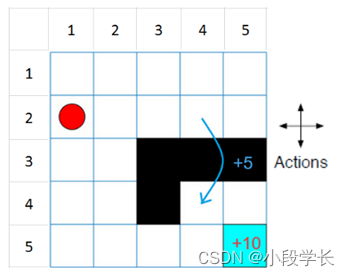
此网格世界环境具有以下配置和规则:
一个由边界界定的5 x 5网格世界,有4种可能的动作(北= 1,南= 2,东= 3,西= 4)。
代理从单元格[2,1](第二行,第一列)开始。
如果代理人到达单元格[5,5]的最终状态(蓝色),则代理商会获得+10的奖励。
该环境包含从单元格[2,4]到单元格[4,4]的特殊跳转,奖励为+5。
代理被障碍物(黑格)阻塞。
所有其他动作都会导致-1奖励。
1.创建网格世界环境
创建基本的网格世界环境。
env = rlPredefinedEnv("BasicGridWorld");
要指定代理的初始状态始终为[2,1],请创建一个reset函数,返回初始代理状态的状态号。该功能在每次训练和模拟开始时调用。状态从位置[1,1]开始编号。随着您向下移动第一列,然后向下移动后续的每一列,状态号会增加。因此,创建一个匿名函数句柄,将初始状态设置为2.
env.ResetFcn = @() 2;
修复随机生成器种子以获得可再现性。
rng(0)
2.创建Q-学习代理
要创建一个Q-learning agent,首先使用grid world环境中的观察和动作规范创建一个Q表。将优化器的学习率设置为0.01。
qTable = rlTable(getObservationInfo(env),getActionInfo(env));
qFunction = rlQValueFunction(qTable,getObservationInfo(env),getActionInfo(env));
qOptions = rlOptimizerOptions(“LearnRate”,0.01);
接下来,使用Q值函数创建Q学习代理,并配置ε贪婪探索。有关创建Q-learning代理的更多信息,请参见rlQAgent和rlQAgentOptions。
agentOpts = rlQAgentOptions;
agentOpts.EpsilonGreedyExploration.Epsilon = .04;
agentOpts.CriticOptimizerOptions = qOptions;
qAgent = rlQAgent(qFunction,agentOpts);
3.培训Q-学习代理
要培训代理,请先指定培训选项。对于此示例,请使用以下选项:
最多训练200集。指定每集最多持续50个时间步。
当代理在连续30集内获得的平均累积奖励大于10时,停止培训。
如需详细资讯,请参阅rlTrainingOptions。
trainOpts = rlTrainingOptions;
trainOpts.MaxStepsPerEpisode = 50;
trainOpts.MaxEpisodes= 200;
trainOpts.StopTrainingCriteria = "AverageReward";
trainOpts.StopTrainingValue = 11;
trainOpts.ScoreAveragingWindowLength = 30;
使用培训Q-learning代理train功能。培训可能需要几分钟才能完成。若要在运行此示例时节省时间,请通过设置来加载预训练的代理doTraining到false。要自己训练代理,请设置doTraining到true。
doTraining = false;
if doTraining
% Train the agent.
trainingStats = train(qAgent,env,trainOpts);
else
% Load the pretrained agent for the example.
load('basicGWQAgent.mat','qAgent')
end
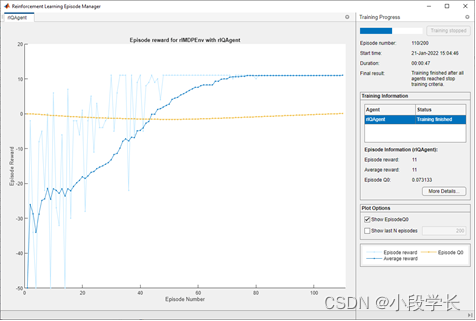
这剧集经理窗口打开并显示培训进度。
4.验证Q-学习结果
要验证培训结果,请在培训环境中模拟代理。
在运行模拟之前,可视化环境并配置可视化以维护代理状态的跟踪。
plot(env)
env.Model.Viewer.ShowTrace = true;
env.Model.Viewer.clearTrace;
使用模拟环境中的代理sim功能。
sim(qAgent,env)
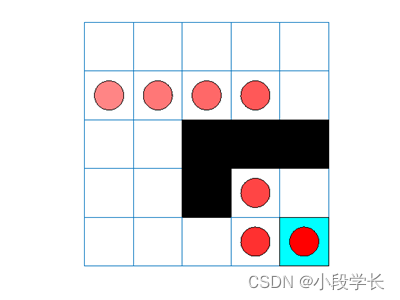
代理跟踪显示代理成功地找到了从单元格[2,4]到单元格[4,4]的跳转。
5.创建和培训SARSA代理
要创建SARSA代理,请使用与Q学习代理相同的Q值函数和ε贪婪配置。有关创建SARSA代理的更多信息,请参见rlSARSAAgent和rlSARSAAgentOptions。
agentOpts = rlSARSAAgentOptions;
agentOpts.EpsilonGreedyExploration.Epsilon = 0.04;
agentOpts.CriticOptimizerOptions = qOptions;
sarsaAgent = rlSARSAAgent(qFunction,agentOpts);
使用培训SARSA代理train功能。培训可能需要几分钟才能完成。若要在运行此示例时节省时间,请通过设置来加载预训练的代理doTraining到false。要自己训练代理,请设置doTraining到true。
doTraining = false;
if doTraining
% Train the agent.
trainingStats = train(sarsaAgent,env,trainOpts);
else
% Load the pretrained agent for the example.
load('basicGWSarsaAgent.mat','sarsaAgent')
end
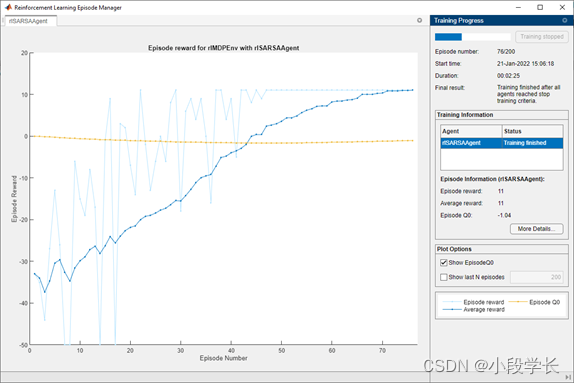
6.验证SARSA培训
要验证培训结果,请在培训环境中模拟代理。
plot(env)
env.Model.Viewer.ShowTrace = true;
env.Model.Viewer.clearTrace;
在环境中模拟代理。
sim(sarsaAgent,env)
最后
以上就是糟糕跳跳糖最近收集整理的关于在基本网格世界中训练强化学习代理1.创建网格世界环境2.创建Q-学习代理3.培训Q-学习代理4.验证Q-学习结果5.创建和培训SARSA代理6.验证SARSA培训的全部内容,更多相关在基本网格世界中训练强化学习代理1内容请搜索靠谱客的其他文章。








发表评论 取消回复