在学习简单的爬虫时,想试着登录管理系统练练手,首先分析了源码,发现了它所提交的数据是在下面这个函数中:
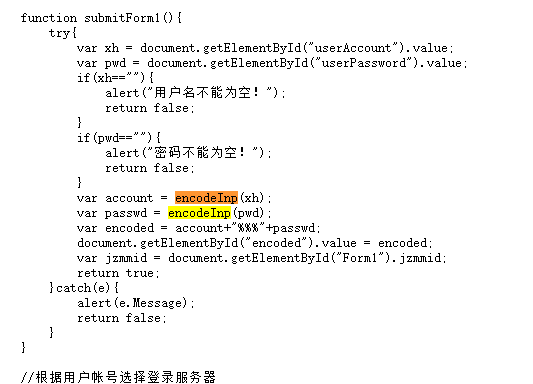
它是将账号和密码放在了一个变量:encoded中的,如果不确信的话也可以先登录看看,如下

需要注意的是账号与密码是加密的,而在源代码中引入的js文件中有个文件就是加密文件
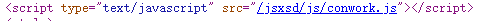

那么既然知道它提交的数据以及如何加密,就可以开始工作了,首先也需要安装可以在python中可以编译js的库 ,pip install PyExecJS(注意需要js环境)
引入库 :
from urllib import parse,request
from http.cookiejar import CookieJar
import execjs
定义一个函数用来加密账号和密码的(需要注意的是调用"encodeInp"时,需要将账号和密码转换成字符串,否则调用函数时会报错):
def coder(username,password):
with open("conwork.js") as f:
cxt = execjs.compile(f.read())
username_coder = cxt.call("encodeInp",str(username))
password_coder = cxt.call("encodeInp",str(password))
encoder = username_coder+"%%%"+password_coder
f.close()
print(encoder)
return encoder
接着需要利用cookie模拟登陆:
cookiejar = CookieJar()
handler = request.HTTPCookieProcessor(cookiejar)
#创立请求对象
opener = request.build_opener(handler)
#配置模拟浏览器
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36"
}
#提交给服务器的参数
data={
"encoder":coder(xxxxxxx,"xxxxxxx")
}
#登陆页面
login_url="http://xxxxx"
# 构建请求
req = request.Request(login_url,headers=headers,data=parse.urlencode(data).encode("utf-8"),method="POST")
#请求页面
opener.open(req)
上面的代码执行成功后,便表示登陆成功了,
接下来就是进入你想要进入的页面了
url = "http://xxxx"
req = request.Request(url,headers=headers)
resp = opener.open(req)
最后
以上就是花痴抽屉最近收集整理的关于学习Python爬虫分析如何实现自动登录学生个人中心的全部内容,更多相关学习Python爬虫分析如何实现自动登录学生个人中心内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复