头一阵子放假了,专栏都没有怎么更新了,今天开始继续更新(想问问小伙伴们都放了多久的假期?我们只有两周感觉时间好短呀~)
作者&编辑 | 小米粥
上一期中,我们说明了GAN训练中的几个问题,例如由于把判别器训练得太好而引起的梯度消失的问题、通过采样估算距离而造成偏差的问题、minmax问题不清晰以及模式崩溃、优化选择在参数空间而非函数空间的问题等,今天这篇小文将从博弈论的角度出发来审视一下GAN训练时的问题,说明训练GAN其实是在寻找纳什均衡,然后说明达到纳什均衡或者说损失函数收敛是很难的,并最后给出了3个稳定训练的小技巧。
1 博弈论与GAN
大家对GAN的基本模型想必已经非常熟悉了,我们先从博弈论的角度来重新描述GAN模型。游戏中有两个玩家:D(判别器)和G(生成器),D试图在判别器的参数空间上寻找最好的解使得它的损失函数最小:
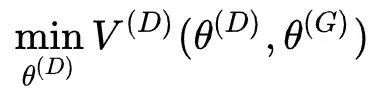
G也试图在生成器的参数空间上寻找最好的解使得它的损失函数最小:
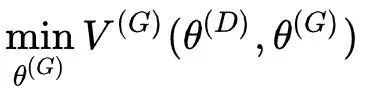
需要说明,D和G并不是彼此独立的,对于GAN,整个博弈是“交替进行决策”的。例如先确定生成器G的参数,则D会在给定的G的参数的条件下更新判别器的参数以此最小化D的损失函数,如下面中蓝线过程(提升D的辨别能力);接着G会在给定的D的参数的条件下更新判别器的参数以此来最小化G的损失函数,如下面中绿线过程(提升G的生成能力)......直到达到一个稳定的状态:纳什均衡。
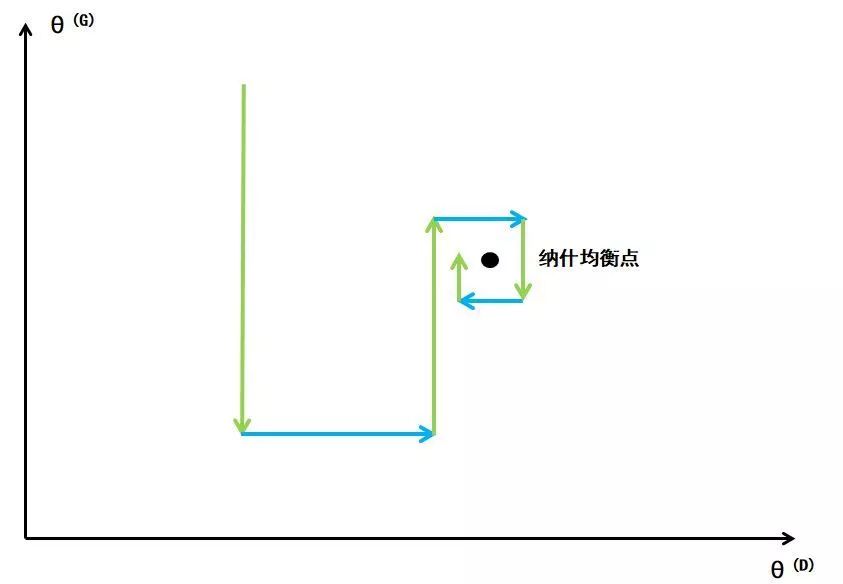
在纳什均衡点,两者的参数到达一种“制衡”状态。在给定G的参数情况下,D当前的参数便对应了D损失函数的最小值,同样在给定D的参数情况下,G当前的参数便对应了G损失函数的最小值,也就是说在交替更新过程中,D和G均不可能单独做出任何改变。
解空间中可能存在多个纳什均衡点,而且纳什均衡点并不意味着全局最优解,但是是一种经过多次博弈后的稳定状态,所以说GAN的任务是并非寻找全局最优解,而是寻找一个纳什均衡状态,损失函数收敛即可。在损失函数非凸、参数连续、参数空间维度很高的情况下,不可能通过严格的数学计算去更新参数从而找到纳什均衡,在GAN中,每次参数更新(对应蓝线、绿线表示的过程)使用的是梯度下降法;另外,每次D或者G对自身参数更新都会减少自身的损失函数同时加大对方的损失函数,这导致了寻找GAN的纳什均衡是比较困难的。
这里有一个比GAN简单多的例子表明很多时候纳什均衡的状态难以达到:
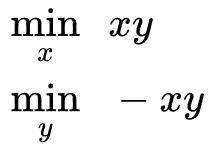
使用梯度下降法发现x,y在参数空间中并不会收敛到纳什均衡点(0,0),损失函数的表现为:不收敛。
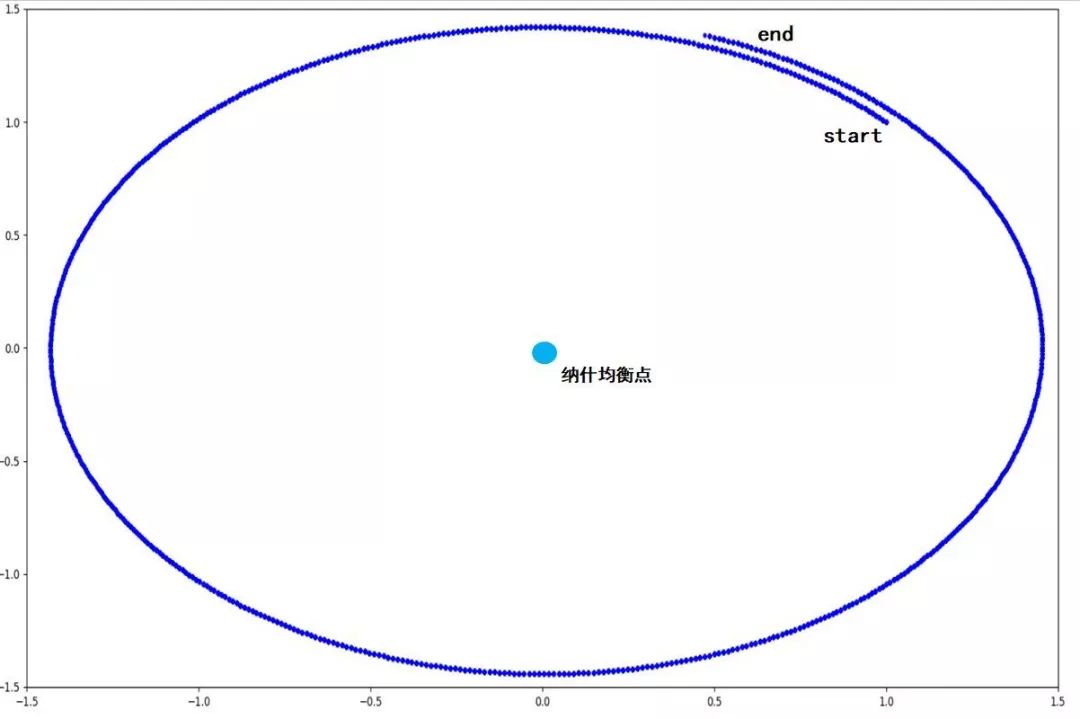
针对GAN训练的收敛性问题,我们接下来将介绍几种启发式的训练技巧。
2 特征匹配
在GAN中,判别器D输出一个0到1之间的标量表示接受的样本来源于真实数据集的概率,而生成器的训练目标就是努力使得该标量值最大。如果从特征匹配(feature matching)的角度来看,整个判别器D(x)由两部分功能组成,先通过前半部分f(x)提取到样本的抽象特征,后半部分的神经网络根据抽象特征进行判定分类,即
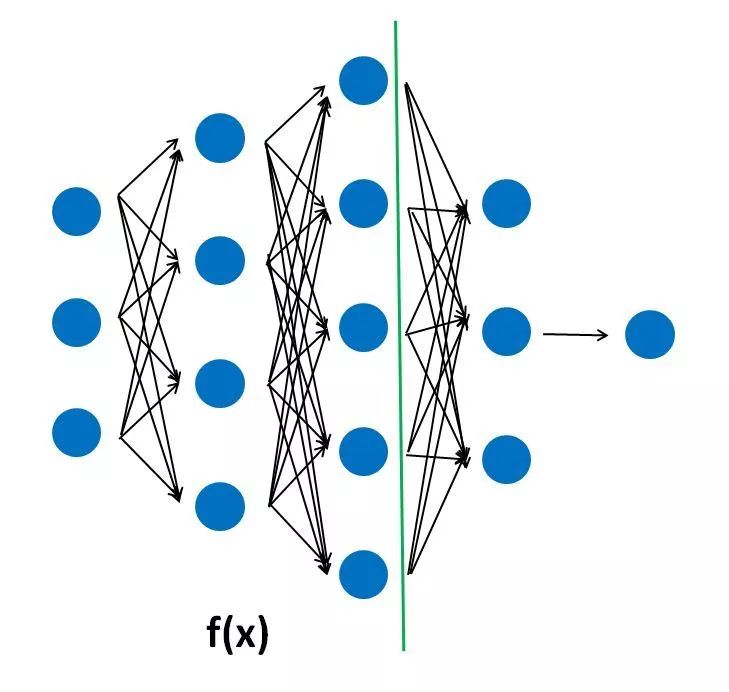
f(x)表示判别器中截止到中间某层神经元激活函数的输出。在训练判别器时,我们试图找到一种能够区分两类样本的特征提取方式f(x),而在训练生成器的时候,我们可以不再关注D(x)的概率输出,我们可以关注:从生成器生成样本中用f(x)提取的抽象特征是否与在真实样本中用f(x)提取的抽象特征相匹配,另外,为了匹配这两个抽象特征的分布,考虑其一阶统计特征:均值,即可将生成器的目标函数改写为:
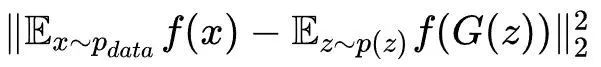
采用这样的方式,我们可以让生成器不过度训练,让训练过程相对稳定一些。
3 历史均值
历史均值(historical averaging)是一个非常简单方法,就是在生成器或者判别器的损失函数中添加一项:
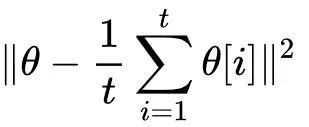
这样做使得判别器或者生成器的参数不会突然产生较大的波动,直觉上看,在快要达到纳什均衡点时,参数会在纳什均衡点附近不断调整而不容易跑出去。这个技巧在处理低维问题时确实有助于进入纳什均衡状态从而使损失函数收敛,但是GAN中面临的是高维问题,助力可能有限。
4 单侧标签平滑
标签平滑(label smoothing)方法最开始在1980s就提出过,它在分类问题上具有非常广泛的应用,主要是为了解决过拟合问题。一般的,我们的分类器最后一层使用softmax层输出分类概率(Sigmoid只是softmax的特殊情况),我们用二分类softmax函数来说明一下标签平滑的效果。
对于给定的样本x,其类别为1,则标签为[1,0],如果不用标签平滑,只使用“硬”标签,其交叉熵损失函数为:
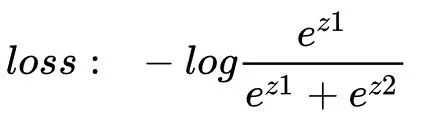
这时候通过最小化交叉熵损失函数来训练分类器,本质上是使得:
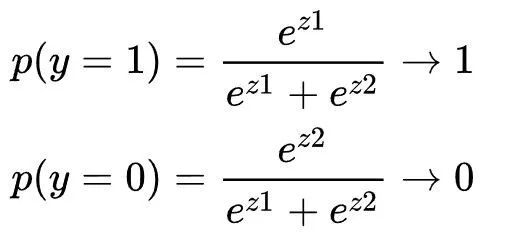
其实也就是使得:
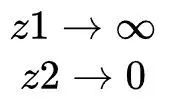
对于给定的样本x,使z1的值无限大(当然这在实际中是不可能的)而使z2趋于0,无休止拟合该标签1,便产生了过拟合、降低了分类器的泛化能力。如果使用标签平滑手段,对给定的样本x,其类别为1,例如平滑标签为[1-ε ,ε],交叉损失函数为:
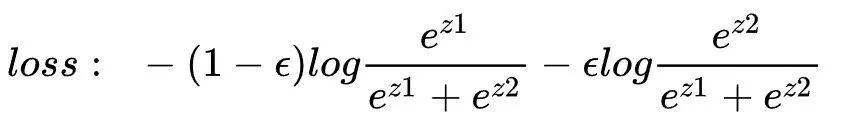
当损失函数达到最小值时,有:
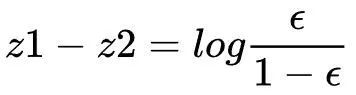
选择合适的参数,理论上的最优解z1与z2存在固定的常数差值(此差值由ε决定),便不会出现z1无限大,远大于z2的情况了。如果将此技巧用在GAN的判别器中,即对生成器生成的样本输出概率值0变为β ,则生成器生成的单样本交叉熵损失函数为:
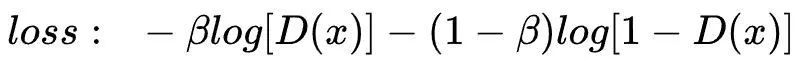
而对数据集中的样本打标签由1降为α,则数据集中的单样本交叉熵损失函数为:
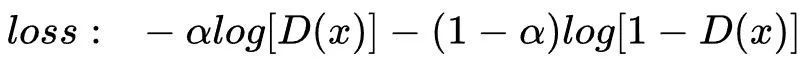
总交叉损失函数为:
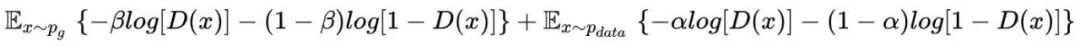
求导容易得其最优解D(x)为:
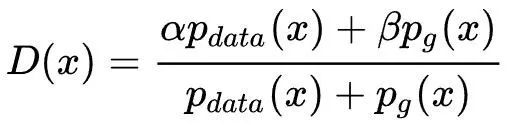
实际训练中,有大量这样的x:其在训练数据集中概率分布为0,而在生成器生成的概率分布不为0,他们经过判别器后输出为β。为了能迅速“识破”该样本,最好将β降为0,这就是所谓的单侧标签平滑。
训练GAN时,我们对它的要求并不是找到全局最优解,能进入一个纳什均衡状态、损失函数收敛就可以了。(虽然这个纳什均衡状态可能非常糟糕)最近的几篇文章将着重于讨论GAN训练的收敛问题。
[1] Müller, Rafael, S. Kornblith , and G. Hinton . "When Does Label Smoothing Help?." 2019
[2] Salimans T , Goodfellow I , Zaremba W , et al. Improved Techniques for Training GANs[J]. 2016.
总结
这篇文章阐述了GAN的训练其实是一个寻找纳什均衡状态的过程,然而想采用梯度下降达到收敛是比较难的,最后给出了几条启发式的方法帮助训练收敛。
下期预告:GAN训练中的动力学
GAN群

有三AI建立了一个GAN群,便于有志者相互交流。感兴趣的同学也可以微信搜索xiaozhouguo94,备注"加入有三-GAN群"。
有三AI夏季划
有三AI夏季划进行中,欢迎了解并加入,系统性成长为中级CV算法工程师。
转载文章请后台联系
侵权必究

往期精选
【GAN优化】GAN优化专栏上线,首谈生成模型与GAN基础
【GAN的优化】从KL和JS散度到fGAN
【GAN优化】详解对偶与WGAN
【GAN优化】详解SNGAN(频谱归一化GAN)
【GAN优化】一览IPM框架下的各种GAN
【GAN优化】GAN优化专栏栏主小米粥自述,脚踏实地,莫问前程
【GAN优化】GAN训练的几个问题
【技术综述】有三说GANs(上)
【模型解读】历数GAN的5大基本结构
最后
以上就是正直大白最近收集整理的关于【GAN优化】GAN训练的小技巧的全部内容,更多相关【GAN优化】GAN训练内容请搜索靠谱客的其他文章。








发表评论 取消回复