在训练深度模型的时候,Keras提供了对训练历史的默认回调方法。在深度学习的训练过程中,默认回调方法之一是history回调,它记录每个epoch的训练指标,包括损失和准确度。
训练过程的信息可以从fit的返回值获取,可以都存起来,来画图,可以很方便的看到模型的训练情况:
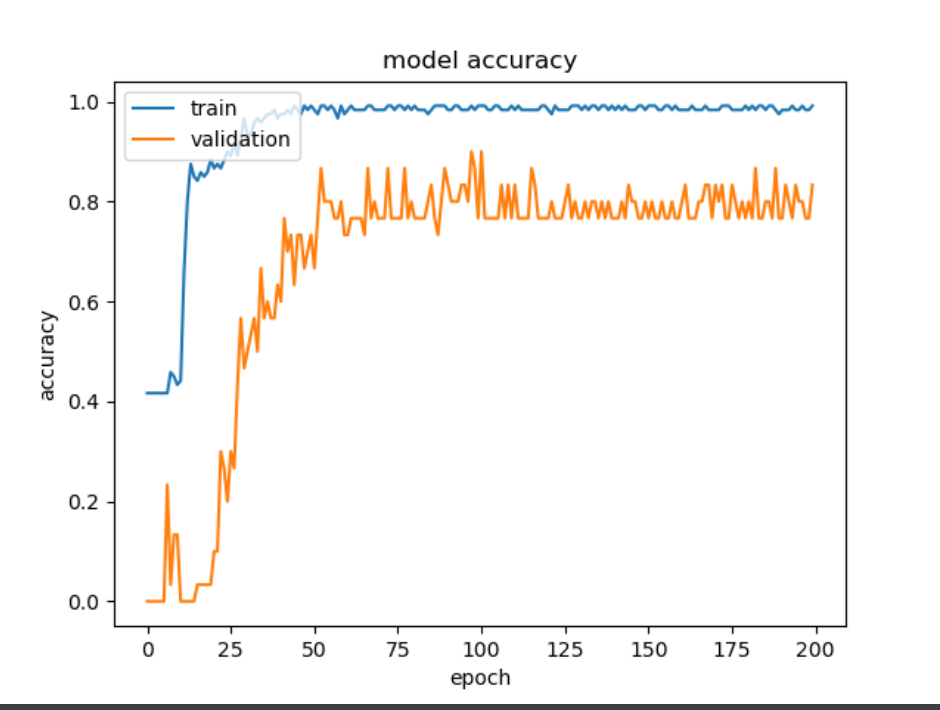
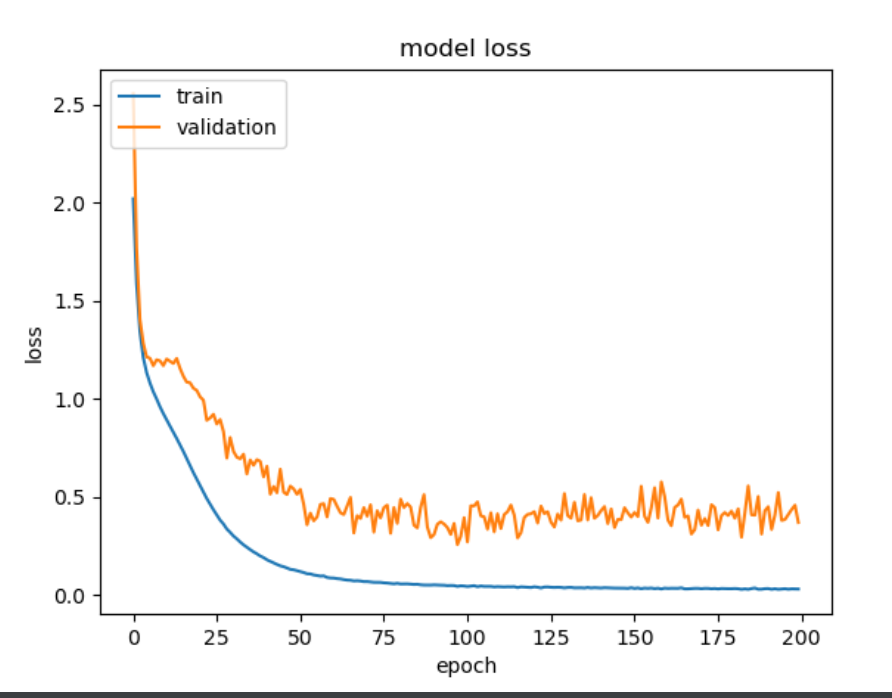
- 模型在epoch的收敛速度(斜率)
- 模型是否已经收敛(该线是否平滑收敛)
- 模型是否过拟合(验证线的拐点)
下面使用莺尾花数据集,来展示以下信息:
- 训练数据和评估数据在各epoch的准确度及损失情况
from sklearn import datasets
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import to_categorical
from matplotlib import pyplot as plt
# 导入数据
dataset = datasets.load_iris()
x = dataset.data
Y = dataset.target
# 将标签转换为分类 one-hot 编码
Y_labels = to_categorical(Y, num_classes=3)
# 设定随机种子
seed = 7
np.random.seed(seed)
# 构建模型函数
def create_model(optimizer='rmsprop', init='glorot_uniform'):
# 构建模型
model = Sequential()
model.add(Dense(units=4, activation='relu', input_dim=4, kernel_initializer=init))
model.add(Dense(units=6, activation='relu', kernel_initializer=init))
model.add(Dense(units=3, activation='softmax', kernel_initializer=init))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
# 构建模型
model = create_model()
history = model.fit(x, Y_labels, validation_split=0.2, epochs=200, batch_size=5, verbose=0)
# 评估模型
scores = model.evaluate(x, Y_labels, verbose=0)
print('%s: %.2f%%' % (model.metrics_names[1], scores[1] * 100))
# Hisotry列表
print(history.history.keys())
# accuracy的历史
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
# loss的历史
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()

最后
以上就是复杂长颈鹿最近收集整理的关于keras---训练过程的可视化的全部内容,更多相关keras---训练过程内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复