论文传送门:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
FasterRCNN的目的:
完成目标检测任务。
FasterRCNN的改进:
相较于FastRCNN,提出了anchor的概念和RPN结构来取代SS(Selective Search)算法产生候选区域(region proposal),大大加快了模型的推理时间,并提高了目标检测任务的精度。
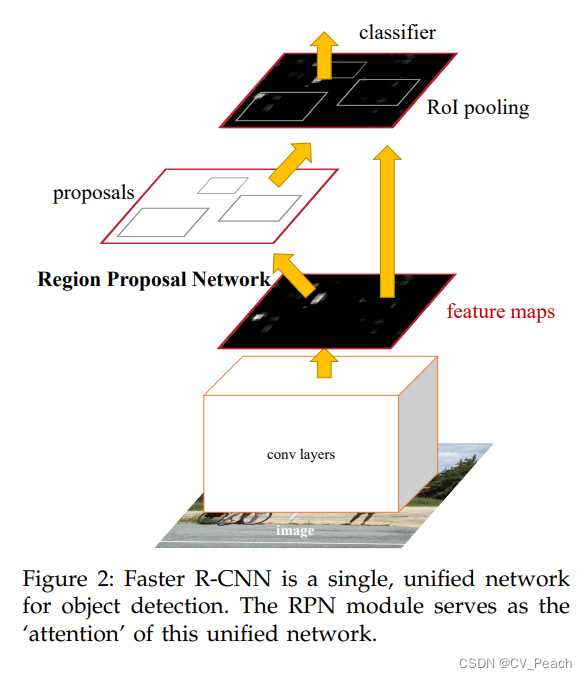
FasterRCNN的结构:
①Backbone:对输入图像(input images)使用卷积层(conv layers)进行特征提取,得到特征层(feature maps);
②Region Proposal Network(RPN):由特征层和预先设定的anchors,生成候选区域(region proposal/roi);
③Head:在特征层上对候选区域进行roi pooling,再经过分类器(classifier),输出候选区域的类别置信度和回归参数。
Anchor:
预先设定的一系列可能存在目标的框,需要设定:
①anchor的大小(面积)与高宽比;
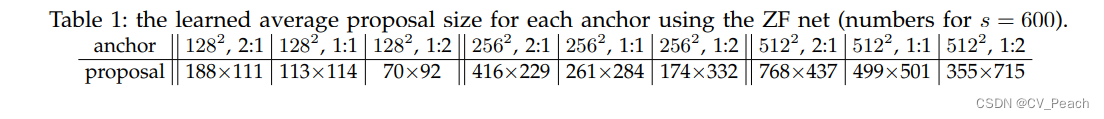
②anchor的数量与位置,与特征层的特征点相对应。
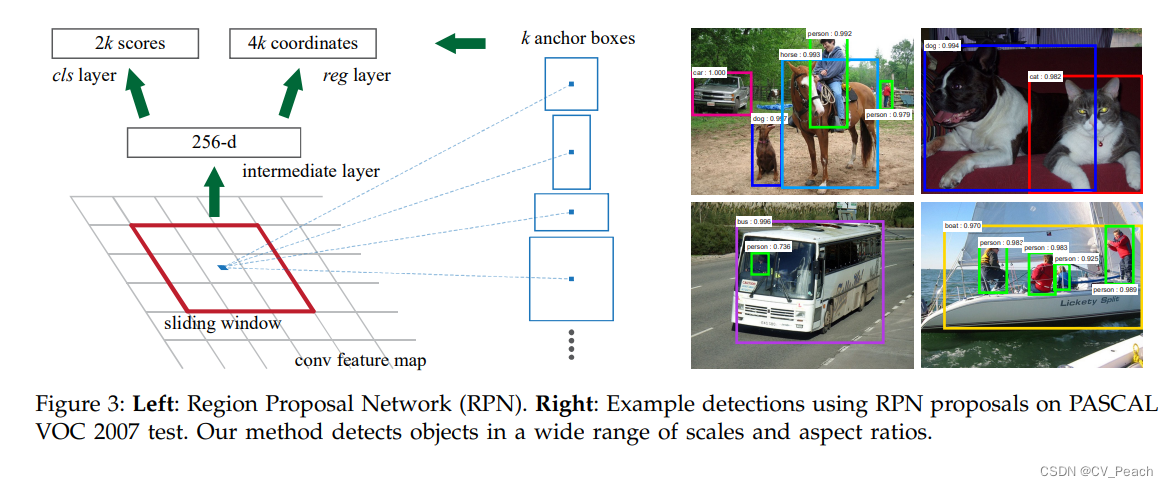
RPN:
候选区域生成网络,实现过程:
①输入特征层,输出2k scores和4k coordinates,分别对应anchor的类别(前景/背景)置信度和回归参数,其中k代表anchors的种类数(实际实现可以只生成k scores代表前景置信度);
②根据coordinates对全部anchors的位置和大小进行调整,得到初步的proposals;
③对得到的proposals进行条件筛选:
a.将proposals的范围限制在原图边界;
b.删除尺寸过小的proposals(尺寸阈值需要人为设定);
c.按照scores对proposals进行降序排列,取前n个保留,剩余删除(n需要人为设定,且在训练过程和验证过程中不同)(一般情况下,此前的proposals数量≥n,如不足n则全部保留);
d.对剩余proposals进行nms并按scores进行降序排列,取前m个保留,剩余删除(m需要人为设定,且在训练过程和验证过程中不同)(一般情况下,此前的proposals数量≥m,如不足则重复采样)。
注:为方便代码实现,以上筛选方法与原文描述有一些差异,但最终效果相差不大。
import torch
import torch.nn as nn
from torchvision.models import vgg16
from torchvision.ops import nms, RoIPool
from einops import rearrange
class AnchorGenerator(nn.Module): # Anchor相关方法
def __init__(
self,
anchor_scales=(128, 256, 512), # anchor的面积(开根号)
anchor_ratios=(0.5, 1., 2.) # anchor的高宽比(H:W)
):
super(AnchorGenerator, self).__init__()
self.anchor_scales = torch.as_tensor(anchor_scales).unsqueeze(0)
self.anchor_ratios = torch.as_tensor(anchor_ratios).unsqueeze(1)
self.anchor_base = self.generate_anchor_base() # 生成基础anchor
def generate_anchor_base(self):
'''
生成基础anchor方法
:return: anchor_base: tensor(k,4)
其中,k是anchor尺寸类别数量,对应3x3共9种anchor;4代表以anchor中心点为原点的位置(尺寸)坐标(xmin,ymin,xmax,ymax)
'''
h_ratios = torch.sqrt(self.anchor_ratios)
w_ratios = 1. / h_ratios
h = (self.anchor_scales * h_ratios).view(-1, 1)
w = (self.anchor_scales * w_ratios).view(-1, 1)
return torch.cat((-w / 2, -h / 2, w / 2, h / 2), dim=1)
def generate_all_anchors(self, step, feature_size):
'''
生成全部anchor方法
:param step: 步距,原图高(宽)/特征层高(宽),即特征层上的一像素在原图上代表的像素长度
:param feature_size: 特征层尺寸(H,W)
:return: anchors: (N,4),将特征层上的所有像素点(特征点),对应在原图上生成的anchors,N = HxWxk
'''
feature_h, feature_w = feature_size
x, y = torch.meshgrid(torch.arange(0, step * feature_w, step), torch.arange(0, step * feature_h, step))
x = torch.flatten(x)
y = torch.flatten(y)
shift = torch.stack((x, y, x, y), dim=1)
anchors = (shift.unsqueeze(0) + self.anchor_base.unsqueeze(1)).view(-1, 4)
return anchors
class ProposalGenerator(nn.Module): # Proposal相关方法
def __init__(
self,
train=True, # 是否为训练状态
nms_iou_th=0.7, # nms的iou阈值
n_train_pre_nms=10000, # 训练时,在nms之前保留的proposals数量
n_train_post_nms=2000, # 训练时,在nms之后保留的proposals数量
n_test_pre_nms=5000, # 验证时,在nms之前保留的proposals数量
n_test_post_nms=1000, # 验证时,在nms之后保留的proposals数量
min_size=20 # proposals的最小尺寸(H/W)
):
super(ProposalGenerator, self).__init__()
self.train = train
self.nms_iou_th = nms_iou_th
if self.train:
self.n_pre_nms = n_train_pre_nms
self.n_post_nms = n_train_post_nms
else:
self.n_pre_nms = n_test_pre_nms
self.n_post_nms = n_test_post_nms
self.min_size = min_size
def anchors2proposals(self, anchors, reg_coordinates):
'''
根据reg参数,将anchors转换为proposals方法
:param anchors: 全部anchors
:param reg_coordinates:RPN的输出reg_coordinates参数(dx,dy,dw,dh),用于将anchors调整为proposals
:return: proposals: (B,N,4)
其中,B代表batch size,N代表proposals个数(即anchors个数),4代表位置坐标(xmin,ymin,xmax,ymax)
'''
batch_size = reg_coordinates.shape[0]
anchors = torch.repeat_interleave(anchors.unsqueeze(0), batch_size, dim=0)
xmin, ymin, xmax, ymax = map(lambda t: anchors[:, :, t::4], [0, 1, 2, 3])
x = (xmin + xmax) / 2
y = (ymin + ymax) / 2
w = xmax - xmin
h = ymax - ymin
dx, dy, dw, dh = map(lambda t: reg_coordinates[:, :, t::4], [0, 1, 2, 3])
reg_x = x + dx * x # x' = x + x * dx
reg_y = y + dy * y # y' = y + y * dx
reg_w = torch.exp(dw) * w # w' = w * exp(dw)
reg_h = torch.exp(dh) * h # h' = h * exp(dh)
proposals = torch.cat((reg_x - reg_w / 2, reg_y - reg_h / 2, reg_x + reg_w / 2, reg_y + reg_h / 2), dim=-1)
return proposals
def generate_proposals(self, anchors, cls_scores, reg_coordinates, image_size):
'''
生成RPN最终输出的proposals(rois)
:param anchors: 全部anchors
:param cls_scores: RPN的输出cls_scores,代表每个anchor为前景(目标)的置信度
:param reg_coordinates:RPN的输出reg_coordinates,代表每个anchor的中心坐标和宽高调整参数
:param image_size:输入图像(原图)尺寸
:return:rois (B, n_post_nms, 4)
'''
proposals = self.anchors2proposals(anchors, reg_coordinates) # 根据reg_coordinates将anchors调整为proposals
proposals[:, :, [0, 2]] = torch.clamp(proposals[:, :, [0, 2]],
min=0, max=image_size[1]) # 限制proposals宽度方向超过原图边界
proposals[:, :, [1, 3]] = torch.clamp(proposals[:, :, [1, 3]],
min=0, max=image_size[0]) # 限制proposals高度方向超过原图边界
batch_size = proposals.shape[0]
roi_list = []
for i in range(batch_size): # 对batch进行循环
roi = proposals[i] # batch中每张图像的roi(proposals)
cls_score = cls_scores[i] # batch中每张图像的cls_scores
# 删除宽/高小于min_size的roi
keep = torch.where(((roi[:, 2] - roi[:, 0]) >= self.min_size) & ((roi[:, 3] - roi[:, 1]) >= self.min_size))[
0]
roi = roi[keep, :]
cls_score = cls_score[keep]
# 根据置信度进行排序,选择前n_pre_nms个roi
# 一般情况下,此时roi的数量≥n_pre_nms,如不足则全部保留
keep = torch.argsort(cls_score, descending=True)[:self.n_pre_nms]
roi = roi[keep, :]
cls_score = cls_score[keep]
# 对剩下的roi进行nms处理,再选择前n_post_nms个roi
# 一般情况下,此时roi的数量≥n_post_nms,如不足则重复采样
keep = nms(roi, cls_score, self.nms_iou_th)
if len(keep) < self.n_post_nms:
rand_index = torch.randint(0, len(keep), size=(self.n_post_nms - len(keep),))
keep = torch.cat([keep, keep[rand_index]], dim=0)
keep = keep[:self.n_post_nms]
roi = roi[keep, :]
roi_list.append(roi)
rois = torch.stack(roi_list, dim=0)
return rois
class RegionProposalNetwork(nn.Module): # RPN
def __init__(self, channels, step, image_size,cuda=True):
super(RegionProposalNetwork, self).__init__()
self.step = step # 步距,原图高(宽)/特征层高(宽),即特征层上的一像素在原图上代表的像素长度
self.image_size = image_size # 输入图像(原图)尺寸
self.anchorgenerator = AnchorGenerator() # 实例化AnchorGenerator
self.proposalgenerator = ProposalGenerator() # 实例化ProposalGenerator
self.anchor_base = self.anchorgenerator.anchor_base
k = self.anchor_base.shape[0]
self.conv = nn.Conv2d(channels, channels, 3, 1, 1) # RPN的特征整合
self.conv_cls = nn.Conv2d(channels, k, 1, 1, 0) # RPN的cls层,生成k scores **原论文此处生成2k并进行softmax**
self.conv_reg = nn.Conv2d(channels, k * 4, 1, 1, 0) # RPN的reg层,生成4k coordinates
self.relu = nn.ReLU(inplace=True)
self.sigmoid = nn.Sigmoid()
def forward(self, features):
'''
前向传播
:param features: 图像经过backbone提取到的feature map(特征层)
:return:
cls_scores: 全部anchors的前景置信度,此处返回用于RPN的loss计算
reg_coordinates: 全部anchors的中心点和宽高回归参数,此处返回用于RPN的loss计算
anchors: 全部anchors
rois: 最终输出的roi,与features一起输入head网络
'''
x = self.relu(self.conv(features)) # (N,C,H,W) -> (N,C,H,W)
cls_scores = self.sigmoid(self.conv_cls(x)) # (N,C,H,W) -> (N,k,H,W)
cls_scores = rearrange(cls_scores, "N K H W -> N (K H W)")
reg_coordinates = self.conv_reg(x) # (N,C,H,W) -> (N,4k,H,W)
reg_coordinates = rearrange(reg_coordinates, "N (a K) H W -> N (K H W) a", a=4)
anchors = self.anchorgenerator.generate_all_anchors(self.step, features.shape[2:])
if self.cuda:
anchors = anchors.cuda()
rois = self.proposalgenerator.generate_proposals(anchors, cls_scores, reg_coordinates, self.image_size)
return cls_scores, reg_coordinates, anchors, rois
class Head(nn.Module): # Head
def __init__(
self,
num_classes, # 检测类别数,包含背景(实际检测类别数+1)
channels, # 特征层通道数
step, # 步距,原图高(宽)/特征层高(宽),即特征层上的一像素在原图上代表的像素长度
roi_size=7 # roi pooling的输出尺寸
):
super(Head, self).__init__()
self.num_classes = num_classes
self.step = step
self.classifier = nn.Sequential(
nn.Linear(channels * roi_size ** 2, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 1024),
nn.ReLU(inplace=True)
)
self.cls = nn.Linear(1024, self.num_classes)
self.reg = nn.Linear(1024, self.num_classes * 4)
self.roipool = RoIPool((roi_size, roi_size), 1) # roi pooling
def forward(self, feature, rois):
'''
前向传播
:param feature: 图像经过backbone提取到的feature map(特征层)
:param roi_list: 特征层经过rpn得到的roi列表(候选框)
:return:
scores: 类别置信度,(B, n_post_nms, num_classes)
regs: 边界框回归参数,(B, n_post_nms, num_classes x 4)
'''
batch_size = feature.shape[0]
feature_rois = rois / self.step # 将原图上的roi转换为特征层上的roi(尺寸变换)
feature_rois_list = [feature_rois[i, :, :] for i in range(batch_size)]
rois = self.roipool(feature, feature_rois_list) # (N,C,7,7) N代表roi的总个数,N = batch size x n_post_nms
rois = rearrange(rois, "N C H W -> N (C H W)")
out = self.classifier(rois)
scores = self.cls(out).view(batch_size, -1, self.num_classes)
regs = self.reg(out).view(batch_size, -1, self.num_classes * 4)
return scores, regs
class FasterRCNN(nn.Module): # FasterRCNN
def __init__(self, backbone, rpn, head):
super(FasterRCNN, self).__init__()
self.backbone = backbone
self.rpn = rpn
self.head = head
def forward(self, x):
'''
前向传播
:param x:输入图像(训练/验证/测试图像)
:return:
rpn_scores: rpn输出的每个anchor前景置信度
rpn_regs: rpn输出的每个anchr回归参数
anchors: rpn输出的全部anchors
rois: rpn输出的rois
head_scores: head输出的每个roi类别置信度
head_regs: head输出的每个roi回归参数
'''
feature = self.backbone(x)
rpn_scores, rpn_regs, anchors, rois = self.rpn(feature)
head_scores, head_regs = self.head(feature, rois)
return rpn_scores, rpn_regs, anchors, rois, head_scores, head_regs
if __name__ == "__main__":
cuda = True
backbone = vgg16().features # 选用vgg16的features部分作为FasterRCNN的backbone
batch_size = 8
feature_channels = 512 # vgg16输出的特征层通道数
step = 32 # vgg16输出的特征层与输入图像的步距关系
num_classes = 20 # 目标类别数量(不包括背景)
image_size = (800, 1300) # 输入图像尺寸
rpn = RegionProposalNetwork(feature_channels, step, image_size, cuda=cuda) # 构建rpn
head = Head(num_classes + 1, feature_channels, step) # 构建head
fasterrcnn = FasterRCNN(backbone, rpn, head) # 构建FasterRCNN
data = torch.randn(batch_size, 3, 800, 1300) # 模拟网络输入
if cuda:
data = data.cuda()
fasterrcnn.cuda()
rpn_scores, rpn_regs, anchors, rois, head_scores, head_regs = fasterrcnn(data)
# torch.Size([8, 9000])
# torch.Size([8, 9000, 4])
# torch.Size([9000, 4])
# torch.Size([8, 2000, 4])
# torch.Size([8, 2000, 21])
# torch.Size([8, 2000, 84])
[print(i.shape) for i in [rpn_scores, rpn_regs, anchors, rois, head_scores, head_regs]]
最后
以上就是幸福树叶最近收集整理的关于FasterRCNN模型结构——pytorch实现的全部内容,更多相关FasterRCNN模型结构——pytorch实现内容请搜索靠谱客的其他文章。








发表评论 取消回复