一、语音识别方法(1)
1 语音识别原理
一段语音信号,在处理为声学特征向量后表示为:
X
=
[
x
1
,
x
2
,
x
3
,
.
.
.
]
X=[x_1, x_2, x_3,...]
X=[x1,x2,x3,...]
其中,
x
i
x_i
xi 表示一个音频帧(Frame)的特征向量。而对应的候选文本序列则表示为:
W
=
[
w
1
,
w
2
,
w
3
,
.
.
.
]
W=[w_1,w_2,w_3,...]
W=[w1,w2,w3,...]
其中
w
i
w_i
wi 表示一个词向量。
语音识别的基本出发点在于,根据给定输入声学特征向量,求得最可能的文本序列,即概率
P
(
W
∣
X
)
P(W|X)
P(W∣X) 最大时的文本序列
W
∗
W^*
W∗,表示为:
W
∗
=
a
r
g
m
a
x
W
P
(
W
∣
X
)
W^* = argmax_W P(W|X)
W∗=argmaxW P(W∣X)
根据贝叶斯公式,传统语音识别任务将后验概率1分解为先验概率2
P
(
W
)
P(W)
P(W)和似然概率3
P
(
X
∣
W
)
P(X|W)
P(X∣W) ,即:
P
(
W
∣
X
)
=
P
(
X
∣
W
)
P
(
W
)
P
(
X
)
∝
P
(
X
∣
W
)
P
(
W
)
begin{aligned} P(W|X) = frac {P(X|W)P(W)}{P(X)} \ propto P(X|W)P(W) end{aligned}
P(W∣X)=P(X)P(X∣W)P(W)∝P(X∣W)P(W)
其中
P
(
X
∣
W
)
P(X|W)
P(X∣W) 为声学模型,即给定文本序列
W
W
W 时产生的声学特征向量为
X
X
X 的概率;
P
(
W
)
P(W)
P(W) 为语言模型,负责计算文本序列在语料库中出现的概率。
P ( X ) P(X) P(X) 为待解码语音的概率,在实际应用中,对于不同候选文本其待解码语音的概率认为是一个不变的固定值,不含任何与语言相关的信息,因此可忽略不计。
早期语音识别工作大多将声学模型
P
(
X
∣
W
)
P(X|W)
P(X∣W) 与 语言模型
P
(
W
)
P(W)
P(W) 分开看待,通过不断改进声学模型来求取最优的文本序列
W
∗
W^*
W∗ 。
P
(
W
∣
X
)
↑
∝
P
(
X
∣
W
)
↑
P
(
W
)
P(W|X) uparrow propto P(X|W) uparrow P(W)
P(W∣X)↑ ∝ P(X∣W)↑P(W)
在深度学习技术出现后,基于深度学习和大数据的端到端模型,可以直接计算后验概率
P
(
W
∣
X
)
P(W|X)
P(W∣X),实现声学模型和语言模型的融合。
2 总体思路与实现方法
明确了语音识别任务原理后,实现该任务的关键在于实现输入语音与候选文本序列的对齐。但由于存在外界因素的干扰,语音与文本序列之间存在多对一而非一对一的映射关系,因此在早期研究中,直接构建一个通用函数,将多个同内容语音直接映射到同一个文本序列上是不现实的。
针对这一问题,后续研究人员的思路是分别找到语音和文本序列的基本组成单位,就像物质中的原子一般,二者的基本单位是精确、规整且可控的,基于这种基本单位的映射也会更简单、清晰些。
语音中选取的基本单位为帧(Frame),一帧就是一个语音向量,由声学特征提取模块产生,涉及离散傅里叶变换、梅尔滤波器组等技术。为了适应不同的文本单位,帧的跨度是可调的,但维度固定不变。
注:语音分帧的意义
在语音信号处理中,为了弄清语音中各频率成分的分布,常采用 傅里叶变换 进行处理。但傅里叶变换要求输入信号是一个平稳信号,而语音信号在宏观上是振荡的。但从微观来看,由于人口腔和喉部等发声器官在发声时运动速度没那么快,因此可以在一个较短时间内将其看作是平稳信号,从而截取出来进行傅里叶变换。而截取出的这一小段,就是一「帧」
宏观来看,口型变化是导致信号不稳定的重要因素,因此一帧期间口型不能有明显变化,即一帧长度应小于一个音素的长度,而音素持续时间为 50 ∼ 200 m s 50 sim 200ms 50∼200ms ,故帧长一般小于 50 m s 50ms 50ms。但从微观来看,一个帧又需要包含足够的振动周期,因为只有重复多次才能供傅里叶变换分析频率。对于语音来说,男声的基频在 100 h z 100hz 100hz 左右,女声在 200 h z 200hz 200hz 左右,换算成周期就是 10 m s 10ms 10ms 和 5 m s 5ms 5ms ,为了包含多个周期,因此一般取至少 20 m s 20ms 20ms。
综上,帧长一般取值为 20 ∼ 50 m s 20 sim 50ms 20∼50ms,常用值为20、25、30、40、50等。
在实现了语音与文本序列的对齐后,常见的语音识别基本途径有如下几种,分别是基于注意力机制、CTC以及DNN-HMM方法:
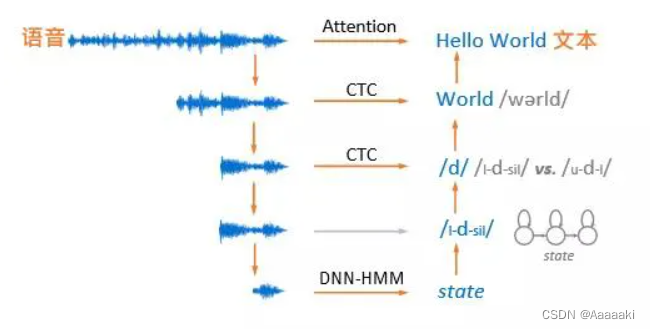
- 整段语音到整句文本序列的映射,通过基于注意力机制的端到端深度学习模型实现。
- 每个词或每个音素的发音范围到对应词和音标的映射,通过基于CTC损失函数的端到端结构实现。
- 三音素和隐马尔可夫模型状态,通过考虑上下文范围,将语音建模尺度由单个音素长度拓展为三音素发音范围,长度则保持与单音素相同。随后对每个三音素都采用一个三状态隐马尔可夫模型表示,以每个状态为建模粒度,使得对应的语音建模尺度进一步缩短。通过DNN-HMM(深度神经网络-隐马尔可夫)模型结构实现。
3 声学模型、解码器、语言模型的作用与关系
在实际语音识别系统中,声学模型、解码器以及语言模型等各模块间的关系如图所示:
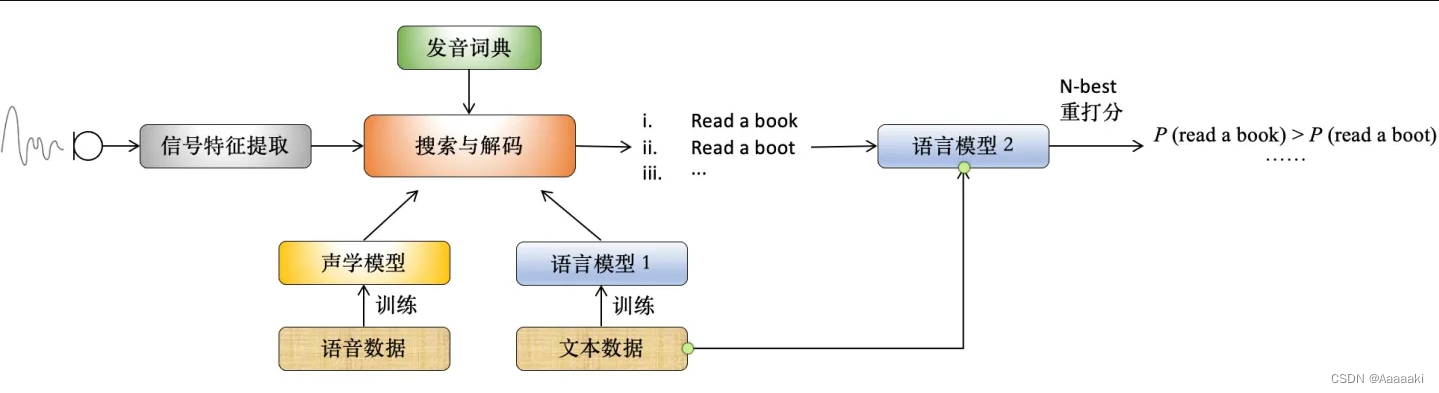
- 语音输入后,特征提取阶段对语音信号进行分帧、加窗等预处理,将其分为小段清晰片段,通过傅里叶变换提取特征,存为特征向量
- 特征向量通过隐马尔可夫模型、混合高斯模型等转化为发音最小单元,如音素特征。随后借助发音词典将特征映射为对应单词,将最终识别成果存在一张图中(词图)。同时引入n元语法模型作为先验,并将单词以及声学和语言模型的分数保存在图的路径上。
- 从词图上生成识别结果的过程就叫搜索与解码(decoding),即从在图上通过搜索算法找出最短的 n 条路径。保留最好的n个假设生成结果,通过第二个语言模型进行重打分,选取得分最高的作为最终结果。
(decoding),即从在图上通过搜索算法找出最短的 n 条路径。保留最好的n个假设生成结果,通过第二个语言模型进行重打分,选取得分最高的作为最终结果。
后验概率:考虑相关数据 X X X后所获得的条件概率,即一个未知随机变量 θ theta θ基于试验和调查后得到的概率分布 P ( θ ∣ X ) P(theta|X) P(θ∣X) ↩︎
先验概率:不依赖观测数据的概率分布,即与其他因素独立的分布 P ( θ ) P(theta) P(θ) ↩︎
似然概率:关于统计模型参数的函数,对于一组数据,需要构建一组参数对这些数据进行建模,在多组参数中选出令模型尽可能拟合这组数据的过程就是求最大似然概率 a r g m a x P ( X ∣ θ ) argmax P(X|theta) argmax P(X∣θ) 的过程。 ↩︎
最后
以上就是唠叨画板最近收集整理的关于一、语音识别方法(1)的全部内容,更多相关一、语音识别方法(1)内容请搜索靠谱客的其他文章。








发表评论 取消回复