目录
一、经典算法与阶段(Stage)
二、真实框(Ground Truth)、预测框(Prediction)与交并比(IoU)
三、精确率(Precision)与召回率(Recall)
四、置信度(Confidence)与置信度阈值(Confidence Threshold)
五、AP(Average Precision)、mAP(Mean Average Precision)、所有点插值法(Interpolation Performed in all Points)与AUC(Area Under Curve)
六、YOLO V1
七、非极大值抑制(Non-maximum Suppression)
八、YOLO V2
Reference Paper
一、经典算法与阶段(Stage)
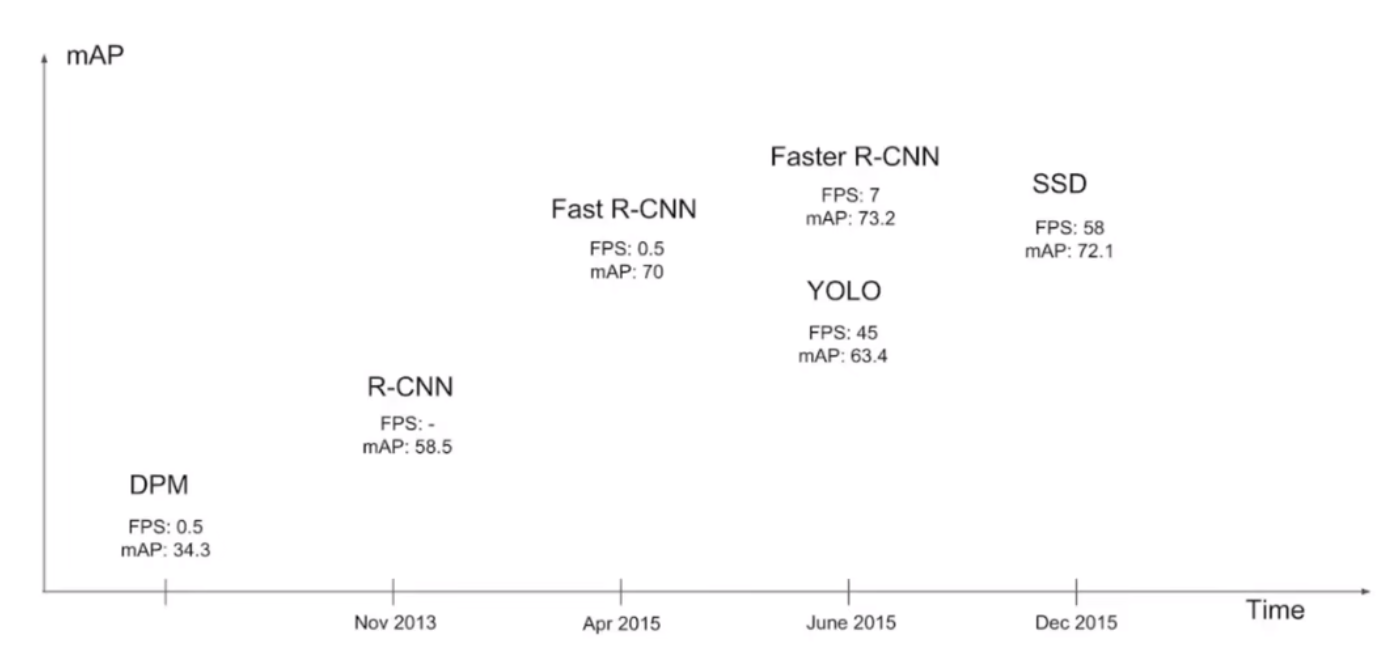
Two-stage(两阶段):Faster R-CNN Mask R-CNN
特点:速度相对较慢,效果好,不适合实时检测
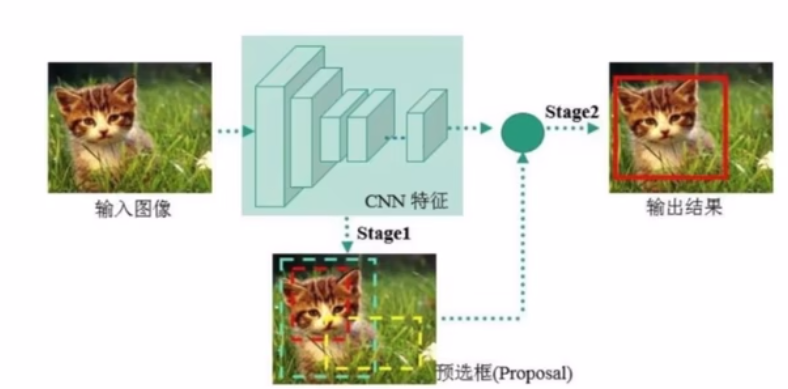
One-stage(单阶段):YOLO
特点:速度快,效果相对较差,适合实时检测
二、真实框(Ground Truth)、预测框(Prediction)与交并比(IoU)


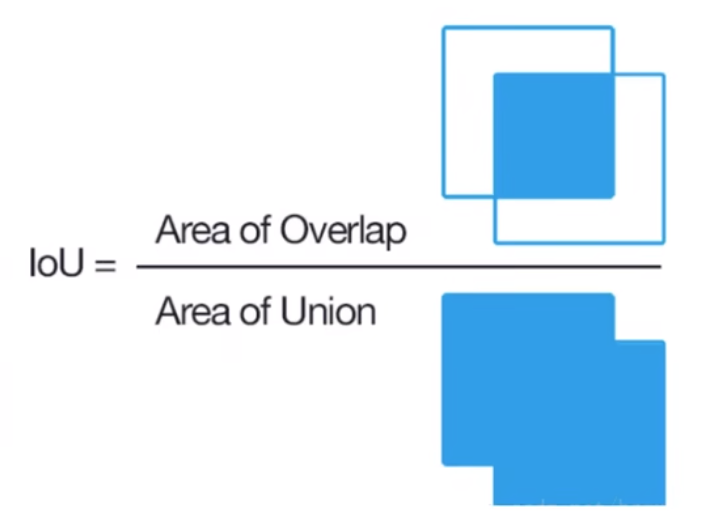
三、精确率(Precision)与召回率(Recall)

举例:在通用技术的尺寸标注中,既要保证精度(不要错标,多标),又要保证召回率(不要漏标)

四、置信度(Confidence)与置信度阈值(Confidence Threshold)
置信度>置信度阈值,则标记为正样本;反之,则标记为负样本
置信度阈值越高,召回率越低,精确率越高;置信度阈值越低,召回率越高,精确率越低
五、AP(Average Precision)、mAP(Mean Average Precision)、所有点插值法(Interpolation Performed in all Points)与AUC(Area Under Curve)
调整置信度阈值,画出所有点插值法的P-R图(含红色虚线),如左下图
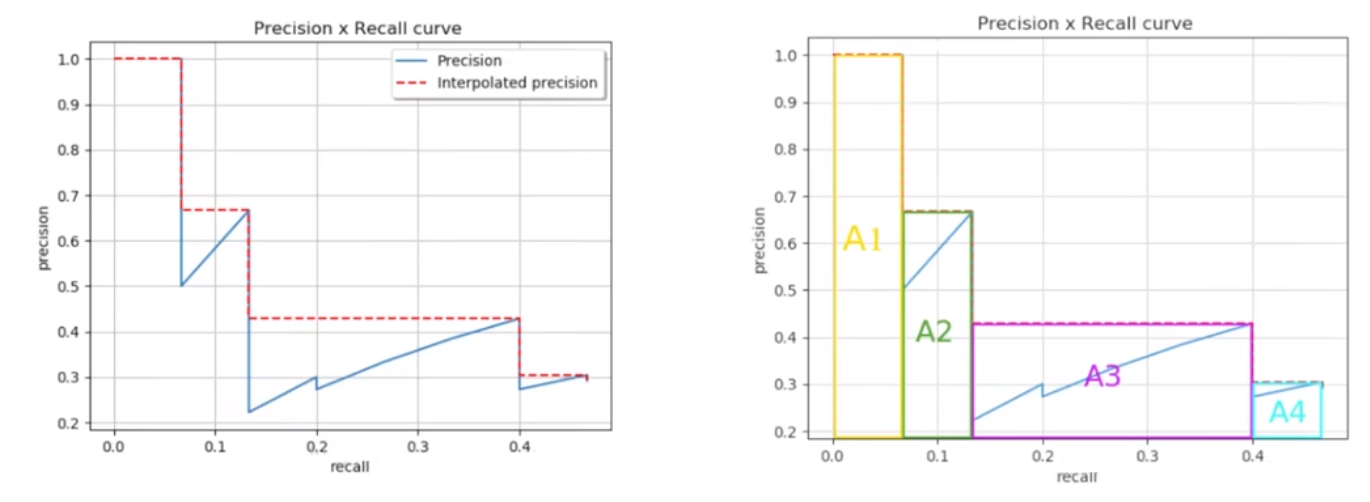
AP计算方式:AUC,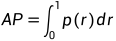
如右上图,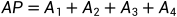
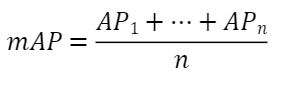
六、YOLO V1
网络架构
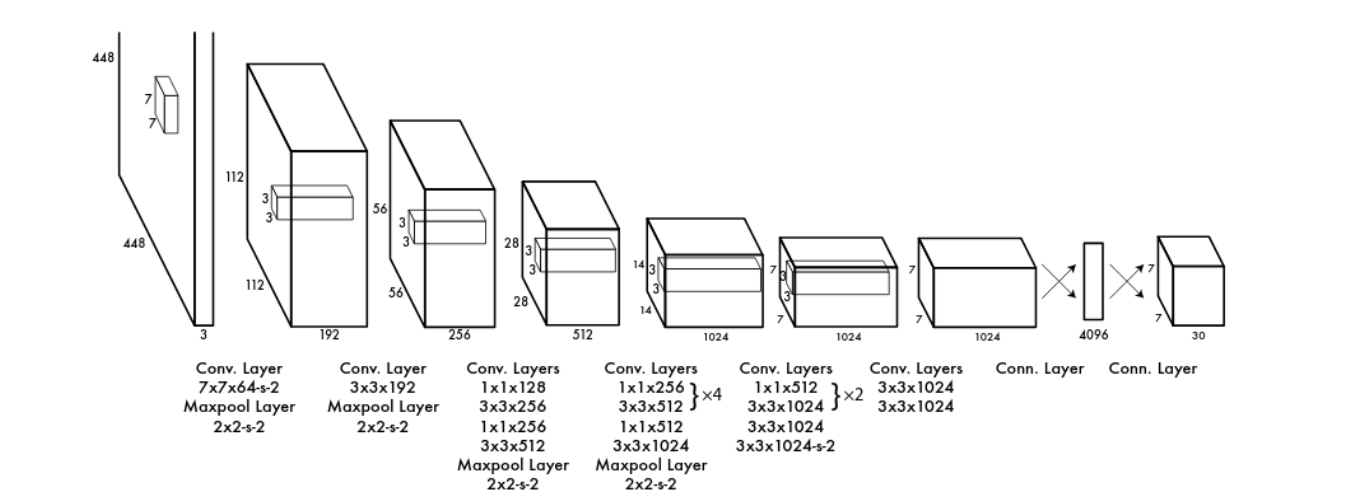
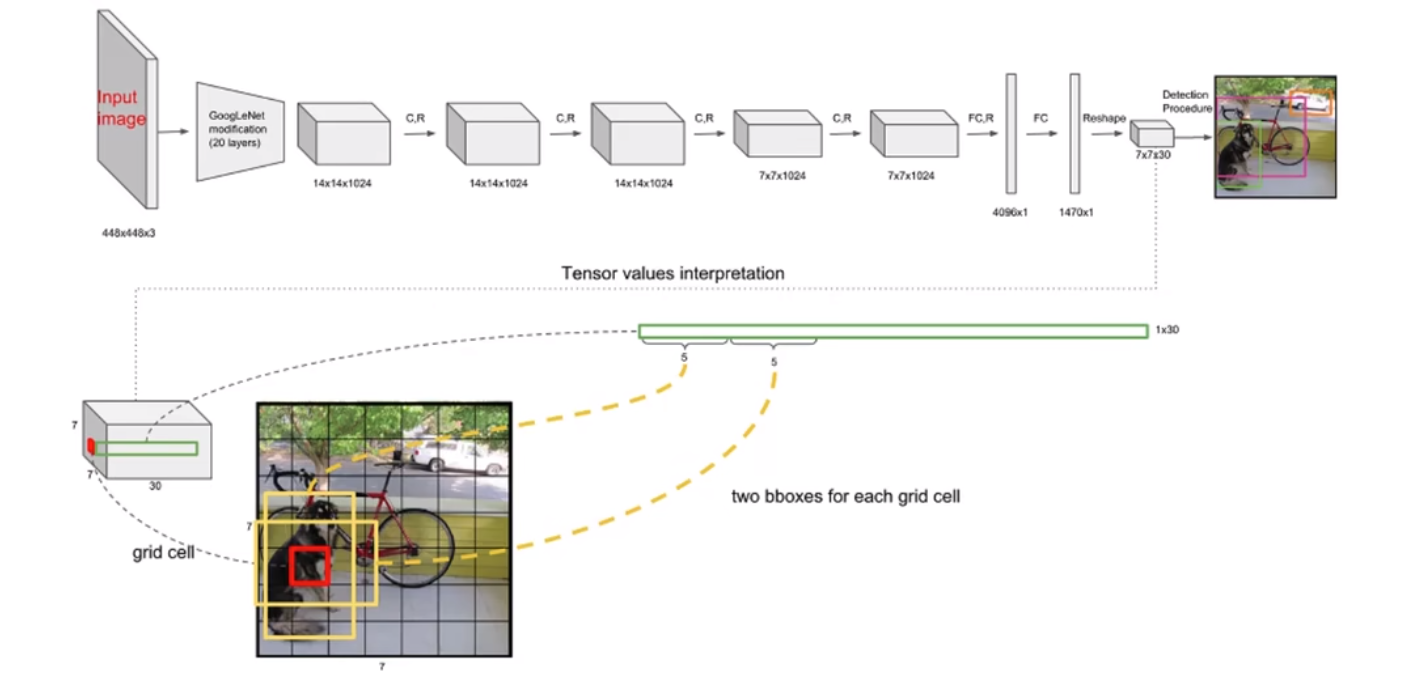
输入图像448x448x3:C3,H448,W448
输出数据7x7x30(5x2(2为每个网格单元含有的边界框数量)+20):GridX(1~7),GridY(1~7),(x1(0~1),y1(0~1),w1,h1,Confidence1,x2(0~1),y2(0~1),w2,h2,Confidence2,p(1),p(2),···,p(n=20)(n为数据集分类数量))
输出数据量计算公式(SxS:网格单元数量,B:每个网格单元含有的边界框数量,5:归一化后的每个网格单元内的边界框横、纵坐标+边界框宽度、高度+边界框置信度,C:数据集分类数量):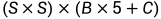
损失函数
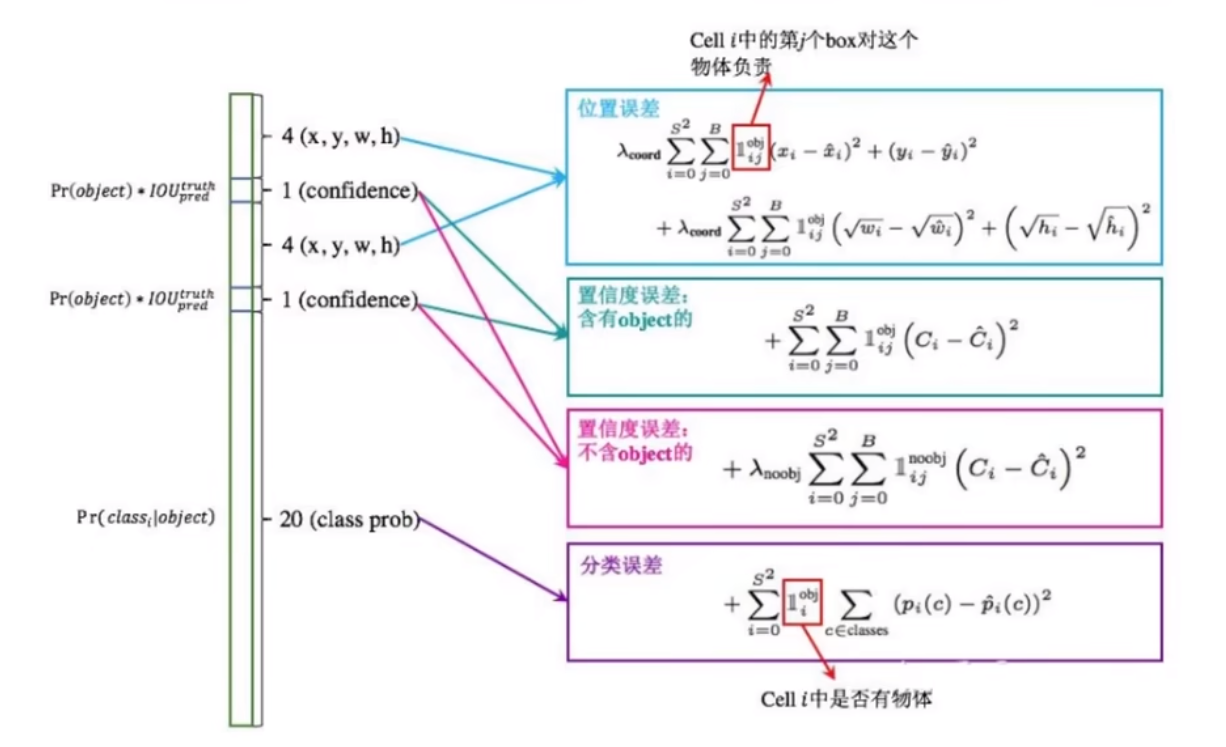
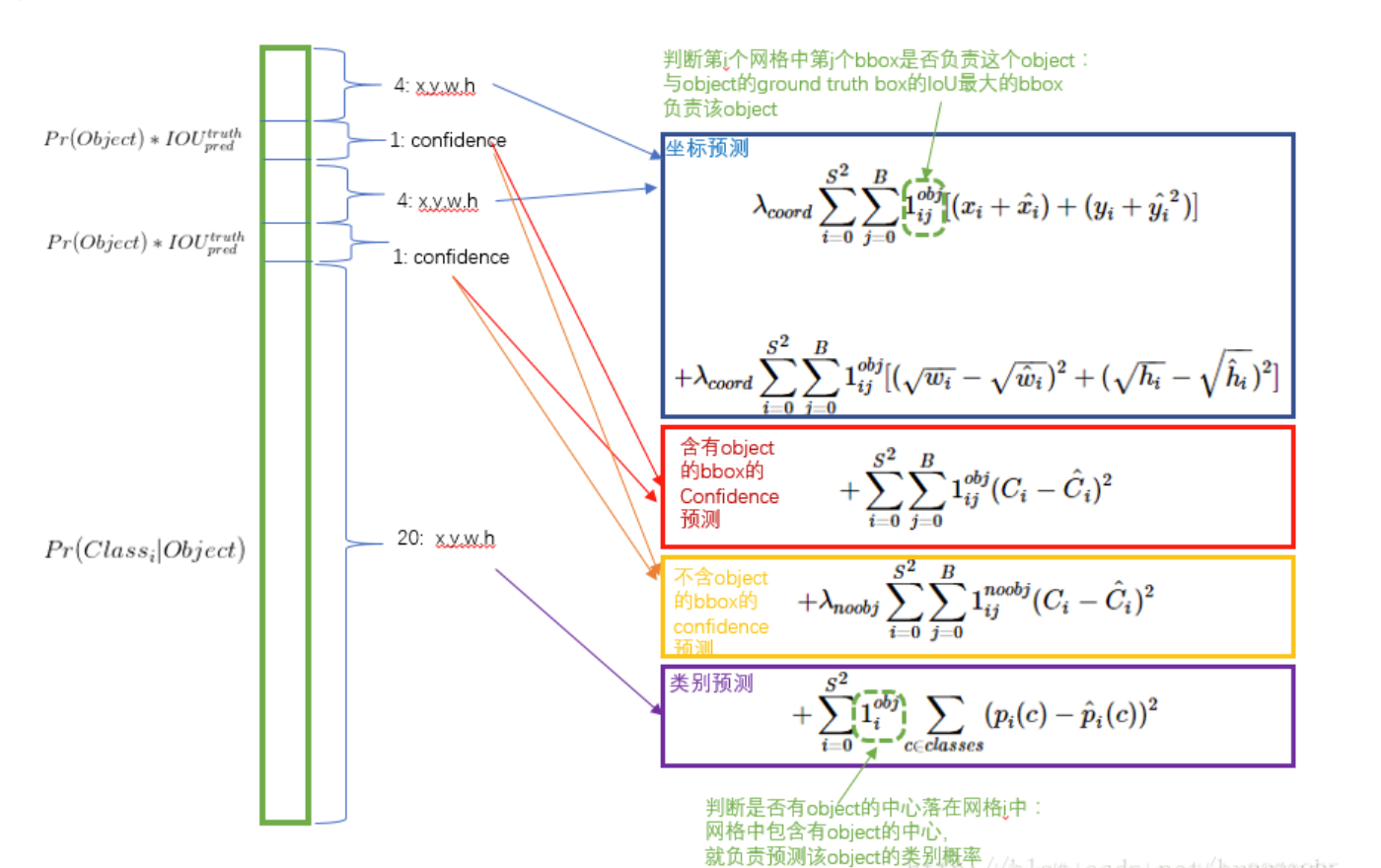
位置误差



置信度误差
Lamda(noobj)=0.5:由于背景在图像中占比较大,故减小负样本(背景)影响,使正样本易于检测

分类误差
MSE(均方差)与CEE(交叉熵):MSE适用于线性回归预测数值,即回归问题模型;CEE适用于逻辑回归测概率,即分类问题模型
此处应选择交叉熵作为损失函数
评价
优点:简单快速
缺点:每个grid cell仅预测一个类,多类重叠问题无法解决;小目标检测效果一般;当同一类出现的不常见的长宽比和其他情况时泛化能力偏弱
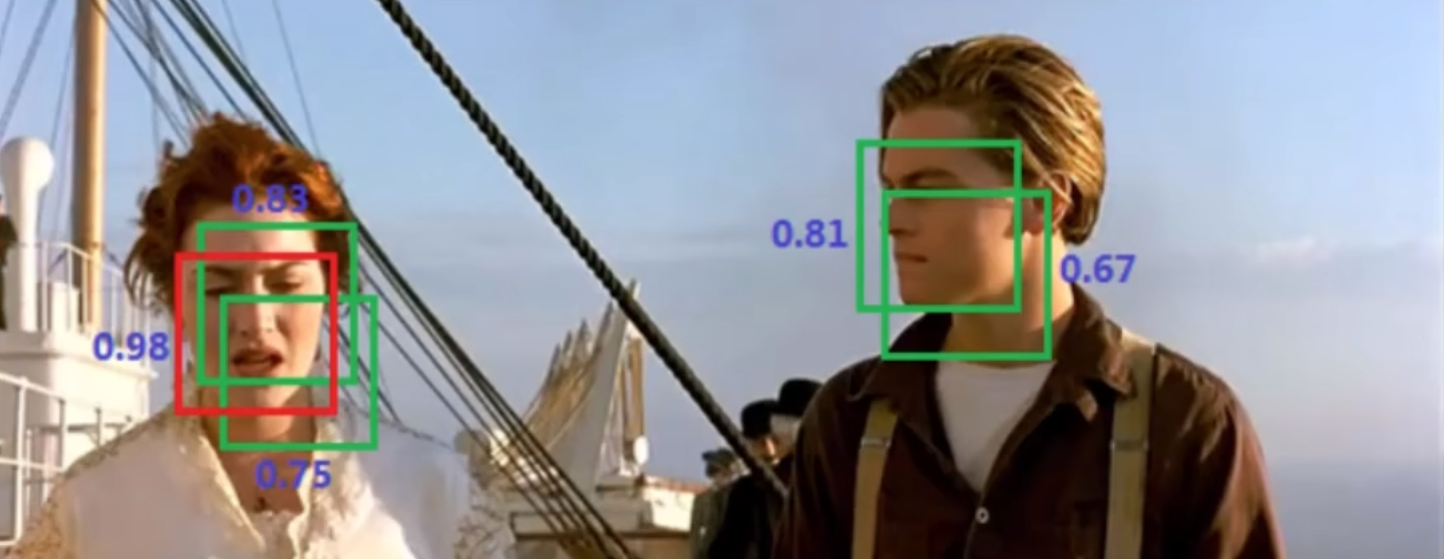
七、非极大值抑制(Non-maximum Suppression)

八、YOLO V2
提升概览

加入批归一化

提高分辨率

输入大小
V2为什么可以使用不同大小的输入:去掉了全连接层,解放了大小限制
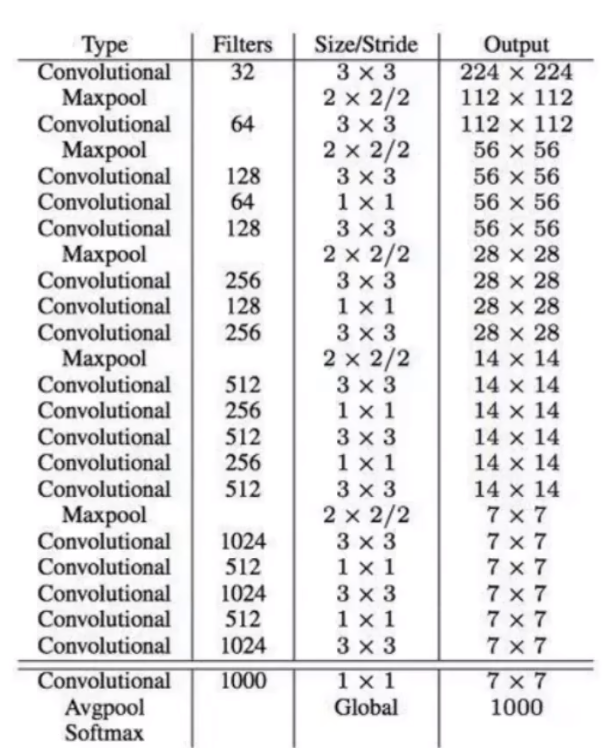
网络结构

输入大小
为什么实际输入为416*416而不是448*448:416=13*32,我们期望输入大小(416)为13的奇数倍,使数据具有实际中心点
为什么网格单元数量由V1的7*7变为13*13:每个网格单元box数量有限,增加了网格单元数量从而增加了box数量
Darkent类型:Darknet-19,含有19个卷积层
3x3卷积:参考了VGG,参数较少,感受野较大
1x1卷积:效果与3x3相近,但节省了大量参数(偷工减料)
聚类提取先验框
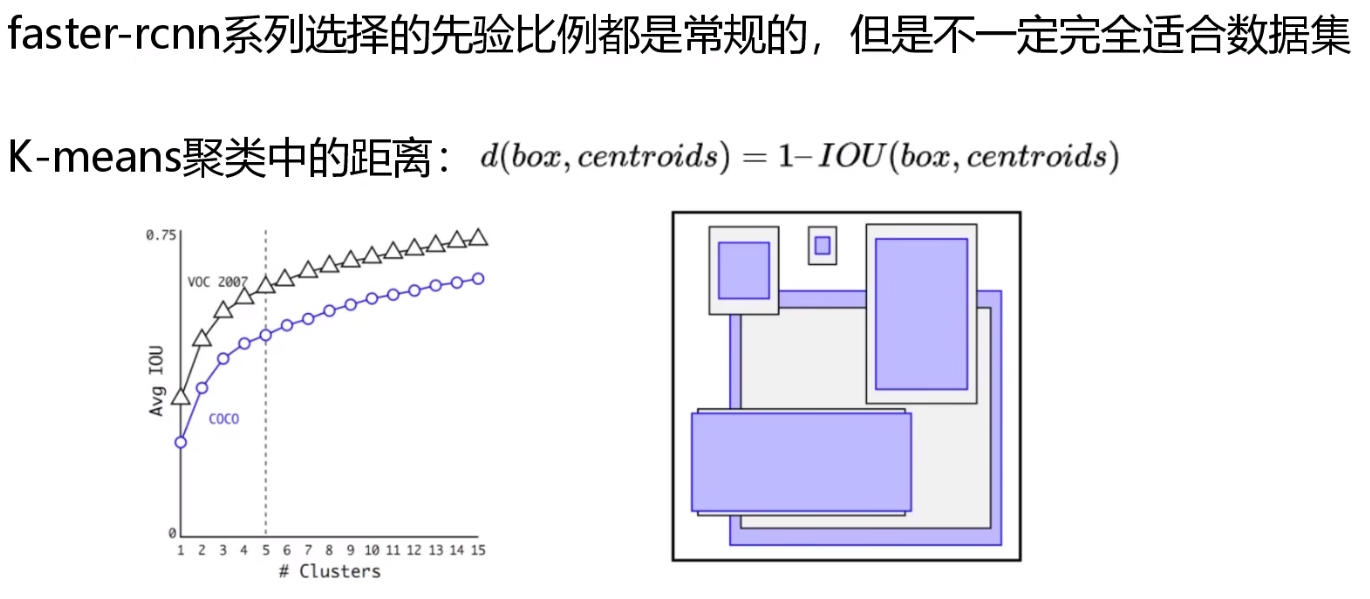
先验框比例
如何确定先验框比例:利用数据集的标注信息,采用K-means划分先验框比例,k=5即分为五类
为什么k=5:Avg IOU较大,Clusters较小
距离的定义
为什么不用欧氏距离:防止误差随先验框大小变化而产生明显变化
Reference Paper:You Only Look Once: Unified, Real-Time Object Detection








最后
以上就是整齐月饼最近收集整理的关于[Pytorch]YOLO目标检测目录一、经典算法与阶段(Stage)二、真实框(Ground Truth)、预测框(Prediction)与交并比(IoU)三、精确率(Precision)与召回率(Recall)四、置信度(Confidence)与置信度阈值(Confidence Threshold)五、AP(Average Precision)、mAP(Mean Average Precision)、所有点插值法(Interpolation Performed in all Points)与的全部内容,更多相关[Pytorch]YOLO目标检测目录一、经典算法与阶段(Stage)二、真实框(Ground内容请搜索靠谱客的其他文章。




![[Pytorch]YOLO目标检测目录一、经典算法与阶段(Stage)二、真实框(Ground Truth)、预测框(Prediction)与交并比(IoU)三、精确率(Precision)与召回率(Recall)四、置信度(Confidence)与置信度阈值(Confidence Threshold)五、AP(Average Precision)、mAP(Mean Average Precision)、所有点插值法(Interpolation Performed in all Points)与](https://www.shuijiaxian.com/files_image/reation/bcimg5.png)



发表评论 取消回复