1.输入Normalize
- 将输入图片Normalize到 [ − 1 , 1 ] [-1,1] [−1,1]之间。
- 生成器最后一层的输出使用Tanh激活函数。
Normalize非常重要,没有处理过的图片是没办法收敛的。图片Normalize一种简单的方法是(images-127.5)/127.5,然后送到判别器去训练。同理生成的图片也要经过判别器,即生成器的输出也是-1到1之间,所以使用Tanh激活函数更加合适。
2.替换原始的GAN损失函数和标签反转
-
原始GAN损失函数会出现训练早期梯度消失和Mode collapse(模型崩溃)问题。可以使用Earth Mover distance(推土机距离)来优化。
-
实际工程中用反转标签来训练生成器更加方便,即把生成的图片当成real的标签来训练,把真实的图片当成fake来训练。
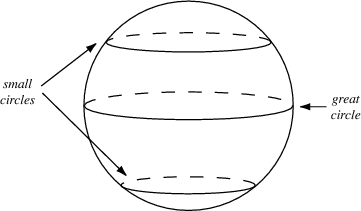
3.使用具有球形结构的随机噪声 Z Z Z作为输入
- 不要使用均匀分布进行采样
- 使用高斯分布进行采样
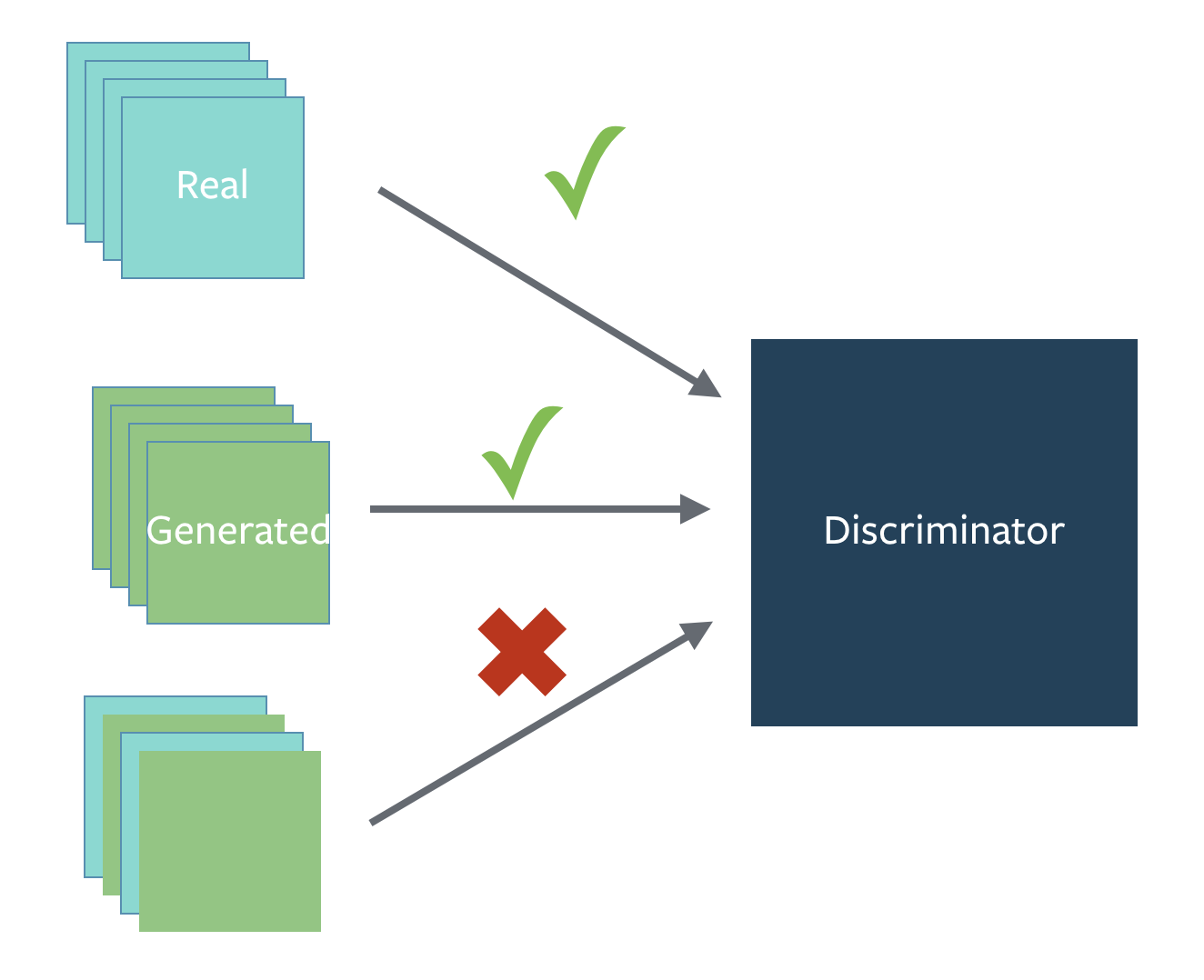
4.使用BatchNorm
- 一个mini-batch中必须只有real数据或者fake数据,不要把他们混在一起训练。
- 如果能用BatchNorm就用BatchNorm,如果不能用则用instance normalization。
5.避免使用ReLU,MaxPool等操作引入稀疏梯度
- GAN的稳定性会因为引入稀疏梯度受到很大影响。
- 最好使用类LeakyReLU的激活函数。(D和G中都使用)
- 对于下采样,最好使用:Average Pooling或者卷积+stride。
- 对于上采样,最好使用:PixelShuffle或者转置卷积+stride。
最好去掉整个Pooling逻辑,因为使用Pooling会损失信息,这对于GAN训练没有益处。
6.使用Soft和Noisy的标签
- Soft Label,即使用 [ 0.7 − 1.2 ] [0.7-1.2] [0.7−1.2]和 [ 0 − 0.3 ] [0-0.3] [0−0.3]两个区间的随机值来代替正样本和负样本的Hard Label。
- 可以在训练时对标签加一些噪声,比如随机翻转部分样本的标签。
7.使用Adam优化器
- Adam优化器对于GAN来说非常有用。
- 在生成器中使用Adam,在判别器中使用SGD。
8.追踪训练失败的信号
- 判别器的损失=0说明模型训练失败。
- 如果生成器的损失稳步下降,说明判别器没有起作用。
9.在输入端适当添加噪声
- 在判别器的输入中加入一些人工噪声。
- 在生成器的每层中都加入高斯噪声。
10.生成器和判别器差异化训练
- 多训练判别器,尤其是加了噪声的时候。
11.Two Timescale Update Rule (TTUR)
对判别器和生成器使用不同的学习速度。使用较低的学习率更新生成器,判别器使用较高的学习率进行更新。
12. Gradient Penalty (梯度惩罚)
使用梯度惩罚机制可以极大增强 GAN 的稳定性,尽可能减少mode collapse问题的产生。
13. Spectral Normalization(谱归一化)
Spectral normalization可以用在判别器的weight normalization技术,可以确保判别器是K-Lipschitz连续的。
14. 使用多个GAN结构
可以使用多个GAN/多生成器/多判别器结构来让GAN训练更稳定,提升整体效果,解决更难的问题。
最后
以上就是超级老师最近收集整理的关于深度学习_GAN_GAN优化训练方法汇总(全网最全,持续更新)的全部内容,更多相关深度学习_GAN_GAN优化训练方法汇总(全网最全内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复