教程目录
- 0x00 教程内容
- 0x01 基础储备
- 1. 自动登录流程
- 2. 获取元素信息
- 3. 提交内容
- 0x02 自动登录实现
- 1. 流程
- 2. 完整代码
- 3. 执行结果
- 0x03 彩蛋
- 0xFF 总结
0x00 教程内容
- 爬虫的流程是怎样的
- 如何通过代码实现自动登录
- 如何实现自动翻页
教程背景:上篇教程已经安装完了Selenium,并能够打开“邵奈一的博客主页”,这篇教程,我们一起来实现登录特定网页(职前通)官网,实现登录功能,并且在登录完成后继续点击特定的类别(大数据),实现翻页功能。
0x01 基础储备
1. 自动登录流程
a. 原理
网页是由HTML组成的,为了网页的好看,所以用到了CSS,为了让网页具有更加炫酷的动态效果,所有又加入了JS,但是我们都知道,网页的最基础骨架,是HTML。
而HTML又是由许许多多的标签所组成的,除了标签,还有标签里面的内容。
当我们要去实现一个自动登录功能的时候,我们需要清楚一些事情,登录按钮往往是通过一个Button标签实现的。我们点击登录按钮,其实就是点击了Button标签,点击之后,我们会进行提交用户名和密码操作。
简而言之,自动登录流程为:
打开谷歌浏览器=>打开网站=>点击登录按钮(显示登录页面)=>输入用户名和密码=>点击登录按钮(提交操作)。
b. 其实最关键点有两个
1、你要点击什么东西?2、点击之后你需要提交什么东西?
答案:
1、点击登录按钮,2、提交用户名和密码
原理已经清楚了,那么我们现在需要做的第一步就是,如何让代码能够找到你所想要点击的地方(标签/内容)?请继续往下面看!
2. 获取元素信息
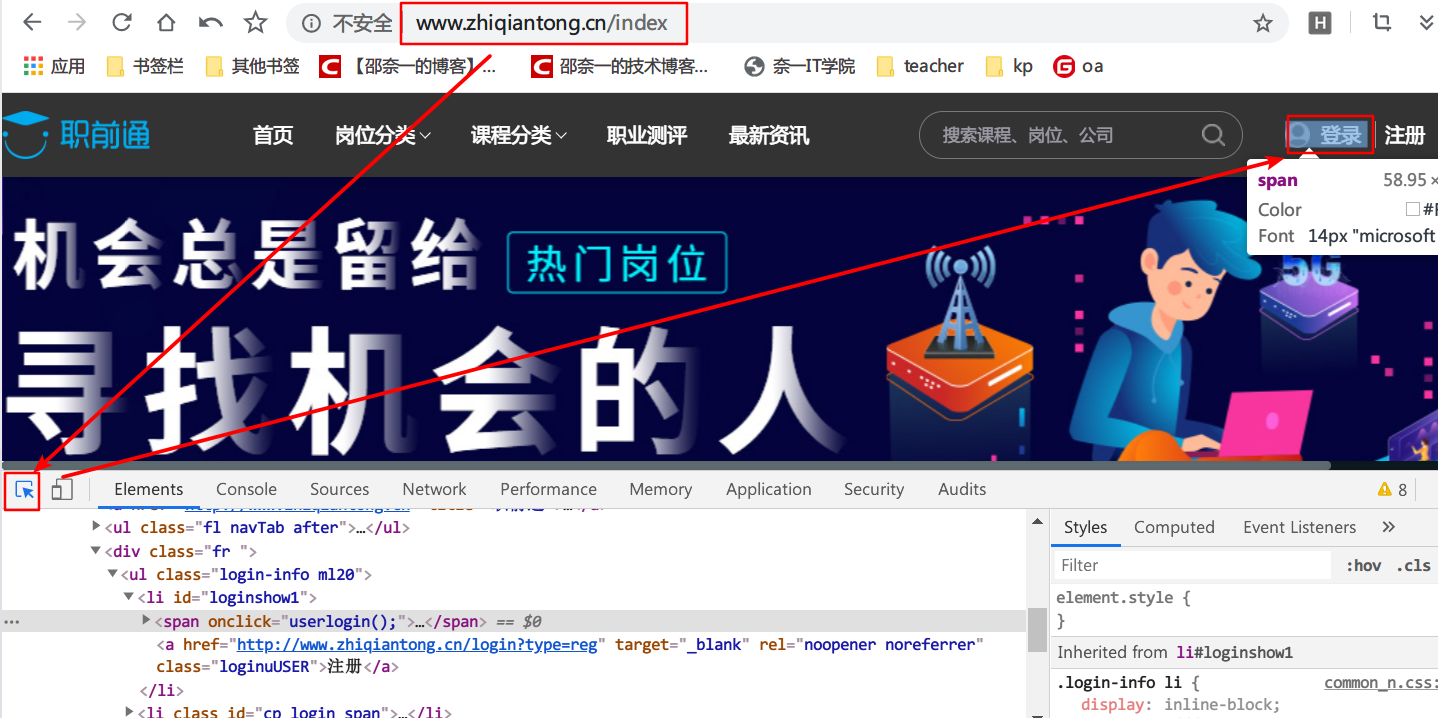
a. 打开调试窗口
当你打开某一个网页的时候,其实你可以按键盘的F12键来调出浏览器的调试窗口,或者你右击网页,选择“检查”也可以,不信你试试现在你现在浏览的这边教程的网页:
b. 选择元素
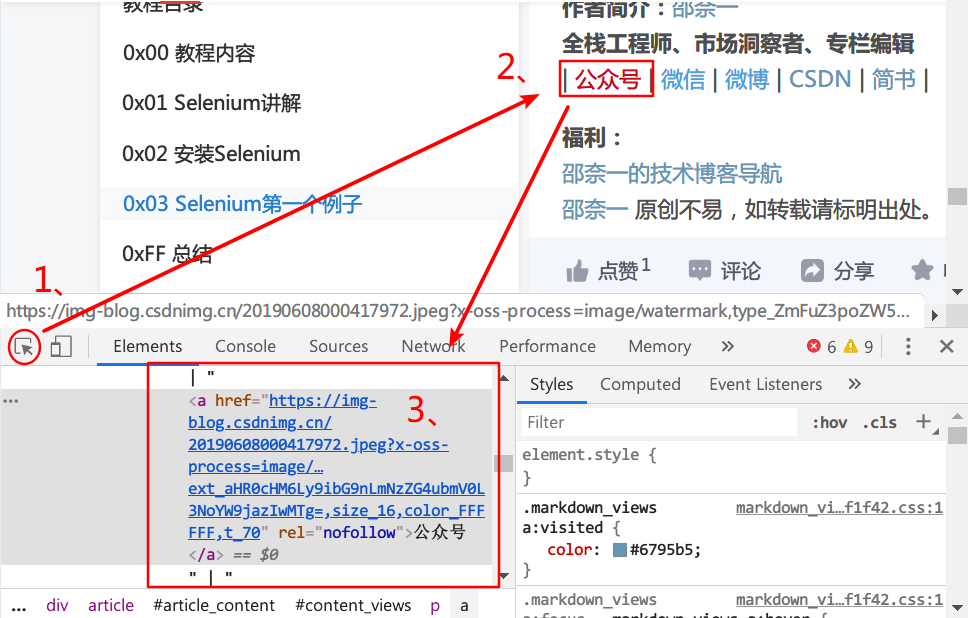
步骤为先点击1、,然后选择2、,就会弹出3、内容了,此内容就是你所点击的标签相关内容,同理,你可以去点击一下登录按钮的标签。
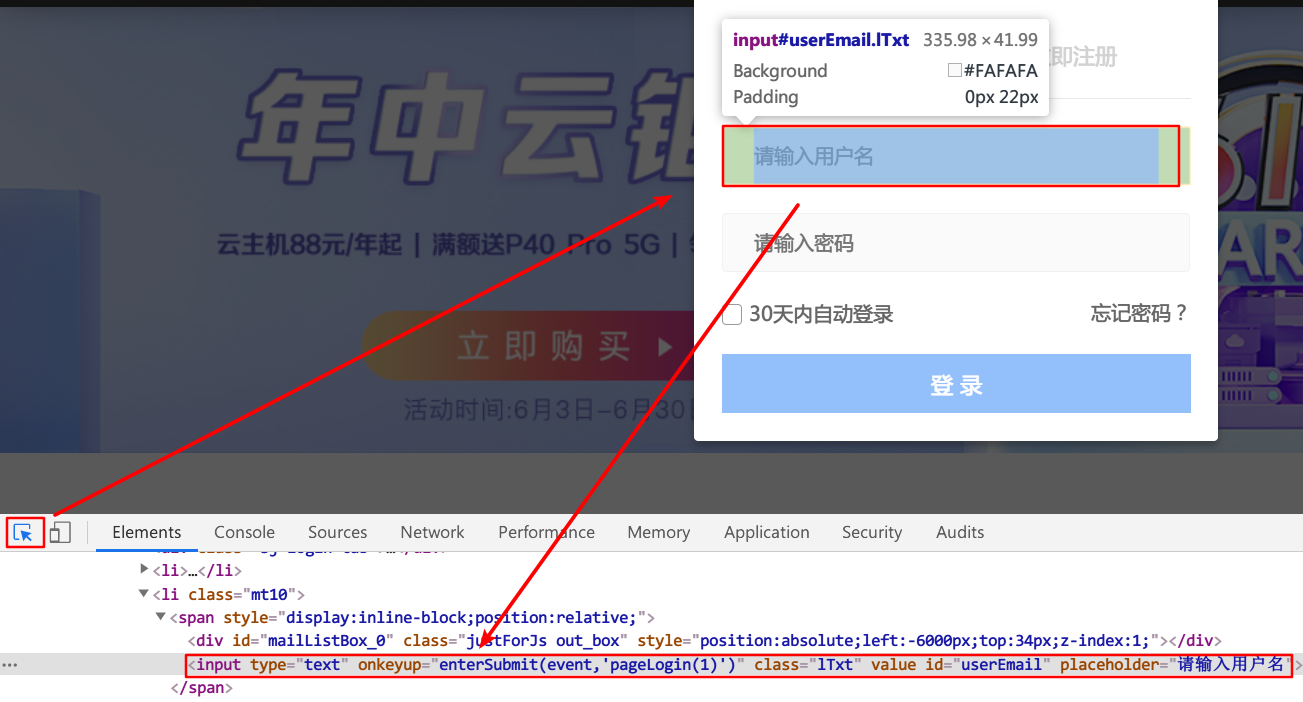
c. 获取元素的位置信息
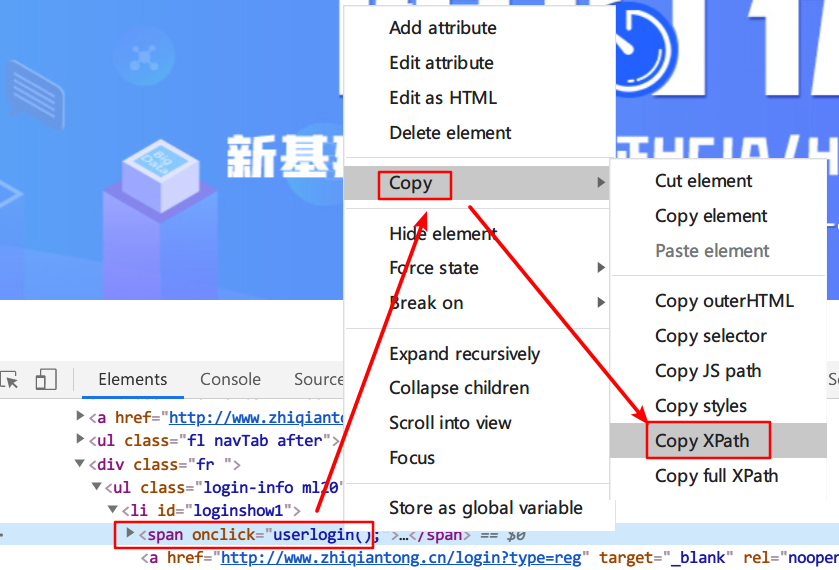
现在我们已经知道怎么获取元素的标签信息了,但是,这个信息仅仅只是元素信息而已,我们都知道,同一种标签,其实是可以在很多地方使用的,竟然是这样,按道理来说,其实代码如果是单单通过获取标签名来获取你的位置信息,其实是会混淆的,原理跟以前学习HTML时一样,此处不多说,能理解即可,不理解也没关系。那怎样才能让代码能够找到你这个位置呢?此处我们可以右击你的标签内容,选择Copy,选择Copy XPath:
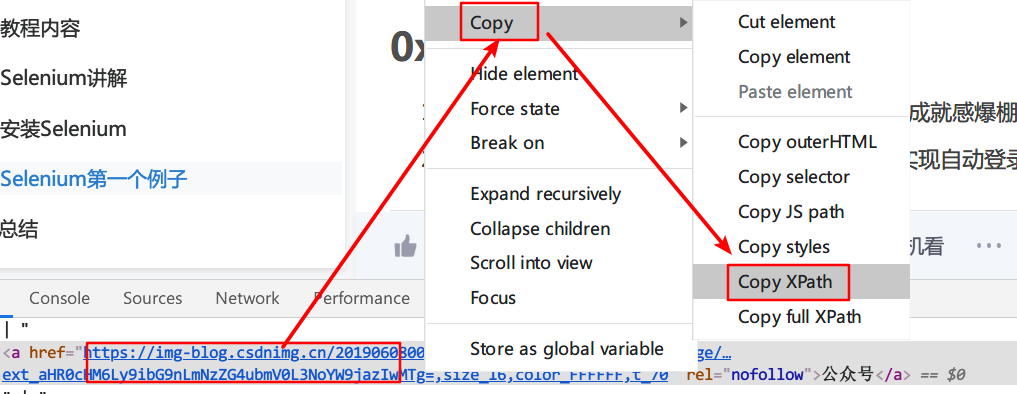
XPath的内容类似于这样://*[@id="content_views"]/p[15]/a[2],XPath 是一门在 XML 文档中查找信息的语言,不理解也没关系。如果你需要用到此位置,你需要记录好此XPath,之后在代码中会用到。
3. 提交内容
a. 刚刚已经获取到我们所需要点击的位置,还需要实现点击操作和填充内容操作,最后才实现点击登录按钮实现提交,这里边的内容需要通过代码来实现:
login = browser.find_element_by_xpath('//*[@id="loginshow1"]/span')
此处可以由XPath获得一个对象,然后此login对象可以点击,如:
login.click()
如果是填充的元素XXX,如用户名输入框,还可以清除内容:
XXX.clear()
也可以填充内容:
XXX.send_keys("shao")
此处先理解!
0x02 自动登录实现
1. 流程
a. 打开谷歌浏览器 => 访问职前通官网 => 获取需要点击的元素 => 点击 => 提交内容 => 提交
2. 完整代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from selenium import webdriver
browser = webdriver.Chrome("C:\Users\shaonaiyi\AppData\Local\Google\Chrome\Application\chromedriver.exe")
browser.get("http://www.zhiqiantong.cn/")
login = browser.find_element_by_xpath('//*[@id="loginshow1"]/span')
login.click()
username = browser.find_element_by_xpath('//*[@id="userEmail"]')
username.clear()
password = browser.find_element_by_xpath('//*[@id="userPassword"]')
password.clear()
username.send_keys("自己的账号")
password.send_keys("自己的密码")
login_button = browser.find_element_by_xpath('//*[@id="dcWrap"]/div/div[3]/ul/li[5]/input')
login_button.click()
代码比较简单,不再重复讲解。
3. 执行结果
发现已经登录上了职前通官网:
0x03 彩蛋
前面已经实现了自动登录功能,此彩蛋为实现自动翻页。因为在爬虫的时候,肯定是会有很多页的内容的。
流程:自动点击进入制定的类别(大数据),找到翻页按钮,点击翻页按钮,当无法点击时,停止翻页。
完整代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from selenium import webdriver
browser = webdriver.Chrome("C:\Users\shaonaiyi\AppData\Local\Google\Chrome\Application\chromedriver.exe")
browser.get("http://www.zhiqiantong.cn/")
login = browser.find_element_by_xpath('//*[@id="loginshow1"]/span')
login.click()
username = browser.find_element_by_xpath('//*[@id="userEmail"]')
username.clear()
password = browser.find_element_by_xpath('//*[@id="userPassword"]')
password.clear()
username.send_keys("自己的账号")
password.send_keys("自己的密码")
login_button = browser.find_element_by_xpath('//*[@id="dcWrap"]/div/div[3]/ul/li[5]/input')
login_button.click()
courses = browser.find_element_by_xpath('//*[@id="header"]/section/nav/ul/li[3]/a')
courses.click()
bigdata_cate = browser.find_element_by_xpath('//*[@id="course-main"]/section/section/div[1]/dl/dd[1]/ul/li[9]/a')
bigdata_cate.click()
next_page = browser.find_element_by_xpath('//*[@id="course-main"]/div/div[1]/ul/li[4]/a')
flag = next_page.click()
if flag is None:
print("——————————————————已是最后一页,无法再点击——————————————————")
其实翻页功能非常容易实现,也就是点击而已。
0xFF 总结
- 本教程不难,但是已经可以做更多有趣的事情了,还可以自动翻页。
- 继续关注我,学习编程技术。
作者简介:邵奈一
全栈工程师、市场洞察者、专栏编辑
| 公众号 | 微信 | 微博 | CSDN | 简书 |
福利:
邵奈一的技术博客导航
邵奈一 原创不易,如转载请标明出处。
最后
以上就是背后绿茶最近收集整理的关于【邵奈一】Python爬虫专栏(三)之自动登录0x00 教程内容0x01 基础储备0x02 自动登录实现0x03 彩蛋0xFF 总结的全部内容,更多相关【邵奈一】Python爬虫专栏(三)之自动登录0x00内容请搜索靠谱客的其他文章。








发表评论 取消回复