文章目录
- 摘要
- 关键词
- 0 引言
- 1 空间连续型机器人动力学模型
- 1.1 场景假设
- (1) 环境假设
- (2) 模型假设
- 1.2 公式分析
- 2 空间连续型机器人滑模控制器
- 3 基于强化学习的滑模控制器
- 4 仿真校验
- 5 结论
摘要
【针对问题】空间主动碎片清除操作中连续型三臂节机器人系统跟踪
【提出方法】一种基于强化学习的自适应滑模控制算法(强化学习 + 滑模控制)
【具体内容】(1)基于数据驱动的建模方法,采用 BP 神经网络对三臂节连续型机械臂进行建
模;(2)神经网络作为预测模型指导强化学习实时调节所提出滑模控制器的控制参数,从而实现连续型机器人运动的实时跟踪控制。
【得出效果】高精度、更低的超调量和更短的调节时间
关键词
- 空间连续型机器人;
- 强化学习;
- 预测控制;
- 滑模控制;
- 轨迹跟踪;
0 引言
【问题背景】
(1)逐渐增多的空间碎片对在轨航天器构成了重大的威胁
→
rightarrow
→ 空间主动碎片清除技术的重要性;
(2)连续型机械臂具有占用空间小,柔软灵活等特点
→
rightarrow
→ 通过主动变形在有限的工作空间内完成复杂的动作
→
rightarrow
→ 呈现出高度非线性的动力学特征
→
rightarrow
→ 传统建模方法在参数摄动、外部干扰等不确定因素下性能表现差
【前人研究】
(1)基于神经网络的建模及控制方法:
| 学者 | 工作 | 效果 |
|---|---|---|
| Grassmann R,Lai J | 前馈神经网络分别拟合连续型机械臂的正逆运动学模型 | 较高的精度 |
| Thuruthel | 前馈神经网络、递归神经网络学习连续型机械臂的动力学模型,用以拟合机械臂的动态响应并进行评估,并据此构建开环控制策略 | 大量的监督数据;限制了机械臂的运动轨迹 |
不足之处:由于拟合模型的精度依赖于监督数据的完备性,导致模型仍不可避免的会受到过拟合问题的影响 + 开环控制策略进一步限制运动轨迹
(2)模型预测控制方法:
| 学者 | 工作 | 效果 |
|---|---|---|
| Li | 提出了一种机器人运动规划网络 MPC-MPNet;网络生成可行路径 + 模型预测控制实现避障 | 执行正向路径扩展,不适合在动态障碍物环境中进行实时规划 |
| Ouyang | 一种具有指数加权预测范围的模型预测控制器;建立接触过程中机器人驱动空间和变形空间的线性近似模型,来实现在接触力作用下的连续型机器人主动变形控制 | 依赖接触变形近似模型的精度 |
| Tang | 一种迭代学习模型预测控制方法;通过伪刚体模型对执行器的变形进行初步预测,利用迭代学习不断降低模型误差,最后由模型预测控制实现机器人变形 | 适用于具有一定刚度的软管式连续型机器人,对弯曲特性较明显的表现较差 |
不足之处:容易局部最优;不具有外部探索的能力
→
rightarrow
→ 无法对外部的反馈信息做进一步处理;不能拓展到大型机器人中
(3)将深度强化学习引入模型预测控制中滚动优化的奖励策略
| 学者 | 工作 | 效果 |
|---|---|---|
| Frazelle | 采用 Actor-Critic 框架的策略搜索方法实现运动学控制 | 对状态和动作进行了离散化 → rightarrow → 造成了一些损失;难以扩展到更复杂的环境中 |
| Shin | 采用神经网络学习视觉空间下软组织受力时的动力学模型 → rightarrow → 预测其动态响应 → rightarrow → 基于模型预测控制的强化学习来对机械臂进行操纵(针对手术机器人与软体组织接触的问题) | 离散数据影响;演示数据影响 |
| Thuruthel | 基于模型的连续型机器人机械手闭环预测控制的策略学习算法;采用递归神经网络拟合前向模型 + 采用强化学习进行轨迹优化 + 推导出闭环策略 | 随机打靶法进行轨迹采样的方法需要大量的数据,且不具有完备性,无法在大范围跟踪运动控制中获得合理解 |
【本文工作】
- 提出一种数据驱动的多层前馈神经网络模型;
- 设计了变结构控制器;
- 在双延迟深度确定性策略梯度算法的基础上,引入模型预测控制原理;
1 空间连续型机器人动力学模型
1.1 场景假设
(1) 环境假设
- 机器人已被送至碎片附近;
- 位姿调整使得机械臂进入可以捕获碎片的范围内;
- 末端装有用于实时监测的传感器 + 执行器;
(2) 模型假设
- 节盘与驱动线之间光滑无摩擦;
- 柔性支撑处无外部碰撞
- 各臂节变形服从等曲率假设
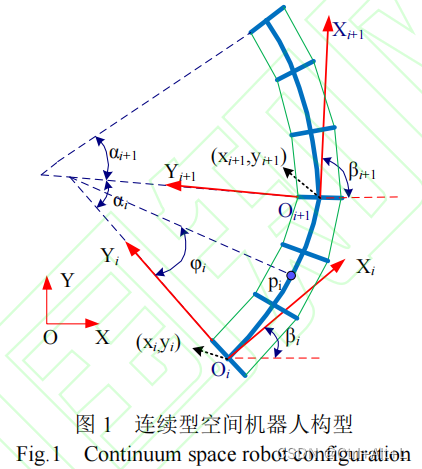
1.2 公式分析
广义坐标描述机器人运动:
q
=
[
α
1
,
α
2
,
α
3
]
T
pmb{q}=[alpha_{1},alpha_{2},alpha_{3}]^{T}
qq=[α1,α2,α3]T
当前臂节
i
i
i 对应的局部坐标系相对于全局坐标系的转角:
β
i
beta_{i}
βi
当前臂节
i
i
i 对应的局部坐标系相对于全局坐标系的坐标:
(
x
i
,
y
i
)
(x_{i},y_{i})
(xi,yi)
当前臂节
i
i
i 的弯曲形变角度:
α
i
alpha_{i}
αi
- 机器人系统动能
T
T
T:
T = T d + T s = 1 2 q ˙ T M q ˙ (1) T=T^{d}+T^{s}=frac{1}{2} dot{q}^{T}Mdot{q} tag{1} T=Td+Ts=21q˙TMq˙(1)
T d → T^{d} rightarrow Td→ 节盘动能;
T s → T^{s} rightarrow Ts→ 柔性支撑动能;
M → pmb{M} rightarrow MM→ 机器人系统的质量阵; - 连续型机器人系统弹性力
Q
e
pmb{Q_{e}}
QeQe对应的虚功:
δ W e = − ∫ 0 l ∫ A E ϵ δ ϵ d A d s = − Q e T δ q (2) delta W_{e}=-int_{0}^{l} int_{A} Eepsilon delta epsilon dAds=-Q_{e}^{T}delta q tag{2} δWe=−∫0l∫AEϵδϵdAds=−QeTδq(2)
E → E rightarrow E→ 柔性支撑的弹性模量;
A → A rightarrow A→ 截面面积;
l → l rightarrow l→ 长度;
ϵ → epsilon rightarrow ϵ→ 中性层的弯曲应变;
s → s rightarrow s→ 局部坐标系下弹性力作用点到原点的弧长; - 机器人系统驱动力
Q
a
pmb{Q_{a}}
QaQa对应的虚功:
δ W a = Q a T δ q (3) delta W_{a}=Q_{a}^{T}delta q tag{3} δWa=QaTδq(3) - 系统的动力学方程:
M q ¨ = − Q e + Q a + Q v (4) Mddot{q} = -Q_{e}+Q_{a}+Q_{v} tag{4} Mq¨=−Qe+Qa+Qv(4)
其中: Q v = − M ˙ q ˙ + ( ∂ T ∂ q ) T Q_{v}=-dot{M}dot{q}+(frac{partial T}{partial q})^{T} Qv=−M˙q˙+(∂q∂T)T -
f
(
t
)
f(t)
f(t)表征外部干扰和建模误差的列向量:
f ( t ) = d ( t ) + △ M 0 q ¨ + △ C 0 q f(t)=d(t)+triangle M_{0}ddot{q}+triangle C_{0}q f(t)=d(t)+△M0q¨+△C0q
2 空间连续型机器人滑模控制器


(对滑模控制不了解呜呜呜。。。
3 基于强化学习的滑模控制器
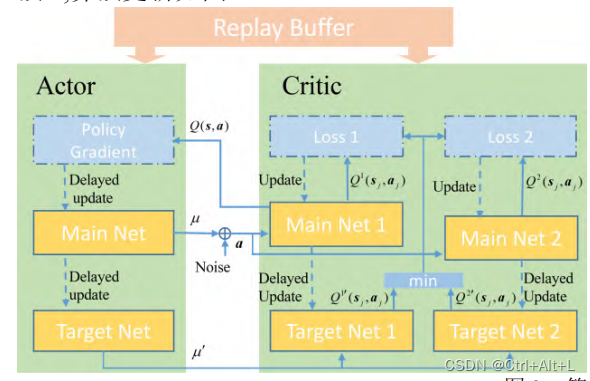
TD3介绍:
- 两个由 θ Q k ( k = 1 , 2 ) theta^{Q_{k}}(k=1,2) θQk(k=1,2) 参数化的 Critic 网络 Q ( s , a ∣ θ Q k ) Q(s,a|theta^{Q_{k}}) Q(s,a∣θQk);
- 及一个由 θ μ theta^{mu} θμ 参数化的 Actor 网络 μ ( s ∣ θ μ ) mu(s|theta^{mu}) μ(s∣θμ);
- 惩罚系数 ρ rho ρ 通过滑动平均法更新目标网络参数: θ ′ = ρ θ + ( 1 − ρ ) θ ′ theta^{prime}=rhotheta+(1-rho)theta^{prime} θ′=ρθ+(1−ρ)θ′
- 始终选取两个 Critic 网络中的最小值,进行延迟策略更新;
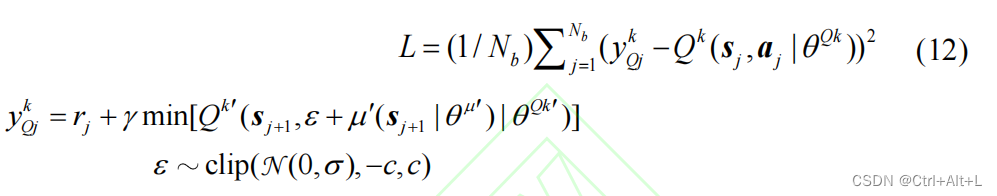
- 引入随机噪声来进一步增加智能体探索环境的能力

产生问题:
- 传统强化学习的动作策略无法在短期内表现出明显的奖励差异
- 每个时间步,不适合频繁调用此类非线性系统动力学方程,容易造成计算负担
解决问题:引入了数据驱动的学习方法
- 计算量小;
- 不需要精确的动力学模型信息;
- 可针对不同的环境采用对应的数据进行训练;
- 具有良好的环境实时交互和迁移能力;
- 适用于仿真计算及地面实验;
本文选用
δ
delta
δ和
k
k
k作为强化学习的自适应优化参数。
4 仿真校验
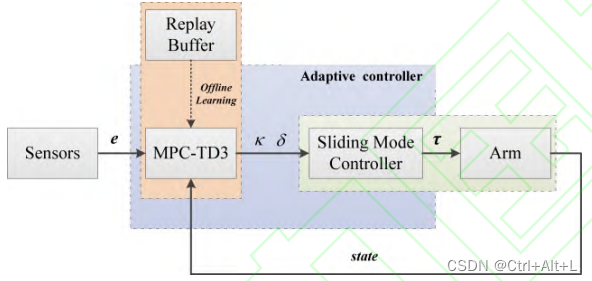
过度冗余的网络输入会导致网络输出对系统状态变化不敏感,降低学习网络的性能;
而关键输入信息的缺失则导致网络不能有效地反映系统动态变化。
动作向量
→
rightarrow
→ 滑模控制器的控制参数
δ
delta
δ和
K
K
K;
状态向量
s
s
s
→
rightarrow
→ 信息包含各节角度、角速度、角度跟踪误差、角速度跟踪误差及下一时刻预期上述信息,来合理地表征机械臂系统与目标轨迹的动态信息;
奖励函数
r
r
r
→
rightarrow
→
r
=
d
e
+
h
g
o
a
l
r=d_{e}+h_{goal}
r=de+hgoal;
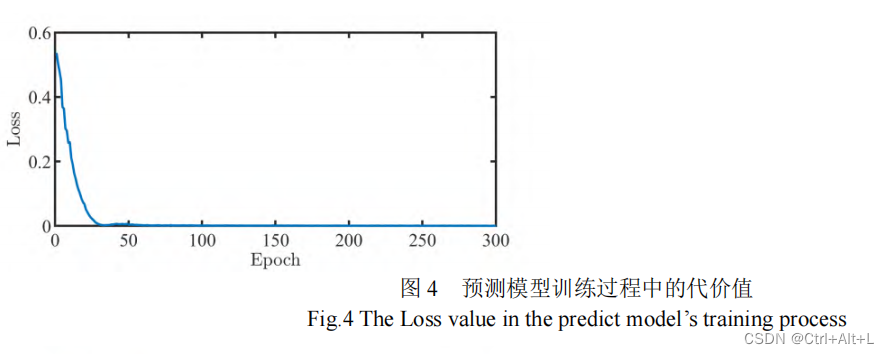
设计的预测模型训练过程中代价值快速下降,经 70 代训练后已趋于稳定。
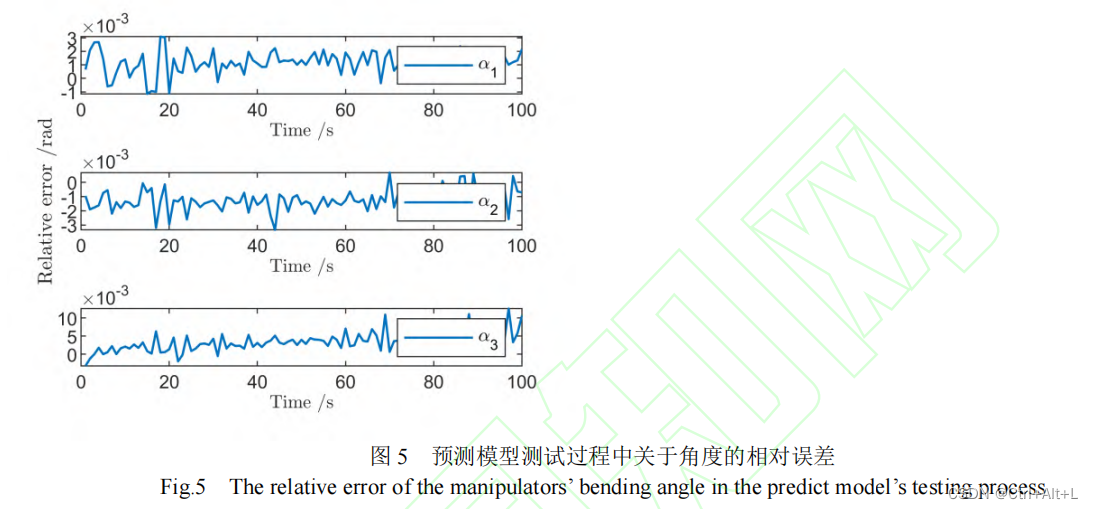
所设计的基于 BP 网络的预测模型可以将拟合的各臂节弯曲角度的相对误差保持在
+
/
−
1
%
+/-1%
+/−1% 以内
验证了该预测模型的准确性
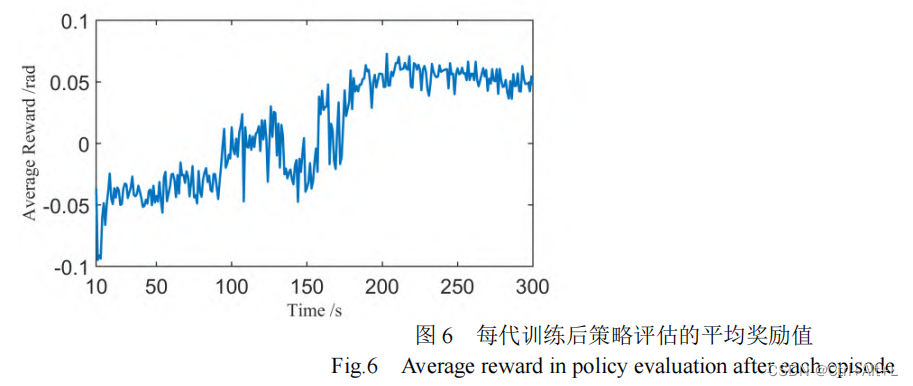
- 每代评估时的平均奖励值在逐步提升,策略在逐步优化
- 由于 f pmb{f} ff的影响,在每代中的每个 step 对应的奖励值尤其是取得额外奖励的时间会存在差异,导致平均奖励值会存在小幅震荡
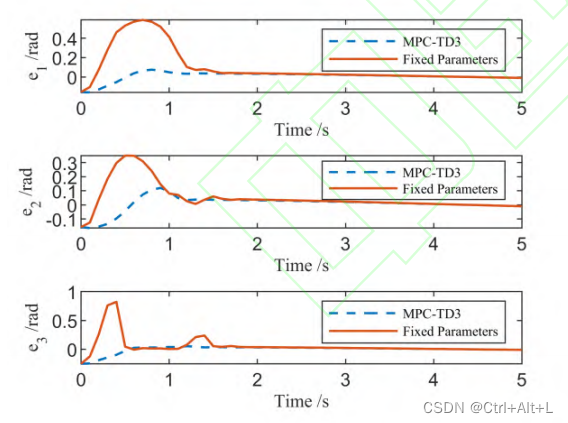
约于 1.7 s 时便达到稳定跟踪状态
本文提出的控制器明显具有更低的超调量和更短的调节时间
本文算法对外部扰动和建模误差具有更强的抑制能力
5 结论
最后
以上就是失眠豌豆最近收集整理的关于【论文笔记】基于强化学习的连续型机械臂自适应跟踪控制摘要0 引言1 空间连续型机器人动力学模型2 空间连续型机器人滑模控制器3 基于强化学习的滑模控制器4 仿真校验5 结论的全部内容,更多相关【论文笔记】基于强化学习的连续型机械臂自适应跟踪控制摘要0内容请搜索靠谱客的其他文章。








发表评论 取消回复