Multi-Level Fusion based 3D Object Detection from Monocular Images
摘要
本文提出了一种基于端到端多层次融合的单目图像三维目标检测框架。整个网络由两部分组成:一部分用于生成二维区域建议,另一部分用于同时预测对象的二维位置、方向、尺寸和三维位置。借助于一个独立的视差估计和三维点云计算模块,我们引入了多级融合方案。首先,对视差信息进行前视图特征表示编码,并与RGB图像融合以增强输入。其次,将原始输入特征与点云特征相结合,提高了目标检测的效率。对于三维定位,我们引入一个额外的流来直接预测点云的位置信息,并将其加入到前面的位置预测中。该算法以端到端的方式直接输出二维和三维目标检测结果,只需输入一幅RGB图像。在具有挑战性的KITTI基准上的实验结果表明,我们的算法明显优于单目最新方法。
方法
在这项工作中,为了得到三维物体的姿态,采用离散连续公式进行方位估计。对于三维对象尺寸,通过分析每个类的训练标签,可以访问由长度、宽度和高度组成的典型尺寸。实际尺寸和典型尺寸之间的偏移量由网络估算。
物体中心的三维坐标(X,Y,Z)的估计要复杂得多,因为只有图像的外观不能决定物体的绝对物理位置。为了解决这个问题,需要将全局上下文信息视为每个区域候选的先验信息。对于输入的单眼图像,通过一个完全卷积网络(FCN)估计每个像素的视差信息,利用摄像机标定文件可以得到近似的深度和点云。然后对估计信息进行多步叠加,实现三维定位。
引入RoI平均池层,通过平均池将方案中的点云转化为固定长度的特征向量。利用点云特征和原始卷积特征估计目标中心的三维位置。此外,还将估计深度编码为前视特征图,并与RGB图像进行融合以提高性能。因此,所有的2D和3D描述符都可以同时预测。
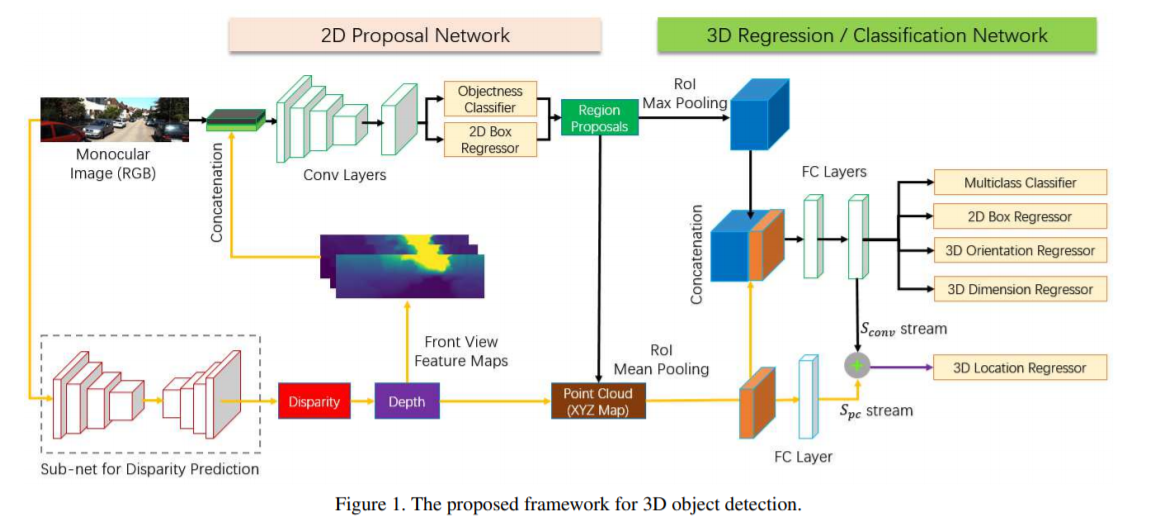
2D边界判断
本文利用快速R-CNN中引入的区域提议网络(RPN)来提取roi以进行进一步的检测。在RPN中,通过卷积特征映射上的滑动小网络和锚定机制,生成一组带有目标得分的矩形目标建议
2D/3D Parameters Estimation
基于二维区域建议,估计了用于对象描述的二维/三维参数。对于二维部分,它由多类分类和二维盒回归组成,我们的实现就像更快的R-CNN一样。对于三维组成,它由方向估计、尺寸估计和三维定位确定。
方位估计
对于方向分支,不可能仅从区域建议的内容来估计相机参考帧中的全局方向。因此,本地定位与最先进的多层构建回归。它将一个角度离散化,并将其分成n个重叠的箱子。利用输入特征,估计了每个箱子的置信概率和箱子中心的剩余部分。这两部分分别被视为角度置信度和角度局部化。
角度置信度的损失函数等于交叉熵(CE),以sigmoid函数为概率,因为相邻的盒子之间存在重叠,一个角度可能属于多个盒子。对于残差角的回归损失,我们采用了[12]中定义的光滑L1。平滑的L1损失是一个稳健的L1损失,比L2损失对异常值不太敏感,其定义如下:

维数定义
对于维数估计,我们不直接回归绝对维数。相反,我们首先在训练数据集上计算每个类的平均长度、高度和宽度,以获得典型维度。然后使用相同的共享特征估计到典型大小的偏移,就像二维边界框的回归部分一样。该分支中的损失函数定义如下:

3D位置定位
估计三维物体的三维位置要复杂得多。在只有区域建议中的特征用于角度和维度回归。然而,由于RoI最大值池的存在,用同样的方法估计3D位置是困难的。从RoI-max池生成的特性有几个缺点。首先,将roi内部不同尺度的特征转换成固定大小的特征张量。因此,它在一定程度上消除了一个基本的摄影限制,即较大尺寸的RoI应该靠近相机。
此外,每个感兴趣区域的图像坐标仅用于提取特征地图上的相应区域。这意味着RoI最大池化后,RoI的不同空间位置可能有相似的输出,而实际的3D位置可能有很大的不同。在二维包围盒回归中,绝对坐标是通过估计方案的偏移量来实现的。但是,对于三维定位,二维方案不包含坐标的三维信息。
另一个事实是,如果我们以前看过场景,我们人类可以分辨出单眼图像中任何物体的大致三维位置。通过我们过去的视觉体验,我们可以对世界有一个丰富的理解[38]。这种理解可以作为整个图像的先验知识,可以用来定位任何物体,甚至其中的任何像素。为了帮助在我们的框架中定位三维对象,可以对对象的近似布局或像素的三维位置进行建模。
深度估计

3d位置确定
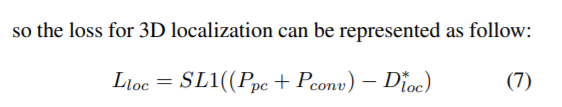
Loss function

结果
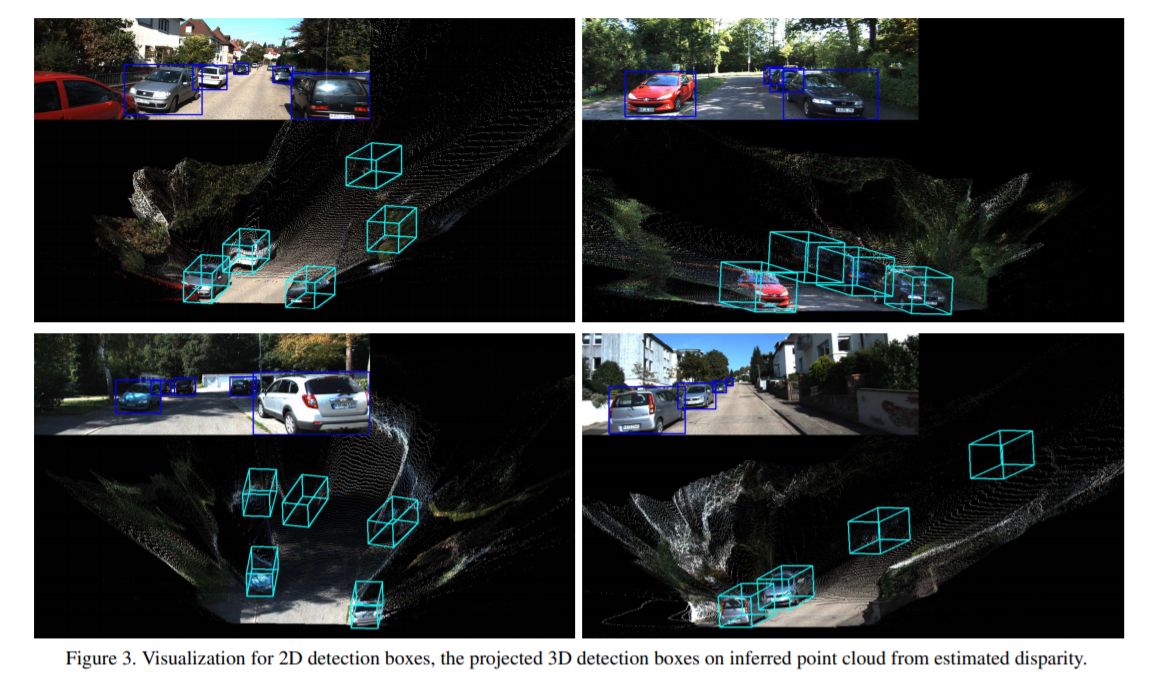
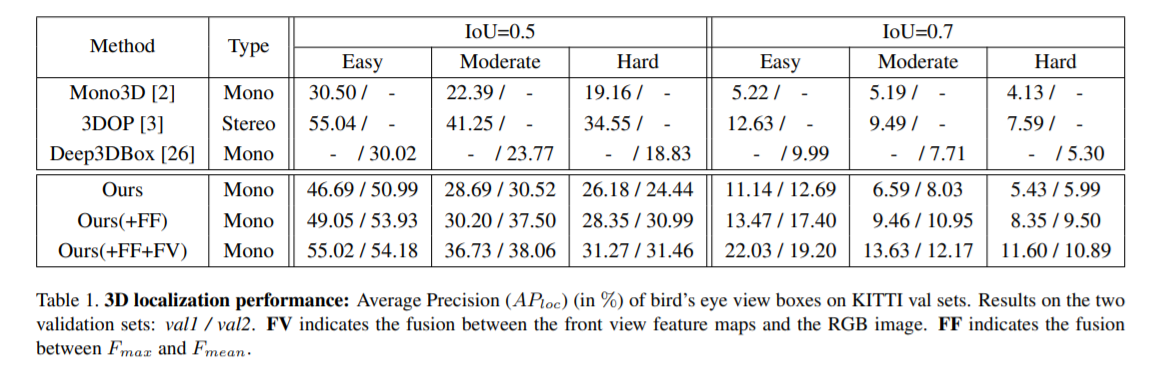
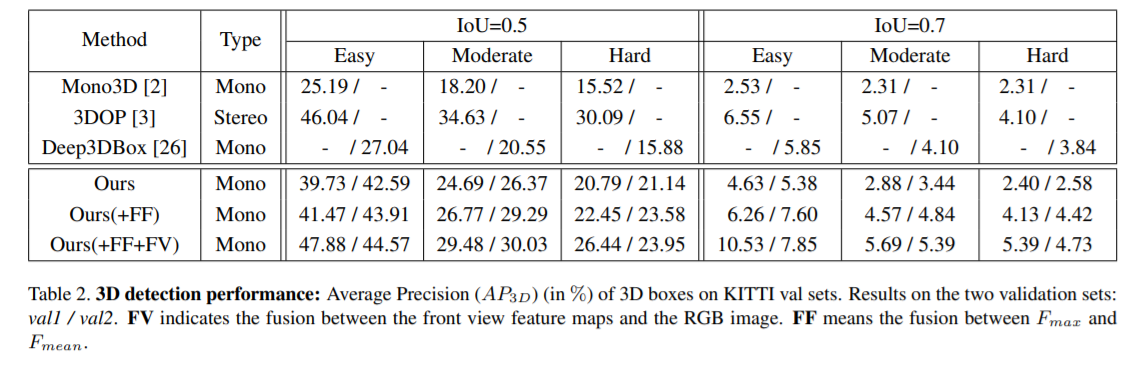
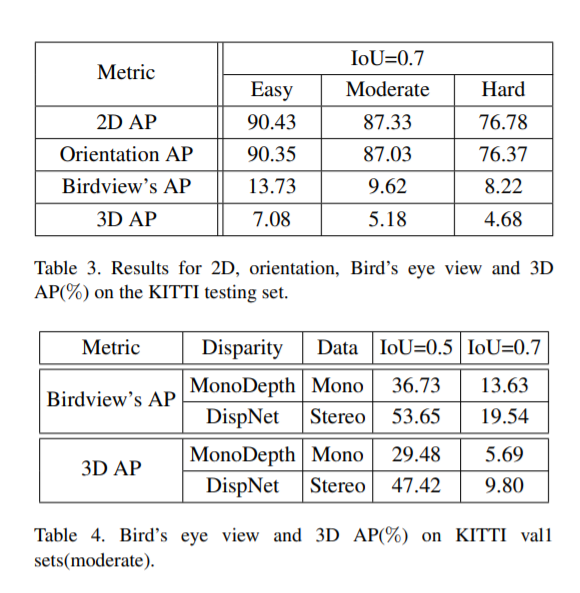
最后
以上就是可靠大碗最近收集整理的关于每天一篇论文 357/365 Multi-Level Fusion based 3D Object Detection from Monocular Images的全部内容,更多相关每天一篇论文内容请搜索靠谱客的其他文章。






![[论文阅读] (14)英文论文实验评估(Evaluation)如何撰写及精句摘抄(上)——以入侵检测系统(IDS)为例一.实验评估如何撰写二.入侵检测系统论文实验评估句子三.实验图表四.总结](https://www.shuijiaxian.com/files_image/reation/bcimg13.png)

发表评论 取消回复