WHY字节对齐:
ü 每个硬件平台对于存储空间的处理不同。有没有字节对齐主要是对于存取效率的影响。
ü 对于协议栈开发,上下层对于字节对齐的处理不同,将直接影响数据的读取。
Ubuntu 2.6.32内核,gcc版本为4.7.0
l 字节对齐:__attribute__((packed))与#pragma pack(n)
#pragma pack() 取消当前设定字节对齐方式。
该环境下默认的最大对齐字节数为4。如果max{sizeof(type)}<4, 则做max{sizeof(type)}字节对齐。




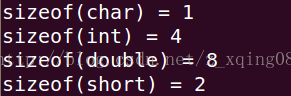
通过typedef struct {}test1; &(((test1*)0)->b)=0x0; &(((test1*)0)->b)=0x4,说明char占用了4字节。为了字节对齐padding了3个字节。




二者结构体大小均为7。
#pragma pack(1) 是将字节对齐的字节数设置为1。
__attribute__((packed)) 作用是取消字节对齐。说明取消之后默认为1。


这说明了#pragma pack(n) 针对sizeof(type) < n的类型做n字节对齐,针对大于n的类型,做n*(k-1)=<sizeof(n)<=n*k(k为正整数)字节对齐。
l 边界对齐:__attribute__((aligned(n)))
该环境下 __attribute__((aligned))等同于__attribute__((aligned(8)))。
按照上述字节对齐方式进行之后,检查边界地址是否为(n的整数倍) - 1,如果不是,则通过字节padding 将其变为(n*k) - 1(k为正整数)。[由于起始地址为0]


通过将其地址打印可以知道,该结构体是4字节对齐存储方式,如果不做边界对齐打印结果为12。所以边界对齐将填充了4字节使其大小成为2*8= 16,即8的倍数。
最后
以上就是殷勤小馒头最近收集整理的关于字节对齐与边界对齐的全部内容,更多相关字节对齐与边界对齐内容请搜索靠谱客的其他文章。








发表评论 取消回复