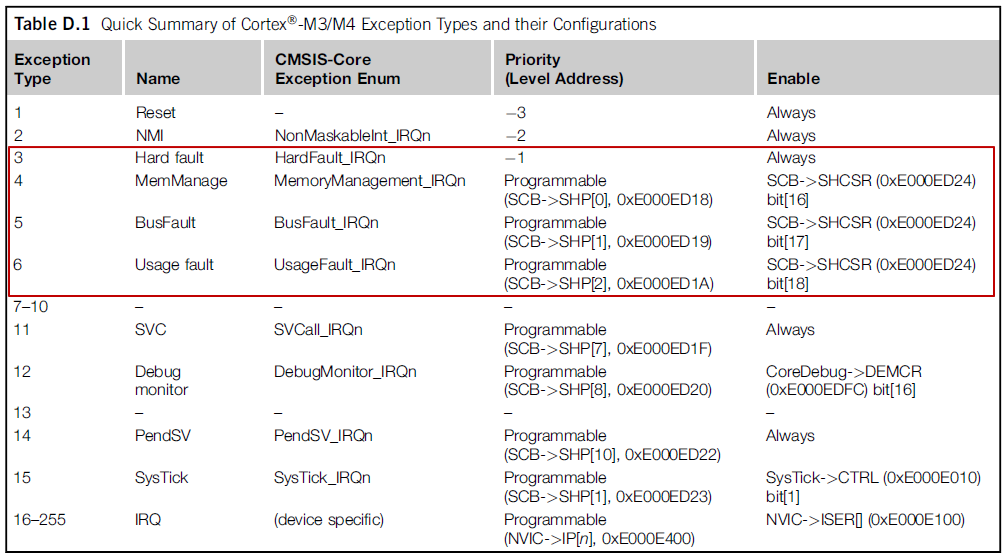
从上表可知,Cortex-M 的Fault 异常主要分为四类(Debug monitor 异常用于前篇博文谈到的两种调试模式中调试监视器模式,也即当发生调试事件时,系统不暂停而是去执行DebugMonitor_Handler 程序):
- MemManage fault:存储器管理故障,主要由违反MPU 定义的访问规则引起的,比如试图访问不被允许的存储区域、从不允许访问的存储区域取指令或读写数据等;
- BusFault:总线访问故障,主要由内存访问期间从处理器总线接口接收到的错误响应触发,比如处理器尝试访问无效的内存位置、设备尚未准备好接收数据传输等;
- Usage fault:用法错误,主要由错误的处理器操作引起的,比如执行未定义的指令、无效的异常返回码EXC_RETURN、未对齐的内存访问、执行除零操作等;
- Hard fault:硬故障(固定优先级为 -1,即它比除 NMI 以外的所有其它中断或异常具有更高的优先级),可能由MemManage fault、BusFault、Usage fault上访而来(若这些fault 未启用,则会强制进入Hard fault 异常处理程序),也可能因取中断向量失败触发。
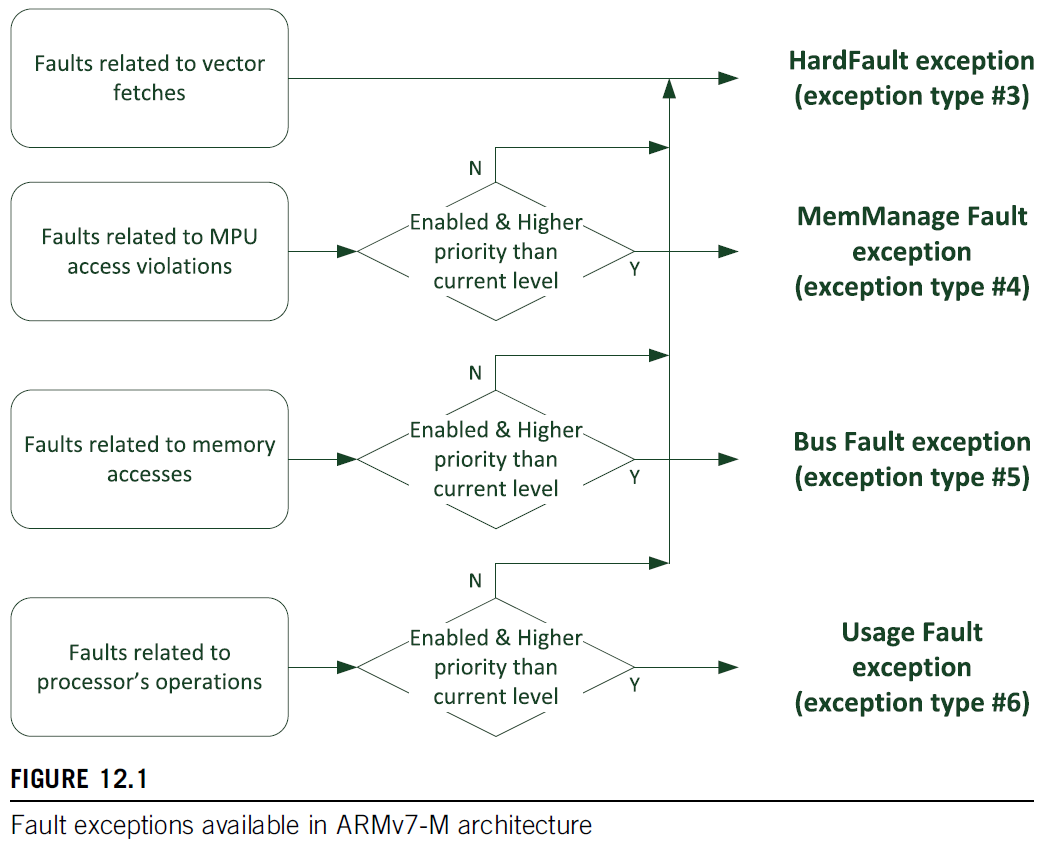
Cortex-M 处理器是如何检测到系统出现Fault 异常的呢?当处理器进入Fault 异常处理程序后,我们如何判断系统是因为什么原因、在哪个地方引起的Fault 异常呢?
1.2 Fault 状态寄存器
嵌入式处理器的执行状态一般都是通过相应的寄存器展示的,Cortex-M 为了支持Fault 异常处理机制,也提供了一些状态寄存器及地址寄存器,状态寄存器的每一位表示一种Fault 异常原因,地址寄存器则提供发生Fault 的存储地址:
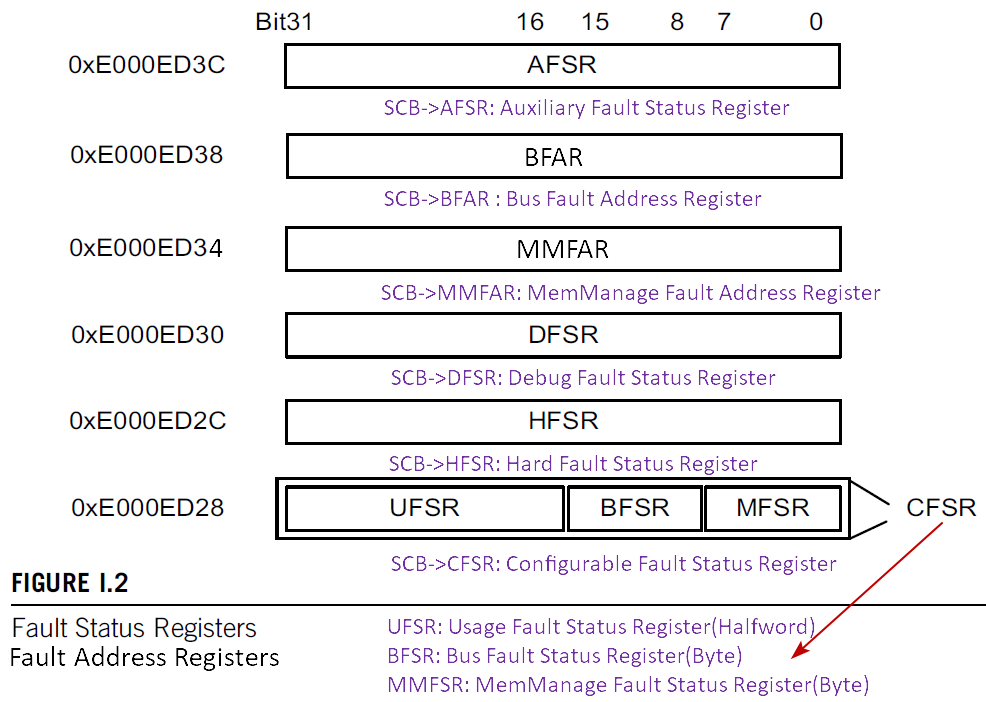
Fault 状态寄存器表示的故障原因如下(方括号内数字表示相应寄存器的第几位,未列出的位为保留位,暂没有使用):
// MMFSR: MemManage Fault Status Register (lowest byte in SCB->CFSR)
[7] MMARVALID - 如果为1,则表示MMFAR寄存器存储的MemManageFault寻址值有效。
[5] MLSPERR - 如果为1,则表示惰性保存浮点状态时发生错误。
[4] MSTKERR - 如果为1,则表示在中断或异常入栈时企图访问不被允许的区域。
[3] MUNSTKERR - 如果为1,则表示在中断或异常出栈时企图访问不被允许的区域。
[1] DACCVIOL - 如果为1,则表示企图从不允许访问的区域读、写数据。
[0] IACCVIOL - 如果为1,则表示企图从不允许访问的区域取指令。
// MMFAR: MemManage Fault Address Register (0xE000ED34, SCB->MMFAR)
[31:0] ADDRESS - 当MMARVALID 的值为1时,MMFAR 记录在访问哪个地址时发生了MemManage Fault。
// BFSR: Bus Fault Status Register (2nd byte in SCB->CFSR)
[15] BFARVALID - 如果为1,则表示BFAR寄存器存储的BusFault 寻址值有效。
[13] LSPERR - 如果为1,则表示惰性保存浮点状态时发生错误。
[12] STKERR - 如果为1,则表示入栈时发生错误。
[11] UNSTKERR - 如果为1,则表示出栈时发生错误。
[10] IMPRECISERR - 如果为1,则表示不精确的数据总线错误。
[9] PRECISERR - 如果为1,则表示精确的数据总线错误。
[8] IBUSERR - 如果为1,则表示指令提取错误。
// BFAR: Bus Fault Address Register (0xE000ED38, SCB->BFAR)
[31:0] ADDRESS - 当BFARVALID的值为1时,BFAR 记录在访问哪个地址时发生了Bus Fault。
// UFSR: Usage Fault Status Register (Upper half-word in SCB->CFSR)
[25] DIVBYZERO - 如果为1,则表示企图执行除 0 操作。
[24] UNALIGNED - 如果为1,则表示企图执行非对齐访问。
[19] NOCP - 如果为1,则表示企图执行不受支持的协处理器指令。
[18] INVPC - 如果为1,则表示将非法或无效的EXC_RETURN值加载到PC。
[17] INVSTATE - 如果为1,则表示试图切换到 ARM 状态。
[16] UNDEFINSTR - 如果为1,则表示企图执行未定义指令。
// HFSR: Hard Fault Status Register (0xE000ED2C ,SCB->HFSR)
[31] DEBUGEVT - 如果为1,则表示发生了一个调试事件。
[30] FORCED - 如果为1,则表示该Hard Fault 是由MemManage Fault、Bus Fault 或Usage Fault 引起的。
[1] VECTTBL - 如果为1,则表示取中断向量时出错。
// DFSR: Debug Fault Status Register (0xE000ED30 ,SCB->DFSR)
[4] EXTERNAL - 如果为1,则表示因外部调试请求触发了调试事件。
[3] VCATCH - 如果为1,则表示因发生向量捕获触发了调试事件。
[2] DWTTRAP - 如果为1,则表示因数据监测点匹配触发了调试事件。
[1] BKPT - 如果为1,则表示因执行BKPT 指令触发了调试事件。
[0] HALTED - 如果为1,则表示调试器请求处理器进入暂停模式。
// AFSR: Auxiliary Fault Status Register (0xE000ED3C, SCB->AFSR)
[31:0] Implementation Defined - 允许芯片设计人员添加自己的故障状态信息。
了解了各类Fault 状态寄存器每一位指示的fault 原因,我们就可以在程序进入fault 异常处理程序后,通过查看上述Fault 状态寄存器哪一位被置为 1 了,了解到产生fault 的可能原因。我们如何定位产生fault 的具体代码呢?
1.3 Fault 异常初始化配置
在回答这个问题前,我们还有个问题,这些fault 寄存器及其异常处理程序在使用前需要怎么初始化呢?
我们在使用中断或异常之前,通常需要先为其配置优先级并使能中断,处理器才会处理并响应对应的中断信号,前面介绍的四种 fault 异常只有Hard Fault 是固定优先级-1,默认开启,其余三种都是默认未开启状态。如果我们想让MemManage Fault、Bus Fault、Usage Fault、Debug Fault 异常处理程序可以正常响应,需要先为其配置优先级并使能对应的异常,配置方法如下(如果上述异常未配置或未开启,处理器也会上访为Hard Fault,去执行Hard Fault Handler):
#define SCB_BASE 0xE000ED00UL /*!< System Control Block Base Address */
/* Structure type to access the System Control Block (SCB). */
typedef struct
{
......
__IOM uint32_t CCR; /*!< Offset: 0x014 (R/W) Configuration Control Register */
__IOM uint8_t SHP[12U]; /*!< Offset: 0x018 (R/W) System Handlers Priority Registers (4-7, 8-11, 12-15) */
__IOM uint32_t SHCSR; /*!< Offset: 0x024 (R/W) System Handler Control and State Register */
__IOM uint32_t CFSR; /*!< Offset: 0x028 (R/W) Configurable Fault Status Register */
__IOM uint32_t HFSR; /*!< Offset: 0x02C (R/W) HardFault Status Register */
__IOM uint32_t DFSR; /*!< Offset: 0x030 (R/W) Debug Fault Status Register */
__IOM uint32_t MMFAR; /*!< Offset: 0x034 (R/W) MemManage Fault Address Register */
__IOM uint32_t BFAR; /*!< Offset: 0x038 (R/W) BusFault Address Register */
__IOM uint32_t AFSR; /*!< Offset: 0x03C (R/W) Auxiliary Fault Status Register */
......
} SCB_Type;
/* Enable the MemManage Fault exception handler */
void MemManage_Handler(void); // 实现MemManage Fault 异常处理函数
NVIC_SetPriority(MemoryManagement_IRQn, priority); // 配置MemManage Fault 中断优先级,实际上配置的是SCB->SHP 寄存器
SCB->SHCSR |= SCB_SHCSR_MEMFAULTENA_Msk; // 使能MemManage Fault 中断或异常, 实际上设置SCB->SHCSR 的bit 16 为 1
/* Enable the Bus Fault exception handler */
void BusFault_Handler(void); // 实现Bus Fault 异常处理函数
NVIC_SetPriority(BusFault_IRQn, priority); // 配置Bus Fault 中断优先级,实际上配置的是SCB->SHP 寄存器
SCB->SHCSR |= SCB_SHCSR_BUSFAULTENA_Msk; // 使能Bus Fault 中断或异常, 实际上设置SCB->SHCSR 的bit 17 为 1
/* Enable the Usage fault exception handler */
void UsageFault_Handler(void); // 实现Usage fault 异常处理函数
NVIC_SetPriority(UsageFault_IRQn, priority); // 配置Usage fault 中断优先级,实际上配置的是SCB->SHP 寄存器
SCB->SHCSR |= SCB_SHCSR_USGFAULTENA_Msk; // 使能Usage fault 中断或异常, 实际上设置SCB->SHCSR 的bit 18 为 1
/* Hard Fault 异常默认开启,固定优先级 -1,根据需要实现HardFault_Handler */
void HardFault_Handler(void); // 默认的HardFault_Handler 为死循环,根据需要实现对应的Hard Fault 异常处理函数
还需要提醒一点的是,对于部分Usage fault 异常,比如DIVBYZERO 或UNALIGNED,Cortex-M 处理器默认是不捕获的,也即忽略该类型异常,如果想让处理器捕获相应的异常,也需要通过配置相应的寄存器实现,配置方法如下:
/* 设置处理器捕获除零操作错误 */
SCB->CCR |= SCB_CCR_DIV_0_TRP_Msk; // 设置寄存器SCB->CCR 的bit 4 为 1,启用捕获除零故障
/* 设置处理器捕获非对齐访问错误 */
SCB->CCR |= SCB_CCR_UNALIGN_TRP_Msk; // 设置寄存器SCB->CCR 的bit 3 为 1,启用捕获非对齐访问故障
了解了如何初始化或配置Fault 中断或异常,再回头考虑如何分析定位Fault 异常呢?
二、如何分析Fault 异常?
在嵌入式软件开发过程中遇到Fault 异常的情况并不少见,大多数情况下,我们可以从fault 状态和地址寄存器得知处理器发生了哪种异常?可能是由什么原因导致的?接下来我们怎么分析定位产生fault 的具体代码呢?
从前篇博文ARM Debug and Trace可知,我们可以通过Debug Port 和Trace Port 获得处理器运行的调试信息和跟踪信息,借助这些调试跟踪信息,我们分析fault 可以有三个方向:
- Call Stack Trace:处理器触发Fault 异常后,我们可以在fault 异常处理函数中设置断点,处理器触发fault 后暂停执行,我们可以查看CPU寄存器和fault 相关寄存器值。除此之外,还可以从SP 指针跟踪在发生fault 之前的堆栈寄存器值(主要是PC值和LR值),继续跟踪LR 值可以获得进入fault_handler 之前的函数调用链,再借助fault status 寄存器值通常可以快速定位到产生fault 的代码并解决该bug;
- Event Trace:需要借助Trace Port(SWO 或Clocked Trace Port) 获得DWT与ITM 跟踪数据,了解到处理器内部事件发生的时序信息,从发生fault 事件的时间点往前追溯系统都发生了什么事件,再借助fault status 寄存器值通常可以快速定位是什么事件触发了fault 异常,从而使查找原因更容易;
- Instruction Trace:需要借助Trace Port(SWO 或Clocked Trace Port) 获得ETM 跟踪数据,了解到处理器内部执行的指令序列,从进入fault handler 执行的指令往前追溯处理器在发生fault 之前都依次执行了什么指令,再借助fault status 寄存器值通常可以快速定位是那几条指令触发了fault 异常,从而使查找原因更容易。
对于相对简单的系统,我们通常只需要使用Call Stack Trace 即可快速定位产生fault 的代码。指令执行流或者事件触发比较复杂的系统,借助Event Trace 和Instruction Trace 可以帮我们更快分析fault 产生的原因,不过需要借助Trace Port 多占用几个引脚(本文仅介绍Call Stack Trace 分析方法)。
Cortex-M 默认MemManage Fault、Bus Fault、Usage Fault 未开启,仅Hard Fault 默认开启,如果没有启用前三种fault,处理器发生任何fault 都会进入HardFault_Handler。
HardFault_Handler 函数默认是死循环,我们在调试模式下执行到该函数内手动暂停,或者在该函数内添加断点,就可以查看发生Fault 时寄存器和内存的值,也可以从Fault status 寄存器值获知发生了哪种fault,以及产生该fault 的大概原因。
对于Keil MDK,进入调试界面后,我们可以通过点击菜单Peripherals–> Core Peripherals–> Fault Reports 即可查看fault 相关寄存器的值。
对于SEGGER Embedded Studio,进入调试界面后,可通过点击窗口Regisrers 1 --> Groups --> SCB,在SCB 寄存器组内查看fault 相关寄存器的值。
我们要跟踪Call Stack,首先要确定发生fault 时处理器正在使用哪个堆栈(MSP 还是PSP)?当Cortex-M 进入中断或异常处理程序后,寄存器LR 的值会更新为EXC_RETURN,我们可以通过EXC_RETURN 值判断当前正在使用MSP 还是PSP?
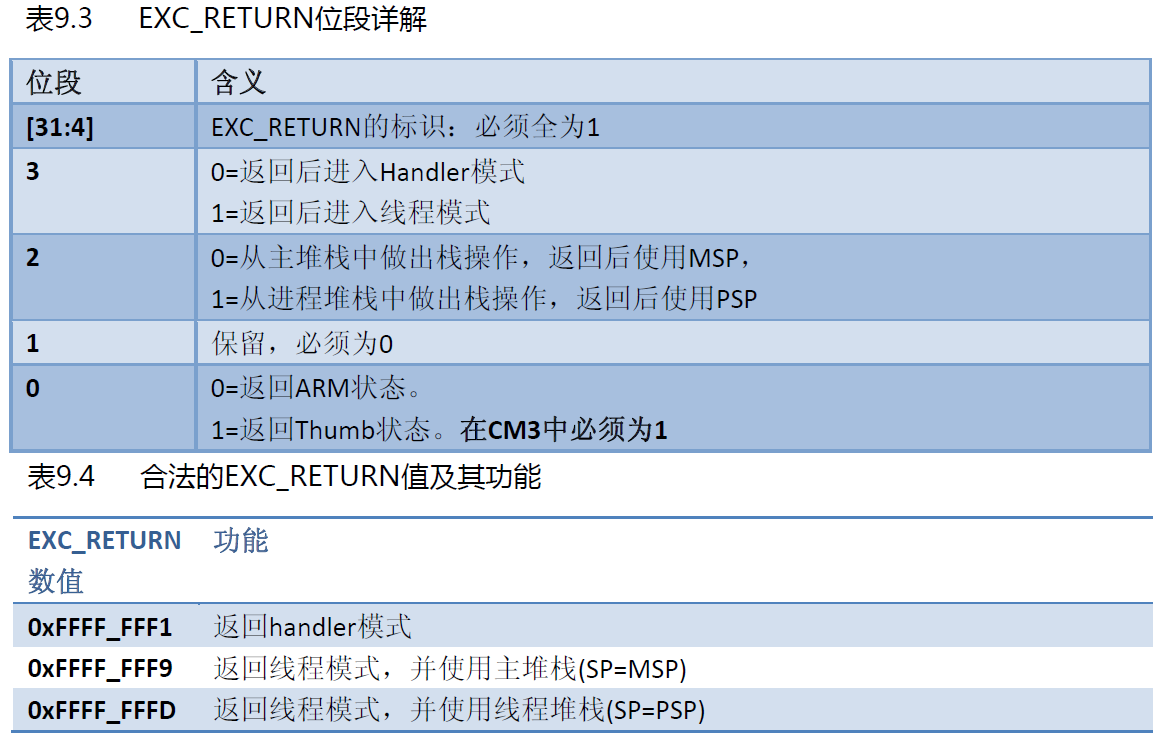
我们从EXC_RETURN 的bit 2 的值可以判断处理器当前使用的是MSP 还是PSP。然后在查找内存中SP 指针指向的位置,就可以获得进入HardFault_Handler 前的栈帧数据,按照寄存器入栈顺序,就可以获得每个寄存器的值,特别是PC 和LR 的值。
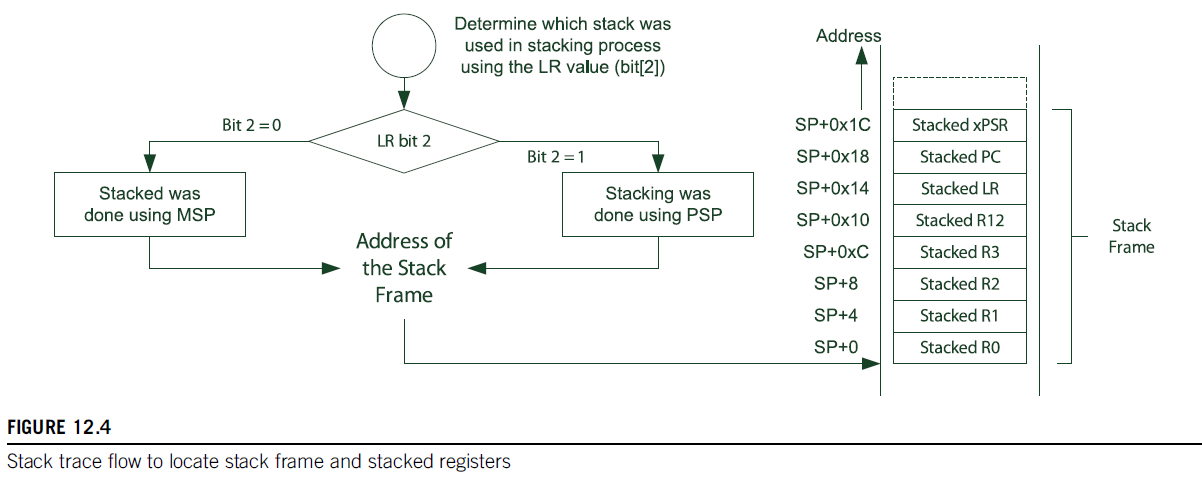
我们从Stack Frame 中获取的PC 值即为进入HardFault_Handler 前执行的指令地址,可从反汇编代码窗口查看该地址对应的汇编指令和C语言指令是哪条?Stack Frame 中LR 的值则表示PC 指向指令所在函数的返回地址,或者借助IDE 或Ozone 中的Call Stack 信息,可以得知发生Fault 前的函数调用链,方便我们快速定位产生fault 的代码行。
这些文字描述不够直观,下文通过示例程序展示分析fault 的过程。
三、分析Fault 示例
3.1 如何借助IDE 或Ozone 分析fault?
本文依然使用前篇博文的示例工程.nRF5_SDK_17.0.2_d674ddeexamplesble_peripheralble_app_uart,为了触发Fault 异常,我们在main 函数中添加点代码如下:
// .nRF5_SDK_17.0.2_d674ddeexamplesble_peripheralble_app_uartmain.c
......
/**@brief Function for Fault exception test.
*/
static int fault_test(void)
{
// Enable fault on divide-by-zero
SCB->CCR |= SCB_CCR_DIV_0_TRP_Msk;
char txt[32] = "fault exception.";
char pkg[32] = "fault";
volatile int txtlen, pkglen, count;
memset(pkg, 0, sizeof(pkg));
txtlen = strlen(txt);
pkglen = strlen(pkg);
count = txtlen / pkglen;
return count;
}
/**@brief Application main function.
*/
int main(void)
{
bool erase_bonds;
// Initialize log
log_init();
// Fault exception test
fault_test();
......
}
编译ble_app_uart 工程,SEGGER Embedded Studio 点击Debug–>Go 进入调试模式,点击continue execution,代码会执行到函数HardFault_Handler 内,该函数内部只有一条原地跳转命令"b .",点击break 暂停执行。我们可以从右边registers 1 窗口的Groups 内开启SCB 寄存器组,查看跟fault 相关的寄存器值如下:
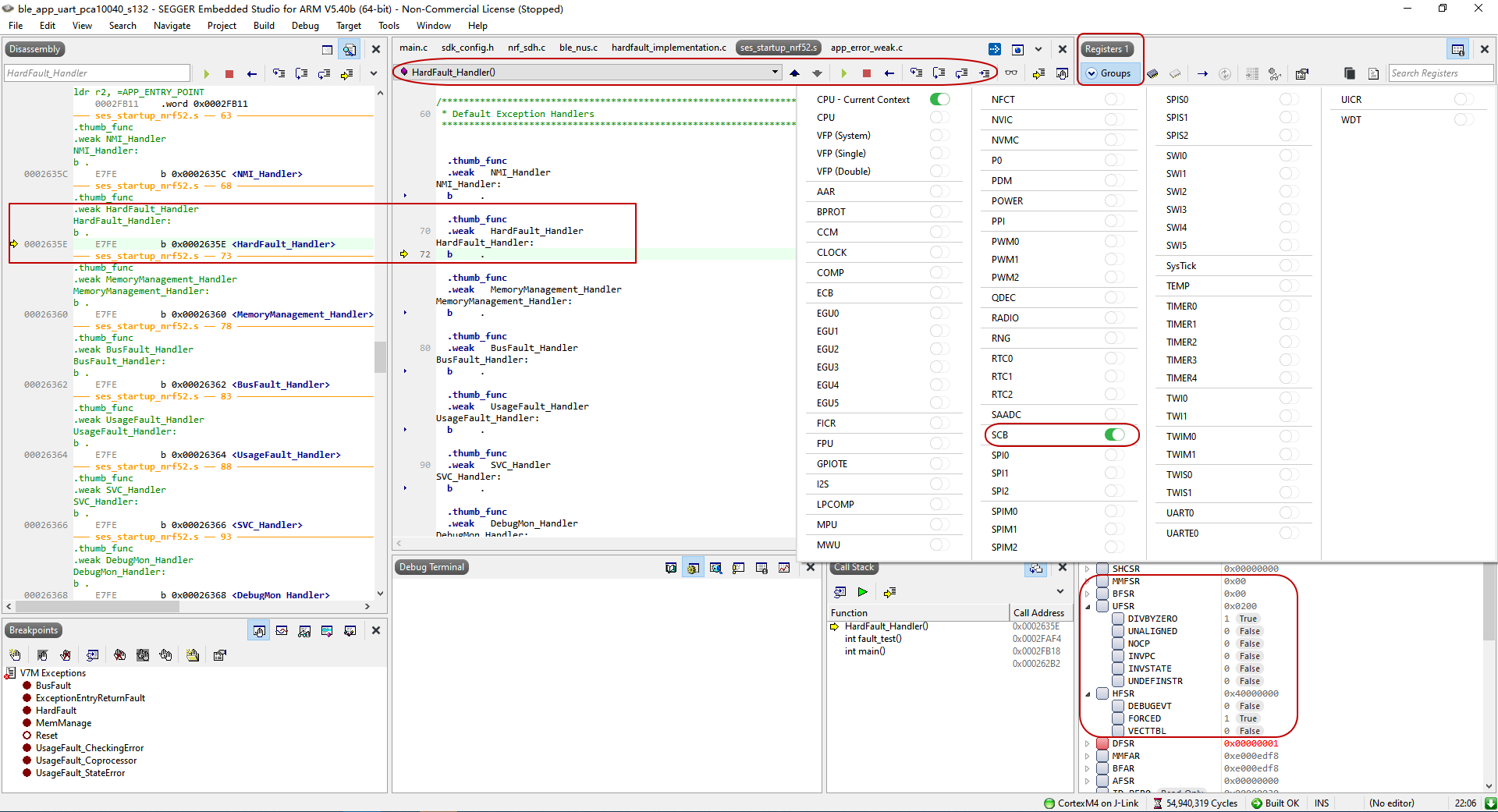
从上图可以看出,fault 相关寄存器只有HFSR->FORCED 和UFSR->DIVBYZERO 值为 1,说明该fault 是由除零操作引起的。
再查看进入HardFault_Handler 前的栈帧数据,LR 的当前值为0xFFFFFFF9 说明使用的是MSP 栈指针。SEGGER Embedded Studio 提供了CPU-Current Context 和CPU 两个寄存器组,从CPU 寄存器组可以看到MSP和PSP 的值,CPU-Current Context 寄存器组则会自动判断并显示当前使用的实际值,我们获知MSP 值为0x2000FF70。
在memory 1 窗口内通过MSP 栈指针值查询对应的栈帧数据,根据寄存器固定的入栈顺序(栈从高地址向低地址增长),可以查得PC 值为0x0002FAF4。在Disassembly 窗口内通过PC 值查得对应的汇编指令为“sdiv r3, r2, r3”,对应到C 语言代码行“count = txtlen / pkglen;”。结合定位到的C 代码上下文和前面分析的引起fault 原因(除零操作),可以很容易分析出除数pkglen 为0。
现在的IDE 调试越来越方便了,我们可以点击按钮Up One Stack Frame直接查看前一个栈帧执行的汇编指令和C 代码行,比前面的方法方便很多(前一种方法便于我们了解分析fault 的步骤),而且还可以继续往前查看函数调用栈,获知发生fault 前的函数调用链,可以帮我们快速定位产生fault 的代码行。
如果觉得SEGGER Embedded Studio 查询fault 相关寄存器的值比较麻烦,可以使用Ozone 调试工具。我们通过Debug-> Debug With Ozone 打开Ozone 调试软件,点击Download & Reset Program 按钮开始调试,系统会执行到main 函数起始位置暂停。我们继续点击Resume program execution,遇到fault exception 会自动弹出如下窗口:
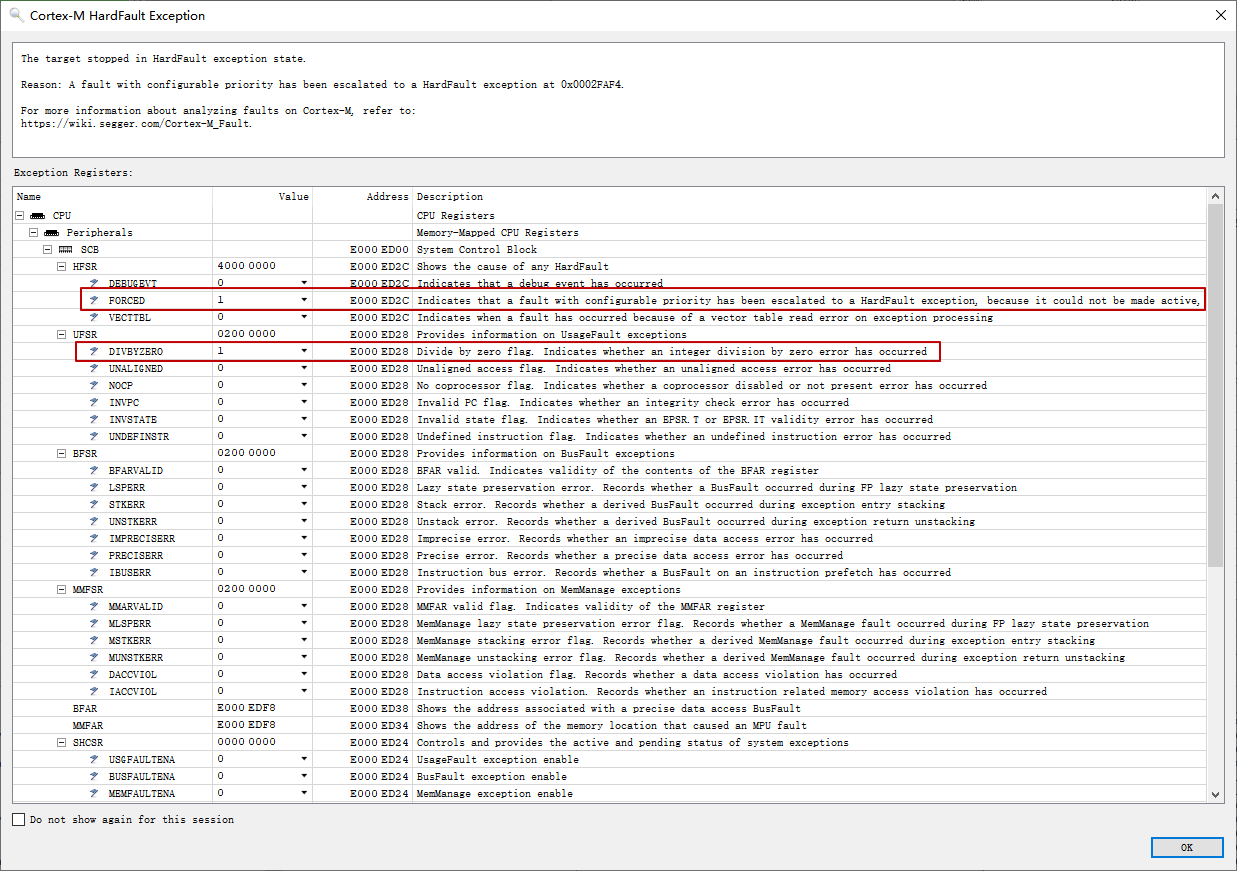
借助Ozone 分析fault exception 更方便些,遇到fault 自动弹出注释界面,fault 相关寄存器每一位表示什么意思也注释的很详细,不需要我们再去查手册了,能提高不少分析fault 的效率。
3.2 如何设计fault handlers 输出fault log?
当我们开发的嵌入式代码运行出现bug,经常通过log 日志先判断产生bug 的软件模块或大概原因。对于fault 异常只是表现为系统停止运行,陷入到HardFault_Handler 的死循环中,并没有相关log 输出,不方便我们及时判断出是出现了fault exception。我们应该怎么设计fault handlers,让系统发生fault 时通过log 输出fault log 关键信息呢?
我们依然使用前面的示例工程,可以在Project Explorer 窗口看到源文件hardfault_implementation.c,从名字就可以看出该文件是实现fault handler 输出fault log 信息的。我们可以看到该文件的实现代码如下:
// .nRF5_SDK_17.0.2_d674ddecomponentslibrarieshardfaulthardfault_implementation.c
#include "sdk_common.h"
#if NRF_MODULE_ENABLED(HARDFAULT_HANDLER)
#include "hardfault.h"
#include "nrf.h"
#include "compiler_abstraction.h"
#include "app_util_platform.h"
#ifdef SOFTDEVICE_PRESENT
#include "nrf_soc.h"
#endif
#define NRF_LOG_MODULE_NAME hardfault
#include "nrf_log.h"
#include "nrf_log_ctrl.h"
NRF_LOG_MODULE_REGISTER();
/*lint -save -e14 */
__WEAK void HardFault_process(HardFault_stack_t * p_stack)
{
// Restart the system by default
NVIC_SystemReset();
}
/*lint -restore */
void HardFault_c_handler(uint32_t * p_stack_address)
{
NRF_LOG_FINAL_FLUSH();
#if (__CORTEX_M == 0x04)
#ifndef CFSR_MMARVALID
#define CFSR_MMARVALID (1 << (0 + 7))
#endif
#ifndef CFSR_BFARVALID
#define CFSR_BFARVALID (1 << (8 + 7))
#endif
HardFault_stack_t * p_stack = (HardFault_stack_t *)p_stack_address;
static const char *cfsr_msgs[] = {
[0] = "The processor has attempted to execute an undefined instruction",
[1] = "The processor attempted a load or store at a location that does not permit the operation",
[2] = NULL,
[3] = "Unstack for an exception return has caused one or more access violations",
[4] = "Stacking for an exception entry has caused one or more access violations",
[5] = "A MemManage fault occurred during floating-point lazy state preservation",
[6] = NULL,
[7] = NULL,
[8] = "Instruction bus error",
[9] = "Data bus error (PC value stacked for the exception return points to the instruction that caused the fault)",
[10] = "Data bus error (return address in the stack frame is not related to the instruction that caused the error)",
[11] = "Unstack for an exception return has caused one or more BusFaults",
[12] = "Stacking for an exception entry has caused one or more BusFaults",
[13] = "A bus fault occurred during floating-point lazy state preservation",
[14] = NULL,
[15] = NULL,
[16] = "The processor has attempted to execute an undefined instruction",
[17] = "The processor has attempted to execute an instruction that makes illegal use of the EPSR",
[18] = "The processor has attempted an illegal load of EXC_RETURN to the PC, as a result of an invalid context, or an invalid EXC_RETURN value",
[19] = "The processor has attempted to access a coprocessor",
[20] = NULL,
[21] = NULL,
[22] = NULL,
[23] = NULL,
[24] = "The processor has made an unaligned memory access",
[25] = "The processor has executed an SDIV or UDIV instruction with a divisor of 0",
};
uint32_t cfsr = SCB->CFSR;
if (p_stack != NULL)
{
// Print information about error.
NRF_LOG_ERROR("HARD FAULT at 0x%08X", p_stack->pc);
NRF_LOG_ERROR(" R0: 0x%08X R1: 0x%08X R2: 0x%08X R3: 0x%08X",
p_stack->r0, p_stack->r1, p_stack->r2, p_stack->r3);
NRF_LOG_ERROR(" R12: 0x%08X LR: 0x%08X PSR: 0x%08X",
p_stack->r12, p_stack->lr, p_stack->psr);
}
else
{
NRF_LOG_ERROR("Stack violation: stack pointer outside stack area.");
}
if (SCB->HFSR & SCB_HFSR_VECTTBL_Msk)
{
NRF_LOG_ERROR("Cause: BusFault on a vector table read during exception processing.");
}
for (uint32_t i = 0; i < sizeof(cfsr_msgs) / sizeof(cfsr_msgs[0]); i++)
{
if (((cfsr & (1 << i)) != 0) && (cfsr_msgs[i] != NULL))
{
NRF_LOG_ERROR("Cause: %s.", (uint32_t)cfsr_msgs[i]);
}
}
if (cfsr & CFSR_MMARVALID)
{
NRF_LOG_ERROR("MemManage Fault Address: 0x%08X", SCB->MMFAR);
}
if (cfsr & CFSR_BFARVALID)
{
NRF_LOG_ERROR("Bus Fault Address: 0x%08X", SCB->BFAR);
}
#if defined(DEBUG)
NRF_BREAKPOINT_COND;
#endif // defined (DEBUG)
#endif // __CORTEX_M == 0x04
HardFault_process((HardFault_stack_t *)p_stack_address);
}
#endif //NRF_MODULE_ENABLED(HARDFAULT_HANDLER)
从上述代码可知,Nordic SDK 提供了函数HardFault_c_handler 来实现输出fault log 的功能,该功能可以通过宏HARDFAULT_HANDLER 启用。我们先在sdk_config.h 文件中开启宏HARDFAULT_HANDLER_ENABLED :
// .nRF5_SDK_17.0.2_d674ddeexamplesble_peripheralble_app_uartpca10040s132configsdk_config.h
......
// <q> HARDFAULT_HANDLER_ENABLED - hardfault_default - HardFault default handler for debugging and release
#ifndef HARDFAULT_HANDLER_ENABLED
#define HARDFAULT_HANDLER_ENABLED 1
#endif
......
函数HardFault_c_handler 需要传入一个栈指针p_stack_address,该栈指针就是进入HardFault_Handler 后的SP 值(可通过EXC_RETURN 值判断是MSP 还是PSP)。借助p_stack_address 可打印出发生fault 前的栈帧内各寄存器的值(主要是触发fault 的指令地址,也即PC 值),也可自动查询寄存器SCB->CFSR (包含UFSR、BFSR、MMFSR 三个寄存器)的值,并打印出fault Cause 和MemManage Fault Address、Bus Fault Address 等信息。
我们在Current Project 中搜索关键词HardFault_Handler,发现只在ses_startup_nrf52.s 文件内定义了函数HardFault_Handler,且定义为死循环,被.weak 修饰(该函数可被重写并取代被weak 修饰的同名函数)。我们需要重新定义HardFault_Handler 函数,让其跳转到函数HardFault_c_handler 执行,且在跳转前将SP 参数传入(需要根据LR bit 2 判断当前使用的是MSP 还是PSP),实现代码如下:
// .nRF5_SDK_17.0.2_d674ddecomponentslibrarieshardfaulthardfault_implementation.c
......
#if NRF_MODULE_ENABLED(HARDFAULT_HANDLER)
......
void HardFault_c_handler(uint32_t * p_stack_address)
{
......
}
/**
* @brief Hard Fault handler wrapper in assembly.
* It extracts the location of stack frame and passes it to handler in C as a pointer.
*/
void HardFault_Handler(void)
{
__ASM("TST LR, #4");
__ASM("ITE EQ");
__ASM("MRSEQ R0, MSP");
__ASM("MRSNE R0, PSP");
__ASM("B HardFault_c_handler");
}
#endif //NRF_MODULE_ENABLED(HARDFAULT_HANDLER)
// .nRF5_SDK_17.0.2_d674ddemodulesnrfxmdkses_startup_nrf52.s
......
.thumb_func
.weak HardFault_Handler
HardFault_Handler:
b .
......
函数HardFault_c_handler 在打印完fault log 后,如果选择Debug 工程会设置断点并暂停(宏代码NRF_BREAKPOINT_COND),否则(也即Release 工程)会去执行函数HardFault_process(实际执行的是NVIC_SystemReset,期待通过重置系统解决该fault)。我们选择Debug 工程,编译工程并烧录到nRF52DK 内,使用J-Link RTT Viewer 查看NRF_LOG 信息如下:
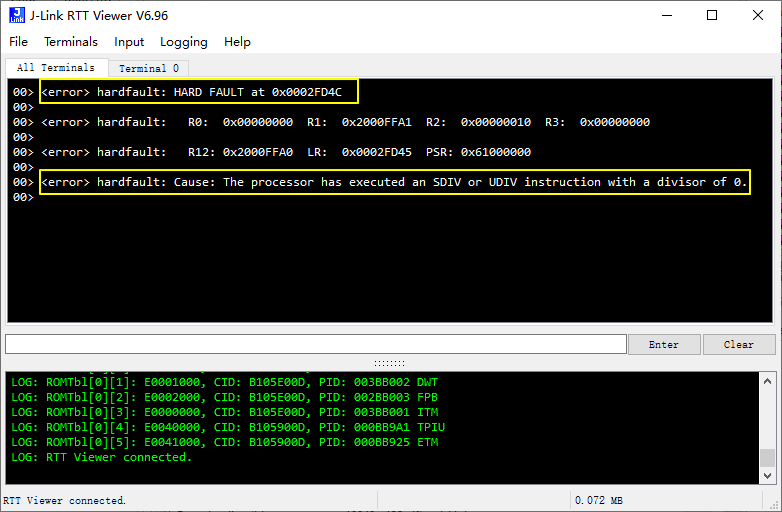
当系统发生fault exception 时,会自动执行函数HardFault_c_handler,将进入HardFault_Handler 前执行的指令地址、栈帧寄存器值、fault cause 等信息以RTT_LOG 的形式输出(也可在调试界面的Debug Terminal 窗口输出这些信息),方便我们快速判断系统在哪里发生了哪种fault?然后再进行针对性调试分析,提高定位分析解决bug 的效率。
3.3 如何利用Fault Address Register?
前面的fault_test 触发的Usage Fault 并没有用到Fault Address Register,这里修改下fault_test 代码,试图访问一个无效的存储地址,修改后的fault_test 代码如下:
// .nRF5_SDK_17.0.2_d674ddeexamplesble_peripheralble_app_uartmain.c
......
/**@brief Function for Fault exception test.
*/
static int fault_test(void)
{
int rd;
volatile unsigned int* p;
p = (unsigned int*)0x00100000; // 0x00100000-0x07FFFFFF is reserved on nRF52832
rd = *p;
return rd;
}
......
编译工程并烧录到nRF52DK 内,使用J-Link RTT Viewer 查看NRF_LOG 信息如下:
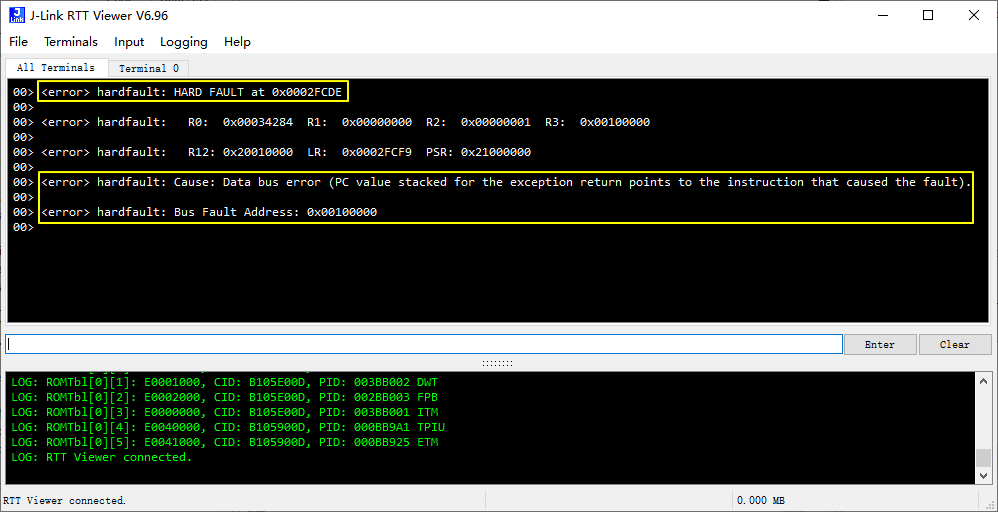
从fault log 可知,系统在执行地址0x0002FCDE 的指令(对应的C 代码:rd = * (volatile unsigned int *)0x00100000;)后发生了Bus fault,也即系统在通过数据总线试图访问地址0x00100000 (BFAR 值)时发生了bus fault。
存储地址0x00100000 在nRF52832 内是未使用的无效地址,通过总线访问该无效存储地址自然会触发bus fault,定位到产生fault 的原因就比较容易解决了。
更多文章:
- 《如何抓包分析BLE 空口报文(GAP + GATT + LESC procedure)?》
- 《代码调试跟踪与优化(二)— 如何调试嵌入式代码?》
- 《How to debug a HardFault on an ARM Cortex-M MCU》
- 《CmBacktrace: ARM Cortex-M series MCU error tracking library》
- 《Cortex-M Fault》
最后
以上就是虚拟奇迹最近收集整理的关于代码调试跟踪与优化(三)--- 如何调试Fault 异常?一、产生Fault 异常的可能原因?二、如何分析Fault 异常?三、分析Fault 示例更多文章:的全部内容,更多相关代码调试跟踪与优化(三)---内容请搜索靠谱客的其他文章。








发表评论 取消回复