摘要
我们解决了对象检测中的域适应任务,其中有注释的源域和没有注释的感兴趣的目标域之间存在域间隙(注:在一个数据集上训练模型,再另外一个数据集上进行预测性能下降很大,在一个数据集上训练好的模型无法应用在另一个数据集上。)。作为一种有效的半监督学习方法,教师-学生框架(学生模型由教师模型的伪标签监督)(注:伪标签技术就是利用在已标注数据所训练的模型在未标注的数据上进行预测,根据预测结果对样本进行筛选,再次输入模型中进行训练的一个过程。)在跨域对象检测中也产生了很大的准确性提升。然而,它受到域偏移的影响,并产生许多低质量的伪标签(例如,误报(注:TP、True Positive 真阳性:预测为正,实际也为正;FP、False Positive 假阳性:预测为正,实际为负;FN、False Negative 假阴性:预测与负、实际为正;TN、True Negative 真阴性:预测为负、实际也为负)),这导致了次优的性能。为了缓解这个问题,我们提出了一个名为 Adaptive Teacher (AT) 的教师学生框架,它利用领域对抗学习和弱强数据增强来解决领域差距。具体来说,我们在学生模型中采用特征级对抗训练,允许从源域和目标域派生的特征共享相似的分布。这个过程确保学生模型产生领域不变的特征。此外,我们在教师模型(从目标域获取数据)和学生模型(从两个域获取数据)之间应用弱强增强和相互学习。这使教师模型能够从学生模型中学习知识,而不会偏向于源域。我们表明,AT 在很大程度上展示了优于现有方法甚至 Oracle(完全监督)模型的优势。
1.介绍
开发可以将从一个标记数据集(即源域)学到的知识转移到另一个未标记的数据集(即目标域)对于对象检测变得越来越重要。研究人员提出了各种方法,例如域分类器和对抗性学习 [10],以解决对象检测中的跨域自适应任务 [2, 3, 14, 32, 39, 42, 44]。尽管这些方法提高了准确性,但仅在复杂的识别任务(例如对象检测)上使用对抗性学习仍然是有限的。因此,目标域上的 Oracle 模型(完全监督)通常仍然存在很大的性能差距。
为了探索在未标记的目标域上进行自我训练以提高检测性能的潜力,研究人员已经利用并将师生自我训练方法从半监督学习扩展到了域适应。
这些方法能够通过通常涉及教师模型来生成伪标签以更新学生模型来学习而无需注释。这些方法在域适应场景中带来了显着的准确性提升。例如,MTOR [1] 使用平均教师 (MT) [40] 作为其管道,以使用区域级、图间和图内一致性来识别关系。
提出了无偏平均教师(UMT)[8],以使用 CycleGAN [43] 来增强师生框架,并实现了进一步的性能提升。
尽管准确率有所提高,但师生框架在领域适应的设置上仍然面临重大挑战:与半监督学习不同,教师模型生成的伪标签通常包含大量错误和误报,如图所示图 1. 这是因为域适应的场景通常涉及标记数据(源域)和未标记数据(目标域)之间的大域间隙。教师模型经过训练,偏向于并且只能在源域上精确捕获特征,因此无法在目标域中提供高质量的伪标签。因此,直接应用师生框架只会导致次优的适应性能。
为了解决这个问题,我们提出了一个名为 Adaptive Teacher (A T) 的自我训练框架,以利用对抗性学习和相互学习来减轻域转移并提高目标域的伪标记质量。我们的模型包括两个独立的模块:特定目标教师模型和跨域学生模型。我们还应用弱增强(仅在学生模型中进行强增强)并将来自目标域的图像输入到教师模型中,我们将其称为“弱-强增强”,遵循无偏教师(UT)[22]。这允许教师模型生成可靠的伪标签,而不会受到大量增强的影响。此外,为了减轻学生模型中对源域的域偏差,我们通过引入具有梯度反向层的鉴别器来应用对抗学习,以对齐学生模型中两个域的分布。通过所有技术,我们观察到伪标签质量显着提高,如图 1 所示,其中误报率被抑制了高达 35%。这进一步导致在所有域适应实验中获得显着的准确性,并优于所有现有方法。我们将本文的贡献总结如下:
• 我们证明了教师-学生框架在域适应场景中的局限性:教师模型偏向源域,只能在目标域上产生低质量的伪标签。
• 我们提出了一个新的框架,利用对抗性学习增强相互学习和弱强增强来解决跨域对象检测中的域转移问题。
• 我们的方法能够处理域转移并大大优于所有现有的 SOTA。例如,我们在 Foggy Cityscape 上实现了 50.9% 的 mAP,分别比 SOTA 和 Oracle(全监督)高出 9.2% 和 8.2%。
2.相关工作
目标检测。对象检测是在给定输入图像的情况下定位对象及其位置的任务。最近,深度模型已被证明在使用基于锚的方法进行目标检测方面是有效的,例如,Faster R-CNN [30] 引入了区域提议网络 (RPN) 以促进感兴趣区域 (ROI) 的提议生成。之后,提出了几个基于锚的工作 [5,6,15,20,26,37] 以提高性能和功效。另一方面,也提出了无锚方法作为单阶段检测器,而无需生成区域建议的步骤。 YOLO [27] 为多个类联合生成边界框和置信度分数作为回归任务。还提出了它的几个变体 [28, 29]。SSD [21] 也建立在 YOLO 之上,但利用了从不同比例的图像生成的特征图。对于我们的工作,我们使用 Faster R-CNN 作为检测的主干,因为它具有灵活性。
域适应。给定来自目标域的未标记数据,无监督域适应 (UDA) 或域适应 (DA) 旨在从附加的标记源域中学习模型,以在目标域上获得令人满意的性能。最近,它已经证明了它使用深度神经网络的有效性。一方面,一些工作开发了基于差异的方法,通过最小化域差异来学习表示,这也称为最大平均差异(MMD)[23-25]。域适应的另一条线是映射域分布并将其视为具有域分类器的对抗性(最小-最大)优化 [10,11,34,41]。一些生成模型,如 CycleGAN [43] 也可以看作是图像级域适应。然而,与这些一般的视觉任务相比,对象检测的问题更加复杂,因为它必须预测每个对象的边界框和类别标签。与其他识别任务相比,我们的目标是处理跨域对象检测这样具有挑战性的任务
跨域对象检测。最近,越来越多的工作更加关注对象检测任务中的域适应,并提出了各种方法。一些利用具有梯度反向层的对抗性学习用于在 [2, 3, 14, 32, 39, 42, 44] 中跨不同域映射特征。注释级别的适应[17,18,31]或课程学习[38]也被提出用于领域适应的任务。最近,另一个方向是利用平均教师(MT)[40],它最初是为这个任务的半监督学习而提出的。 MTOR [1] 是在 MT 之上提出的,并通过执行区域级、图间和图内一致性来训练其教师网络。类似地,已提出无偏平均教师(UMT)[8] 通过使用 CycleGAN [43] 增加训练样本来减少域偏移。然而,上述方法在平均教师 (MT) 中可能会遇到相同且固有的问题,即在目标域上生成低质量的伪标签。
3.适应性教师
3.1.问题表述和概述
在我们展示我们提出的方法如何能够减轻伪标签在对象检测的域适应中的错误之前,我们首先回顾一下问题的表述。我们在源域中给定 Ns 个标记图像 Ds = {(Xs, Bs, Cs)},在目标域中给定 Nt 个未标记图像 Dt = {Xt},其中 Bs = {bis}Nsi=1 表示边界框注释,Cs = {cis}Nsi=1 表示源图像 Xs = {xis}Nsi=1 的相应类别标签。目标图像 Xt = {xj t}Ntj=1 没有注释。跨域目标检测的最终目标是利用 Ds 和 Dt 设计域不变检测器。

我们的框架概述如图 2 所示。
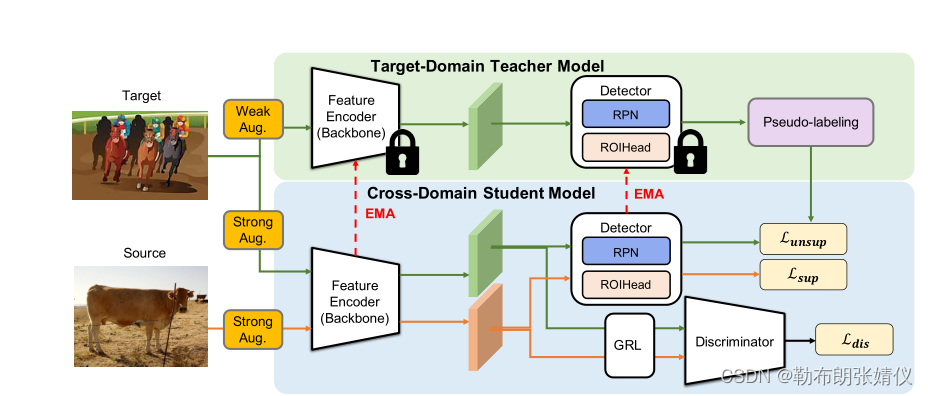
图 2. 我们提出的自适应教师 (AT) 概述。我们的模型由两个模块组成:1)针对特定目标的教师模型,用于从目标域获取弱增强图像;2)跨域学生模型,用于从两个域获取强增强图像。我们使用两个学习流来训练我们的模型:师生相互学习和对抗性学习。教师模型生成伪标签来训练学生,而学生使用指数移动平均 (EMA) 更新教师模型。具有梯度反向层的鉴别器用于对齐学生模型中两个域的分布
我们的 A T 框架由两个模块组成:目标特定的教师模型和跨领域的学生模型。教师模型仅从目标域 (Dt) 获取弱增强图像,而学生模型从两个域 (Ds 和 Dt) 获取强增强图像。我们使用两个训练流来训练我们的模型,它们是师生相互学习和对抗性学习策略。首先,我们使用可用的源标记数据训练目标检测器,并初始化特征编码器和检测器。在相互学习阶段,我们将初始化的目标检测器复制成两个相同的检测器,即教师模型和学生模型。教师生成伪标签来训练学生,而学生通过指数移动平均 (EMA) 将其学到的知识更新给教师。迭代地,用于训练学生的伪标签得到改进。此外,我们使用鉴别器和梯度反向层 (GRL) [10] 进行自适应学习(第 3.3 节),以对齐学生模型中两个域的分布。这允许学生模型减少域转移并有利于教师模型生成更准确的伪标签。
3.2.师生相互学习
遵循最初为半监督对象检测提出的师生框架,我们的模型也由两个架构相同的模型组成:学生模型和教师模型。 Student 模型通过标准梯度更新来学习,Teacher 模型使用来自学生模型的权重的指数移动平均 (EMA) 进行更新。为了为目标域图像生成精确和准确的伪标签,我们将具有弱增强的图像作为输入提供给教师,以提供可靠的伪标签,同时具有强增强的图像作为学生的输入。具体来说,目标样本通过随机水平翻转和裁剪作为教师模型中的弱增强和随机颜色抖动、灰度、高斯模糊和切割补丁作为扰动的强增强。
模型初始化:初始化对于自训练框架很重要,因为我们依靠教师为目标域生成可靠的伪标签,而无需注释来优化学生模型。为了实现这一点,我们首先使用可用的监督源数据 Ds = {(Xs, Bs, Cs)} 来优化我们的模型和监督损失 Lsup。因此,使用标记的源数据训练和初始化学生模型的监督损失可以定义为:
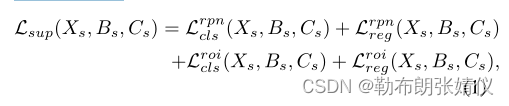
其中 RPN 损失 Lrpn 是用于学习区域建议网络(RPN)的损失,它旨在生成候选建议,而感兴趣区域(ROI)损失 Lroi 是用于 ROI 的预测分支。 RPN 和 ROI 都执行边界框回归 (reg) 和分类 (cls)。我们对 Lrpn cls 和 Lroicls 使用二元交叉熵损失,对 Lrpnreg 和 Lroireg 使用 l1 损失。

使用目标伪标签优化学生:由于标签在目标域中不可用,我们采用伪标签方法在来自目标域的图像上生成虚拟标签来训练学生。为了过滤掉嘈杂的伪标签,我们在教师模型的预测边界框上设置了一个置信阈值 δ,以去除误报。此外,我们通过非最大抑制(NMS)对每个类排除重复框预测。因此,在从 Teacher 模型中获得目标域图像上的伪标签后,我们可以将 Student 的损失更新为:
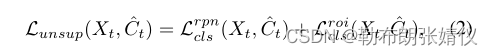
其中 ^Ct 表示教师模型在目标域上生成的伪标签。在这里,无监督损失不应用于边界框回归任务,因为预测边界框在未标记数据上的置信度分数只能表示每个对象的类别的置信度,而不是生成的边界框的位置。
从学生临时更新教师:为了从 MT [40] 之后的目标图像中获得强伪标签,我们应用指数移动平均 (EMA) 通过临时复制学生模型的权重来更新教师模型。更新公式可以定义为:
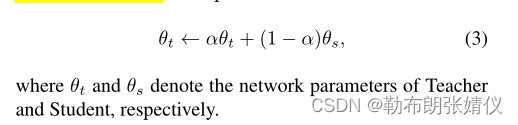
3.3.对抗性学习以弥合领域偏见
由于注释仅在源数据上可用,因此在相互学习过程中,教师和学生都可以很容易地偏向源域。具体而言,Teacher 模型在目标图像上生成的伪标签基本上是使用使用源域标签训练的模型的知识导出的。因此,我们需要弥合源域和目标域之间的域偏差,否则教师模型会在目标图像上生成噪声标签并使学习过程崩溃。因此,我们将对抗性学习引入到框架中,以对齐两个领域的分布。这导致伪标签生成中的假阳性率大幅降低(MT+对抗性损失为 20%)。
由于学生模型从两个域中获取图像,因此对抗性损失适用于学生模型以对齐两个分布。为了实现对抗性学习,在 Student 模型上的特征编码器 E(如图 2 所示)之后放置了域鉴别器 D。判别器旨在区分派生特征 E(X) 来自(源或目标)的位置。然后我们可以将每个输入样本属于目标域的概率定义为 D(E(X)),将其属于源域的概率定义为 1-D(E(X))。在给定每个输入图像的域标签 d 的情况下,我们可以使用二元交叉熵损失来更新域鉴别器 D。具体来说,来自源域的图像被标记为 d = 0,来自目标域的图像被标记为 d = 1。鉴别器损失 Ldis 可以表示为:
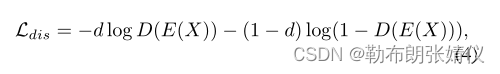
另一方面,鼓励特征编码器 E 产生混淆鉴别器 D 的特征,而鉴别器 D 旨在区分派生特征来自哪个域。因此,这种对抗性优化目标函数可以定义如下:

幸运的是,为了简单的 min-max 优化,我们可以附加一个额外的梯度反转层在特征编码器和鉴别器之间产生反向梯度。在梯度计算过程中,GRL 否定传回的梯度,并且特征编码器 E 的梯度以相反的方向计算。这有助于最大化学习 E 的判别器损失,而我们只需要最小化目标 Ldis。通过上述判别器损失,我们的学生模型解决了视觉特征中的域偏差,并帮助教师在多次 EMA 更新后生成精确的伪标签。
我们想指出,自适应教师的学生模型中的对抗性学习设计是合理的,原因有两个。首先,由于我们只将来自目标域的图像输入到教师模型中以避免教师模型的域偏差,因此在跨两个域获取图像的学生模型中,对齐两个域的过程可能更可取。从像 [1, 8] 这样的源域输入图像可能会给教师和学生模型带来更多的源域偏差。其次,对抗学习是一个最小-最大学习问题,需要损失函数来更新模型。由于学生模型是通过客观损失更新的,因此将对抗性损失应用于学生模型是 Mean Teacher 标准学习中一种简单而合适的方式。
3.4.完全客观和推理
训练我们提出的 AUT 的总损失 L 总结如下:
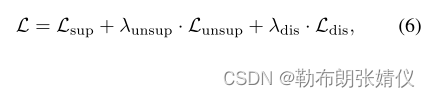
其中 λunsup 和 λdis 是用于控制相应损失权重的超参数。我们注意到 Lsup 和 Lunsup 是为了学习 Student 模型中的特征编码器和检测器而开发的,而 Ldis 是用来更新特征编码器和鉴别器的。教师模型仅通过第 3.2 节中讨论的 EMA 更新。
4. 实验
4.1. Datasets
我们在五个公共数据集上进行了实验,包括 Cityscapes [4])、Foggy Cityscapes [33]、PASCAL VOC [9]、Clipart1k [16] 和Watercolor2k [16]。
城市景观。 Cityscapes [4] 是通过从具有不同场景的 50 个城市在正常天气条件下从户外街景中捕获图像来收集的。它包含 2,975 张用于训练的图像和 500 张用于使用密集像素级标签进行验证的图像。边界框的注释是从实例分割标签转换而来的。
有雾的城市景观。 Foggy Cityscapes [33] 是从 Cityscapes 中的图像合成的。因此,它与 Cityscapes 具有相同的训练/测试拆分。它根据 Cityscapes 中提供的深度信息模拟雾天的状况,并生成三个级别的雾天。
帕斯卡 VOC。 PASCAL VOC [9] 包含来自现实世界的 20 类常见对象,带有边界框和类注释。在 [32, 35] 之后,该数据集由 PASCAL VOC 2007 和 2012 组合而成,共有 16,551 张图像。
剪贴画1k。 Clipart1k [16] 包含剪贴画图像,并与 PASCAL VOC 共享相同的 20 个类。是的,它表现出从 PASCAL VOC 的大域偏移。我们遵循 [32,35] 中的做法,并将其分成训练集和测试集,每组包含 500 张图像。
水彩2k。水彩2k [16] 包含水彩风格的图像,它由来自 6 个类的图像组成,并与 PASCAL VOC 数据集中的相同类共享。在 [32,35] 之后,数据集被分成一半的训练集和测试集,每个包含 1000 张图像
4.2.实施细节
在 [3] 和 [32] 之后,我们使用 Faster RCNN [30] 作为自适应教师中的基础检测模型,并使用 Detectron2 实现它。根据设置,在 ImageNet [7] 上预训练的网络 ResNet101 [13] 或 VGG16 [36] 都用作主干。在使用 ROI-alignment [12] 实施 Faster RCNN 之后,我们通过将图像较短边的大小调整为 600 来缩放所有图像,同时保持图像比例。对于超参数,为简单起见,我们为所有实验设置了 λunsup = 1.0 和 λdis = 0.1。我们将置信度阈值设置为 δ = 0.8。对于训练的初始化阶段,第 2 节中描述的框架。 3.2,我们使用源标签训练 A T 10k 次迭代。然后我们在相互学习开始时将权重复制到教师模型和学生模型,并训练 A T 进行 50k 次迭代。我们在整个训练阶段将学习率设置为 0.04,没有应用任何学习率衰减。我们使用随机梯度下降 (SGD) 优化网络。使用的数据增强方法包括用于弱增强的随机水平翻转,以及用于强增强的随机颜色抖动、灰度、高斯模糊和切出补丁。教师模型的指数移动平均 (EMA) 的权重平滑系数参数设置为 0.9996。每个实验都在 8 个 Nvidia GPU V100 上进行,批量大小为 16,并在 PyTorch 中实现。
4.3.实验设置和评估
我们根据现有工作 [3, 32] 报告所有实验设置的每个类别的平均精度 (AP) 以及所有类别的目标检测平均 AP,描述如下:
真正的艺术适应。首先,我们想对我们的模型在处理大领域差距的广告方面的有效性进行基准测试。在此设置中,我们使用真实图像和艺术图像之间的域转移效果来测试我们的模型。我们使用 Pascal VOC 作为源数据集,使用剪贴画 1k 或水彩画 2k 作为目标数据集。 ResNet-101 [13] 的主干是按照现有作品中的设置使用的。
不利天气适应。对于这个设置,我们在正常天气图像和恶劣天气(有雾)图像之间的域偏移上评估我们的模型。 Cityscapes 数据集的数据作为源域,Foggy Cityscapes 数据集的数据作为目标域。在实验中,该模型使用来自 Cityscapes 的标记图像和来自 Foggy Cityscapes 的未标记图像进行训练。报告了 Foggy Cityscapes 验证集的测试结果。尽管 Cityscapes 和 Foggy Cityscapes 数据集之间存在一对一的图像映射,但我们并未在所有实验中使用此类信息。VGG16 [36] 的主干按照之前的设置使用。
4.4.结果和比较
在本节中,我们在表 1 和表 3 中报告了 Adaptive Teacher 和其他最先进方法的性能。我们还报告了表示为“Source (F-RCNN)”的纯源模型作为训练基础仅使用源图像作为下限基准的更快 RCNN 模型。另一方面,我们还包括一个称为“Oracle (F-RCNN)”的 oracle 模型,作为使用来自目标域的图像和地面实况注释来训练基本 Faster RCNN 模型,这可以被视为上限基准。
真正的艺术适应。设置结果:Clipart1k 上的真实到艺术适应如表 1 所示,Watercolor2k 上的设置结果如表 2 所示。
我们将我们的方法与几种最先进的方法进行比较,并报告预言机模型(完全监督)与每个竞争对手之间的性能差距。
我们观察到,首先,我们的模型以 49.3% 的 mAP 实现了最佳性能,并且大大超过了最近的竞争对手 UMT 5.2% 和其他方法。我们注意到,使用 Mean Teacher 的 UMT 在增强样式训练图像上已经有了显着的性能提升。然而,由于 Mean Teacher 在目标域上的伪标签质量存在固有问题,他们的模型在生成伪标签时也可能会在真实图像和艺术图像之间发生较大的域偏移。另一方面,我们的模型减轻了领域差距并大大提高了性能。其次,我们的模型是在 Clipart1k 数据集上唯一超过 oracle 模型的模型,表明采用 Mean Teacher 加对抗学习的相互学习能够弥合领域差距。在水彩 2k 上进行的实验中可以找到类似的观察结果。
不利天气适应:设置的结果:正常天气对恶劣天气的适应如表 3 所示。我们还报告了预言机模型(完全监督)与每个竞争对手之间的性能差距。与最先进的技术相比,我们可以看到,首先,我们的模型也大大优于所有最先进的方法(超过 9%)。在这些方法中,MTOR [1] 和 UMT [8] 是在他们的模型中采用 Mean Teacher 的两种方法。然而,由于前面讨论过的关于教师模型的增强和对源域的偏差的问题,他们的模型都受到产生噪声标签的影响,并导致我们的 A T 之间的性能差距。第二,我们模型的性能能够超过oracle 模型有很大的差距,这表明仅使用来自晴天(高能见度)的注释训练图像足以在不利的雾天(低能见度)上获得令人满意的目标检测性能。
4.5.域泛化实验
正如我们观察到的,我们的 A T 在三个基准域适应数据集上优于所有 Oracle 模型,我们更感兴趣的是我们的模型在看不见的领域上的泛化能力。我们将此类问题定义为域泛化:我们不再关注模型在目标域上的准确性,而是将模型进一步泛化到完全不可见的域并评估其泛化能力。在本节中,我们进一步进行了两个实验设置,并将我们的 A T 与基线模型 MT [40] 进行比较:

在每个设置中,我们在带有标签的源真实数据集和另一个没有标签的艺术数据集上训练模型。然后,我们在训练期间看不到的目标数据集上推断模型。我们只对Clipart1k 和Watercolor2k 之间的重叠类(6 个类)进行训练,并将结果列在表4 中。从表中可以看出,与Oracle 模型和MT 相比,我们的模型取得了优越的性能。这表明我们的模型能够在不观察任何目标图像的情况下推广到看不见的领域。此外,关于 MT 的对抗性损失或增强的每一项消融研究也显示了它们在我们提出的 A T 中的作用的重要性。
4.6.消融研究
我们进一步对表 5 中的每个重要组件进行消融研究,并在图 3 中展示伪标签的定性研究。
对抗性损失 Ldis。
为了进一步分析对抗性学习在我们的 Adaptive Teacher 中的重要性,我们排除了判别器中的损失 Ldis,并在表 5 中报告了三个实验设置的性能。可以观察到,Clipart1k 和Watercolor2k 出现了 8.7% 和 4.4% 的性能下降在领域差距较大的场景中(真实到艺术适应)。 Y et,在另一种具有较小域差距(天气适应)的场景中,仅观察到 2.2% 的性能下降。我们还可以观察到,Ldis 能够大大降低图 3 中教师模型生成的伪标签中的误报率。另一方面,我们还分析了图 4 中对抗性损失 Ldis 的权重 λdis。在该图中可以从两个方面观察到一些现象。我们可以看到,首先,增加权重可以提高性能,这支持了我们模型中鉴别器的有效性。其次,在不应用对抗性损失的情况下,由于来自噪声伪标签的错误传播,模型的性能不断下降。
增强管道。我们还在 Adaptive Teacher 中对弱强(WS)增强的有效性进行了基准测试,当排除它时,观察到大约 4% 到 5% 的性能下降(表 5)。这表明对训练管道的简单修改(分别对教师和学生进行弱增强和强增强)至关重要。我们还可以观察到,这种增强管道能够降低图 3 中教师模型生成的伪标签中的误报率。
Lunsup & EMA。同样,我们消除了使用表 5 中的平均教师作为以前工作的重要性(即,从我们的模型中排除相互学习和教师模型),并报告了学生模型在跨域训练中的性能,仅具有强大的增强和对抗性损失 Ldis。我们可以看到有一个显着的性能下降,因此性能增益主要来自于目标域上的伪标签的相互学习。
5. 结论
在本文中,我们提出了一个新的框架来解决跨域对象检测的任务。通过引入目标域教师模型和跨域学生模型,该框架能够通过相互学习在目标域上生成正确的伪标签。我们设计的具有适当增强策略和对抗性学习的训练管道也解决了教师和学生模型中对源域的偏见。在两个基准上的实验证实了我们模型在跨域目标检测方面的有效性和优越性。消融研究的广泛实验也证明了我们提出的模型在没有看到目标域上的标签和图像的情况下训练的模型优于在完全监督下训练的 Oracle 模型。
致谢:我们感谢 Meta (Facebook) 的赞助和计算资源。
References
[1] Qi Cai, Yingwei Pan, Chong-Wah Ngo, Xinmei Tian, Lingyu
Duan, and Ting Yao. Exploring object relation in mean
teacher for cross-domain detection. In CVPR, pages 11457–
11466, 2019. 2, 3, 5, 6, 7
[2] Chaoqi Chen, Zebiao Zheng, Xinghao Ding, Y ue Huang, and
Qi Dou. Harmonizing transferability and discriminability for
adapting object detectors. In CVPR, pages 8869–8878, 2020.
1, 3, 5, 6
[3] Y uhua Chen, Wen Li, Christos Sakaridis, Dengxin Dai, and
Luc V an Gool. Domain adaptive faster r-cnn for object de-
tection in the wild. In CVPR, pages 3339–3348, 2018. 1, 3,
6
[4] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo
Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe
Franke, Stefan Roth, and Bernt Schiele. The cityscapes
dataset for semantic urban scene understanding. In CVPR,
pages 3213–3223, 2016. 5
[5] Jifeng Dai, Yi Li, Kaiming He, and Jian Sun. R-fcn: Object
detection via region-based fully convolutional networks. In
NeurIPS, pages 379–387, 2016. 2
[6] Jifeng Dai, Haozhi Qi, Y uwen Xiong, Yi Li, Guodong
Zhang, Han Hu, and Yichen Wei. Deformable convolutional
networks. In ICCV, pages 764–773, 2017. 2
[7] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li,
and Li Fei-Fei. Imagenet: A large-scale hierarchical image
database. In CVPR, pages 248–255. Ieee, 2009. 6
[8] Jinhong Deng, Wen Li, Y uhua Chen, and Lixin Duan. Un-
biased mean teacher for cross-domain object detection. In
CVPR, pages 4091–4101, 2021. 2, 3, 5, 6, 7
[9] Mark Everingham, Luc V an Gool, Christopher KI Williams,
John Winn, and Andrew Zisserman. The pascal visual object
classes (voc) challenge. IJCV, 88(2):303–338, 2010. 5
[10] Yaroslav Ganin and Victor Lempitsky. Unsupervised domain
adaptation by backpropagation. In Proceedings of the In-
ternational Conference on Machine Learning (ICML), pages
1180–1189. PMLR, 2015. 1, 2, 3, 4
[11] Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pas-
cal Germain, Hugo Larochelle, Franc ¸ois Laviolette, Mario
Marchand, and Victor Lempitsky. Domain-adversarial train-
ing of neural networks. The journal of machine learning
research, 17(1):2096–2030, 2016. 2
[12] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Gir-
shick. Mask r-cnn. In ICCV, pages 2961–2969, 2017. 6
[13] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.
Deep residual learning for image recognition. In CVPR,
pages 770–778, 2016. 6
[14] Zhenwei He and Lei Zhang. Multi-adversarial faster-rcnn
for unrestricted object detection. In ICCV, pages 6668–6677,
2019. 1, 3, 6
[15] Han Hu, Jiayuan Gu, Zheng Zhang, Jifeng Dai, and Yichen
Wei. Relation networks for object detection. In CVPR, pages
3588–3597, 2018. 2
[16] Naoto Inoue, Ryosuke Furuta, Toshihiko Yamasaki, and Kiy-
oharu Aizawa. Cross-domain weakly-supervised object de-
tection through progressive domain adaptation. In CVPR,
pages 5001–5009, 2018. 5
[17] Mehran Khodabandeh, Arash V ahdat, Mani Ranjbar, and
William G Macready. A robust learning approach to domain
adaptive object detection. In ICCV, pages 480–490, 2019. 3
[18] Seunghyeon Kim, Jaehoon Choi, Taekyung Kim, and Chang-
ick Kim. Self-training and adversarial background regular-
ization for unsupervised domain adaptive one-stage object
detection. In ICCV, pages 6092–6101, 2019. 3
[19] Taekyung Kim, Minki Jeong, Seunghyeon Kim, Seokeon
Choi, and Changick Kim. Diversify and match: A domain
adaptive representation learning paradigm for object detec-
tion. In CVPR, pages 12456–12465, 2019. 5, 6
[20] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He,
Bharath Hariharan, and Serge Belongie. Feature pyramid
networks for object detection. In CVPR, pages 2117–2125,
2017. 2
[21] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian
Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C
Berg. Ssd: Single shot multibox detector. In ECCV, pages
21–37. Springer, 2016. 2
[22] Yen-Cheng Liu, Chih-Yao Ma, Zijian He, Chia-Wen Kuo,
Kan Chen, Peizhao Zhang, Bichen Wu, Zsolt Kira, and Peter
V ajda. Unbiased teacher for semi-supervised object detec-
tion. In ICLR, 2021. 2
[23] Mingsheng Long, Y ue Cao, Jianmin Wang, and Michael Jor-
dan. Learning transferable features with deep adaptation net-
works. In Proceedings of the International Conference on
Machine Learning (ICML), pages 97–105. PMLR, 2015. 2
[24] Mingsheng Long, Han Zhu, Jianmin Wang, and Michael I
Jordan. Unsupervised domain adaptation with residual trans-
fer networks. In NeurIPS, 2016. 2
[25] Mingsheng Long, Han Zhu, Jianmin Wang, and Michael I
Jordan. Deep transfer learning with joint adaptation net-
works. In Proceedings of the International Conference on
Machine Learning (ICML), pages 2208–2217. PMLR, 2017.
2
[26] Chao Peng, Tete Xiao, Zeming Li, Y uning Jiang, Xiangyu
Zhang, Kai Jia, Gang Y u, and Jian Sun. Megdet: A large
mini-batch object detector. In CVPR, pages 6181–6189,
2018. 2
[27] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali
Farhadi. Y ou only look once: Unified, real-time object de-
tection. In CVPR, pages 779–788, 2016. 2
[28] Joseph Redmon and Ali Farhadi. Y olo9000: better, faster,
stronger. In CVPR, pages 7263–7271, 2017. 2
[29] Joseph Redmon and Ali Farhadi. Y olov3: An incremental
improvement. arXiv preprint arXiv:1804.02767, 2018. 2
[30] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun.
Faster r-cnn: Towards real-time object detection with region
proposal networks. In NeurIPS, volume 28, pages 91–99,
2015. 2, 6
[31] Aruni RoyChowdhury, Prithvijit Chakrabarty, Ashish Singh,
SouY oung Jin, Huaizu Jiang, Liangliang Cao, and Erik
Learned-Miller. Automatic adaptation of object detectors to
new domains using self-training. In CVPR, pages 780–790,
2019. 3
[32] Kuniaki Saito, Y oshitaka Ushiku, Tatsuya Harada, and Kate
Saenko. Strong-weak distribution alignment for adaptive ob-
ject detection. In CVPR, pages 6956–6965, 2019. 1, 3, 5, 6
9
[33] Christos Sakaridis, Dengxin Dai, and Luc V an Gool. Se-
mantic foggy scene understanding with synthetic data. IJCV,
126(9):973–992, 2018. 5
[34] Swami Sankaranarayanan, Y ogesh Balaji, Carlos D Castillo,
and Rama Chellappa. Generate to adapt: Aligning domains
using generative adversarial networks. In CVPR, pages
8503–8512, 2018. 2
[35] Zhiqiang Shen, Harsh Maheshwari, Weichen Yao, and Mar-
ios Savvides. Scl: Towards accurate domain adaptive object
detection via gradient detach based stacked complementary
losses. arXiv preprint arXiv:1911.02559, 2019. 5, 6
[36] Karen Simonyan and Andrew Zisserman. V ery deep convo-
lutional networks for large-scale image recognition. In ICLR,
2014. 6
[37] Bharat Singh, Hengduo Li, Abhishek Sharma, and Larry S
Davis. R-fcn-3000 at 30fps: Decoupling detection and clas-
sification. In CVPR, pages 1081–1090, 2018. 2
[38] Petru Soviany, Radu Tudor Ionescu, Paolo Rota, and Nicu
Sebe. Curriculum self-paced learning for cross-domain ob-
ject detection. Computer Vision and Image Understanding,
2021. 3
[39] Peng Su, Kun Wang, Xingyu Zeng, Shixiang Tang, Dapeng
Chen, Di Qiu, and Xiaogang Wang. Adapting object detec-
tors with conditional domain normalization. In ECCV, pages
403–419. Springer, 2020. 1, 3
[40] Antti Tarvainen and Harri V alpola. Mean teachers are better
role models: Weight-averaged consistency targets improve
semi-supervised deep learning results. In NeurIPS, 2017. 1,
2, 3, 4, 7
[41] Eric Tzeng, Judy Hoffman, Kate Saenko, and Trevor Darrell.
Adversarial discriminative domain adaptation. In Proceed-
ings of the IEEE conference on computer vision and pattern
recognition, pages 7167–7176, 2017. 2
[42] Chang-Dong Xu, Xing-Ran Zhao, Xin Jin, and Xiu-Shen
Wei. Exploring categorical regularization for domain adap-
tive object detection. In CVPR, pages 11724–11733, 2020.
1, 3, 5, 6
[43] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A
Efros. Unpaired image-to-image translation using cycle-
consistent adversarial networks. In ICCV, pages 2223–2232,
2017. 2, 3
[44] Xinge Zhu, Jiangmiao Pang, Ceyuan Yang, Jianping Shi, and
Dahua Lin. Adapting object detectors via selective cross-
domain alignment. In CVPR, pages 687–696, 2019. 1, 3,
6
[45] Chenfan Zhuang, Xintong Han, Weilin Huang, and Matthew
Scott. ifan: Image-instance full alignment networks for
adaptive object detection. In AAAI, volume 34, pages 13122–
13129, 2020.
最后
以上就是淡然唇彩最近收集整理的关于论文笔记:CVPR 2022 Cross-Domain Adaptive Teacher for Object Detection摘要1.介绍2.相关工作3.适应性教师4. 实验5. 结论References的全部内容,更多相关论文笔记:CVPR内容请搜索靠谱客的其他文章。








发表评论 取消回复