一、基本信息
标题:Rich feature hierarchies for accurate object detection and semantic segmentation
时间:2014
领域:物体识别
引用格式:Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 580-587.
二、研究背景
CNN在ImageNet分类挑战的表现不错,能否在PASCAL VOC数据集中改进物体检测性能。
需要解决2个问题:
- 物体定位
- 训练CNN网络
三、创新点
- 使用CNN,能够更好提取特征
- 训练数据比较少时,可以进行预训练然后微调
使用滑动窗口检测器,5层卷积,相对较大的接收域。
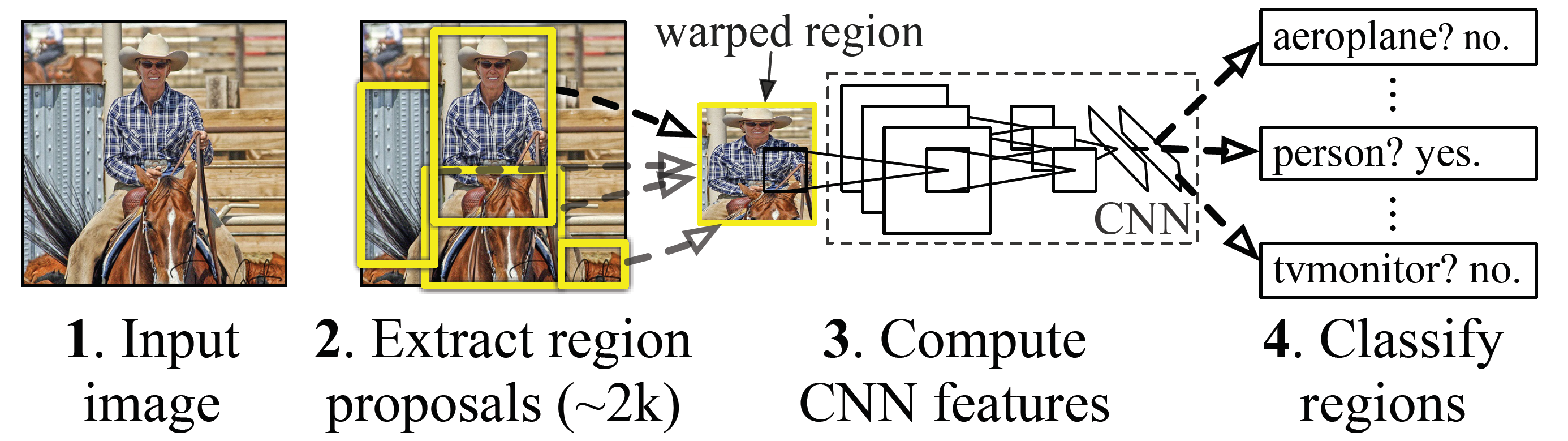
如上图,在测试时,为输入图像生成大约2000个类别无关的建议候选区域,然后使用一个CNN从每个建议中提取一个固定长度的特征向量,然后用与类别相关的SVM对每个区域进行分类。
由于PASCAL数据集中可用于物体检测的监督标签较少,因此在ILSVRC(ImageNet)进行预训练,然后在PASCAL中进行微调。
R-CNN
总体分为3个步骤:候选区域-使用CNN产生特征向量-SVM分类
候选区域使用的方法是选择搜索(后面提到再训练一个bbox检测模型可以提升3~4个百分点),特征提取使用Caff网络(因此需要resize到227* 277),SVM分类完后使用NMS去除不必要的区域

四、实验结果
在仅带1000个类别标签的ILSVRC 2012数据集上预训练(学习率0.01),在VOC数据集上转为21个分类层,重叠大于0.5为正样本,SGD学习(学习率0.001)。每次迭代32个正样本窗口和96个背景窗口(负样本),组成128的批量梯度下降.
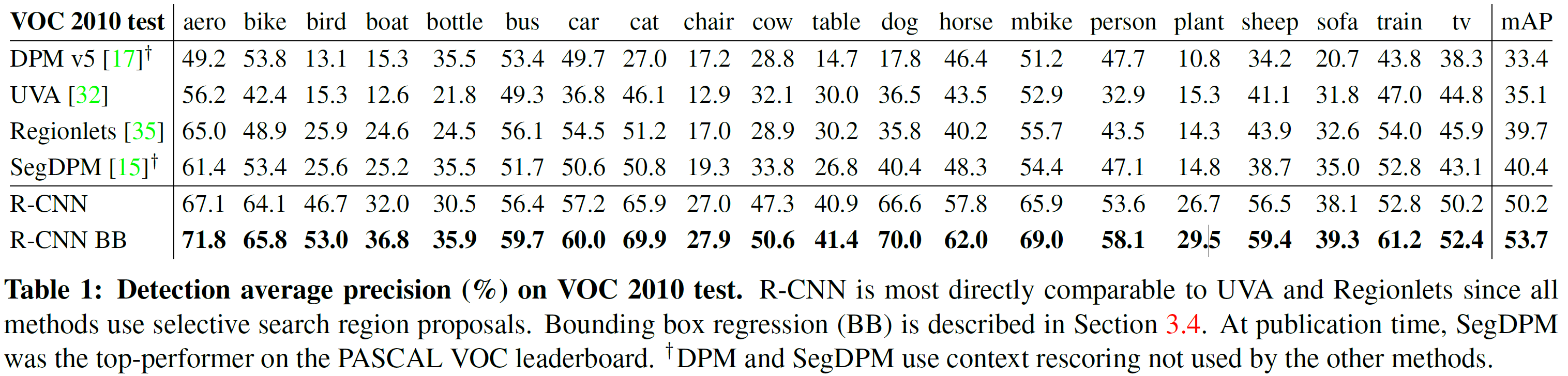
物体分类时,IoU重叠小于0.3被认为负样本,这个超参数通过网格搜索得到。在提取特征和使用训练标签后,对每类优化一个SVM。
实验发现,CNN卷积带来的特征提取是通用的,可以在不同数据集中使用,而全连接层用来学习特定于领域。
五、结论与思考
作者结论
总结
思考
- 那么为什么作者闲着没事干要先用CNN做特征提取(提取fc7层数据),然后再把提取的特征用于训练svm分类器?
这个是因为svm训练和cnn训练过程的正负样本定义方式各有不同,导致最后采用CNN softmax输出比采用svm精度还低。
事情是这样的:
1).cnn在训练的时候,对训练数据做了比较宽松的标注,比如一个bounding box可能只包含物体的一部分,那么我也把它标注为正样本,用于训练cnn;
2).采用这个方法的主要原因在于因为CNN容易过拟合,所以需要大量的训练数据,所以在CNN训练阶段我们是对Bounding box的位置限制条件限制的比较松(IOU只要大于0.5都被标注为正样本了);
3).然而svm训练的时候,因为svm适用于少样本训练,所以对于训练样本数据的IOU要求比较严格,我们只有当bounding box把整个物体都包含进去了,我们才把它标注为物体类别,然后训练svm,具体请看下文。
————————————————
版权声明:本文为CSDN博主「Alanyannick」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u011534057/article/details/51218250
作者认为原因在于softmax中的背景样本是共享的,而SVM的背景样本是独立的,更加hard,所以能够带来更好的分类效果。
原文链接: https://blog.csdn.net/csyhhb/article/details/50425326
- 为什么训练CNN是IoU为0.5,而训练SVM时为0.3?
上面其实回答了,CNN比较宽松所以设置了0.5,而在训练SVM的时候,负样本是IoU<0.3,正样本是ground-truth,所以不改变正样本数目,负样本更少(例如,原来0.4可以认为负样本,而在这不认为是负样本)
参考
RCNN学习笔记1
RCNN学习笔记2
最后
以上就是精明画笔最近收集整理的关于论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation(R-CNN)一、基本信息二、研究背景三、创新点四、实验结果五、结论与思考参考的全部内容,更多相关论文笔记:Rich内容请搜索靠谱客的其他文章。








发表评论 取消回复