为了避免重复造轮子,关于Yolo v3模型的原理就不多说了,下面主要是分析下Yolo v3在Tensorflow2.0版本里面是如何具体实现的,首先我们来分析下模型构建的主代码,这里非常感谢github 上的yunyang1994关于该代码的分享,我在这里只是对于他的代码进行了一个解读,来了解下Yolo v3在工程实现上的一些小细节,以提高自己对Tensorflow 2.0版本语法的掌握水平。
下面代码引入了common,backbone,utils和config文件的函数,对于cutils和config在Tensorflow2.0:Yolo v3代码详解(三)中,对于common和backbone则在第二部分和第三部分给出,下面给出第一部分
第一部分 针对Yolo v3文件代码解析
import numpy as np
import tensorflow as tf
import core.utils as utils
import core.common as common
import core.backbone as backbone
from core.config import cfg
NUM_CLASS = len(utils.read_class_names(cfg.YOLO.CLASSES))
ANCHORS = utils.get_anchors(cfg.YOLO.ANCHORS)
STRIDES = np.array(cfg.YOLO.STRIDES)
IOU_LOSS_THRESH = cfg.YOLO.IOU_LOSS_THRESH # IoU阈值为0.5
进入正题,总的来说,分为五个步骤,其中比较关键的是如何计算Yolo v3的loss,这个loss我是查了很多资料才搞明白的,因为该loss和v1和v2并不完全一致,网上 很多地方并没有写清楚,关于loss的计算下次说。
# 1.模型计算与输出,输出为[conv_sbbox, conv_mbbox, conv_lbbox]
def YOLOv3(input_layer):
route_1, route_2, conv = backbone.darknet53(input_layer)
conv = common.convolutional(conv, (1, 1, 1024, 512))
conv = common.convolutional(conv, (3, 3, 512, 1024))
conv = common.convolutional(conv, (1, 1, 1024, 512))
conv = common.convolutional(conv, (3, 3, 512, 1024))
conv = common.convolutional(conv, (1, 1, 1024, 512))
conv_lobj_branch = common.convolutional(conv, (3, 3, 512, 1024))
# 第一个输出 最后输出是不加激活也不加BN层
conv_lbbox = common.convolutional(conv_lobj_branch, (1, 1, 1024, 3*(NUM_CLASS + 5)), activate=False, bn=False)
conv = common.convolutional(conv, (1, 1, 512, 256))
conv = common.upsample(conv)
# 在通道维度上拼接
conv = tf.concat([conv, route_2], axis=-1)
conv = common.convolutional(conv, (1, 1, 768, 256))
conv = common.convolutional(conv, (3, 3, 256, 512))
conv = common.convolutional(conv, (1, 1, 512, 256))
conv = common.convolutional(conv, (3, 3, 256, 512))
conv = common.convolutional(conv, (1, 1, 512, 256))
conv_mobj_branch = common.convolutional(conv, (3, 3, 256, 512))
conv_mbbox = common.convolutional(conv_mobj_branch, (1, 1, 512, 3*(NUM_CLASS + 5)), activate=False, bn=False)
conv = common.convolutional(conv, (1, 1, 256, 128))
conv = common.upsample(conv)
conv = tf.concat([conv, route_1], axis=-1)
conv = common.convolutional(conv, (1, 1, 384, 128))
conv = common.convolutional(conv, (3, 3, 128, 256))
conv = common.convolutional(conv, (1, 1, 256, 128))
conv = common.convolutional(conv, (3, 3, 128, 256))
conv = common.convolutional(conv, (1, 1, 256, 128))
conv_sobj_branch = common.convolutional(conv, (3, 3, 128, 256))
conv_sbbox = common.convolutional(conv_sobj_branch, (1, 1, 256, 3*(NUM_CLASS +5)), activate=False, bn=False)
return [conv_sbbox, conv_mbbox, conv_lbbox]
# 2. 对模型输出的数据进行预处理
def decode(conv_output, i=0):
"""
return tensor of shape [batch_size, output_size, output_size, anchor_per_scale, 5 + num_classes]
contains (x, y, w, h, score, probability)
"""
conv_shape = tf.shape(conv_output)
batch_size = conv_shape[0] # 样本数
output_size = conv_shape[1] # 输出矩阵大小
conv_output = tf.reshape(conv_output, (batch_size, output_size, output_size, 3, 5 + NUM_CLASS))
conv_raw_dxdy = conv_output[:, :, :, :, 0:2] # xy
conv_raw_dwdh = conv_output[:, :, :, :, 2:4] # wh
conv_raw_conf = conv_output[:, :, :, :, 4:5] # score
conv_raw_prob = conv_output[:, :, :, :, 5:] # 类别class 80个
# 1.对每个anchor生成相对坐标,以左上角为基准,其坐标单位为cell,即数值表示第几个cell
# 方法:tf.tile 复制指定维度,数字表示以指定维度下所有元素来进行该数值的倍数复制
# [:, tf.newaxis]在最后一个维度增加一个维度;[tf.newaxis, :]在第一个维度增加一个维度
y = tf.tile(tf.range(output_size, dtype=tf.int32)[:, tf.newaxis], [1, output_size])
x = tf.tile(tf.range(output_size, dtype=tf.int32)[tf.newaxis, :], [output_size, 1])
# 技巧:tf.tile与[:, tf.newaxis]的搭配使用 # shape=(1, 13, 13, 1, 2)变shape=(batch_size, 13, 13, 3, 2)
xy_grid = tf.concat([x[:, :, tf.newaxis], y[:, :, tf.newaxis]], axis=-1) # shape=(13, 13, 2)
xy_grid = tf.tile(xy_grid[tf.newaxis, :, :, tf.newaxis, :], [batch_size, 1, 1, 3, 1])
xy_grid = tf.cast(xy_grid, tf.float32)
# 2,计算预测框的绝对坐标以及宽高度
pred_xy = (tf.sigmoid(conv_raw_dxdy) + xy_grid) * STRIDES[i] # xy_grid表示左上角的位置,即是第几行第几个格子,STRIDES表示格子的长度
pred_wh = (tf.exp(conv_raw_dwdh) * ANCHORS[i]) * STRIDES[i] # ANCHORS[i]) * STRIDES[i]表示先验框的大小即为pw和ph
pred_xywh = tf.concat([pred_xy, pred_wh], axis=-1)
# 3. 计算预测框的置信值和分类值
# 方法:sigmoid处理
pred_conf = tf.sigmoid(conv_raw_conf)
pred_prob = tf.sigmoid(conv_raw_prob)
return tf.concat([pred_xywh, pred_conf, pred_prob], axis=-1)
# 3. 计算IoU
def bbox_iou(boxes1, boxes2):
boxes1_area = boxes1[..., 2] * boxes1[..., 3]
boxes2_area = boxes2[..., 2] * boxes2[..., 3]
boxes1 = tf.concat([boxes1[..., :2] - boxes1[..., 2:] * 0.5,
boxes1[..., :2] + boxes1[..., 2:] * 0.5], axis=-1)
boxes2 = tf.concat([boxes2[..., :2] - boxes2[..., 2:] * 0.5,
boxes2[..., :2] + boxes2[..., 2:] * 0.5], axis=-1)
left_up = tf.maximum(boxes1[..., :2], boxes2[..., :2])
right_down = tf.minimum(boxes1[..., 2:], boxes2[..., 2:])
inter_section = tf.maximum(right_down - left_up, 0.0)
inter_area = inter_section[..., 0] * inter_section[..., 1]
union_area = boxes1_area + boxes2_area - inter_area
return 1.0 * inter_area / union_area
# 4. 计算误差GlOU
# 输入:pred_xywh = [:, :, :, :, 0:4] # 模型输出处理后的位置
# 输出:giou = [:, :, :, :, 1] # [batch_size, output_size, output_size, anchor_per_scale, gious]
def bbox_giou(boxes1, boxes2):
boxes1 = tf.concat([boxes1[..., :2] - boxes1[..., 2:] * 0.5,
boxes1[..., :2] + boxes1[..., 2:] * 0.5], axis=-1)
boxes2 = tf.concat([boxes2[..., :2] - boxes2[..., 2:] * 0.5,
boxes2[..., :2] + boxes2[..., 2:] * 0.5], axis=-1)
boxes1 = tf.concat([tf.minimum(boxes1[..., :2], boxes1[..., 2:]),
tf.maximum(boxes1[..., :2], boxes1[..., 2:])], axis=-1)
boxes2 = tf.concat([tf.minimum(boxes2[..., :2], boxes2[..., 2:]),
tf.maximum(boxes2[..., :2], boxes2[..., 2:])], axis=-1)
boxes1_area = (boxes1[..., 2] - boxes1[..., 0]) * (boxes1[..., 3] - boxes1[..., 1])
boxes2_area = (boxes2[..., 2] - boxes2[..., 0]) * (boxes2[..., 3] - boxes2[..., 1])
left_up = tf.maximum(boxes1[..., :2], boxes2[..., :2])
right_down = tf.minimum(boxes1[..., 2:], boxes2[..., 2:])
inter_section = tf.maximum(right_down - left_up, 0.0)
inter_area = inter_section[..., 0] * inter_section[..., 1]
union_area = boxes1_area + boxes2_area - inter_area
iou = inter_area / union_area
enclose_left_up = tf.minimum(boxes1[..., :2], boxes2[..., :2])
enclose_right_down = tf.maximum(boxes1[..., 2:], boxes2[..., 2:])
enclose = tf.maximum(enclose_right_down - enclose_left_up, 0.0)
enclose_area = enclose[..., 0] * enclose[..., 1]
giou = iou - 1.0 * (enclose_area - union_area) / enclose_area
return giou
# 5.计算损失
# pred是decode后的conv
# 输入: 模型输出的conv conv经处理后得到的pred 标签图片label
# 标签图片label的格式为[batch_size, output_size, output_size, anchor_per_scale, 85=(2个位置xy+2个形状wh+1个置信值+80个类别)]
def compute_loss(pred, conv, label, bboxes, i=0):
conv_shape = tf.shape(conv)
batch_size = conv_shape[0]
output_size = conv_shape[1]
input_size = STRIDES[i] * output_size # 原始图片尺寸
input_size = tf.cast(input_size, tf.float32)
# 格式为[batch_size, output_size, output_size, anchor_per_scale, 85=(2个位置xy+2个形状wh+1个置信值+80个类别)]
conv = tf.reshape(conv, (batch_size, output_size, output_size, 3, 5 + NUM_CLASS))
# 模型输出的置信值与分类
conv_raw_conf = conv[:, :, :, :, 4:5]
conv_raw_prob = conv[:, :, :, :, 5:]
pred_xywh = pred[:, :, :, :, 0:4] # 模型输出处理后预测框的位置
pred_conf = pred[:, :, :, :, 4:5] # 模型输出处理后预测框的置信值
label_xywh = label[:, :, :, :, 0:4] # 标签图片的标注框位置
respond_bbox = label[:, :, :, :, 4:5] # 标签图片的置信值,有目标的为1 没有目标为0
label_prob = label[:, :, :, :, 5:] # 标签图片的分类
# 1,位置和形状误差损失计算
# 方法:只计算有标签的anchor上的xy和wh的误差,若anchor没有标签,则不计入分类误差
# giou_loss计算的由来为https://yunyang1994.github.io/posts/YOLOv3/#more
giou = tf.expand_dims(bbox_giou(pred_xywh, label_xywh), axis=-1)
# bbox_loss_scale 制衡误差 2-w*h
bbox_loss_scale = 2.0 - 1.0 * label_xywh[:, :, :, :, 2:3] * label_xywh[:, :, :, :, 3:4] / (input_size ** 2)
giou_loss = respond_bbox * bbox_loss_scale * (1 - giou)
# 2.置信confidence误差损失计算方法:正样本误差+负样本误差
# 方法:在计算confidence的loss时,对于正样本(即该格子有目标),计算交叉熵;
# 对于负样本(即该格子没有目标),只有bbox与ground truth的IOU小于阈值ignore threshold(通常取为0.5)时再计入
# 实现:正样本用respond_bbox 负样本用respond_bgd 用0或1的相乘形式来保留符合条件去除不符合条件的
# 生成负样本
iou = bbox_iou(pred_xywh[:, :, :, :, np.newaxis, :], bboxes[:, np.newaxis, np.newaxis, np.newaxis, :, :])
max_iou = tf.expand_dims(tf.reduce_max(iou, axis=-1), axis=-1) # [batch_size, output_size, output_size, 1, 1]
# respond_bgd为[batch_size, output_size, output_size, anchor_per_scale, x] 当无目标且小于阈值时x为1,其余为0
respond_bgd = (1.0 - respond_bbox) * tf.cast(max_iou < IOU_LOSS_THRESH, tf.float32)
conf_focal = tf.pow(respond_bbox - pred_conf, 2)
# 但为何还要乘上conf_focal,我认为是去除这个的
conf_loss = conf_focal * (
# 正样本误差
respond_bbox * tf.nn.sigmoid_cross_entropy_with_logits(labels=respond_bbox, logits=conv_raw_conf)
+
# 负样本误差
respond_bgd * tf.nn.sigmoid_cross_entropy_with_logits(labels=respond_bbox, logits=conv_raw_conf)
)
# 3.分类损失误差 只计算在有目标的预测框上的分类误差,若预测框内没有目标,则不计入分类误差
# 方法: 通过相乘的形式可实现有条件的计算,不符合条件时,位置上的值为0,符合条件则为1,
# 比如 prob_loss就是这样计算的,当预测框上有目标时,此时对应在respond_bbox的位置上的值就为1
prob_loss = respond_bbox * tf.nn.sigmoid_cross_entropy_with_logits(labels=label_prob, logits=conv_raw_prob)
# 误差平均
giou_loss = tf.reduce_mean(tf.reduce_sum(giou_loss, axis=[1, 2, 3, 4]))
conf_loss = tf.reduce_mean(tf.reduce_sum(conf_loss, axis=[1, 2, 3, 4]))
prob_loss = tf.reduce_mean(tf.reduce_sum(prob_loss, axis=[1, 2, 3, 4]))
return giou_loss, conf_loss, prob_loss
第二部分 针对common文件代码解析
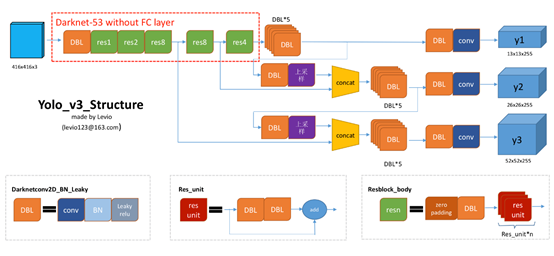
这一部分和下一部分主要是关于网络结构的搭建,根据下面这张图会更好地理解代码的含义,这张图相信大家也能在网上找到
import tensorflow as tf
# BN层不参与训练更新
# 这个写法我还是第一次见,比较怪
class BatchNormalization(tf.keras.layers.BatchNormalization):
"""
"Frozen state" and "inference mode" are two separate concepts.
`layer.trainable = False` is to freeze the layer, so the layer will use
stored moving `var` and `mean` in the "inference mode", and both `gama`
and `beta` will not be updated !
"""
def call(self, x, training=False):
if not training:
training = tf.constant(False)
training = tf.logical_and(training, self.trainable)
return super().call(x, training)
# 名称DBL 作用:卷积,输出是将输入行列各减半或一样大小 选项:是否加BN或激活
def convolutional(input_layer, filters_shape, downsample=False, activate=True, bn=True):
if downsample:
# ((top_pad, bottom_pad), (left_pad, right_pad)) 填充0
input_layer = tf.keras.layers.ZeroPadding2D(((1, 0), (1, 0)))(input_layer)
# 输出大小等于输入大小减去kernel_size加上1,最后再除以strides向上取整
padding = 'valid'
strides = 2
else:
strides = 1
# 输出大小等于输入大小除以strides向上取整
padding = 'same'
conv = tf.keras.layers.Conv2D(filters=filters_shape[-1], kernel_size=filters_shape[0], strides=strides, padding=padding,
use_bias=not bn, kernel_regularizer=tf.keras.regularizers.l2(0.0005), # 卷积核正则化
kernel_initializer=tf.random_normal_initializer(stddev=0.01), # 卷积核权值初始化
bias_initializer=tf.constant_initializer(0.))(input_layer)
if bn:
conv = BatchNormalization()(conv)
if activate == True:
conv = tf.nn.leaky_relu(conv, alpha=0.1)
return conv
# 名称res unit 作用
def residual_block(input_layer, input_channel, filter_num1, filter_num2):
short_cut = input_layer
conv = convolutional(input_layer, filters_shape=(1, 1, input_channel, filter_num1))
conv = convolutional(conv, filters_shape=(3, 3, filter_num1, filter_num2))
residual_output = short_cut + conv
return residual_output
# 调整图像大小 长宽各增加一倍
def upsample(input_layer):
return tf.image.resize(input_layer, (input_layer.shape[1] * 2, input_layer.shape[2] * 2), method='nearest')
第三部分 针对backbone文件代码解析
import tensorflow as tf
import core.common as common
# 第一个输出route_1 第二个输出route_2 第三个输出input_data
def darknet53(input_data):
input_data = common.convolutional(input_data, (3, 3, 3, 32))
input_data = common.convolutional(input_data, (3, 3, 32, 64), downsample=True)
for i in range(1):
input_data = common.residual_block(input_data, 64, 32, 64)
input_data = common.convolutional(input_data, (3, 3, 64, 128), downsample=True)
for i in range(2):
input_data = common.residual_block(input_data, 128, 64, 128)
input_data = common.convolutional(input_data, (3, 3, 128, 256), downsample=True)
for i in range(8):
input_data = common.residual_block(input_data, 256, 128, 256)
route_1 = input_data
input_data = common.convolutional(input_data, (3, 3, 256, 512), downsample=True)
for i in range(8):
input_data = common.residual_block(input_data, 512, 256, 512)
route_2 = input_data
input_data = common.convolutional(input_data, (3, 3, 512, 1024), downsample=True)
for i in range(4):
input_data = common.residual_block(input_data, 1024, 512, 1024)
return route_1, route_2, input_data
最后
以上就是有魅力季节最近收集整理的关于Tensorflow2.0:Yolo v3代码详解(一)的全部内容,更多相关Tensorflow2.0:Yolo内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。


![[Pytorch]YOLO目标检测目录一、经典算法与阶段(Stage)二、真实框(Ground Truth)、预测框(Prediction)与交并比(IoU)三、精确率(Precision)与召回率(Recall)四、置信度(Confidence)与置信度阈值(Confidence Threshold)五、AP(Average Precision)、mAP(Mean Average Precision)、所有点插值法(Interpolation Performed in all Points)与](https://www.shuijiaxian.com/files_image/reation/bcimg5.png)





发表评论 取消回复