先从一个故事说起
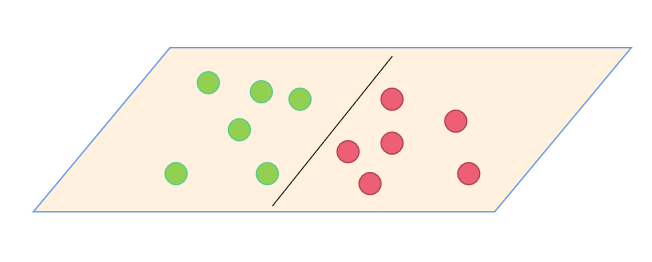
国王为武林高手出了一道题,将红豆绿豆摆在桌子上,让他将其分开,于是武林高手轻松的在桌子上画了一条线,将红豆绿豆分开,如下图
于是,国王又将这两种豆子混子一起散落在桌子上,如图
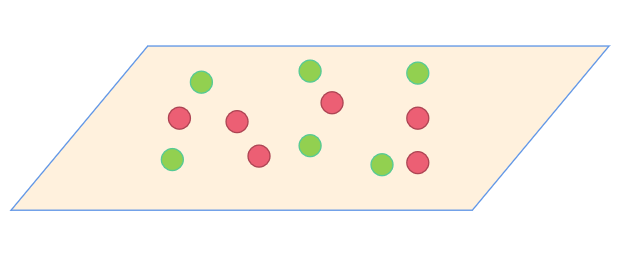 又让武林高手将其分开,心想,这次我看你怎么分,没想到,武林高手站在桌子面前,运足内力,用手掌拍在桌子上,豆子瞬间腾空而起,高手用一张纸将豆子分成两部分,上面的是绿豆,下面的是红豆
又让武林高手将其分开,心想,这次我看你怎么分,没想到,武林高手站在桌子面前,运足内力,用手掌拍在桌子上,豆子瞬间腾空而起,高手用一张纸将豆子分成两部分,上面的是绿豆,下面的是红豆
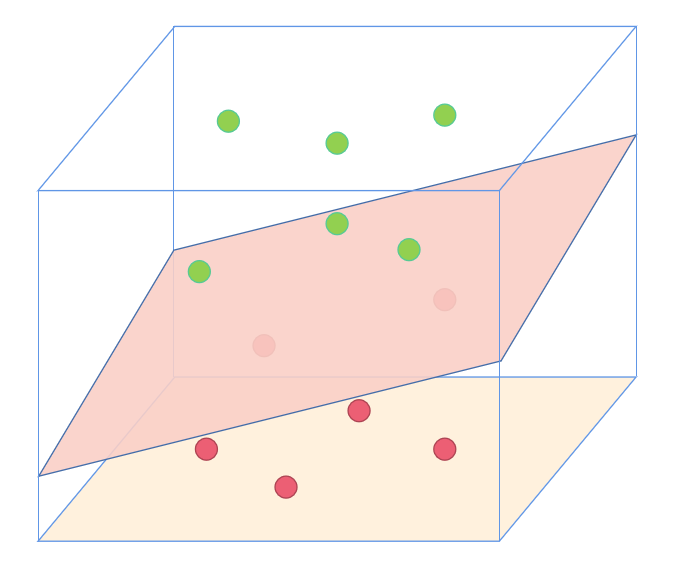
上面的故事其实就是支持向量机的直观理解,这些豆子叫做data,把线叫做classifier, 最大间隙trick叫做optimization,拍桌子叫做kernelling, 那张纸叫做hyperplane
支持向量机( support vector machines, SVM)是一种二类分类模型。SVM最基本的原理就是寻找一个分隔“平面”将样本空间一分为二,对于二维平面,分割的其实是一条线,三维平面就需要一个平面来分开,对于 n 维数据,要想将其分开,就需要一个 n-1 维的超平面
支持向量机学习方法包含构建由简至繁的模型:线性可分支持向量机( linear support vectormachine in linearly separable case)、线性支持向量机( linear support vector machine)及非线性支持向量机(non- linear support vector machine)。 简单模型是复杂模型的基础,也是复杂模型的特殊情况。当训练数据线性可分时, 通过硬间隔最大化( hard margin maximization),学习一个线性的分类器,即线性可分支持向量机,又称为硬间隔支持向量机;当训练数据近似线性可分时,通过软间隔最大化( soft margin aximization),也学习一个线性的分类器,即线性支持向量机,又称为软间隔支持向量机;当训练数据线性不可分时,通过使用核技巧( kernel trick)及软间隔最大化,学习非线性支持向量机
硬间隔最大化模型
下面就从线性可分支持向量机硬间隔最大化说起,以二维为例,如图

要把数据分开可以有很多种分法,我们要取得就是最好的分法,如上图,黑色线代表分割直线(平面),蓝色区域代表间隔,显然,间隔越大,代表这个线(面)的区分能力越大。我们的目的就是找到这个线(面),由上图我们可以看到,绝大多数样本对这个间隔的大小不起作用,只有在蓝色区域边上的样本才能决定间隔的大小,SVM中这些落在边缘的样本称为支持向量,这也就是SVM名字的由来
这个分割平面用公式表示
w
T
x
+
b
=
0
w^Tx+b=0
wTx+b=0
分类决策函数为
f
(
x
)
=
s
i
g
n
(
w
T
x
+
b
)
f(x)=sign(w^Tx+b)
f(x)=sign(wTx+b)
其中
x
x
x 表示一个 n 维的样本向量,
w
w
w 是平面的 n 维法向量。虽然从公式上来看和线性回归很像,但是它们之间的本质区别,线性回归是用来拟合label的,而SVM的平面方程是用来确定平面方向的。在这个平面一侧为一类数据,另一侧则为另一类
我们的目标是让这个间隔最大,样本到这个分割平面的距离为
d
=
∣
w
T
x
+
b
∣
∣
∣
w
∣
∣
d=frac{|w^Tx+b|}{||w||}
d=∣∣w∣∣∣wTx+b∣
这个公式其实就是高中学过点到直线距离得演变
d
=
∣
A
x
+
B
y
+
C
∣
A
2
+
B
2
d=frac{|Ax+By+C|}{sqrt{A^2+B^2}}
d=A2+B2∣Ax+By+C∣
||w|| 是L2范数
模型假设
首先这个平面要将数据正确分类,在平面上方的数据类别为
y
=
1
y=1
y=1,在平面下方的数据类别为
y
=
−
1
y=-1
y=−1
对于上方数据,到平面距离
w
T
x
+
b
>
0
w^Tx+b>0
wTx+b>0, 平面下方数据
w
T
x
+
b
<
0
w^Tx+b<0
wTx+b<0,这样我们可以用
y
i
(
w
T
x
i
+
b
)
>
0
y_i(w^Tx_i+b)>0
yi(wTxi+b)>0
表示样本被正确分类
这样问题就转化为
{
m
a
x
2
∣
w
T
x
+
b
∣
∣
∣
w
∣
∣
s
.
t
.
y
i
(
w
T
x
i
+
b
)
>
0
,
i
=
1
,
2
,
3
…
,
n
begin{cases} max&2frac{|w^Tx+b|}{||w||} \ s.t.&y_i(w^Tx_i+b)>0, i=1,2,3…,n end{cases}
{maxs.t.2∣∣w∣∣∣wTx+b∣yi(wTxi+b)>0,i=1,2,3…,n
在间隔边缘上的点到分割平面的距离是间隔距离得一半,我们令这个点的函数值为
γ
gamma
γ,则
y
i
(
w
T
x
i
+
b
)
=
γ
y
i
(
w
T
γ
x
i
+
b
γ
)
=
1
y_i(w^Tx_i+b)=gamma \ y_i(frac{w^T}{gamma}x_i+frac{b}{gamma})=1
yi(wTxi+b)=γyi(γwTxi+γb)=1
这里令新的
w
^
=
w
T
γ
hat{w}=frac{w^T}{gamma}
w^=γwT,新的
b
^
=
b
γ
hat{b}=frac{b}{gamma}
b^=γb,可以将这个距离看做是单位 1,这样就得到
y
i
(
w
T
x
i
+
b
)
≥
1
y_i(w^Tx_i+b)≥1
yi(wTxi+b)≥1 对于支持向量来说
y
i
(
w
T
x
i
+
b
)
=
1
y_i(w^Tx_i+b)=1
yi(wTxi+b)=1,那么间隔可以表示为
γ
=
2
∣
w
T
x
+
b
∣
∣
∣
w
∣
∣
=
2
∣
∣
w
∣
∣
gamma=2frac{|w^Tx+b|}{||w||}=frac{2}{||w||}
γ=2∣∣w∣∣∣wTx+b∣=∣∣w∣∣2
为了方便计算,我们要求
2
∣
∣
w
∣
∣
frac{2}{||w||}
∣∣w∣∣2的最大值,转换为
∣
∣
w
∣
∣
2
||w||^2
∣∣w∣∣2 的最小值,问题进一步转化为
{
m
i
n
w
,
b
∣
∣
w
∣
∣
2
2
s
.
t
.
y
i
(
w
T
x
i
+
b
)
≥
1
,
i
=
1
,
2
,
3
…
,
n
begin{cases} underset{w,b}{min}&frac{||w||^2}{2} \ s.t.&y_i(w^Tx_i+b)geq1, i=1,2,3…,n end{cases}
⎩⎨⎧w,bmins.t.2∣∣w∣∣2yi(wTxi+b)≥1,i=1,2,3…,n
目标函数本身是一个凸二次规划问题,能直接用现成的优化计算包求解,这种解法有一个很大的缺点在于没办法套用核函数,我们可以有更高效的做法——求解对偶问题
首先要构造朗格朗日函数
我们先看一下拉格朗日乘子法的使用过程,给定一个不等式约束问题:
{
m
i
n
x
f
(
x
)
s
.
t
.
g
i
(
x
)
≤
0
,
i
=
1
,
2
,
3
…
,
k
h
i
(
x
)
=
0
,
i
=
1
,
2
,
3
…
,
m
begin{cases} underset{x}{min}f(x) \ begin{aligned}s.t.g_i(x)≤0, i=1,2,3…,k \ h_i(x)=0, i=1,2,3…,mend{aligned}end{cases}
⎩⎪⎪⎨⎪⎪⎧xminf(x)s.t.gi(x)≤0,i=1,2,3…,khi(x)=0,i=1,2,3…,m
我们引入一个广义朗格朗日函数,将它改写成这样:
L
(
x
,
α
,
β
)
=
f
(
x
)
+
∑
i
=
1
k
α
i
g
i
(
x
)
+
∑
i
=
1
m
β
i
h
i
(
x
)
,
α
i
≥
0
L(x,alpha,beta)=f(x)+sum_{i=1}^{k}alpha_ig_i(x)+sum_{i=1}^{m}beta_ih_i(x),alpha_i≥0
L(x,α,β)=f(x)+i=1∑kαigi(x)+i=1∑mβihi(x),αi≥0
我们会发现
L
≤
f
(
x
)
Lleq f(x)
L≤f(x)所以我们要求的是
m
a
x
L
(
x
,
α
,
β
)
max L(x,alpha,beta)
maxL(x,α,β)
最终的目标是
m
i
n
b
,
w
(
m
a
x
α
i
≥
0
L
(
b
,
w
,
α
)
)
underset{b,w}{min} big(underset{alpha_igeq0}{max}L(b,w,alpha)big)
b,wmin(αi≥0maxL(b,w,α))
构造的拉格朗日函数为
L
(
w
,
b
,
α
)
=
1
2
∣
∣
w
∣
∣
2
+
∑
i
=
1
m
α
i
(
1
−
y
i
(
w
T
x
i
+
b
)
)
L(w,b,alpha)=frac{1}{2}||w||^2+sum_{i=1}^{m}alpha_i(1-y_i(w^Tx_i+b))
L(w,b,α)=21∣∣w∣∣2+i=1∑mαi(1−yi(wTxi+b))
对偶问题
m i n b , w ( m a x α i ≥ 0 L ( b , w , α ) ) underset{b,w}{min}big(underset{alpha_igeq0}{max}L(b,w,alpha)big) b,wmin(αi≥0maxL(b,w,α)) 转化为 m a x α i ≥ 0 ( m i n b , w L ( b , w , α ) ) underset{alpha_igeq0}{max}big(underset{b,w}{min}L(b,w,alpha)big) αi≥0max(b,wminL(b,w,α))
KKT条件
α
i
≥
0
y
i
(
w
T
+
b
)
−
1
≥
0
α
i
(
1
−
y
i
(
w
T
+
b
)
)
=
0
begin{aligned} alpha_i&geq0 \ y_i(w^T+b)-1&geq0\ alpha_i(1-y_i(w^T+b))&=0 end{aligned}
αiyi(wT+b)−1αi(1−yi(wT+b))≥0≥0=0
分别对 w , b w,b w,b求导
∂
L
∂
b
=
−
∑
i
=
1
m
α
i
y
i
=
0
∂
L
∂
w
=
w
−
∑
i
=
1
m
α
i
y
i
x
i
→
w
=
∑
i
=
1
m
α
i
y
i
x
i
begin{aligned} &frac{partial L}{partial b}=-sum_{i=1}^{m}alpha_iy_i=0 \ &frac{partial L}{partial w}=w-sum_{i=1}^{m}alpha_iy_ix_i → w=sum_{i=1}^{m}alpha_iy_ix_i end{aligned}
∂b∂L=−i=1∑mαiyi=0∂w∂L=w−i=1∑mαiyixi→w=i=1∑mαiyixi
代入到上面函数
L
(
w
,
b
,
α
)
=
1
2
w
T
w
+
∑
i
=
1
m
α
i
−
∑
i
=
1
m
α
i
y
i
w
T
x
i
−
∑
i
=
1
m
α
i
y
i
b
=
−
1
2
(
∑
i
=
1
m
α
i
y
i
x
i
)
T
∑
i
=
1
m
α
i
y
i
x
i
+
∑
i
=
1
m
α
i
=
∑
i
=
1
m
α
i
−
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
x
i
T
x
j
begin{aligned} L(w,b,alpha)&=frac{1}{2}w^Tw+sum_{i=1}^{m}alpha_i-sum_{i=1}^{m}alpha_iy_iw^Tx_i-sum_{i=1}^{m}alpha_iy_ib \ &=-frac{1}{2}(sum_{i=1}^{m}alpha_iy_ix_i )^Tsum_{i=1}^{m}alpha_iy_ix_i +sum_{i=1}^{m}alpha_i \ &=sum_{i=1}^{m}alpha_i-frac{1}{2}sum_{i=1}^{m}sum_{j=1}^{m}alpha_ialpha_jy_iy_jx_i^Tx_j end{aligned}
L(w,b,α)=21wTw+i=1∑mαi−i=1∑mαiyiwTxi−i=1∑mαiyib=−21(i=1∑mαiyixi)Ti=1∑mαiyixi+i=1∑mαi=i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxj
我们要求的是上式的最大值,最终我们的目标是
m
i
n
α
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
x
i
T
x
j
−
∑
i
=
1
m
α
i
underset{alpha}{min}frac{1}{2}sum_{i=1}^{m}sum_{j=1}^{m}alpha_ialpha_jy_iy_jx_i^Tx_j-sum_{i=1}^{m}alpha_i
αmin21i=1∑mj=1∑mαiαjyiyjxiTxj−i=1∑mαi
s
.
t
.
∑
i
=
1
m
α
i
y
i
=
0
α
i
≥
0
,
i
=
1
,
2
,
3
,
…
,
m
begin{aligned} s.t. &sum_{i=1}^{m}alpha_iy_i=0 \ &alpha_igeq 0, i=1,2,3,…,m end{aligned}
s.t. i=1∑mαiyi=0αi≥0,i=1,2,3,…,m
唯一的变量
α
alpha
α,求出
α
alpha
α 就可以推导出对应的
w
w
w 和
b
b
b 了
w
=
∑
i
=
1
m
α
i
y
i
x
i
b
=
y
i
−
w
∗
x
i
w=sum_{i=1}^{m}alpha_iy_ix_i \ b=y_i-w*x_i
w=i=1∑mαiyixib=yi−w∗xi
软间隔最大化模型
在实际场景中,数据不可能都是线性可分的,我们要允许一些样本出错,这样我们就要引入一个松弛变量
ξ
xi
ξ,适当放松
y
i
(
w
t
x
i
+
b
)
≥
1
y_i(w^tx_i+b)geq1
yi(wtxi+b)≥1 这个条件,变为
y
i
(
w
t
x
i
+
b
)
≥
1
−
ξ
y_i(w^tx_i+b)geq1-xi
yi(wtxi+b)≥1−ξ
我们把松弛变量加入到目标函数中
m
i
n
b
,
w
,
ξ
1
2
∣
∣
w
∣
∣
2
+
C
∑
i
=
1
m
ξ
i
s
.
t
.
y
i
(
w
T
x
i
+
b
)
≥
1
−
ξ
,
i
=
1
,
2
,
3
…
,
n
ξ
i
≥
0
,
i
=
1
,
2
,
3
…
n
,
begin{aligned} underset{b,w,xi}{min}&frac{1}{2}||w||^2+Csum_{i=1}^mxi_i\&s.t. quad y_i(w^Tx_i+b)geq1-xi, i=1,2,3…,n end{aligned}\ xi_igeq0,i=1,2,3…n,
b,w,ξmin21∣∣w∣∣2+Ci=1∑mξis.t.yi(wTxi+b)≥1−ξ,i=1,2,3…,nξi≥0,i=1,2,3…n,
C为一个常数,可以理解为惩罚参数。我们希望
∣
∣
w
∣
∣
2
||w||^2
∣∣w∣∣2尽可能小,也希望
∑
ξ
i
sumxi_i
∑ξi尽量小,C就是用来协调两者的。C越大代表我们对模型的分类要求越严格
拉格朗日函数
L
(
w
,
b
,
ξ
,
α
,
β
)
=
1
2
∣
∣
w
∣
∣
2
+
C
∑
i
=
1
m
ξ
i
+
∑
i
=
1
m
α
i
(
1
−
ξ
i
−
y
i
(
w
T
x
i
+
b
)
)
+
∑
i
=
1
m
β
i
(
−
ξ
i
)
L(w,b,xi,alpha,beta)=frac{1}{2}||w||^2+Csum_{i=1}^{m}xi_i+sum_{i=1}^{m}alpha_i(1-xi_i-y_i(w^Tx_i+b))+sum_{i=1}^{m}beta_i(-xi_i)
L(w,b,ξ,α,β)=21∣∣w∣∣2+Ci=1∑mξi+i=1∑mαi(1−ξi−yi(wTxi+b))+i=1∑mβi(−ξi)
我们要求这个函数的最值,也就是
m
i
n
w
,
b
,
ξ
(
m
a
x
α
≥
0
,
β
≥
0
L
(
w
,
b
,
ξ
,
α
,
β
)
)
underset{w,b,xi}{min}big(underset{alphageq0,betageq0}{max}L(w,b,xi, alpha,beta)big)
w,b,ξmin(α≥0,β≥0maxL(w,b,ξ,α,β))
原函数的对偶问题是
m
a
x
α
≥
0
,
β
≥
0
(
m
i
n
w
,
b
,
ξ
L
(
w
,
b
,
ξ
,
α
,
β
)
)
underset{alphageq0,betageq0}{max}big(underset{w,b,xi}{min}L(w,b,xi, alpha,beta)big)
α≥0,β≥0max(w,b,ξminL(w,b,ξ,α,β))
分别对 w , b , ξ w,b,xi w,b,ξ求导
∂
L
∂
w
=
w
−
∑
i
=
1
m
α
i
y
i
x
i
→
w
=
∑
i
=
1
m
α
i
y
i
x
i
∂
L
∂
b
=
−
∑
i
=
1
m
α
i
y
i
=
0
∂
L
∂
ξ
=
C
−
α
i
−
β
i
=
0
→
β
i
=
C
−
α
i
begin{aligned} &frac{partial L}{partial w}=w-sum_{i=1}^{m}alpha_iy_ix_i → w=sum_{i=1}^{m}alpha_iy_ix_i \ &frac{partial L}{partial b}=-sum_{i=1}^{m}alpha_iy_i=0 \ &frac{partial L}{partial xi}=C-alpha_i-beta_i=0 →beta_i = C-alpha_i end{aligned}
∂w∂L=w−i=1∑mαiyixi→w=i=1∑mαiyixi∂b∂L=−i=1∑mαiyi=0∂ξ∂L=C−αi−βi=0→βi=C−αi
代入对偶函数得:
L
(
w
,
b
,
ξ
,
α
,
β
)
=
−
1
2
∣
∣
w
∣
∣
2
+
C
∑
i
=
1
m
ξ
i
+
∑
i
=
1
m
α
i
(
1
−
ξ
i
)
−
∑
i
=
1
m
(
C
−
α
i
)
ξ
i
=
∑
i
=
1
m
α
i
−
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
x
i
T
x
j
begin{aligned}L(w,b,xi,alpha,beta)&=-frac{1}{2}||w||^2+Csum_{i=1}^{m}xi_i+sum_{i=1}^{m}alpha_i(1-xi_i)-sum_{i=1}^{m}(C-alpha_i)xi_i\ &=sum_{i=1}^{m}alpha_i-frac{1}{2}sum_{i=1}^{m}sum_{j=1}^{m}alpha_ialpha_jy_iy_jx_i^Tx_j end{aligned}
L(w,b,ξ,α,β)=−21∣∣w∣∣2+Ci=1∑mξi+i=1∑mαi(1−ξi)−i=1∑m(C−αi)ξi=i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxj
由于
α
i
≥
0
alpha_igeq0
αi≥0 ,可以得到
0
≤
α
i
≤
C
0leqalpha_ileq C
0≤αi≤C ,所以最后式子化简为
m
i
n
α
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
x
i
T
x
j
−
∑
i
=
1
m
α
i
underset{alpha}{min}frac{1}{2}sum_{i=1}^{m}sum_{j=1}^{m}alpha_ialpha_jy_iy_jx_i^Tx_j-sum_{i=1}^{m}alpha_i
αmin21i=1∑mj=1∑mαiαjyiyjxiTxj−i=1∑mαi
s
.
t
.
∑
i
=
1
m
α
i
y
i
=
0
0
≤
α
i
≤
C
,
i
=
1
,
2
,
3
,
…
,
m
begin{aligned} s.t. &sum_{i=1}^{m}alpha_iy_i=0 \ &0leqalpha_ileq C, i=1,2,3,…,m end{aligned}
s.t. i=1∑mαiyi=00≤αi≤C,i=1,2,3,…,m
下面来看KTT条件,分三个部分
原始问题可行:
1
−
ξ
i
−
y
i
(
w
T
x
i
+
b
)
≤
0
−
ξ
i
≤
0
begin{aligned}1-xi_i-y_i(w^Tx_i+b)&leq0\ -xi_i&leq0 end{aligned}
1−ξi−yi(wTxi+b)−ξi≤0≤0
对偶问题可行:
α
i
≥
0
β
i
=
C
−
α
i
begin{aligned}alpha_i&geq0\ beta_i &= C-alpha_i end{aligned}
αiβi≥0=C−αi
以及松弛可行:
α
i
(
1
−
ξ
i
−
y
i
(
w
T
x
i
+
b
)
)
=
0
β
i
ξ
i
=
0
begin{aligned}alpha_i(1-xi_i-y_i(w^Tx_i+b))&=0\ beta_ixi_i&=0 end{aligned}
αi(1−ξi−yi(wTxi+b))βiξi=0=0
观察
α
i
(
1
−
ξ
i
−
y
i
(
w
T
x
i
+
b
)
)
=
0
alpha_i(1-xi_i-y_i(w^Tx_i+b))=0
αi(1−ξi−yi(wTxi+b))=0
1.如果
α
i
=
0
alpha_i=0
αi=0,则
β
>
0
,
beta>0,
β>0,
ξ
i
=
0
xi_i=0
ξi=0 那么
1
−
ξ
i
−
y
i
(
w
T
x
i
+
b
)
≤
0
1-xi_i-y_i(w^Tx_i+b)leq0
1−ξi−yi(wTxi+b)≤0,即
y
i
(
w
T
x
i
+
b
)
≥
1
y_i(w^Tx_i+b)geq1
yi(wTxi+b)≥1,样本被正确分类,这些样本不是支持向量
2.如果
α
i
>
0
alpha_i>0
αi>0,那么
1
−
ξ
i
−
y
i
(
w
T
x
i
+
b
)
=
0
1-xi_i-y_i(w^Tx_i+b)=0
1−ξi−yi(wTxi+b)=0,样本是支持向量。由于
C
=
α
i
+
β
i
C=alpha_i+beta_i
C=αi+βi
又可以分为下面两种情况
(1)
0
<
α
<
C
0<alpha<C
0<α<C,那么
β
i
>
0
beta_i>0
βi>0 ,所以
ξ
i
=
0
xi_i=0
ξi=0,样本在边界上
(2)
α
=
C
alpha=C
α=C,那么
β
i
=
0
beta_i=0
βi=0 ,此时
- 如果 ξ i < 1 xi_i<1 ξi<1,样本被正确分类
- 如果 ξ i = 1 xi_i=1 ξi=1,样本在超平面上
- 如果 ξ i > 1 xi_i>1 ξi>1,样本分类错误
核函数
对于线性不可分的数据集,无法在原始空间找到分离平面,于是我们就要把原始数据映射到更高的维度(如故事中的拍桌子),在高维度上找到一个分割平面。
在线性回归中,我们用多项式扩展可以将非线性问题转化为线性问题,我们借鉴这个思路,在SVM中,我们把低维不可分的数据,映射到高维,变成线性可分的。
我们用
Φ
Phi
Φ 来表示核函数,样本经过核函数映射之后,就变为
Φ
(
x
)
Phi(x)
Φ(x)
m
i
n
α
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
x
i
T
x
j
−
∑
i
=
1
m
α
i
underset{alpha}{min}frac{1}{2}sum_{i=1}^{m}sum_{j=1}^{m}alpha_ialpha_jy_iy_jx_i^Tx_j-sum_{i=1}^{m}alpha_i
αmin21i=1∑mj=1∑mαiαjyiyjxiTxj−i=1∑mαi
s
.
t
.
∑
i
=
1
m
α
i
y
i
=
0
0
≤
α
i
≤
C
,
i
=
1
,
2
,
3
,
…
,
m
begin{aligned} s.t. &sum_{i=1}^{m}alpha_iy_i=0 \ &0leqalpha_ileq C, i=1,2,3,…,m end{aligned}
s.t. i=1∑mαiyi=00≤αi≤C,i=1,2,3,…,m
把核函数代入便得到
m
i
n
α
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
Φ
(
x
i
)
T
Φ
(
x
j
)
−
∑
i
=
1
m
α
i
underset{alpha}{min}frac{1}{2}sum_{i=1}^{m}sum_{j=1}^{m}alpha_ialpha_jy_iy_jPhi(x_i)^TPhi(x_j)-sum_{i=1}^{m}alpha_i
αmin21i=1∑mj=1∑mαiαjyiyjΦ(xi)TΦ(xj)−i=1∑mαi
s
.
t
.
∑
i
=
1
m
α
i
y
i
=
0
0
≤
α
i
≤
C
,
i
=
1
,
2
,
3
,
…
,
m
begin{aligned} s.t. &sum_{i=1}^{m}alpha_iy_i=0 \ &0leqalpha_ileq C, i=1,2,3,…,m end{aligned}
s.t. i=1∑mαiyi=00≤αi≤C,i=1,2,3,…,m
我们可以看到,核函数仅仅是将內积
x
i
T
x
j
x_i^Tx_j
xiTxj 变成
Φ
(
x
i
)
T
Φ
(
x
j
)
Phi(x_i)^TPhi(x_j)
Φ(xi)TΦ(xj),如果我们的原始数据是2维度,映射到5维,再做点积运算,复杂度就会大大提高,如果是更高维度,复杂度将会大大增加,而核函数是在低微来计算得,这样就降低了运算的复杂度,我们把符合这种条件的函数称为核函数,称为K
K
(
x
i
,
x
j
)
=
K
(
x
i
T
x
j
)
=
Φ
(
x
i
)
T
Φ
(
x
j
)
K(x_i,x_j)=K(x_i^Tx_j)=Phi(x_i)^TPhi(x_j)
K(xi,xj)=K(xiTxj)=Φ(xi)TΦ(xj)
核函数作用其实就是把问题映射到更高维度,把求解复杂度降下来,在训练模型时如果用到了核函数,在与测试也会经过核函数
经过核函数,数据被映射到高维,计算量只是增加了一点
常用的核函数有
1、线性核函数
K
(
x
i
,
x
j
)
=
x
i
T
x
j
K(x_i,x_j)=x_i^Tx_j
K(xi,xj)=xiTxj
2、多项式核函数
K
(
x
i
,
x
j
)
=
(
γ
x
i
T
x
j
+
r
)
d
K(x_i,x_j)=(gamma x_i^Tx_j+r)^d
K(xi,xj)=(γxiTxj+r)d 其中
γ
,
r
,
d
gamma,r,d
γ,r,d需要自己调参
3、高斯核函数
K
(
x
i
,
x
j
)
=
e
x
p
(
−
γ
∣
∣
x
i
−
x
j
∣
∣
2
)
K(x_i,x_j)=exp(-gamma ||x_i-x_j||^2)
K(xi,xj)=exp(−γ∣∣xi−xj∣∣2)
4、sigmoid核函数
K
(
x
i
,
x
j
)
=
t
a
n
h
(
γ
x
i
T
x
j
+
r
)
K(x_i,x_j)=tanh(gamma x_i^Tx_j+r)
K(xi,xj)=tanh(γxiTxj+r) 其中
γ
,
r
gamma,r
γ,r需要自己调参
最后
以上就是风中画板最近收集整理的关于机器学习——SVM(支持向量机)的全部内容,更多相关机器学习——SVM(支持向量机)内容请搜索靠谱客的其他文章。








发表评论 取消回复