一、KNN算法的概念
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是
数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
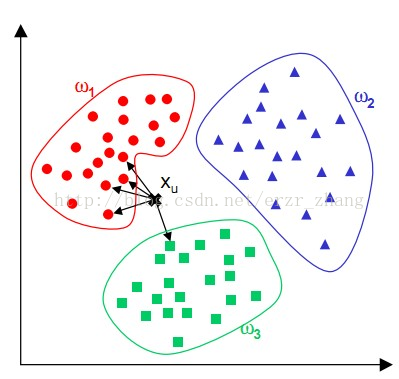
简单来说,K-NN可以看成:有那么一堆你已经知道分类的数据,然后当一个新数据进入的时候,就开始跟训练数据
里的每个点求距离,然后挑离这个训练数据最近的K个点看看这几个点属于什么类型,然后用少数服从多数的原则,
给新数据归类。
二、K近邻分类模型的三要素:
a:距离度量 b:K值的选择 c:分类决策的规则
距离度量:
1.
欧氏距离是最常见的距离度量,衡量的是多维空间中各个点之间的绝对距离。公式如下:
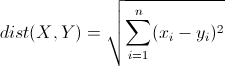
2.
曼哈顿距离(Manhattan Distance),公式如下:
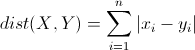
K值选择:
下面有一幅图片来理解K的取值

如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
如果K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
K越大,模型越简单,近似误差也越大。反之,K越小,模型越复杂,越容易发生过拟合。
分类决策规则:
1.多数表决规则
2.距离加权规则
三、计算步骤
1.算距离
2.找临近
3.做分类
四、用python实现分类
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
X_train, Y_train = mnist.train.next_batch(5000)
X_test, Y_test = mnist.test.next_batch(200)
x_train = tf.placeholder(tf.float32, [None, 784])
x_test = tf.placeholder(tf.float32, [784])
distance = tf.reduce_sum(tf.abs(tf.add(x_train, tf.negative(x_test))), axis=1)
pred = tf.argmin(distance, 0)
accuracy = 0
init = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
m = len(x_test)
for i in range(m):
index = sess.run([pred, distance], feed_dict={x_train: X_train, x_test: X_test[i:]})
pred_label = np.argmax(Y_train[index])
true_label = np.argmax(Y_train[i])
if pred_label == true_label:
accuracy += 1
print("test", i, "predict label:", pred_label, "true label:", true_label)
print("done")
print("accuracy:", accuracy / m)最后
以上就是标致人生最近收集整理的关于用Tensorflow实现简单的KNN的全部内容,更多相关用Tensorflow实现简单内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复