本文是在https://blog.csdn.net/acl_lihan/article/details/104076938的基础上进行了部分改动,加上了一点个人理解,原博客写的非常好,不妨一同查阅。
普通的Q-learning比policy gradient比较容易实现,但是在处理连续动作(比如方向盘要转动多少度)的时候就会显得比较吃力。
因为如果action是离散的几个动作,那就可以把这几个动作都代到Q-function去算Q-value。但是如果action是连续的,此时action就是一个vector,vector里面又都有对应的value,那就没办法穷举所有的action去算Q-value。
本文就介绍一个用来处理连续动作的算法Normalized Advantage Functions(NAF)
当然,最常见的处理方法还是不使用Q-learning而使用actor-critic
一、NAF算法
设计一个新的网络来解连续动作的最优化问题。
先给出概念如下,后面再讲具体的。
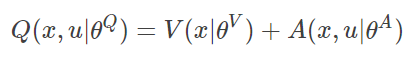 (公式3-1)
(公式3-1)
此时Q value 由状态值函数V与动作价值函数 A 相加而得。
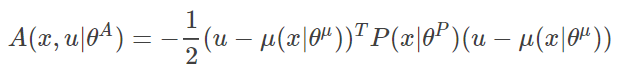 (公式3-2)
(公式3-2)
其中 x 表示状态State,u表示动作Action,θ 是对应的网络参数,A函数可以看成动作 u 在状态 x 下的优势。我们的目的就是要使网络输出的动作 u 所对应的Q值最大。

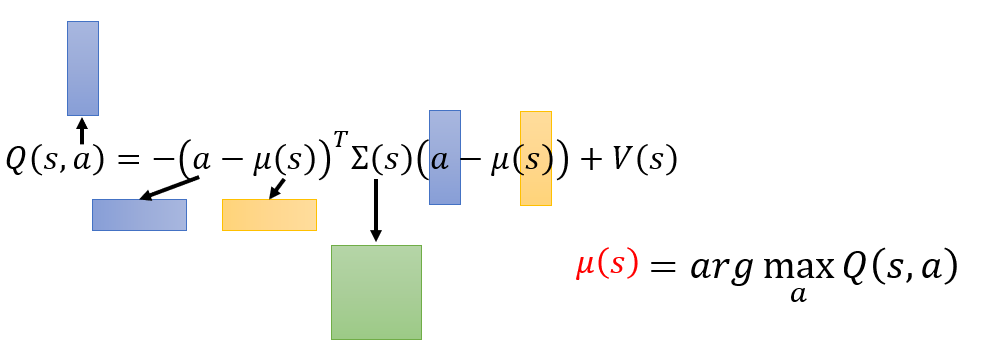

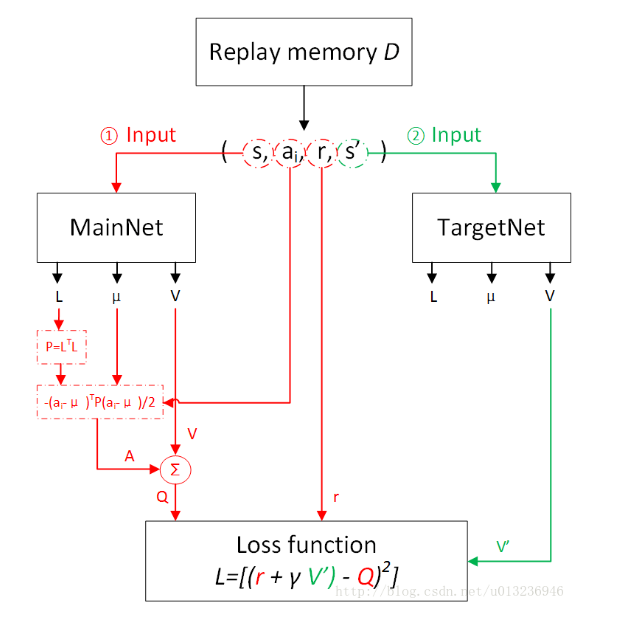
下图为NAF执行过程(图参考自https://blog.csdn.net/u013236946/article/details/73243310)
参考:
https://blog.csdn.net/acl_lihan/article/details/104076938
最后
以上就是标致含羞草最近收集整理的关于强化学习入门(六):Q-learning系列算法3:连续动作(NAF)一、NAF算法的全部内容,更多相关强化学习入门(六)内容请搜索靠谱客的其他文章。








发表评论 取消回复