知识图谱概要
概念介绍
什么是知识,知识从哪来
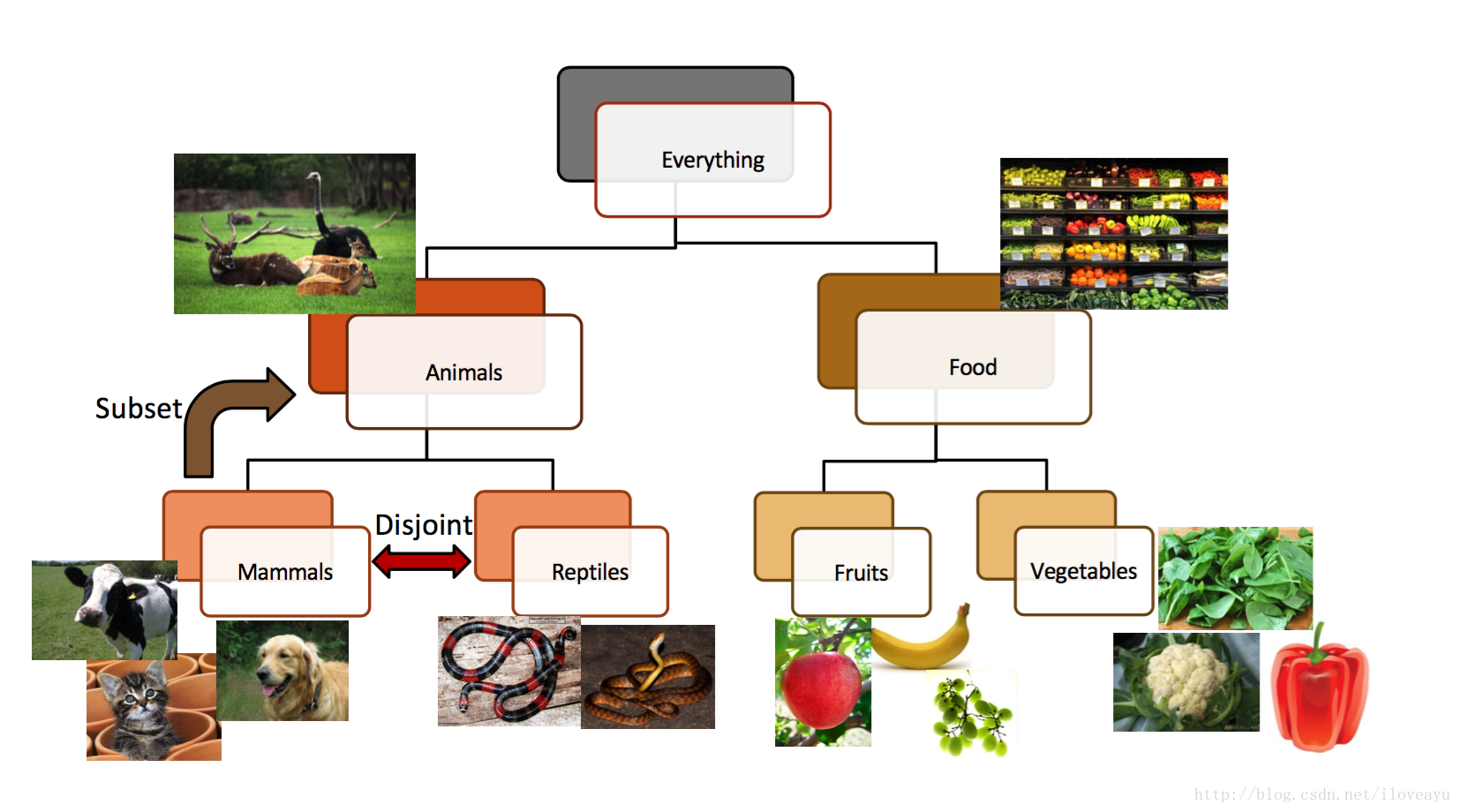
现实世界的语义本体,本体的相关语义,本体的认知层次,本体间的关系,都可以叫做知识
知识从哪里来
- 结构化文本
wiki,infobox,tables,database,social-net

- 非结构化文本
互联网,新闻,社交媒体… - 图像,视频流
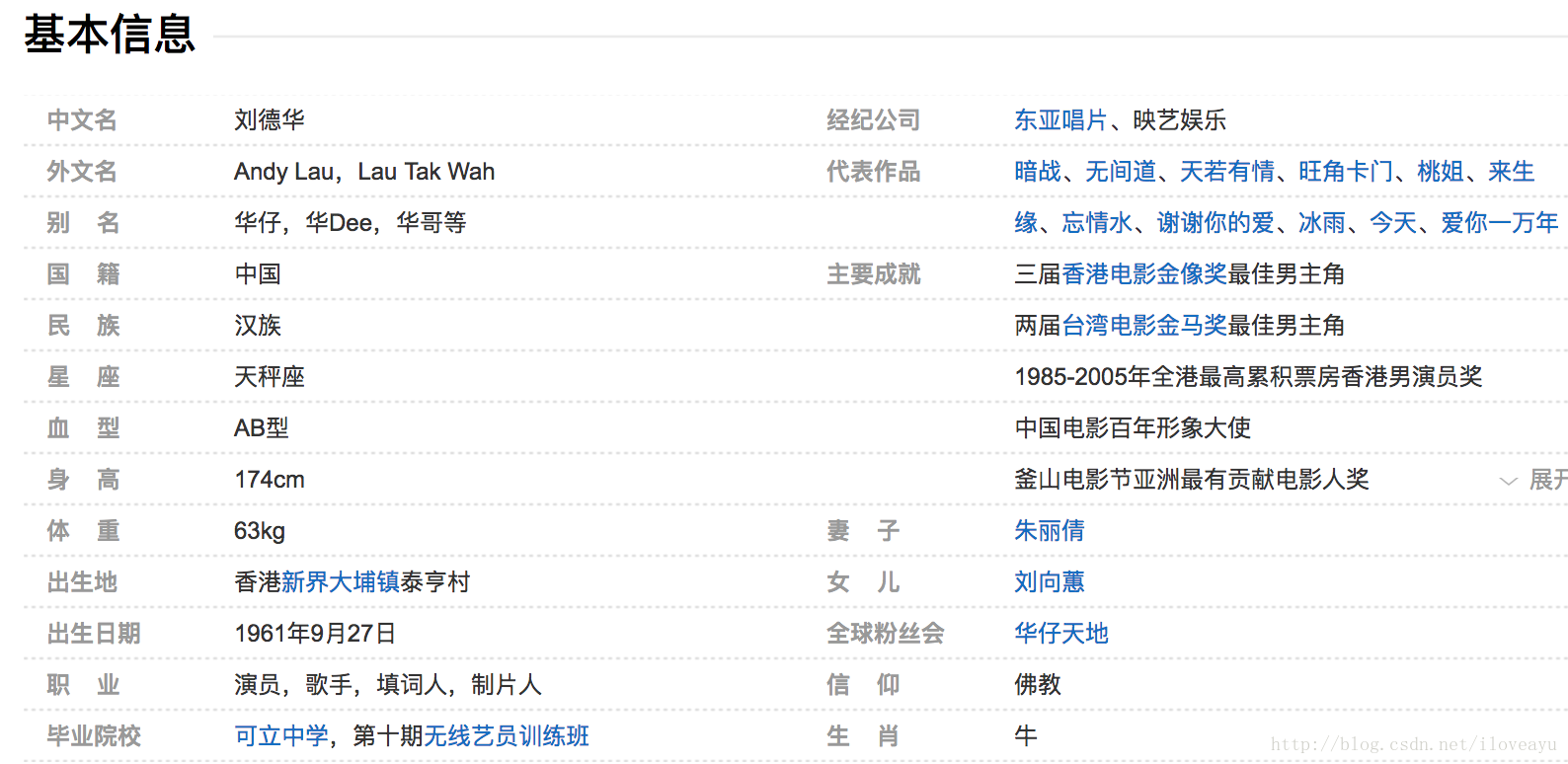
什么是知识图谱
- 实体-对应现实世界的语义本体
- 关系-对应本体间的关系,连接了不同类型的实体
属性-描述一类实体的common特性,实体被属性所标注
为什么需要知识图谱
查询理解
- 优化搜索排序
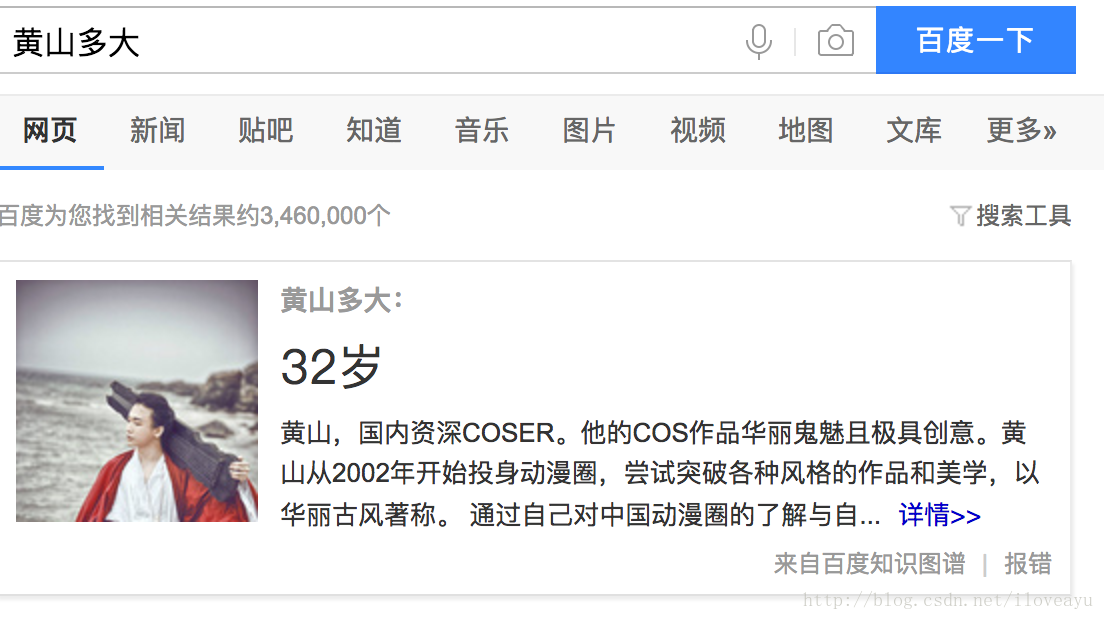
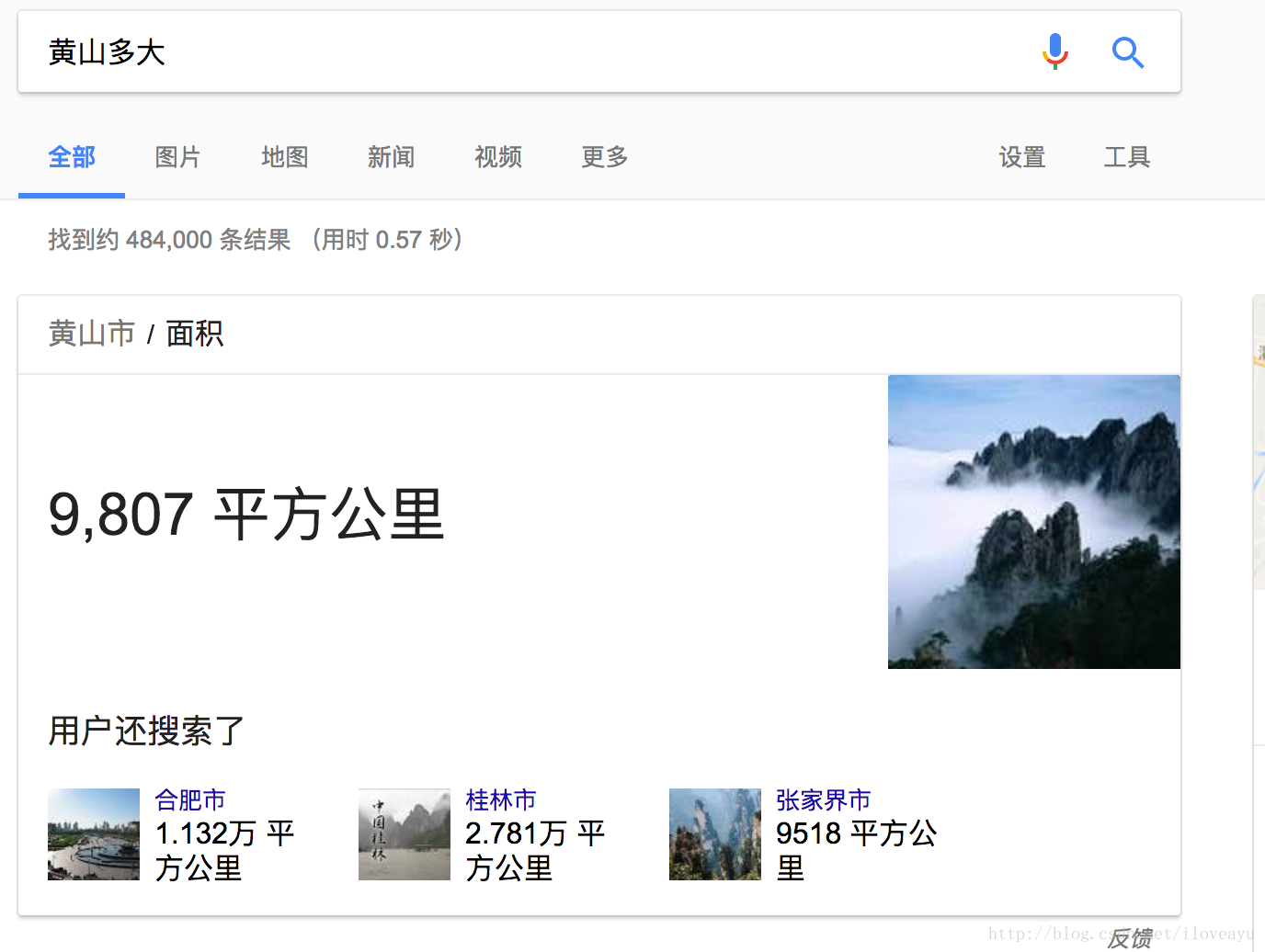
- 对同名实体进行搜索属性,为什么百度和google给出了不一样的排序结果?
- 特定意图的知识展现
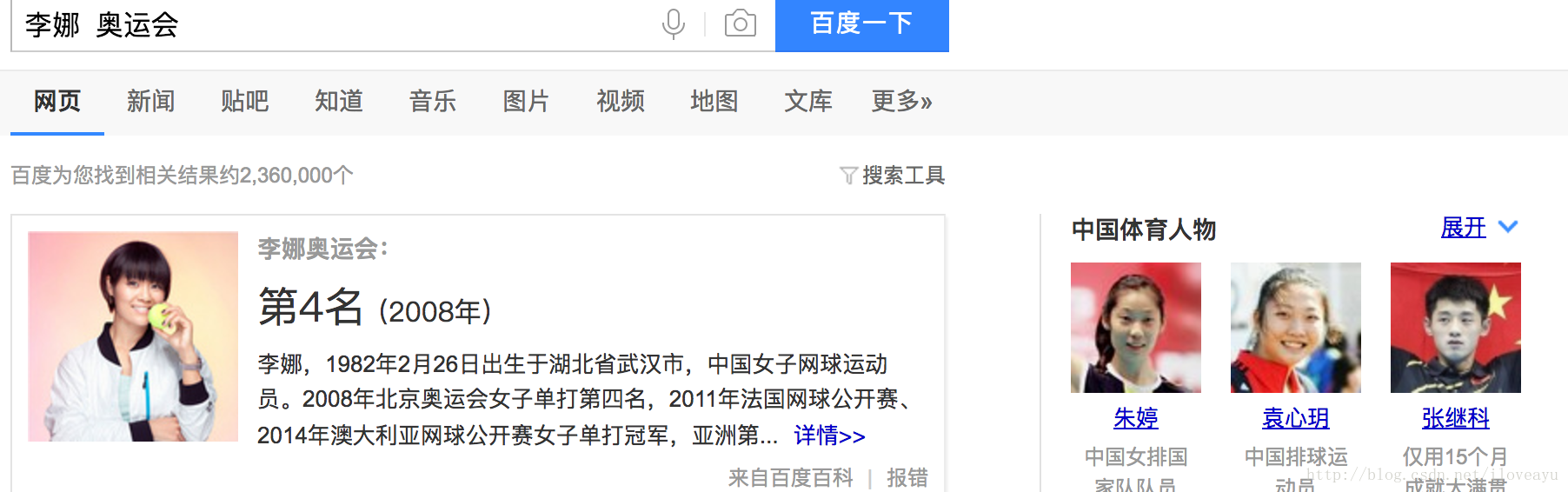
- 搜索李娜和奥运会,出现了李娜的奥运会名次,还有侧边栏的体育人物展现逻辑
- 优化搜索排序
智能问答(KB-QA)
- 知识推理
- 谓词逻辑和消解原理




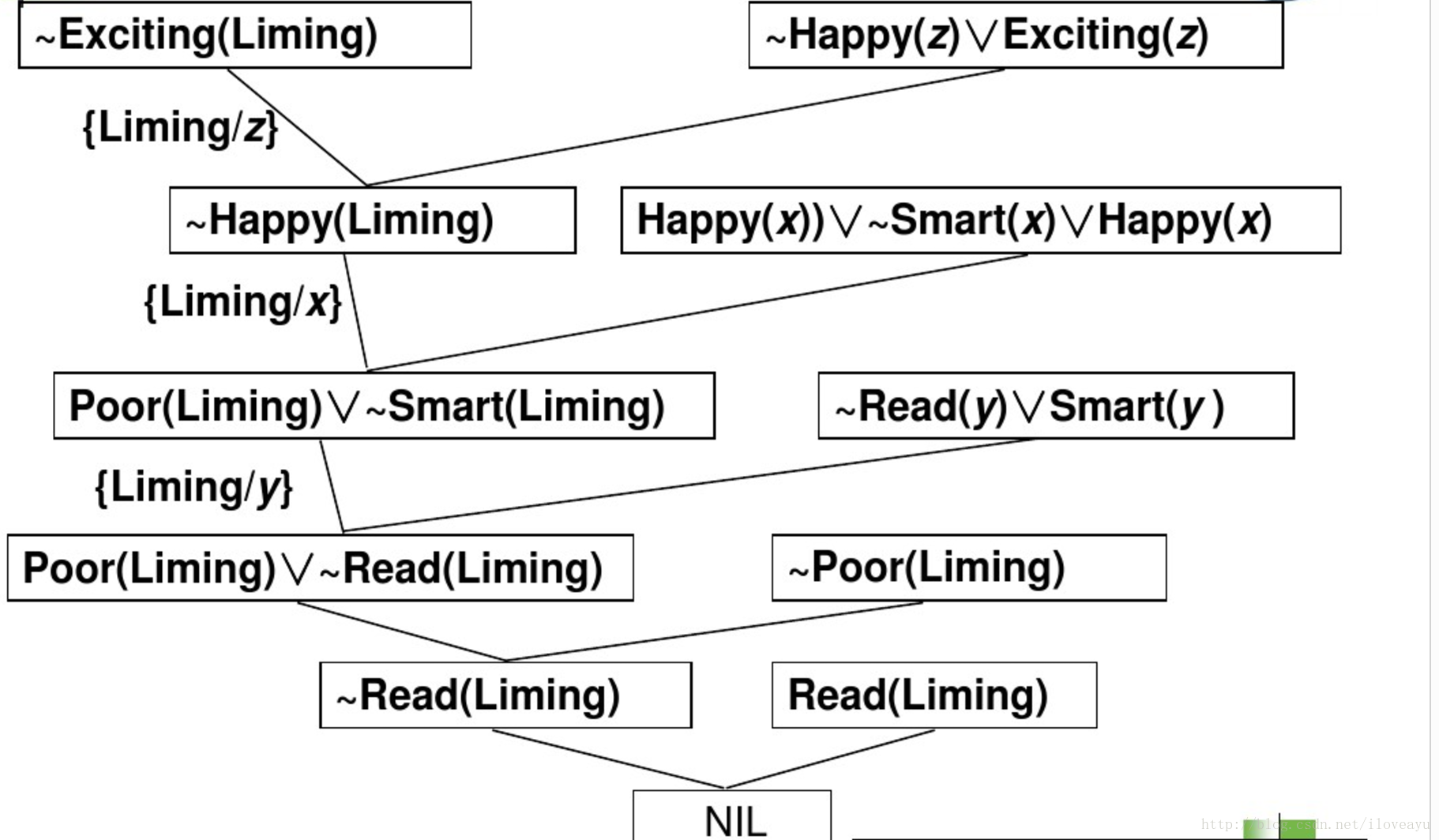
一系列推理以后,发现关于李明的假设没有推理出合理命题,最后得假设为假
![这里写图片描述])
- 谓词逻辑和消解原理
- 知识推理
金融领域
- 反欺诈
-
- 智能投顾
社交领域
- 兴趣推荐
- 用户聚类
- SimRank
-
S(U1,U2)=C|I(U1)||I(U2)|∑i=1|I(U1)|∑j=1|I(U2)|S(Ii(U1),Ij(U2))
-
- SimRank
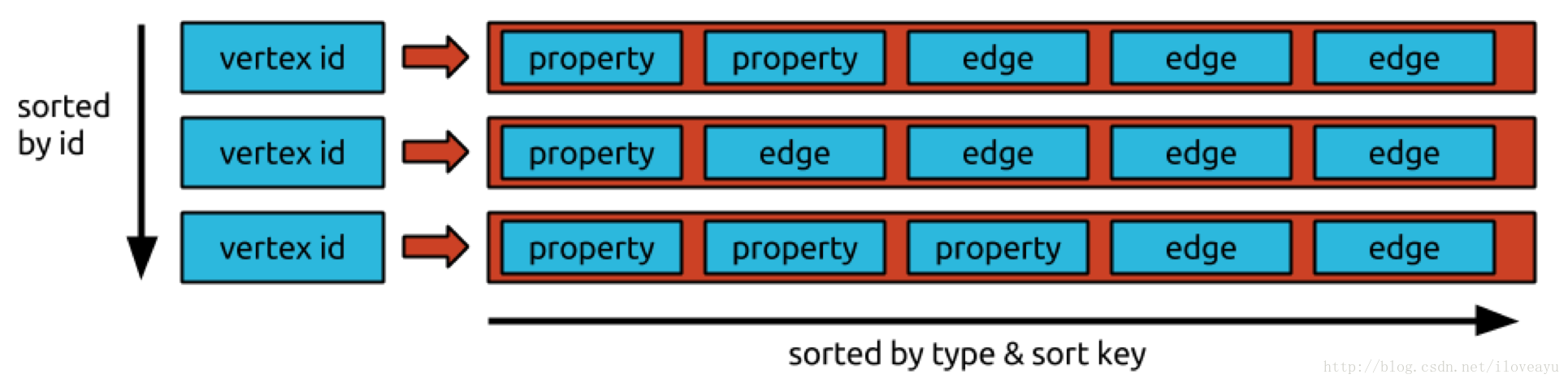
怎么存储知识图谱
rdf (语义网)
<?xml version="1.0"?> <RDF> <Description about="http://www.yahoo.com/"> <资源作者>Yahoo!公司</资源作者> <资源名称>Yahoo!首页</资源名称> </Description> </RDF>图数据库
neo4j
插入 CREATE (n:Person { name : 'Andres'}); 删除 MATCH (n:Person { name:'Andres' }) DETACH DELETE n; 查询 MATCH (a:Person { name:'Andres' })-[r]->(b:Person { name:'Taylor' }) RETURN type(r); CREATE CONSTRAINT ON (a:Person) ASSERT a.name IS UNIQUE; MATCH (a:Person),(b:Person) WHERE a.name = 'Node A' AND b.name = 'Node B' CREATE (a)-[r:Follow]->(b); MATCH (a:Person)-[r:Follow]->(b:Person) WHERE a.name = 'Andres' AND b.name = 'Taylor' DELETE r; MATCH (:Person { name:'Taylor' })-[r:Follow]->(Person) RETURN Person.name; 创建索引 CREATE INDEX ON :Person(name);titan
-
-

Transform g = TinkerGraphFactory.createTinkerGraph() g.V().in().outE().toList() g.V().in().outE().toList()g.v(1).map g.E.has(‘weight’, T.gt, 0.5f).outV.age.(_).transform{it+2} Filter e.outV.outE(e.label).filter{ElementHelper.haveEqualProperties(e,it)}.as('e').inV.filter{it==e.inV.next()}.back('e').except([e]) g.V[0..2].name g.v(1).outE.and(_().has('weight', T.gt, 0.4f), _().has('weight', T.lt, 0.8f)) g.V.as(‘x’).outE(‘knows’).inV.has(‘age’, T.gt, 30).back(‘x’).age sideEffect g.v(1).out.aggregate(x).next() g.V.groupBy{it}{it.out}.cap Method g.addVertex(100) g.addVertex(null,[name:"stephen"])
-
知识图谱的关键问题
信息抽取(Infomation Extraction)
- 什么是信息抽取
从自然语言文本中抽取指定类型的实体、关系、事件等事实信息,并形成结构化数据输出的文本处理技术
自然语言处理和信息抽取
实体链接(Entity Linking )
问题分类
- 实体识别
人名,地名,机构名,时间,日期,货币,百分比
子任务:实体边界识别和确定实体类别 开放域实体抽取
实体消歧
如何确定一个实体指称所指向的是真实世界的实体?

- bow方法计算相似度
score(q,ek)=cos(q.T,ek.T)=q.T,ek.T||q.T||||ek.T||
ê =argmaxscore(q,ek) - 加入其特征的分类
- 类别共现特征
- 文本相似度
- 实体本身流行度 P(e)
- 实体到指代的先验 P(s|e)
- 实体上下文的先验 P(c|e)
- 实体在网页链接上的社会化关系进行聚类消歧
- 基于实体链接的方法
- Pairwise
- Referent Graph
- bow方法计算相似度
方法分类
manual-Defining Domain
- 高精度的语义本体
- 高准确的提取算子
- 构建成本高
- 需要业务专家
Sime-automatic
- 本体类型上下位人工定义
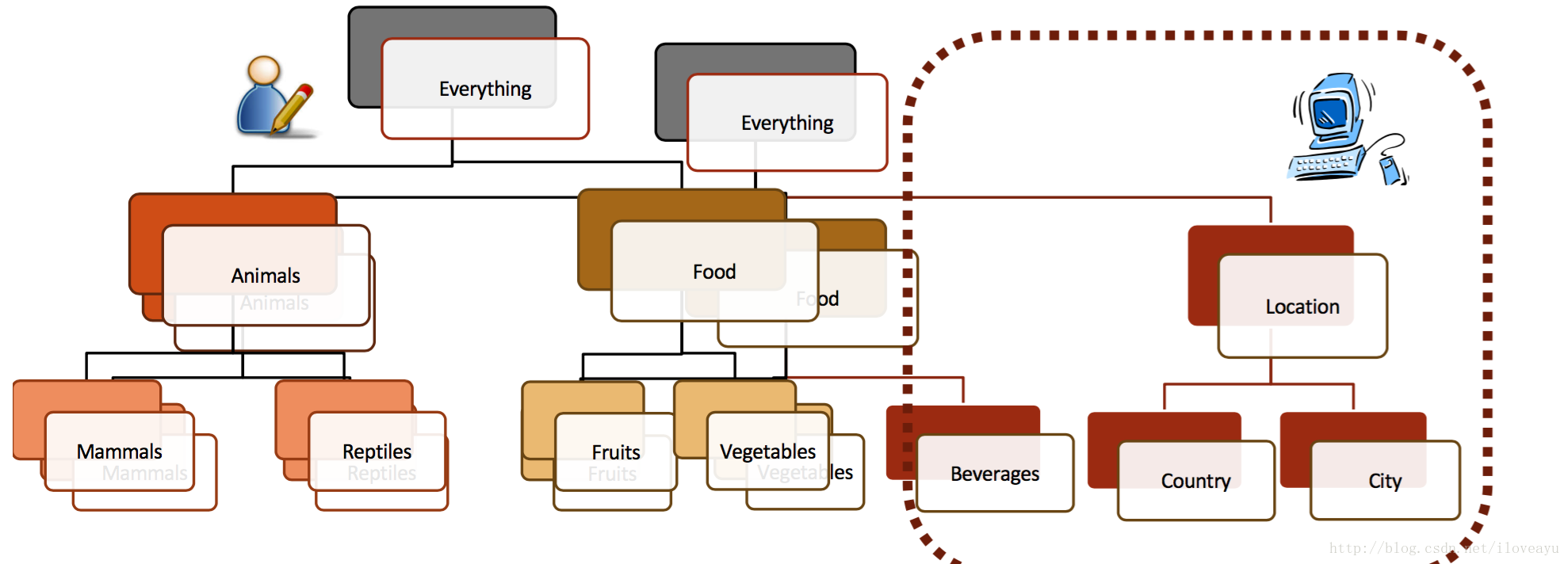
- SSL实现data上的label
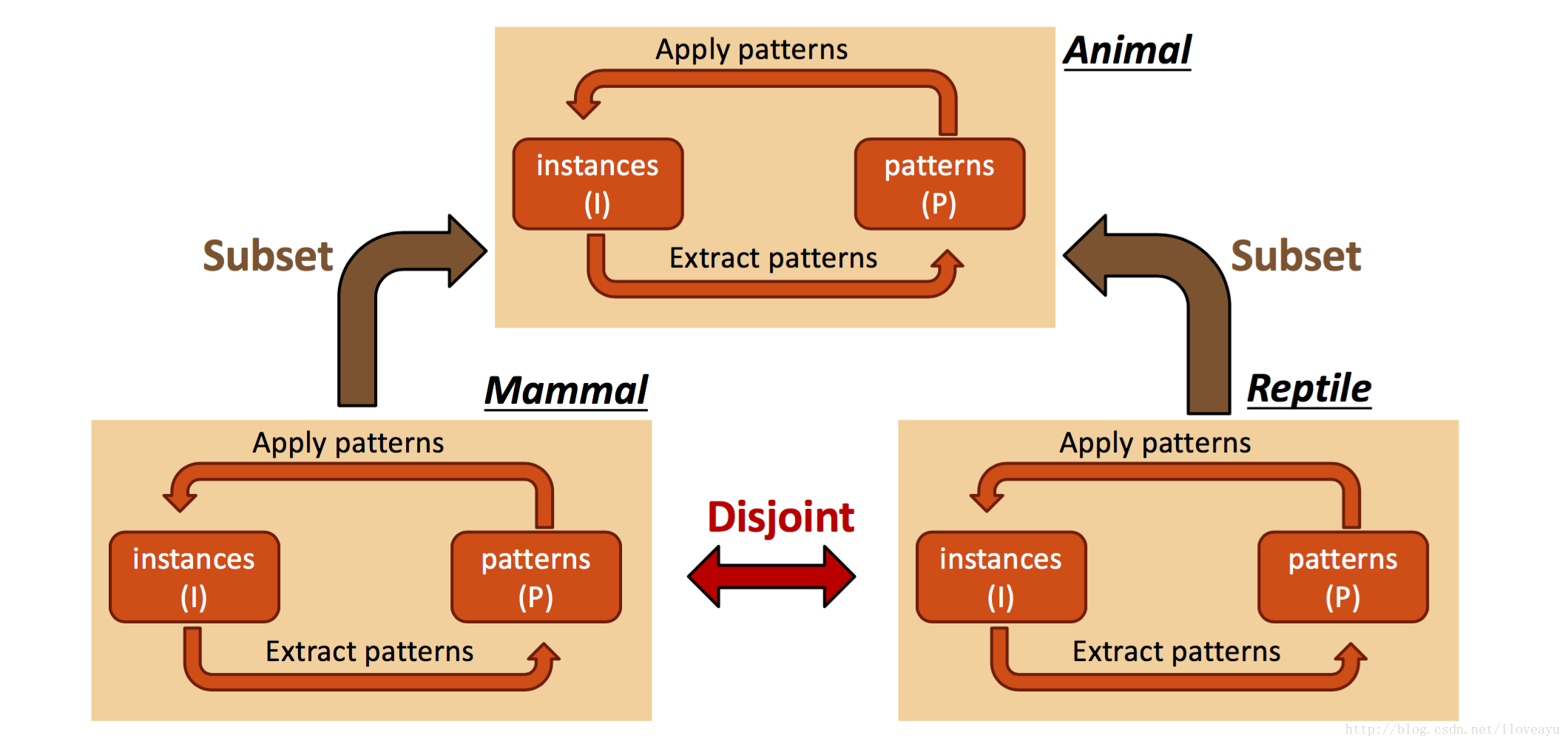
用已有类别很容易判断实体类型
- 可以从现有的语料库中抽取出关系
- 可以得到较为松散提取语法
Automatic
- 所有名词短语都是实体
- 所有动词短语都是属性
- 频率统计实现挖掘
web实体抽取系统构成
- Fetcher
把种子放到相关搜索引擎,把topN的相关页面爬取下来 - Extractor
针对单个页面,使用模板抽取候选实例 - Ranker
构建种子,网页,模板,候选的相关排序规则,计算候选的置信度
实体链接的评测方法
- 以指代项准的评测
Accuarcymicro=NumCorrectNumQueries - 以实体为标准的评测
Accuarcymicro=∑iNumEntitysNumCorrect(Ei)NumQueries(Ei)NumQueries
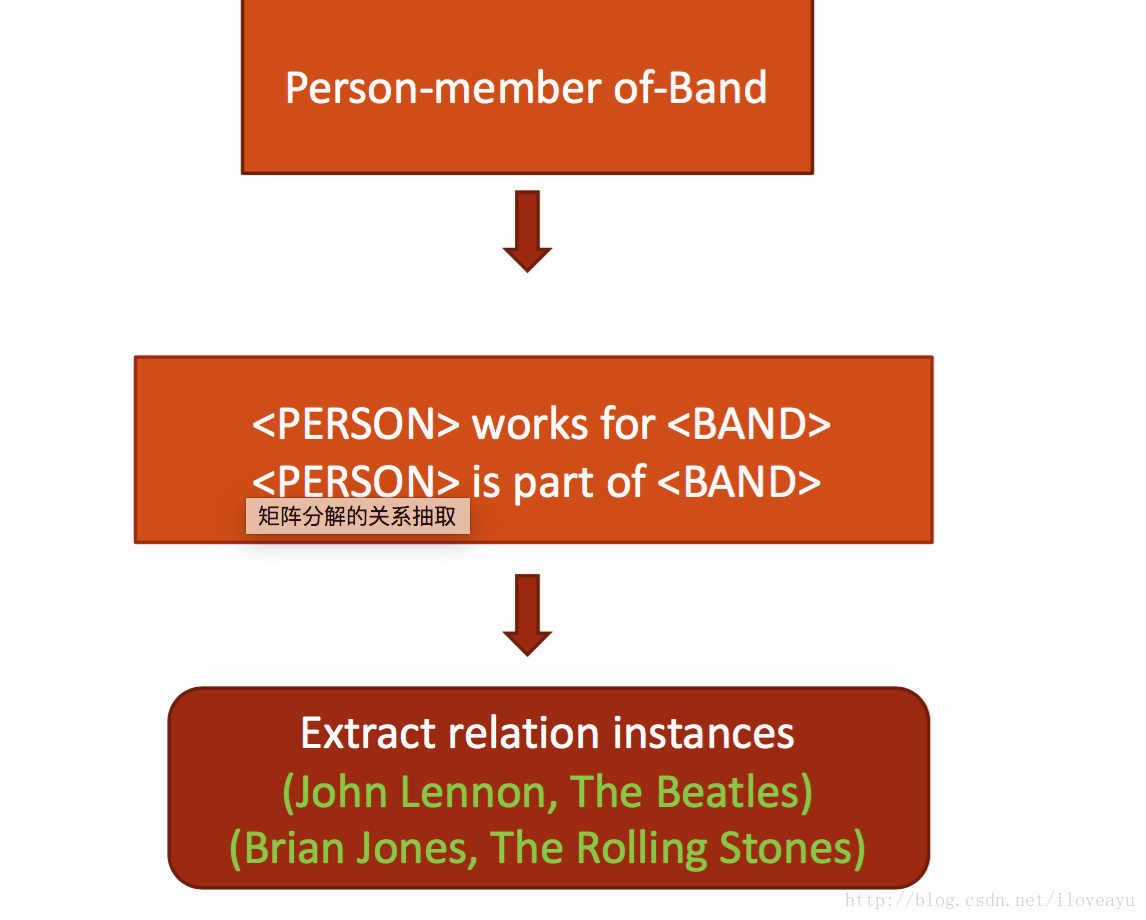
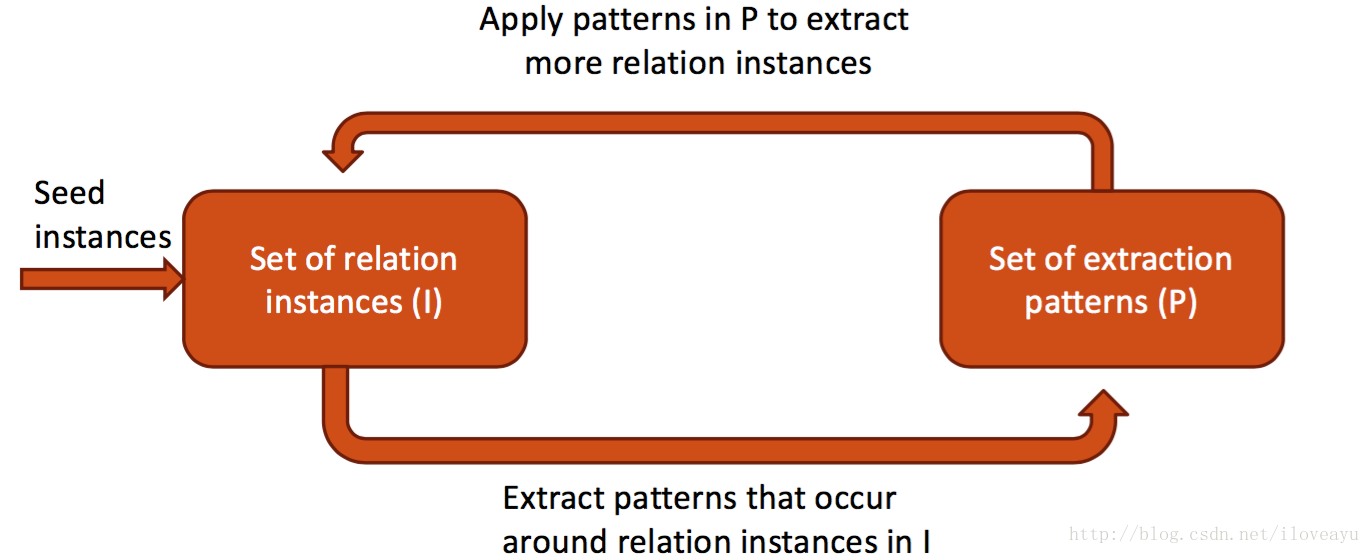
关系挖掘(Relation Extraction)
- 目标-自动识别由一对概念和联系这对概念的关系构成的相关三元组
bootstraping
- Distant Supervision
- Matrix Factorization
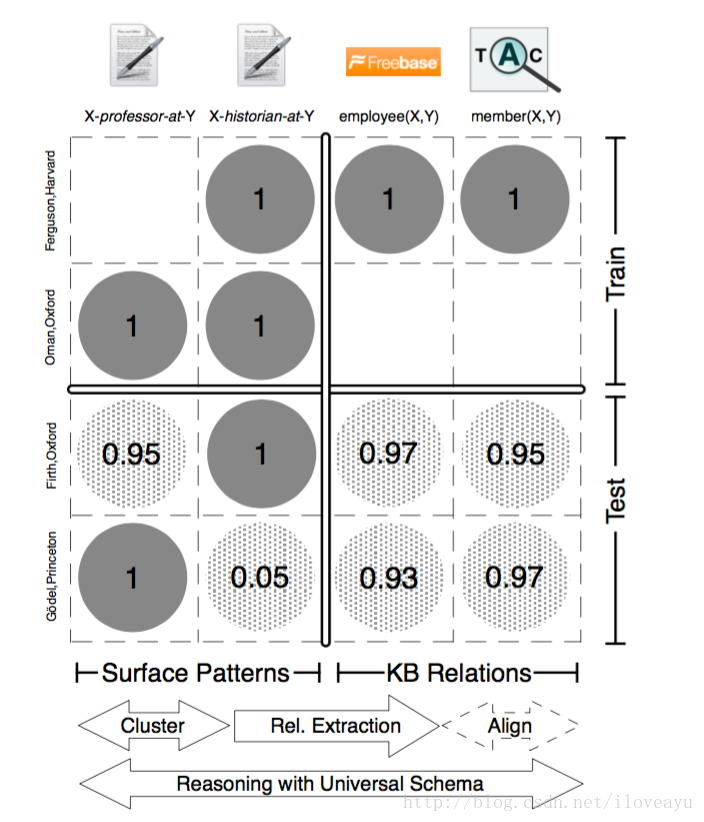
- Matrix Factorization
PRA
Predicate Logic
知识表示(RL)
- 目标-将研究对象的语义信息表示为低维稠密实值向量,从而可以表示研究对象语义相似度,是一种分布式表示
- RL的分布式表示的应用
- 相似度计算
- 知识图谱补全(linking prediction)
- 实体链接
- RL的优点:
- 不同于三元组的one-hot表示,可以提升计算效率
- 缓解数据稀疏
- 异质信息融合
RL方法
- 距离模型(structured embedding, SE)
argminr||RlhsriEv(eli)−RrhsriEv(eri)||1,whereei∈Rd,RlriRrri∈Rdxd
s.t.f(eli,ri,rri)<f(elj,ri,eri),∀(elj,ri,eri)∉xwherex∈triple_tuple
f(eli,ri,rri)<f(eli,ri,erj),∀(eli,ri,erj)∉xwherex∈triple_tuple 单层神经网络(Single Layer Model, SLM)
- A word
i
is then embedded in a
d=∑kdk dimensional space by concatenating all lookup-table outputs:
LTW1,...,WK(i)T=(LTW1(i1)T,...,LTWK(iK)T) - A classical TDNN layer performs a convolution on a given sequence
x(·)
, outputting another sequence
o(·)
whose value at time t is:
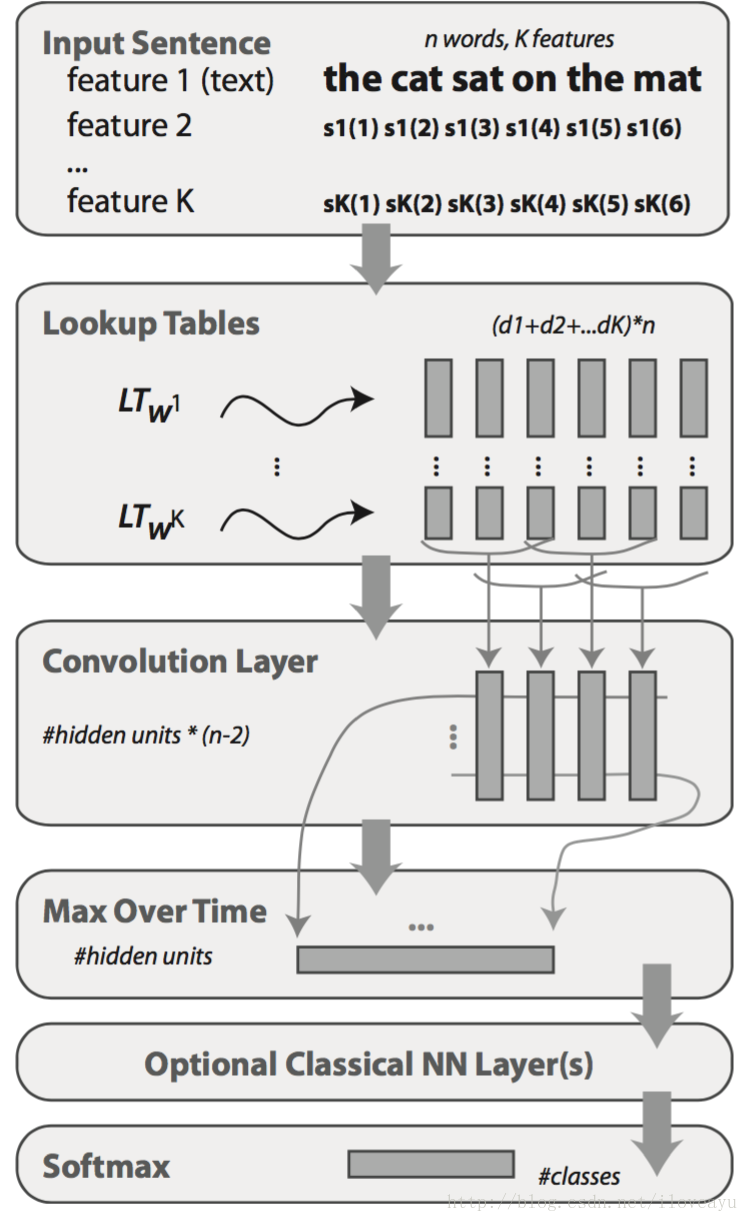
fr(h,t)=uTrg(Mr,llh+Mr,2lt)
- A word
i
is then embedded in a
语义匹配能量模型(SME sematic matching energy)
— 为每个三元组定义两种评分函数
fr(h,t)=(Mllh+M2lr+b1)T(M3Lt+M4lr+b2)
fr(h,t)=(Mllh⋅M2lr+b1)T(M3Lt⋅M4Lr+b2)双线性模型(Latent factor model, LFM)
fr(h,t)=lThMrlt张量神经网络模型
- Represent each entity as the average of its word vectors, allowing the sharing of statistical strength between the words describing each entity,word vectors which are trained on large unlabeled text.
- Train on relationships in WordNet and Freebase and evaluate on a heldout set of unseen relational triplets
- Define a set of parameters indexed by R for each relation’s scoring function.
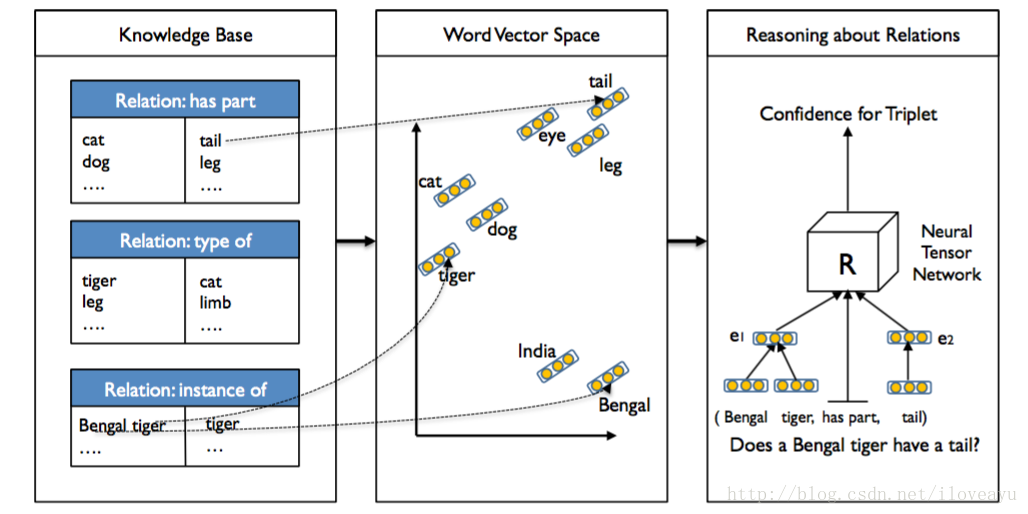
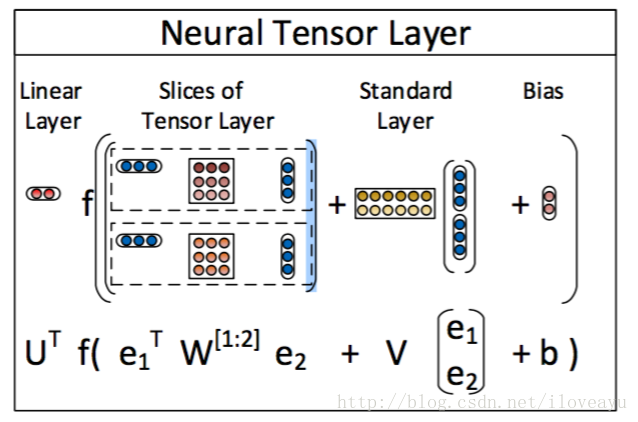
s.t.g(e1,R,e2)−uTRf(eT1W[1:k]Re2+VR[e1e2]+bR)wheref=tanh,W[1:k]R∈Rk,eT1W[1:k]Re2∈h∈RkVR∈Rkx2d,U∈Rk,bR∈Rk
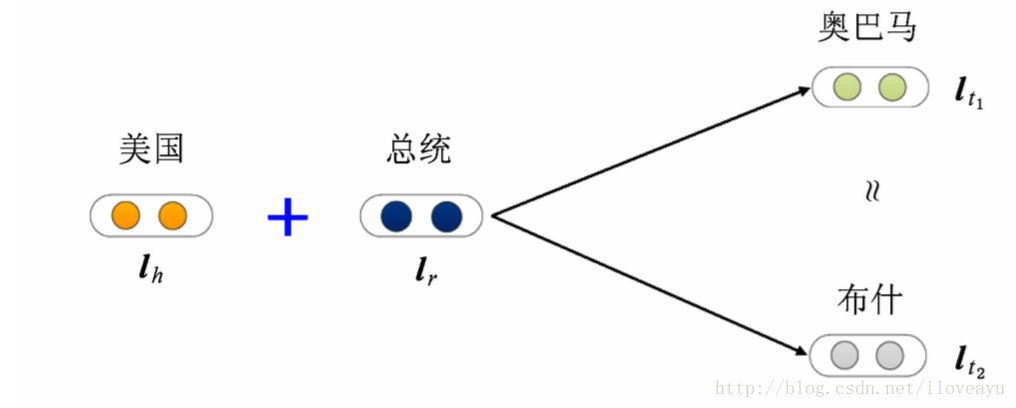
翻译模型
- transE
- 知识库的关系看做实体之间的某种平移向量
fr(h,t)=|lh+lr−lt|L1/L2 - 损失函数
∑(h,r,t)∈s∑(h′,r′,t′)∈s−max(0,fr(h,t)+γ−fr′(h′,t′))whereS−=(h′,l,t)∪(h,l′,t)∪(h,l,t′) 缺点
无法处理复杂关系(1-N,N-1)
transH
- 同时使用平移向量
l
和超平面法向量
wr 表示 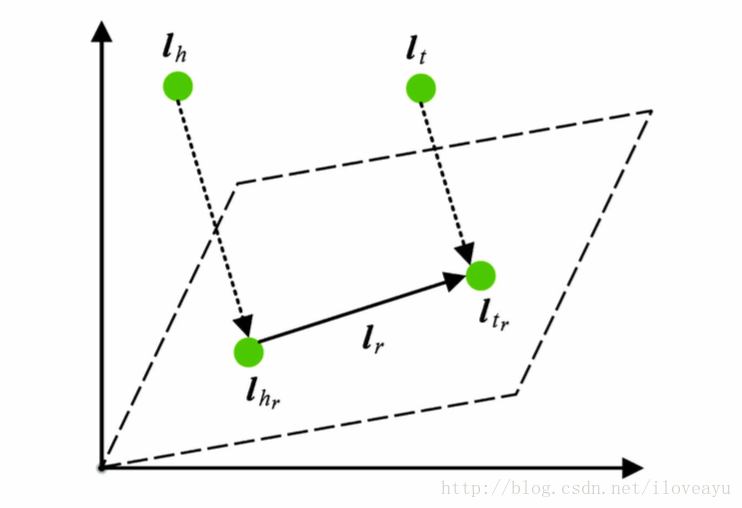
fr(h,t)=||lhr+lr−ltr||L1/L2s.t.lhr=lh−wTrLhWr,ltr=lt−wTrltWr- transR
- 假设关系和实体处于不同的语义空间中
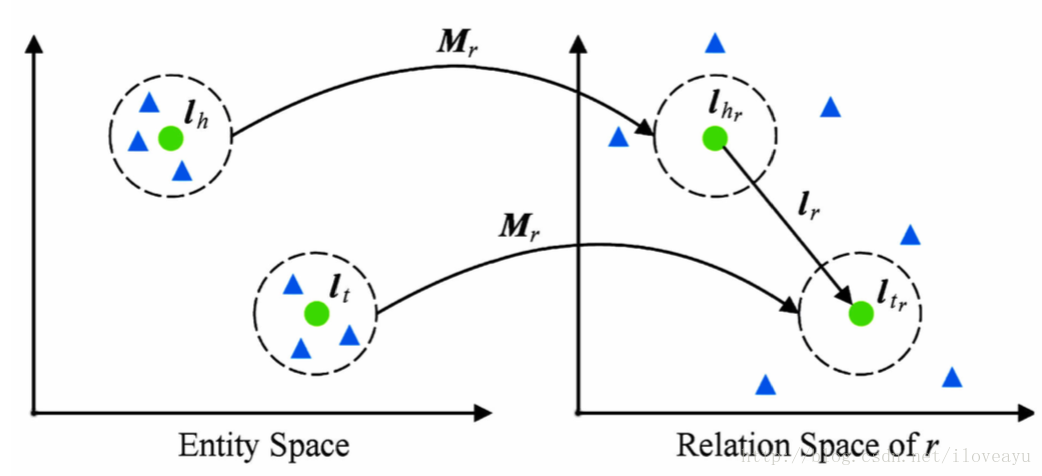
fr(h,t)=||lhr+lr−ltr||L1/L2s.t.lhr=lhMr,ltr=ltMr- TransD
- 头尾空间不共享投影矩阵,关系的头尾实体的类型和属性可能差异巨大
- 投影矩阵与实体和关系均相关
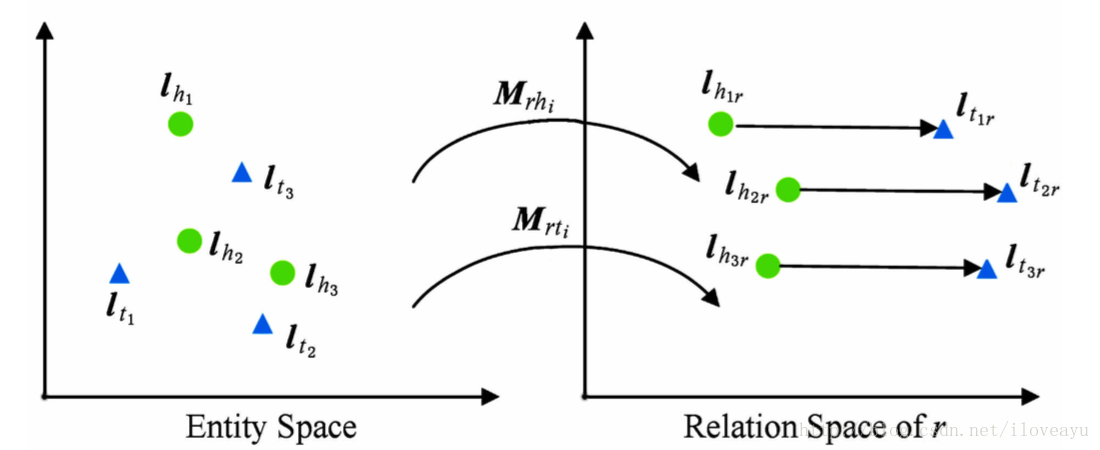
Mrh=lrplThp+Idxk
Mrt=lrplTtp+Idxk损失函数
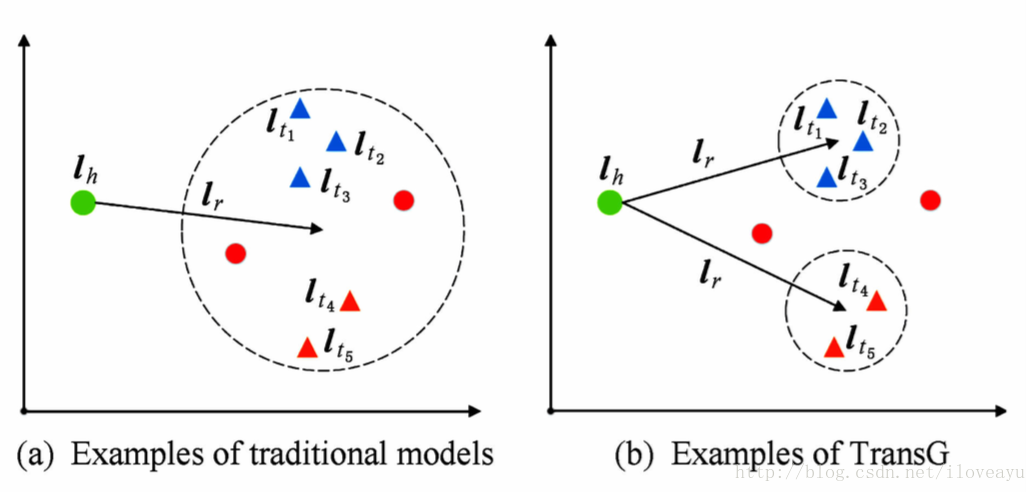
fr(h,t)=||lhMrh+lr−ltMrt||L1/L2- TransG
GMM描述模型头尾实体关系,一个关系对应多种语义,每种语义用一个高斯分布刻画
lt−lh|lr≈∑m=1Mπr,mN(μr,m,I)
KG2E
使用高斯分布表示实体和关系,高斯分布均值表示他们在语义kongjian中心位置,高斯分布协方差表示实体或者关系的不确定性。
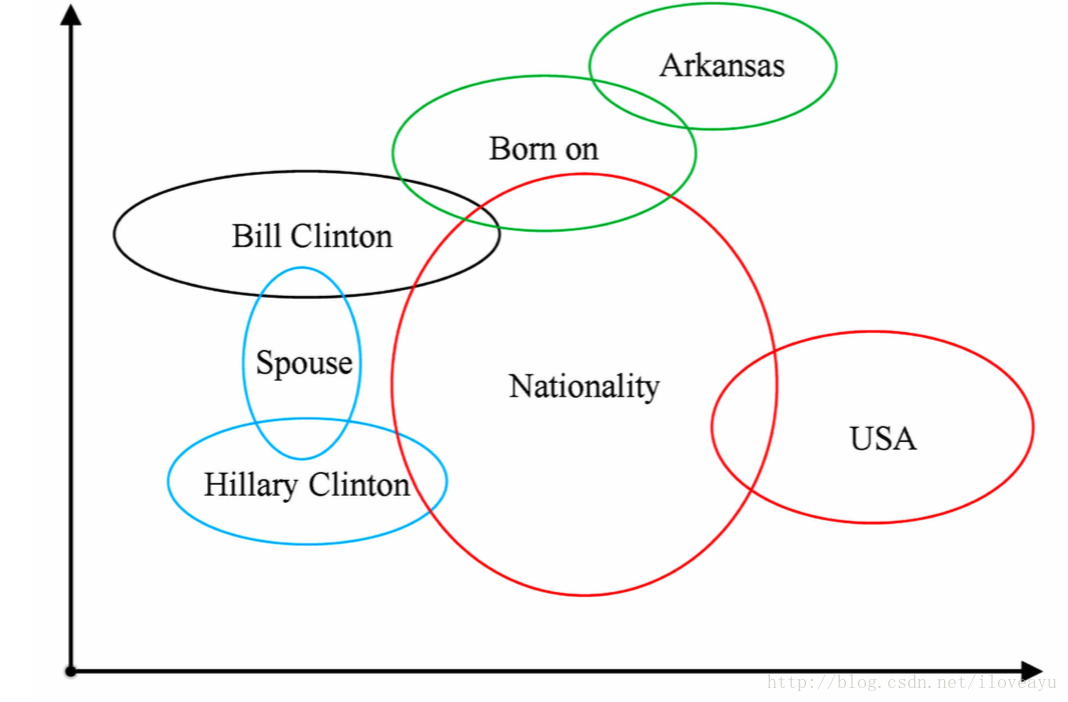
使用概率分布表示头尾关系
pe≈N(μh−μt,∑h+∑t)- 假设关系本身也满足一个分布
pr≈N(μr,∑r) - 使用相对熵定义距离度量
fr(h,t)=∫x∈RkeN(x;μr,∑r)N(s;μe,∑e)dx
- 距离模型(structured embedding, SE)
相关研究和应用
知识库
FreeBase
google(5.7亿实体,180亿关系)
Satori(MicrosoBing)
应用系统
TextRunner
http://dl.acm.org/citation.cfm?id=1614177
OpenIE
http://openie.allenai.org/#
NELL
http://openie.allenai.org/#
知识计算平台
WolframAlpha
10万亿个实体,各种type的知识和逻辑表示
Graph Search(Facebook)
知立方(搜狗)
最后
以上就是怡然发带最近收集整理的关于知识图谱相关介绍知识图谱概要的全部内容,更多相关知识图谱相关介绍知识图谱概要内容请搜索靠谱客的其他文章。








发表评论 取消回复