使用CDH提供的 Cloudera Search创建二级索引:
近实时索引常使用Apache Flume或Apache Kafka来不断的摄取并索引数据。
Lily HBase NRT Indexer既可以用在近实时索引又可用在批索引。
Lily HBase NRT Indexer服务是灵活的、可扩展的、容错的、具有事物性、近实时的系统,解决更新HBase数据的时候,同步更新索引数据。可以使用它为HBase构建二级索引。
它使用SolrCloud来索引存储在HBase中的数据,当HBase执行插入、更新、删除操作的时候,利用标准HBase复制功能,索引器保证SolrCloud中的索引数据和HBase中的数据一致。
索引器支持自定义,使其可以按照应用相关的规则对存储在HBase的数据抽取、转换,并插入Solr中。
尽可能多地在不同的主机上运行Lily HBase NRT Indexer,因为创建索引的任务被共享给所有的索引器,可以通过更多的索引器扩展构建索引的能力,建议一个HBase RegionServer一个Indexer,不过在高可用系统中,最少应该开启5个Indexer。
1准备工作
开启集群范围内的HBase复制功能
Cloudera Manager:
1)依次操作HBase service > Configuration > Category > Backup
2)勾选Enable Replication(启用复制)
3)设置Replication Source Ratio(复制来源比例)为1
4)设置Replication Batch Size(复制批大小)为1000
5)点击Save Changes(保存变更)
6)重启HBase集群
添加Lily HBase NRT Indexer服务
在Cloudera Manager中,Lily HBase NRT Indexer服务被称为Key-Value Store Indexer,在服务角色类型中被称为Lily HBase Indexer,如果在部署集群的时候没有将这个服务加进来,那么使用Cloudera Manager将其加进来就可以了。
为Lily HBase NRT Indexer配置HBase依赖
在启动Lily HBase NRT Indexer服务之前,必须使用目标HBase集群使用的ZooKeeper的位置配置各个服务,如果使用Cloudera Manager管理集群,那么当你设置HBase Service的依赖时这一步会自动完成(Key-Value Store Indexer service > Configuration)
启动Lily HBase NRT Indexer
如果使用Cloudera Manager管理集群,就可以使用Cloudera Manager启动服务了,官网文档也提供了不使用Cloudera Manager的情况下如何启动服务。
2使用Lily HBase NRT Indexer服务
2.1启用HBase列族复制功能
对于每一个已存在的表,为表的每个列族设置REPLICATION_SCOPE,如:
hbase shell
hbase shell> disable 'sample_table'
hbase shell> alter 'sample_table', {NAME => 'columnfamily1', REPLICATION_SCOPE => 1}
hbase shell> enable 'sample_table'
对于每一个新表,为表的每个列族设置REPLICATION_SCOPE:
hbase shell
hbase shell> create 'test_table', {NAME => 'testcolumnfamily', REPLICATION_SCOPE => 1}
2.2在Cloudera Search中创建一个聚集
搜索用的聚集必须具有Solr模式,适配被索引的HBase列族和列。我们先看看包括所有HBase列族和列的Solr模式。例如,使用下面的命令创建:
solrctl instancedir --generate $HOME/hbase_collection_config
## Edit $HOME/hbase_collection_config/conf/schema.xml as needed ##
## If you are using Sentry for authorization, copy solrconfig.xml.secure to solrconfig.xml as follows: ##
## cp $HOME/hbase_collection_config/conf/solrconfig.xml.secure $HOME/hbase_collection_config/conf/solrconfig.xml ##
solrctl instancedir --create hbase_collection_config $HOME/hbase_collection_config
solrctl collection --create hbase_collection -s -c hbase_collection_config
2.3创建Lily HBase Indexer配置文件
使用hbase-indexer命令行工具创建单独的Lily HBase Indexer,一般地为每一个HBase表配备一个Lily HBase Indexer配置文件。Lily HBase Indexer配置文件是一个XML文件,例如morphline-hbase-mapper.xml。每个Lily HBase Indexer配置文件都涉及到MorphlineResultToSolrMapper的实现,并指向Morphline配置文件的位置,例如下面的morphline-hbase-mapper.xml。
我们一般使用Cloudera Manager来管理集群,所以设置morphlineFile为morphlines.conf相对路径。如果不使用Cloudera Manager来管理集群,那么设置morphlineFile为Lily HBase Indexer主机上的morphlines.conf文件绝对路径。要确保这个文件可被HBase系统读取。
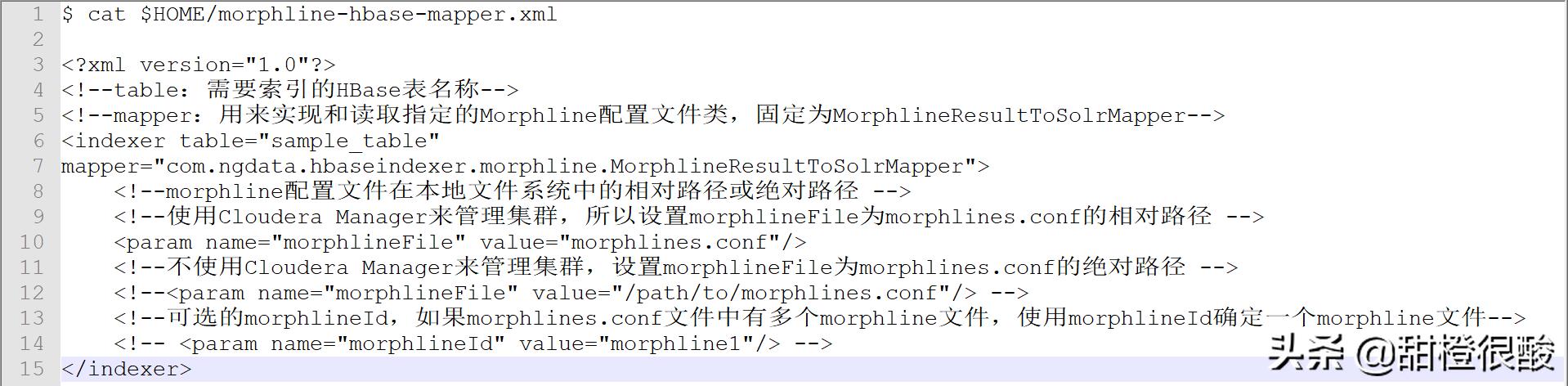
Lily HBase Indexer配置文件英文说明见:https://github.com/NGDATA/hbase-indexer/wiki/Indexer-configuration#table
最基本的配置文件只需要一个表名和一个字段。
全局的索引属性
顶级元素的属性如下:
table
需要索引的HBase表名。
mapping-type
这个属性可能有两个值:row, 或column。这个属性指明是基于行还是列做二级索引。
基于行做索引是将HBase表中的一行作为单个solr文档的输入。这种索引方式用于每一行都代表一个独立实体的情形。这是,默认的mapping-type配置值。
基于列做索引是将HBase表中的每个Cell作为单个solr文档的输入。这种索引方式用于,例如,一个用户的所有信息都存储在为一行,并且每一个信息存储在一个Cell中。
read-row
这个属性有两个值dynamic(默认的设置),或never。
只有当基于行做索引时,这个属性才是重要的。它指明索引器是否应该重新读取HBase数据以便执行索引。
当设置为dynamic时,如果一行的一部分数据被更新了,索引器将从这一行中读取必要的数据。在dynamic模式下,如果所有待索引数据都包含在行更新中,那么这行不会被重新读取。
如果设置为never,永远都不会重新读取一行。
mapper
允许用户使用自定义的mapper类,这个mapper类会根据HBase结果对象创建一个solr文档。自定义的mapper类必须实现com.ngdata.hbaseindexer.parse.ResultToSolrMapper接口。
默认地使用内建的com.ngdata.hbaseindexer.parse.DefaultResultToSolrMapper
unique-key-formatter
指定Solr中使用的文档标识符字段的名称。默认是“id”。
row-field
指定用于存储HBase行键的Solr字段的名称。这个属性仅在基于列索引时才起作用。为了使索引器能够从索引中删除单行的所有文档,它需要能够在Solr中找到该行的所有文档。在索引器定义中填充此属性时,它的值将用作Solr中字段的名称以存储编码的行键。默认情况下,此属性为空,表示行键未存储在Solr中。 这样做的结果是删除HBase中的完整行或完整列族不会删除Solr中的索引文档。
column-family-field
用于存储HBase列族名称的Solr字段名称。详见row-field属性。默认为空。
table-name-field
指定Solr字段的名称,该字段用于存储HBase表名,默认为空,因此除非在索引器配置中显式设置此属性,否则不会存储HBase表名。
用于索引器定义的元素
field元素定义要在Solr中索引的单个字段,以及从HBase获取和解释其内容的位置。 索引器配置中通常会列出一个或多个字段 - 每个字段用于存储每个Solr字段。
field元素有四个属性:name、value、source、type。
name
name属性指定用于存储数据的Solr字段的名称。应在Solr模式中定义具有匹配名称的字段。name属性是必需的。
value
value属性指定用来填充Solr字段的来自HBase中数据,它采用列族名称(column family )和限定符(qualifier)的形式,用冒号分隔。
限定符部分可以以星号结尾,星号被解释为通配符。 在这种情况下,将使用所有匹配的列族和限定符表达式。
下面是几个例子:
mycolumnfamily:myqualifier
mycolumnfamily:my*
mycolumnfamily:*
source
source属性确定HBase KeyValue的哪个部分将用作索引内容。
这个属性可能值为:value、qualifier。
如果指定为value,那么Cell的值将被索引。
如果指定位qualifier,column qualifier将被索引。
type
定义HBase中内容的数据类型。
因为所有数据都作为字节数组存储在HBase中,但Solr中的所有内容都被索引为文本,因此需要一种从字节数组转换为实际数据类型的方法。
此字段的值可以是HBase Bytes类支持的任何数据类型之一:int,long,string,boolean,float,double,short或bigdecimal。
如果基于字节的表示尚未用于HBase中存储数据,可为这个属性指定自定义名称。自定义类必须实现com.ngdata.hbaseindexer.parse.ByteArrayValueMapper接口。
元素
元素定义了一个键值对,它将提供给实现com.ngdata.hbaseindexer.Configurable接口的自定义类。
元素也可以嵌套在元素中。
该元素有两个属性:name和value。 两者都是强制性的
看看给出的例子:

2.4创建Morphline配置文件
创建完索引器配置文件后,可以在morphlines.conf配置文件中配置morphline ETL转换命令,morphlines.conf配置文件可以包含任何数量的morphline ETL转换命令。一般地,extractHBaseCells是第一个命令,readAvroContainer或 readAvro这两个morphline命令被用与从HBase字节数组中提取Avro数据。此配置文件可以在使用morphlines的不同应用程序之间共享。
如果使用Cloudera Manager,依次点击Key-Value Store Indexer service > Configuration > Category > Morphlines > Morphlines File,就可以编辑morphlines.conf了。
2.5理解Morphline 命令extractHBaseCells
extractHBaseCells抽取HBase数据,并将其转换为SolrInputDocument。这个命令有0个或多个命令规范组成。
对于每个映射都有:
1)inputColumn参数
指定要填充到Solr字段的HBase数据。它具有列族名称和限定符的形式,以冒号分隔列族名称和限定符。限定符部分可以以星号结尾,星号被解释为通配符。在这种情况下,将使用所有匹配的列族和限定符表达式。下例为有效inputColumn值:
mycolumnfamily:myqualifier
mycolumnfamily:my*
mycolumnfamily:*
2)outputField参数
指定morphline记录字段,这些记录要被添加到输出值中。morphline记录字段也被称为Solr文档字段。
以*结尾的outputField参数可以开启动态输出字段。例如:
inputColumn : "mycolumnfamily:*"
outputField : "belongs_to_*"
这样如果在HBase中执行Put操作:
put 'table_name' , 'row1' , 'mycolumnfamily:1' , 'foo'
put 'table_name' , 'row1' , 'mycolumnfamily:9' , 'bar'
那么solr文档字段为:
belongs_to_1 : foo
belongs_to_9 : bar
3)type参数
定义了存储在HBase中的内容的类型。HBase中的数据都是字节数组,而Solr中的索引文件是文本文档。所以需要一个方法将字节数组转换为实际类型。type参数可以是类型名称,org.apache.hadoop.hbase.util.Bytes.to*要支持这种类型(目前包括byte[], int, long, string, boolean, float, double, short, 和bigdecimal)。使用类型byte[]传递字节数组给morphline而不用转换。
type:byte[],将字节数组不加修改地拷贝到记录的输出字段。其他是调用相应的方法进行转换。例如使用org.apache.hadoop.hbase.util.Bytes.toInt转换int。或者type是实现了com.ngdata.hbaseindexer.parse.ByteArrayValueMapper接口的Java类的名称。HBase数据格式化并不总是与org.apache.hadoop.hbase.util.Bytes指定的格式相匹配。可以通过转换数据来索引这个HBase数据。可以使用下面的方式:
- 使用Java morphline命令来解析输入数据
{
imports : "import java.util.*;" code: """ // manipulate the contents of a record field
String stringAmount = (String) record.getFirstValue("amount");
Double dbl = Double.parseDouble(stringAmount); record.replaceValues("amount
最后
以上就是能干哈密瓜最近收集整理的关于无法为属性或索引器赋值_使用Lily HBase NRT Indexer为HBase构建二级索引1准备工作开启集群范围内的HBase复制功能添加Lily HBase NRT Indexer服务为Lily HBase NRT Indexer配置HBase依赖启动Lily HBase NRT Indexer2使用Lily HBase NRT Indexer服务2.1启用HBase列族复制功能2.2在Cloudera Search中创建一个聚集2.3创建Lily HBase Indexer配置文件全局的全部内容,更多相关无法为属性或索引器赋值_使用Lily内容请搜索靠谱客的其他文章。








发表评论 取消回复