Python爬虫的方式有多种,从爬虫框架到解析提取,再到数据存储,各阶段都有不同的手段和类库支持。虽然不能一概而论哪种方式一定更好,毕竟不同案例需求和不同应用场景会综合决定采取哪种方式,但对比之下还是会有很大差距。

00 概况
以安居客杭州二手房信息为爬虫需求,分别对比实验了三种爬虫框架、三种字段解析方式和三种数据存储方式,旨在全方面对比各种爬虫方式的效率高低。
安居客平台没有太强的反爬措施,只要添加headers模拟头即可完美爬取,而且不用考虑爬虫过快的问题。选中杭州二手房之后,很容易发现url的变化规律。值得说明的是平台最大开放50页房源信息,每页60条。为使爬虫简单便于对比,我们只爬取房源列表页的概要信息,而不再进入房源详情页进行具体信息的爬取,共3000条记录,每条记录包括10个字段:标题,户型,面积,楼层,建筑年份,小区/地址,售卖标签,中介,单价,总价。
01 3种爬虫框架
1. 常规爬虫
实现3个函数,分别用于解析网页、存储信息,以及二者的联合调用。在主程序中,用一个常规的循环语句逐页解析。
import requests
from lxml import etree
import pymysql
import time
def get_info(url):
pass
return infos
def save_info(infos):
pass
def getANDsave(url):
pass
if __name__ == '__main__':
urls = [f'https://hangzhou.anjuke.com/sale/p{page}/' for page in range(1,51)]
start = time.time()
#常规单线程爬取
for url in urls:
getANDsave(url)
tt = time.time()-start
print("共用时:",tt, "秒。")
耗时64.9秒。
2. Scrapy框架
Scrapy框架是一个常用的爬虫框架,非常好用,只需要简单实现核心抓取和存储功能即可,而无需关注内部信息流转,而且框架自带多线程和异常处理能力。
class anjukeSpider(scrapy.Spider):
name = 'anjuke'
allowed_domains = ['anjuke.com']
start_urls = [f'https://hangzhou.anjuke.com/sale/p{page}/' for page in range(1, 51)]
def parse(self, response):
pass
yield item
耗时14.4秒。
3. 多线程爬虫
对于爬虫这种IO密集型任务来说,多线程可明显提升效率。实现多线程python的方式有多种,这里我们应用concurrent的futures模块,并设置最大线程数为8。
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
def get_info(url):
pass
return infos
def save_info(infos):
pass
def getANDsave(url):
pass
if __name__ == '__main__':
urls = [f'https://hangzhou.anjuke.com/sale/p{page}/' for page in range(1,51)]
start = time.time()
executor = ThreadPoolExecutor(max_workers=8)
future_tasks = [executor.submit(getANDsave, url) for url in urls]
wait(future_tasks, return_when = ALL_COMPLETED)
tt = time.time()-start
print("共用时:",tt, "秒。")
耗时8.1秒。
对比来看,多线程爬虫方案耗时最短,相比常规爬虫而言能带来数倍的效率提升,Scrapy爬虫也取得了不俗的表现。需要指出的是,这里3种框架都采用了Xpath解析和MySQL存储。
02 3种解析方式
在明确爬虫框架的基础上,如何对字段进行解析提取就是第二个需要考虑的问题,常用的解析方式有3种,一般而言,论解析效率Re>=Xpath>Bs4;论难易程度,Bs4则最为简单易懂。
因为前面已经对比得知,多线程爬虫有着最好的执行效率,我们以此为基础,对比3种不同解析方式,解析函数分别为:
1. Xpath
from lxml import etreedef get_info(url):
response = requests.get(url, headers = headers)
html = response.text
html = etree.HTML(html)
items = html.xpath("//li[@class = 'list-item']")
infos = []
for item in items:
try:
title = item.xpath(".//div[@class='house-title']/a/text()")[0].strip()
houseType = item.xpath(".//div[@class='house-details']/div[2]/span[1]/text()")[0]
area = item.xpath(".//div[@class='house-details']/div[2]/span[2]/text()")[0]
floor = item.xpath(".//div[@class='house-details']/div[2]/span[3]/text()")[0]
buildYear = item.xpath(".//div[@class='house-details']/div[2]/span[4]/text()")[0]
adrres = item.xpath(".//div[@class='house-details']/div[3]/span[1]/text()")[0]
adrres = "|".join(adrres.split())
tags = item.xpath(".//div[@class='tags-bottom']//text()")
tags = '|'.join(tags).strip()
broker = item.xpath(".//div[@class='broker-item']/span[2]/text()")[0]
totalPrice = item.xpath(".//div[@class='pro-price']/span[1]//text()")
totalPrice = "".join(totalPrice).strip()
price = item.xpath(".//div[@class='pro-price']/span[2]/text()")[0]
values = (title, houseType, area, floor, buildYear, adrres, tags, broker, totalPrice, price)
infos.append(values)
except:
print('1条信息解析失败')
return infos
耗时8.1秒。
2. Re
import re
def get_info(url):
response = requests.get(url, headers = headers)
html = response.text
html = html.replace('n','')
pattern = r'<li class="list-item" data-from="">.*?</li>'
results = re.compile(pattern).findall(html)##先编译,再正则匹配
infos = []
for result in results:
values = ['']*10
titles = re.compile('title="(.*?)"').findall(result)
values[0] = titles[0]
values[5] = titles[1].replace(' ','')
spans = re.compile('<span>(.*?)</span><em class="spe-lines">|</em><span>(.*?)</span><em class="spe-lines">|</em><span>(.*?)</span><em class="spe-lines">|</em><span>(.*?)</span>').findall(result)
values[1] =''.join(spans[0])
values[2] = ''.join(spans[1])
values[3] = ''.join(spans[2])
values[4] = ''.join(spans[3])
values[7] = re.compile('<span class="broker-name broker-text">(.*?)</span>').findall(result)[0]
tagRE = re.compile('<span class="item-tags tag-others">(.*?)</span>').findall(result)
if tagRE:
values[6] = '|'.join(tagRE)
values[8] = re.compile('<span class="price-det"><strong>(.*?)</strong>万</span>').findall(result)[0]+'万'
values[9] = re.compile('<span class="unit-price">(.*?)</span>').findall(result)[0]
infos.append(tuple(values))
return infos
耗时8.6秒。
3. Bs4
from bs4 import BeautifulSoup
def get_info(url):
response = requests.get(url, headers = headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
items = soup.find_all('li', attrs={'class': "list-item"})
infos = []
for item in items:
try:
title = item.find('a', attrs={'class': "houseListTitle"}).get_text().strip()
details = item.find_all('div',attrs={'class': "details-item"})[0]
houseType = details.find_all('span')[0].get_text().strip()
area = details.find_all('span')[1].get_text().strip()
floor = details.find_all('span')[2].get_text().strip()
buildYear = details.find_all('span')[3].get_text().strip()
addres = item.find_all('div',attrs={'class': "details-item"})[1].get_text().replace(' ','').replace('n','')
tag_spans = item.find('div', attrs={'class':'tags-bottom'}).find_all('span')
tags = [span.get_text() for span in tag_spans]
tags = '|'.join(tags)
broker = item.find('span',attrs={'class':'broker-name broker-text'}).get_text().strip()
totalPrice = item.find('span',attrs={'class':'price-det'}).get_text()
price = item.find('span',attrs={'class':'unit-price'}).get_text()
values = (title, houseType, area, floor, buildYear, addres, tags, broker, totalPrice, price)
infos.append(values)
except:
print('1条信息解析失败')
return infos
耗时23.2秒。
Xpath和Re执行效率相当,Xpath甚至要略胜一筹,Bs4效率要明显低于前两者(此案例中,相当远前两者效率的1/3),但写起来则最为容易。
03 存储方式
在完成爬虫数据解析后,一般都要将数据进行本地存储,方便后续使用。小型数据量时可以选用本地文件存储,例如CSV、txt或者json文件;当数据量较大时,则一般需采用数据库存储,这里,我们分别选用关系型数据库的代表MySQL和文本型数据库的代表MongoDB加入对比。
1. MySQL
import pymysql
def save_info(infos):
#####infos为列表形式,其中列表中每个元素为一个元组,包含10个字段
db= pymysql.connect(host="localhost",user="root",password="123456",db="ajkhzesf")
sql_insert = 'insert into hzesfmulti8(title, houseType, area, floor, buildYear, adrres, tags, broker, totalPrice, price) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'
cursor = db.cursor()
cursor.executemany(sql_insert, infos)
db.commit()
耗时8.1秒。
2. MongoDB
import pymongo
def save_info(infos):
# infos为列表形式,其中列表中的每个元素为一个字典,包括10个字段
client = pymongo.MongoClient()
collection = client.anjuke.hzesfmulti
collection.insert_many(infos)
client.close()
耗时8.4秒。
3. CSV文件
import csv
def save_info(infos):
# infos为列表形式,其中列表中的每个元素为一个列表,包括10个字段
with open(r"D:PyFileHZhouseanjuke.csv", 'a', encoding='gb18030', newline="") as f:
writer = csv.writer(f)
writer.writerows(infos)
耗时8.8秒。
可见,在爬虫框架和解析方式一致的前提下,不同存储方式间并不会带来太大效率上的差异。
04 结论
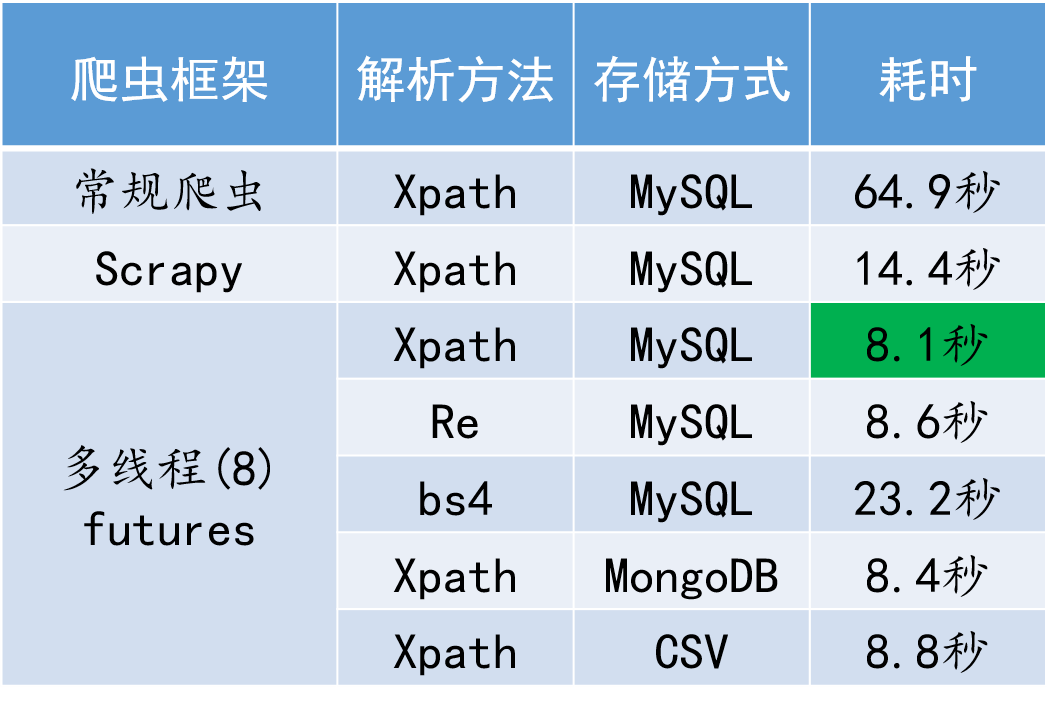
不同爬虫执行效率对比
易见,爬虫框架对耗时影响最大,甚至可带来数倍的效率提升;解析数据方式也会带来较大影响,而数据存储方式则不存在太大差异。
对此,个人认为可以这样理解:类似于把大象装冰箱需要3步,爬虫也需要3步:
网页源码爬取,
目标信息解析,
数据本地存储。
其中,爬取网页源码最为耗时,这不仅取决于你的爬虫框架和网络负载,还受限于目标网站的响应速度和反爬措施;信息解析其次,而数据存储则最为迅速,尤其是在磁盘读取速度飞快的今天,无论是简单的文件写入还是数据库存储,都不会带来太大的时间差异。
此为上篇。
下篇,我们将利用Pandas对爬取的房源信息进行数据分析和可视化。
每日留言
说说你最近遇到的有趣事情?
或者一句激励自己的话?
(字数不少于15字)
留言赠书
《Python网络爬虫开发》

2小时快速掌握Python基础知识要点。
完整Python基础知识要点
Python小知识 | 这些技能你不会?(一)
Python小知识 | 这些技能你不会?(二)
Python小知识 | 这些技能你不会?(三)
Python小知识 | 这些技能你不会?(四)
近期推荐阅读:
【1】整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了
【2】【终篇】Pandas中文官方文档:基础用法6(含1-5)
觉得不错就点一下“在看”吧

最后
以上就是深情小虾米最近收集整理的关于多种爬虫方式对比的全部内容,更多相关多种爬虫方式对比内容请搜索靠谱客的其他文章。








发表评论 取消回复