阅读这篇博客之前建议先阅读R-CNN之前的准备:Efficient Graph-Based Image Segmentation 以及R-CNN之前的准备:Selective Search for Object Recognition,这两篇博客讲的内容都是R-CNN的重要组成部分,先阅读他们可以帮助更好理解R-CNN。
首先上图,说明R-CNN的组成。该图表示的是R-CNN模型在测试(test)阶段的过程,后续还将写到训练(train)阶段的过程。
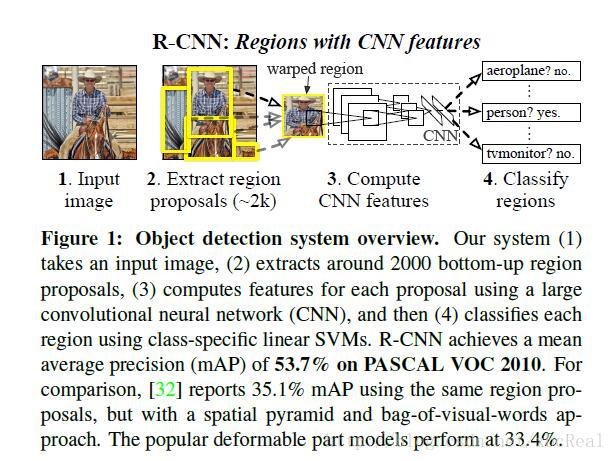
如图所示,R-CNN的输入是一张任意尺寸的图片,输出是图片中各个物体所在的位置(locations),在R-CNN系统的中间,总共分为三个模块来完成这个功能。
[1]利用R-CNN之前的准备:Selective Search for Object Recognition方法,给定一张图片,从中提取出大约2k的可能是物体的位置(理解为locations、proposals、regions都可),即上图中1到2的步骤。具体selective search是怎么做的建议参考给出的博客链接。
[2]输入大约2k的可能是物体位置的图片,通过一个深度网络,这个深度网络的具体模型是AlexNet模型,对每一个可能是物体位置的图片都进行warp,即将尺寸缩放到固定的尺寸,这个尺寸是满足深度网络输入的尺寸要求的,并从中提取出固定长度的特征向量。因此输出是大约2k个固定长度的特征向量。即完成了上图中2到3的步骤。
[3]输入大约2k个固定长度的特征向量,对于每一个特征都使用一个事先训练好的分类器进行类别的区分,加入此处总共是20类,那么分类器会将图片分类到20+1类中的其中一类,+1类表示的是背景( 不是任何物体的类别)。从而完成了上图中3到4的步骤。事实上还有一个小步骤是上图中没有显示的,那就是在得到了一系列确定是某种类别的位置后,使用非极大值抑制的方法对这些位置进行一些融合。举个例子即是,假如A图片被判断是汽车所在的位置,在SVM分类时给其打的置信分数是0.3,B图片也被判断是汽车所在的位置,在SVM分类时给其打的置信分数是0.7,但是呢,A图片和B图片有50%的内容是重叠的,并且他俩的IOU(交集和并集的比)大于了阈值threshold,那么对这两个图片就要进行非极大值抑制形成一个图片。
这样的R-CNN系统是有效的,原因有以下两点:
[1]CNN的模型参数对于所有的种类都是共享的,也就是说,假如你要进行一个20类的分类,参数的量是200k,突然又想进行一个1000类的分类,那么CNN参数的量还是200k,只是会增加SVM分类器的参数。
[2]相对于一般的方法而言,通过CNN提取到的特征的维度是相对较低的,大概在4k的数量级,而一般的方法比如UVA系统的特征数量级是360k。特征维度低的好处是对内存的要求更低了,因为对于一张图片经过R-CNN系统时,要提取出4k*2k个特征,并存储在内存中,假如这个4k变成了360k,那么对于内存的要求是可想而知的。
上面讲的是测试阶段的流程,在测试阶段,我们可以通过一个训练好的神经网络来提取特征,通过一个训练好的SVM分类器来进行分类。可以看到,测试前都需要我们先进行训练阶段的流程,不然神经网络无法提取到有效的特征,SVM也不能将类别进行准确的分类。下面讲述训练阶段的流程。
训练过程主要有以下三个阶段:
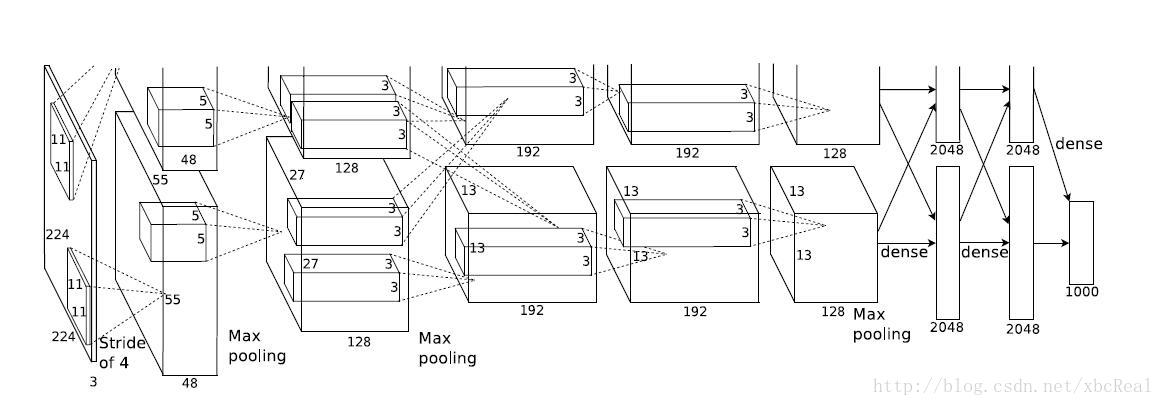
[1]有监督的预训练。在imagenet上,先对网络进行一个一个1000类分类器的训练,事实上,R-CNN中用到的AlexNet最开始本来是用来在imagenet上做图像分类的。做预训练的目的就是如果这个网络被训练到可以分别1000种类别,说明这个网络现在可以提取到一般物体的特征了,那么这个网络得到的权重一定也在一个比较适合对其它类别进行分类的情况。简言之,即是给网络一个较好的初始值,为后续针对PASCAL VOC上的图片进行分类做准备。下图为AlexNet的网络结构示意图。
[2]针对特定的图片进行调优(fine tune)。这里的特定主要是指PASCAL VOC的图片,更准确的是对于从每个图片上提取的那2k个warped voc windows。由于VOC的类别是20类,所以只要把Alex Net的1000个类别的分类层替换为21个类别的分类层(新加入了背景类别)即可。然后采用随机梯度下降法(SGD)进行训练,学习率设置为0.0001,是预训练的学习率的10分之一(因为调优嘛,所学习率设得小一点可以达到更小得损失函数的值)。每一次的SGD中,使用32个正样本和96个背景样本。
[3]在调优之后,网络便可以对PASCAL数据集上的数据提取到有效的特征,因此有了正负样本,可以通过调整后的AlexNet进行特征提取,从而可以得到特征向量和其类别的对应关系,然后以此为训练数据,训练一个线性的SVM分类器,对warped voc windows进行分类。
到这里,训练和测试的流程就全部结束了,最后作者还做了一个Bounding box regression的步骤,用来对物体的位置进行修正,因为region proposals可能没有恰好包含物体的proposal,如下图所示,如何进行这一步骤的在论文中没有阐述,我也正在查阅这方面的资料中,后续再做补充吧。想要了解更多的细节,还是建议https://github.com/rbgirshick/rcnn进行源码的学习。

最后
以上就是现代信封最近收集整理的关于R-CNN:Rich feature hierarchies for accurate object detection and semantic segmentation的全部内容,更多相关R-CNN:Rich内容请搜索靠谱客的其他文章。








发表评论 取消回复