Direction-aware Spatial Context Features for Shadow Detection and Removal
零、论文信息
- 2018 CVPR
- https://arxiv.org/abs/1805.04635
- http://tongtianta.site/paper/37507
- https://github.com/xw-hu/DSC
一、论文贡献
- 首先,我们在空间RNN中设计一种新颖的注意机制,并构建DSC模块,以方向感知的方式学习空间背景。
- 其次,我们开发了一个新的阴影检测网络,采用多个DSC模块来学习不同层中的方向感知空间背景,并设计加权交叉熵损失以平衡阴影和非阴影区域的检测精度。
- 第三,我们通过制定欧几里德损失并使用颜色补偿无阴影图像训练网络进一步采用网络去除阴影,这些图像是通过颜色传递函数产生的。
- 最后,我们在阴影检测和阴影去除的几个基准数据集上评估我们的方法,并将其与最先进的方法进行比较。实验结果表明,我们的网络对于这两项任务都有利于以前的方法;有关定量和定性比较结果,请参见第4节和第5节。
二、论文方法
-
网络结构
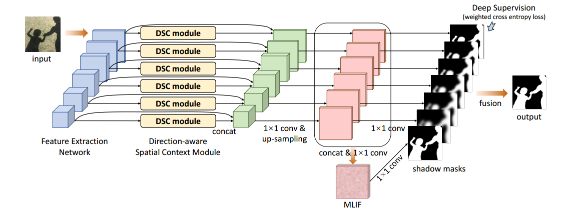
整个阴影检测网络的示意图:(i)我们从输入图像中提取CNN层上不同尺度的特征; (ii)我们嵌入了DSC模块(见上图),为每一层生成方向感知空间背景(DSC)特征; (iii)我们将DSC特征与每层的卷积特征相结合,并将连接的特征映射上采样到输入图像的大小; (iv)我们将上采样特征映射组合成多级集成特征(MLIF),使用[30]中的深度监督机制基于每个层的特征预测阴影掩模,并融合生成的阴影掩模; (v)在测试过程中,我们计算MLIF层和融合层上的平均阴影掩模,并使用条件随机场[31]进一步重新确定检测结果。
-
DSC模块
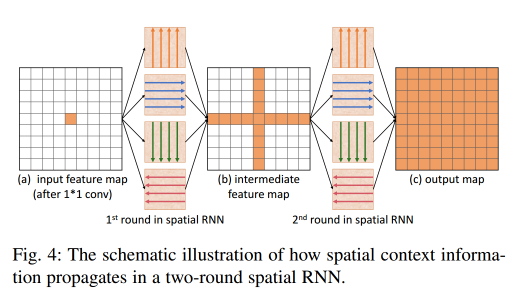
将来自CNN的2D特征图作为输入,我们首先执行卷积来模拟RNN中的输入到隐藏数据转换。然后,我们应用四个独立的数据转换来沿着每个主方向(左,右,上和下)聚合局部空间上下文,并将结果融合到中间特征图中;见图4(b)。最后,我们重复整个过程,以进一步传播每个主要方向的聚合空间背景,并生成整体空间背景;见图4(c)。
与图4(c)相比,图4(a)中的每个像素仅知道其局部空间上下文,而图4(b)中的每个像素在第一轮数据转换之后进一步知道四个主要方向上的空间上下文。因此,在两轮数据转换之后,每个像素可以获得相关的方向感知全局空间上下文,用于学习特征以增强阴影的检测和去除。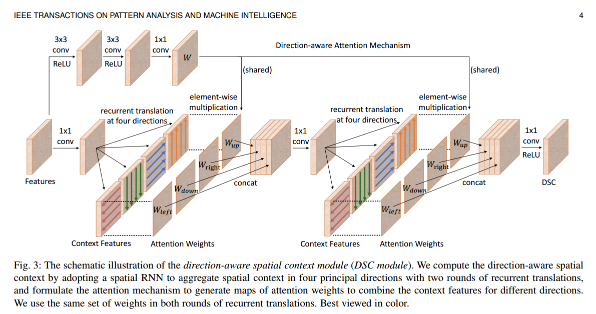
为了在空间RNN中执行数据转换,我们遵循IRNN模型[50],因为它快速,易于训练,并且具有良好的远程数据依赖性[49]。将hi,j表示为像素(i,j)中的特征,我们通过重复以下操作n次向右执行一轮数据转换(类似地,对于其他三个方向中的每一个执行同样的操作)。
h i , j = max ( α r i g h t h i , j − 1 + h i , j , 0 ) (1) h_{i, j} = max(alpha_{right} h_{i, j-1} + h_{i,j}, 0) tag{1} hi,j=max(αrighthi,j−1+hi,j,0)(1)
其中n是特征映射的宽度,而αright是右方向的循环转换层中的权重参数。请注意,αright以及其他方向的权重被初始化为单位矩阵,并通过训练过程自动学习。
为了以方向感知的方式有效地学习空间上下文,我们进一步在空间RNN中形成方向感知注意机制以学习注意权重并生成方向感知空间上下文(DSC)特征。该设计形成了我们在图3中呈现的DSC模块。
方向感知注意机制。该机制的目的是使空间RNN能够通过学习选择性地利用在不同方向上聚合的空间上下文。请参见图3中所示的DSC模块中的左上方块。首先,我们使用两个连续的卷积层(使用3*3内核),然后是ReLU [51]非线性操作,然后使用第三个卷积层(使用1*1内核)生成四个通道的W.然后我们将W分成四个注意权重图,表示为Wleft,Wdown,Wright和Wup,每个都是一个通道。在数学上,如果我们将上面的运算符表示为fatt并且输特征映射为X,我们有:W = f a t t ( X ; θ ) , (2) W = f_{att}(X; theta), tag{2} W=fatt(X;θ),(2)
其中θ表示fatt(也称为关注估计器网络)要学习的卷积运算中的参数。再次参见图3中所示的DSC模块。四个权重图以元素方式在相应方向上与空间上下文特征(来自循环数据转换)相乘。因此,在我们训练网络之后,网络应该学习θ以产生合适的注意权重以选择性地利用空间RNN中的空间上下文。
接下来,我们提供有关DSC模块的详细信息。如图3所示,在我们将空间上下文特征与注意权重相乘后,我们将结果连接起来并使用1*1卷积来模拟RNN中的隐藏数据转换,并将特征维度减少四分之一。然后,我们执行第二轮循环转换并使用相同的一组注意力来选择空间背景,我们根据经验发现,共享注意权重而不是使用两组不同的权重会带来更高的性能;有关实验,请参阅第5节。还要注意,这些注意力是基于从输入图像中提取的深度特征自动学习的,因此它们可能因图像而异。最后,我们使用1*1卷积,然后在级联特征映射上使用ReLU [51]非线性运算来模拟隐藏到输出的转换并生成输出DSC功能。
三、收获
-
损失函数
在自然图像中,阴影通常比非阴影区域在图像空间中占据的区域较小。 因此,如果损失函数仅针对整体精度,它将倾向于匹配像素更多的非阴影区域。 因此,我们在训练过程中使用加权的交叉熵损失来优化阴影检测网络。
假设y为像素的地面真实值(如果在阴影中,则y = 1,否则为y = 0),而p为像素的预测标签(其中p ∈ [0,1])。 第i个CNN层的加权交叉熵损失 L i L_i Li是按类别分布 L i d L_i^d Lid加权的交叉熵损失和按每类精度 L i a L_i^a Lia加权的交叉熵损失的和: L i = L i d + L i a L_i = L_i^d + L_i^a Li=Lid+Lia 。L i d = − ( N n N p + N n ) y log ( p ) − ( N p N p + N n ) ( 1 − y ) log ( 1 − p ) (3) L_i^d = -(frac{N_n}{N_p+N_n})ylog(p) - (frac{N_p}{N_p+N_n})(1 - y)log(1 - p) tag{3} Lid=−(Np+NnNn)ylog(p)−(Np+NnNp)(1−y)log(1−p)(3)
L i a = − ( 1 − T P N p ) y log ( p ) − ( 1 − T N N n ) ( 1 − y ) log ( 1 − p ) (4) L_i^a = -(1 - frac{TP}{N_p})ylog(p) - (1 - frac{TN}{N_n})(1-y)log(1 - p) tag{4} Lia=−(1−NpTP)ylog(p)−(1−NnTN)(1−y)log(1−p)(4)
其中TP和TN是true positives和 true negatives像素的个数,Np和Nn分别是每个图像的阴影和非阴影像素数,因此Np + Nn是第i层像素的总数。实际上, L i d L_i^d Lid有助于平衡阴影和非阴影的检测。如果阴影的面积小于非阴影区域的面积,则对错误分类的阴影像素的惩罚要大于对错误分类的非阴影像素的惩罚。另一方面,受[53]的启发,[53]倾向于选择分类错误的示例来训练深度网络,因此我们扩大了难以分类的类别(阴影或非阴影)的权重。为此,我们使用 L i a L^a_i Lia,当正确分类的阴影(或非阴影)像素的数量较小时,阴影(或非阴影)类的权重较大,反之亦然。 -
训练集
文中用的训练集是SBU,然后使用SBU-test和UCF来计算BER和accuracy。
-
使用了迁移学习
文中的第一层,也就是特征提取层,使用了在ImageNet上预训练VGG-net的第一层。
最后
以上就是温婉镜子最近收集整理的关于Direction-aware Spatial Context Features for Shadow Detection and Removal的全部内容,更多相关Direction-aware内容请搜索靠谱客的其他文章。



![[论文阅读] (14)英文论文实验评估(Evaluation)如何撰写及精句摘抄(上)——以入侵检测系统(IDS)为例一.实验评估如何撰写二.入侵检测系统论文实验评估句子三.实验图表四.总结](https://www.shuijiaxian.com/files_image/reation/bcimg13.png)




发表评论 取消回复