本教程为keras-yolov3版本的训练及测试全过程实现,为保证对新手的友好性,不会过多解释原理,主要是让新手能对全过程有个比较清楚的概念和认识,方便训练自己的数据。
本教程一共有三个部分:一.数据集准备及生成 二.训练所需知识 三.测试及相关性能测试可视化
一.数据集准备及生成:
1.先来熟悉文件结构
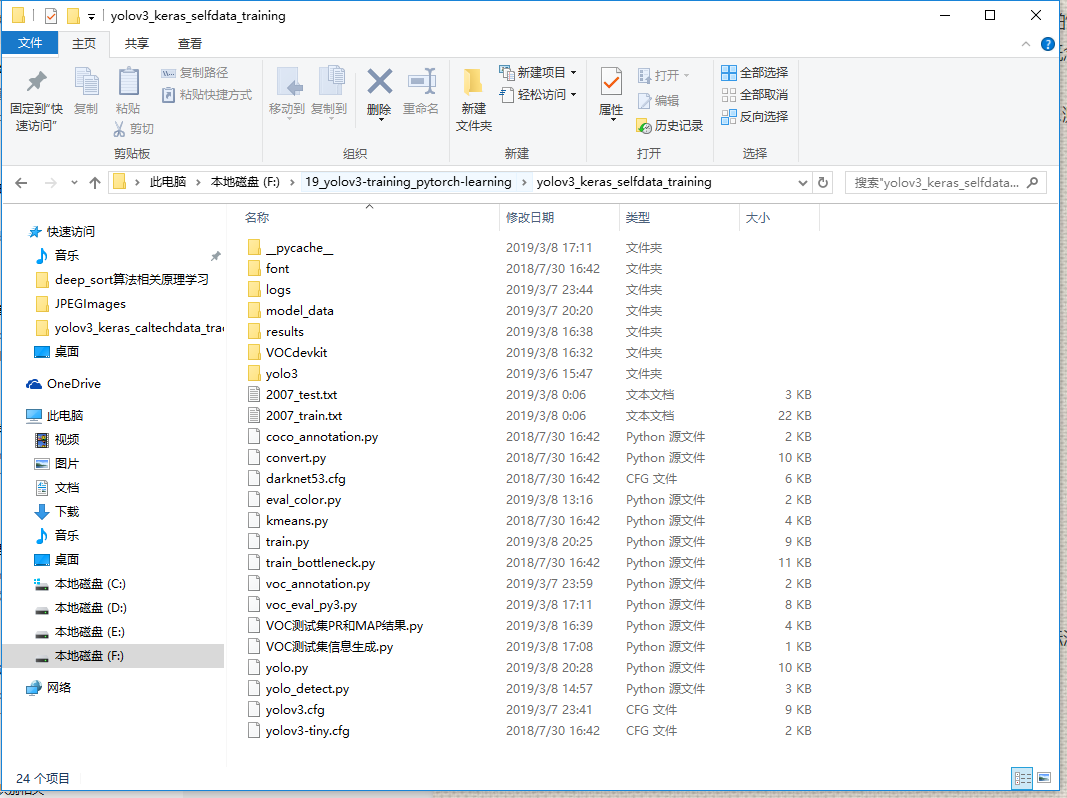
font文件夹下是保存keras-yolov3可能会调用到的字体及颜色,在测试部分有用,方便在图片上显示相应文字标签
logs文件夹是保存模型权重的,在训练时也会保存tensorflow下的tensorboard可视化图,可供查看训练曲线
model_data文件夹下保存有coco_classes.txt,tiny_yolo_anchors.txt,voc_classes.txt,yolo.h5,yolo_anchors.txt,yolo-tiny.h5这6个文件,其中必须需要的是后5个。因为在本次训练中,全程按照VOC2007数据集格式来,所以coco_classes.txt文件中保存的coco数据集类别数据可以删除不要,而后5个分别是yolo和tiny-yolo的anchors(锚点)大小和其在原版darknet下载训练并转换成keras模型的预训练权重,这些在训练过程中都要用到。
results文件夹是保存测试部分中对测试集图片进行测试的结果,在测试分析中需要用到
VOCdevkit文件夹是所有数据存放的文件夹,其下文件夹目录为
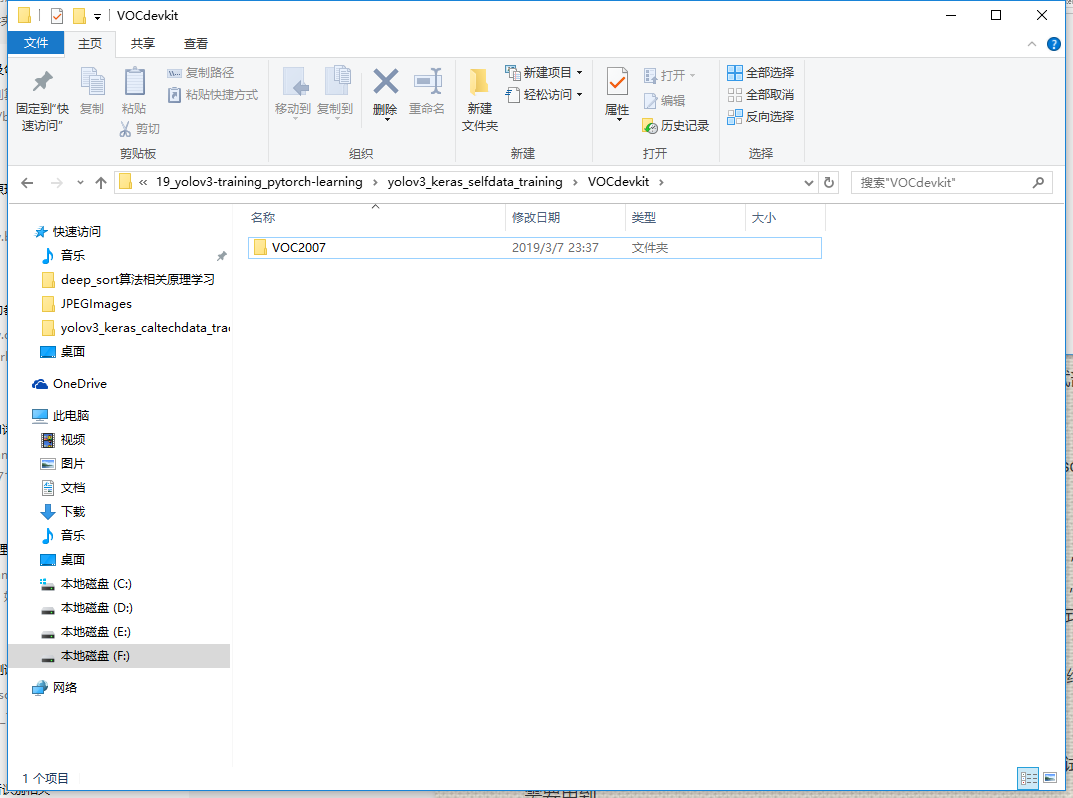
进入VOC2007文件夹可看到
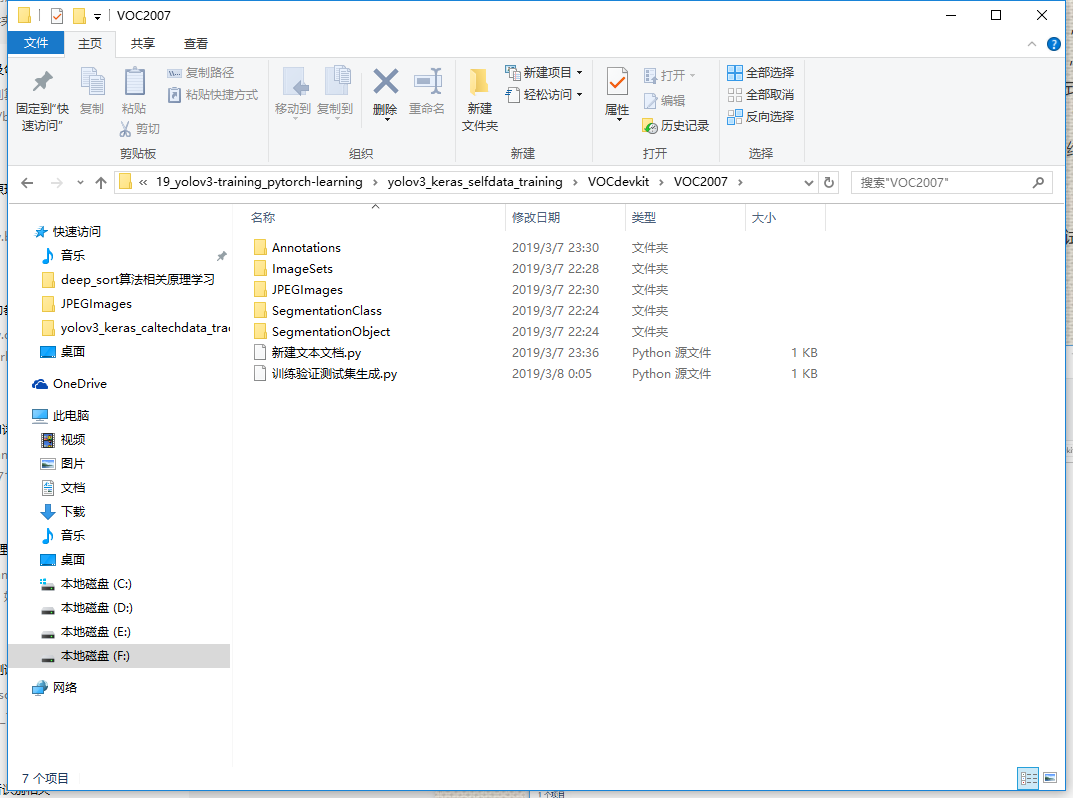
这里Annotations文件夹保存的是所有图片的标注框xml格式的数据。ImageSets文件夹下还有

三个子文件夹,其中只有Main文件夹有用,里面存放着训练需要调用的图片名称,
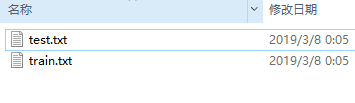
这里放着的是训练集和测试集的图片名称,方便训练时的调用。
JPEGImages文件夹下放着所有的图片文件,可以是JPG或者PNG格式的图片。
SegmentationClass和SegmentationObject是作为语义分割中用的,这里keras-yolov3是目标检测,所以可以删去不要。
训练验证测试集生成.py 文件是根据已有的xml(图片)数据生成Main文件夹下的test.txt和train.txt文件的脚本。
新建文本文档.py 文件是修改保存Annotations文件夹下的xml文件路径的脚本,如果路径都是对了,可以不用管这个脚本,如果不对,可以根据自己的文件所在目录进行更改。
回到最开始的目录,yolo3文件夹下保存的是keras-yolov3的模型源码。
2007_train.txt和2007_test.txt是在标注完数据后调用voc_annotation.py文件生成的训练数据和测试数据文件的集合,里面存放着图片路径和目标框信息及类别信息。
剩下的.py文件中最重要的是convert.py,kmeans.py,train.py,voc_annotation.py,yolo.py,yolo_detect.py,yolov3.cfg,yolov3-tiny.cfg这几个文件,其作用分别是:
convert.py 将darknet下训练的权重转化为keras权重使用
kmeans.py 可以根据你自己的xml数据生成新的anchors(锚点),如果自己的数据集数据太特殊,目标太大或者太小导致使用原版效果不好,可以使用这个文件修改anchors,以达到检测更好的效果
train.py 是训练模型并保存权重的文件
voc_annotation.py 是根据已有数据集生成2007_train.txt和2007_test.txt这两个训练时真正调用的文件
yolo.py 定义了yolo模型类,并提供了一些方法,可以方便调用yolo功能进行测试
yolo_detect.py 可以测试图片、视频及实时摄像头,直接生成结果
yolov3.cfg和yolov3-tiny.cfg是模型的config文件,里面定义了模型的结构,一般不用改变,在训练时会有一点地方需要改动
2.文件夹结构及作用讲完后,可以开始准备数据了。先限定是自己的数据集,那么只有源视频数据或者图片,没有任何标注,那么要做的第一件事是将视频转化为图片后存入VOCdevkit/VOC2007/JPEGImages文件目录下,然后使用已经安装好的labelImg对该目录下图片进行标注,并将生成的xml文件存入VOCdevkit/VOC2007/Annotations文件目录下。这两步做完后,运行 python 训练验证测试集生成.py 命令会在同目录下的ImageSets/Main文件下生成train.txt和test.txt,其train和test之间的比例可以通过改变训练验证测试集生成.py脚本中的test_percent = 0.1和train_percent = 0.9这两个数字进行改变。
之后返回根目录,运行 python voc_annotation.py 命令生成训练模型真正需要的2007_train.txt和2007_test.txt文件。至此,数据集的准备已经全部完成。
二.训练所需知识 :
准备好数据集后当然就是开始训练,在训练前有两个文件中的内容需要修改
–model_data/voc_classes.txt文件和yolov3.cfg文件,在voc_classes.txt中你只需要将根据你数据集的种类和标注时的标签对上,写下英文名字即可
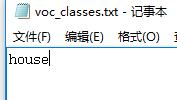
这里只有房子这一类,那么房子在标注时label设为0,在这里放第一个,如果有多类,只需要按照标注时的label数字从小到大写好就可以了;
yolov3.cfg中需要改的地方一共有三处:先进入文件,搜索 yolo 变会有三处地方显示出来,这三处都需要根据自己数据进行修改。如下图:
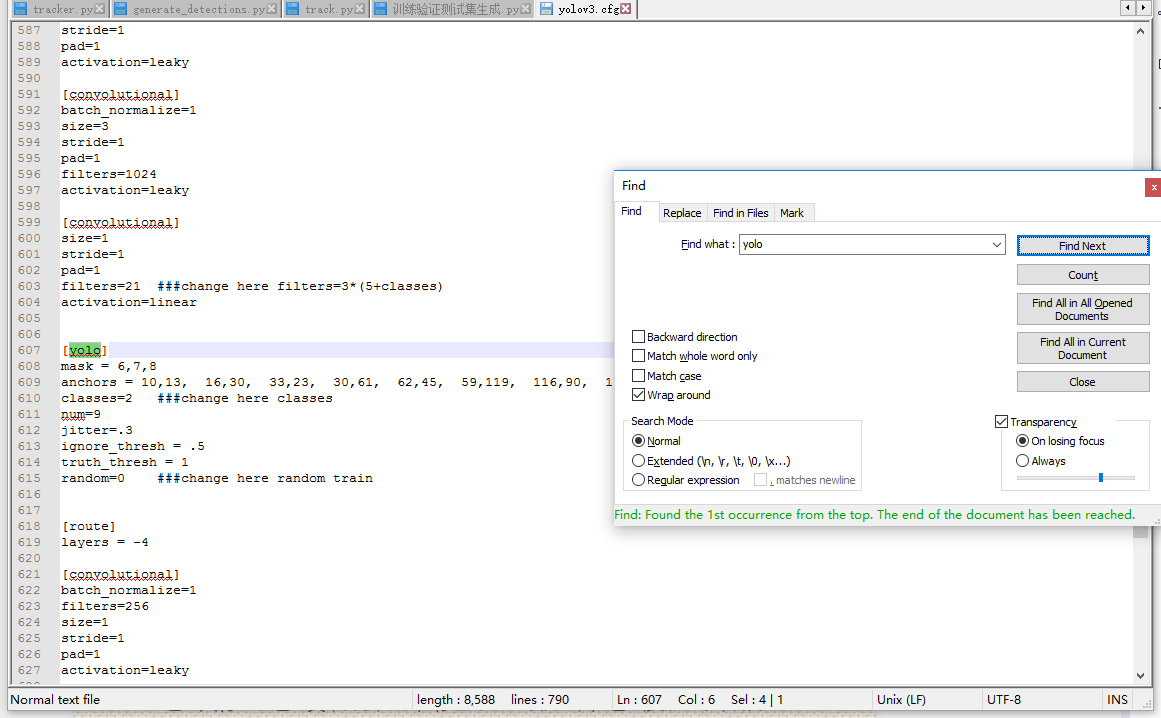
这是其中一处,这里我标注了三个地方需要改变,带有###change的就是了,filters根据公式3*(5+数据集类别数目)可以修改,这里只有一类那么修改为filters=18就可以(3*(5+1)=18);classes=2修改classes=1,因为只有一类;random=0代表了多尺度训练不开启,不开启对显存的要求会更低,这样显存不够的显卡也可以训练,如果random=1那么多尺度训练开启,在训练中图片会随机增强放大等等,对显存要求更高,这里设为0即可。
剩下两处也跟这里一样进行修改即可。
修改完这两个文件后,就可以进行train.py文件准备开始训练了,下面讲解一下train.py文件中的一些参数,方便自己训练修改:
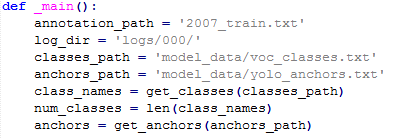
上图中的annotation_path,log_dir,classes_path,anchors_path分别代表了训练图片数据的路径,模型存放路径,数据集种类路径,模型anchors数据路径,这些自己都是可以修改的,这里我们因为前面的数据生成一直按照VOC2007格式来,所以这里可以不用变。

上图代表训练图片输入的宽高大小,其数值必须是32的倍数,一般设置为(320,320),(416,416),(608,608)这个根据你显存的大小和数据目标框大小进行改变,一般情况下(416,416)即可,这代表训练时会把图片都变成这个大小再送入网络中。

这里选择是使用yolov3的模型还是tiny-yolov3模型,tiny相对小速度快,不过精度降低。

这里进行数据的训练集和验证集划分,比例9:1,可以自行更改。
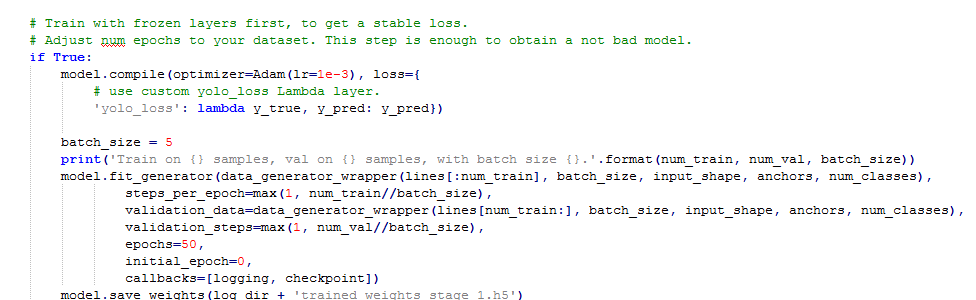
这里加载预训练模型进行预热,其作用在于使用预训练模型权重,只改变后两层的权重,前面特征提取的权重都没变,为后面不冻结模型-全部层训练打下了基础,方便其loss的降低,这里batch_size和epochs都可以更改,不过一般修改batch_size就够了,显存大的可以改大,预热训练完成后模型权重会保存到’logs/000/trained_weights_stage_1.h5’这里。
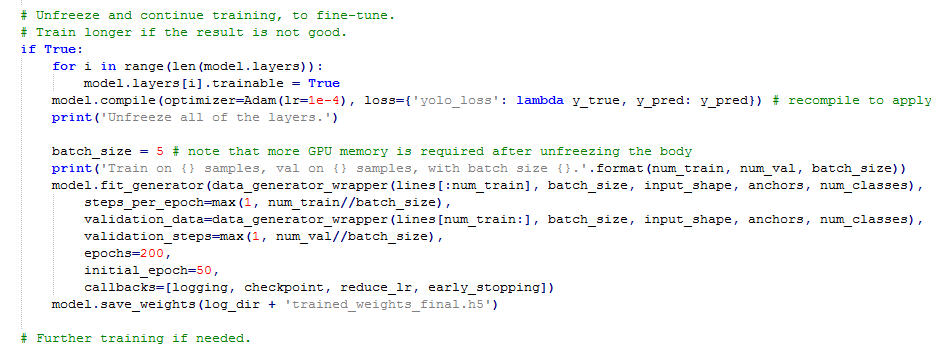
这里开启了所有层,都进行训练,轮数更多,以便训练到比较好的效果,让loss收敛。
注意:在keras-yolov3中因为模型构建时使用了l2正则化的措施,所以最终模型的loss都不会降到特别低,一般keras-yolov3loss降到10左右效果便可以了。
训练到结束即可,训练过程就此结束。
三.测试及相关性能测试可视化:
对单张图片,视频及摄像头测试可以使用 yolo_detect.py , 只要输入相应的参数即可,比如输入 python yolo_detect.py --image 后就可以对单张图片进行测试等等。这里要注意其调用的都是 yolo.py 中的Yolo类
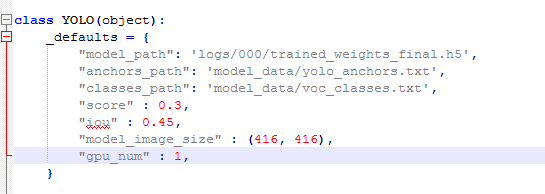
这些都是可以根据你自己实际需求改的,比如model_path就是你想测试的模型权重路径,anchors_path和classes_path也是同理,score代表一个阈值,只有置信度高于此值的目标才会被框出来,iou也是同理,model_image_size需要跟你训练时的input_shape一致,gpu_num代表你是否加载多GPU进行测试。
VOC测试集信息生成.py 文件使用了yolo.py 中的Yolo类进行测试集图片的测试,并将生成的结果保存下来,可以作为 pr曲线绘制和map计算的依据。
VOC测试集PR和MAP结果.py 文件调用了 voc_eval_py3.py 文件中的方法计算pr曲线和MAP,并将结果保存下来。
四. 结语:
这篇教程详细阐述了keras-yolov3下的训练和测试全过程,对关键地方进行了解释和说明,读者可以自行更改。关于yolov3 的原理可以自行去查阅资料,这里不作过多解释。
心得:
- 在keras-yolov3下,.cfg文件可以不用,在darknet下才有用,只是作为学习其结构的参考,所以我改了backbone后,将darknet_body改为mobilenet_body,一样可以正常训练和运行,只要保持结构一致即可。
- 在keras-yolov3下,主要修改的参数还是yolo_anchors.txt和train.py里create_model的ignoresh参数,还有input_shape,这个是决定你显存的,所以,由此也可以看出,keras-yolov3的效果比darknet原版差一些也是自然的,因为很多设置都是没法调的,能改的地方不多。
- 仿照原版的结构来理解即可,参读了一下源码,还是基本一致的,所以效果也还是可以的。进一步改进除了我改了的backbon外,估计就是改进结构了,那这个模型就得重新写了。大概就是这样
最后
以上就是善良香菇最近收集整理的关于keras-yolov3训练及测试详解的全部内容,更多相关keras-yolov3训练及测试详解内容请搜索靠谱客的其他文章。








发表评论 取消回复