吴恩达深度学习笔记
- P3 用神经网络进行监督学习
- P4 深度学习的兴起
- P7 二分分类
- P8 logistic回归
- P10 梯度下降法
- P14 使用计算图求导
- P16 批量梯度下降
- P17 向量化
- P21 广播机制
- P22 关于numpy
- P24 logistics损失函数
- P26 神经网络的表示
- P28 多个样本向量化
- P30 激活函数
- P31 使用非线性激活函数的原因
- P35 随机初始化参数
- P36 深层神经网络
- P40 使用深层的神经网络的原因
- P41 搭建深层神经网络块
- P42 超参数
- P47 训练集验证集测试集
- P48 偏差和方差
- P49 高偏差和高方差的解决方法(机器学习基础)
- P50 正则化
- P51 正则化能防止过拟合的原因
- P52 dropout正则化
- P53 dropout正则化2
- P54 其他正则化方法
- P55 归一化输入
- P56 梯度爆炸/梯度消失
- P57 神经网络权重初始化
- P58 逐步实现梯度检验的前提-梯度数值逼近
- P59 梯度检验
- P60 关于梯度检验
- P61 小批量的梯度下降
- P62 小批量的梯度下降2
- P66 动量梯度下降
- P67 RMSprop算法
- P68 adam算法
- P69 学习率衰减
- P70 局部最优问题
- P71 超参数调试
- P72 选取超参数的取值范围
- P73 超参数的训练
- P74 Batch Normalization
- P75 在神经网络里使用batch norm
- P76 batch norm有效的原因
- P77 测试时的BN
- P78 softmax回归
- P85 正交化
- P86 选择一个数字作为评价指标-F1
- P87 满足和优化指标
- P89 训练集、验证集、测试集的划分
- P92 可避免偏差
- P96 误差分析
- P97 清除错误标记
- P99 在不同划分上进行训练和测试
- P100 不匹配数据划分的偏差和方差
- P101 解决数据不匹配
- P102 迁移学习
- P103 多任务学习
- P105 端到端学习
- P110 边缘检测
- P111 padding
- P112 卷积步长
- P113 三维卷积
- P114 单层卷积层
- P116 池化层
- P117 卷积网络示例
- P118 使用卷积的原因
- P122 残差网络与其作用
- P123 1×1卷积核
- P124 inception网络
- P127 迁移学习
- P130 目标定位
- P133 滑动窗口的卷积实现
- P134 bounding box
- P135 交并比
- P136 非最大值抑制
- P137 anchor box
- P138 YOLO算法
- P139 R-CNN
- P141 一次(One-Hot)学习
- P142 Siamese网络
- P143 三元组损失值
- P144 面部识别与二分类
- P147 风格转换的代价函数
- P148 内容代价函数
- P149 风格代价函数
- P153 RNN
- P154 RNN的反向传播
- P155 不同类型的RNN
- P156 语言模型与序列生成
- P157 新序列采样
- P158 梯度消失与梯度爆炸
- P159 GRU单元
- P160 LSTM
- P161 双向循环神经网络
- P162 深层的RNN
- P163 词汇表征
- P164 使用词嵌入
- P165 词嵌入特性
- P166 嵌入矩阵
- P167 学习词嵌入
- P168 word2vec
- P169 负采样
- P170 GloVe
- 看不懂
- P171 情绪分类
- P172 词嵌入去偏
- P173 基础模型
- P174 贪心搜索
- P175 集束搜索
- P176 对于集束搜索的一些改进
- P177 集束搜索的误差分析
- P178 Bleu得分
- 看不懂
- P180 注意力机制
- P181 语音识别
- P182 触发字检测
- P183 完结撒花
视频链接:[双语字幕]吴恩达深度学习deeplearning.ai
P3 用神经网络进行监督学习
神经网络的不同应用:
- 房地产、在线广告:标准神经网络standard NN
- 图像应用方面:卷积神经网络CNN
- 序列数据(含有时间成分的音频——一维时间序列):循环神经网络RNN
- 语言分析:更复杂的RNNs
- 无人驾驶:混合神经网络结构
结构化数据:数据的数据库
非结构化数据:音频、图片、文本–>早期让计算机处理和理解比较困难 现在有了神经网络和深度学习 计算机可以更好的理解非结构化数据
P4 深度学习的兴起
从sigmoid到ReLU:sigmoid函数在最左边和最右边的梯度接近0 这样会使得在使用梯度下降算法的时候学习的太慢 参数变化太慢 ReLU函数是修正的线性函数 在正值输入的部分梯度永远大于0 这样学习的效果就更好一点 因此要将sigmoid转成ReLU 让梯度下降算法学习的更好
P7 二分分类
logistic算法:解决二分类问题
输入的X:m列 n行(m是样本容量 n是每个样本维度)
比如说 有一张rgb图片 尺寸大小是6464 每个颜色通道都是6464的矩阵 将这张图片作为输入 则输入的x维度是64643 即n=64643 要输入多少图片作为样本 这个数量就是m
输出的Y:1行m列
因为这是一个二分类问题 每个y只能是0或者1 而m个样本对于m个输出(y) 因此输出矩阵Y是1行m列
P8 logistic回归
sigmoid函数:将变量映射到0到1之间
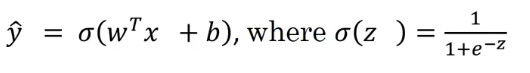
logistic损失函数:为了使梯度下降法更方便 不直接用预测值-真实值的误差平方计算 采用以下函数

可以假设y=1和y=0 这样的损失函数可以使得:当y=1(真实值为1)想要让损失函数更小 那么也就是让y-hat(y的预测值)更大(更靠近1) y=0时同理 这就是这个公式的巧妙之处了
损失函数是在单个样本上训练的结果 衡量单个训练样本的表现
成本函数:衡量在全体训练样本上的表现 衡量w b在训练集上的效果

P10 梯度下降法
梯度下降法:梯度下降函数会使每一次迭代的w都往最优解走 不管w一开始是很大还是很小(先针对w来说 后面w b都可以按照这种方式迭代)

P14 使用计算图求导
反向传播 类似于链式法则?
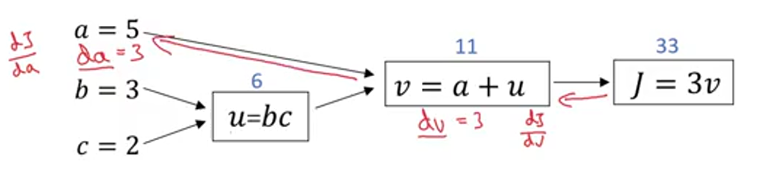
先计算了dv 在后面计算da时就会用到
P16 批量梯度下降
成本函数就是每个样本的损失函数求和再求平均
批量梯度下降算法实现:
循环(for)计算每个样本的对于w和b的导数 求和 然后除以样本总数 (计算平均)就得到一次梯度下降的结果(只改变一次w b)
向量化可以避免使用for循环
P17 向量化
向量化 提升运算速度 避免for循环 尽量找别的方法代替
numpy有很多针对矩阵每个元素的计算的内置函数
P21 广播机制
广播:
- 如果一个(m,n)矩阵加(减乘除)一个(1,n)或(m,1)矩阵 广播机制会自动把后面的矩阵变成(m,n)
- (m,1)矩阵加上一个常数 矩阵的每个元素自动加上这个元素
P22 关于numpy
要注意numpy可能会产生奇怪的bug 比如维度不匹配等等 因为机制太灵活了
比如 在建立一个5*1的矩阵时 要使用np.random.randn(5,1)
np.random.rand(5)会创建一个不是行向量也不是列向量的一组数(数组)
P24 logistics损失函数
成本函数的由来
- 针对二分类样本的条件概率函数求ln() 因为ln()是严格递增的 算出来的公式是损失函数的负值 因此ln的最大就是损失的最小
- 求总体样本的成本函数 先假设每个样本都是独立同分布的 因此总体样本的观测概率就是每个样本的概率乘积 做极大似然估计 等式两边同时求对数 因此原来的乘积就变成了和的形式 其中每一项都是刚刚算过的每个样本的损失函数的负值 极大似然法就是要求一组参数使得整个公式的概率最大 在成本函数中我们一般令成本最小 因此去掉刚刚算的符号 再进行一个1/m的缩放 就成了最后成本函数的形式
P26 神经网络的表示
一般文献或者论文都将有输入层、一个隐含层(我们只能看到输入和输出 看不到这一层)、输出层的“三层”神经网络称为“双层”神经网络 默认输入层是第零层 不是一个标准的“层” 且隐含层和输出层都带有参数
P28 多个样本向量化
多个样本向量化 就是把他们都组合到一个矩阵里 横向堆叠成一个矩阵

横向代表不同的训练样本 竖向代表隐含层的不同节点
P30 激活函数
tanh函数和sigmoid函数差不多 就是tanh函数经过原点 也就是说tanh函数的数值平均值为0 这样的平移在某些时候比sigmoid函数跟适合学习 但是这两者的共同问题就是在z很大或很小的时候 函数的导数很小 不利于梯度下降算法
ReLU函数 z小于0时是0 z大于0时是z 但是z小于0时导不存在
LeakyReLU函数 z大于0时是z z小于0时是一个斜率很小的正比例函数
选择激活函数:如是二分类 输出层选择sigmoid函数 其他单元用ReLU
可以在保留的交叉验证集或者开发集上训练 看结果 选择使用哪个激活函数
P31 使用非线性激活函数的原因
如果隐含层也使用线性激活函数 那么隐含层将没有任何用 相当于logistic回归 所以需要非线性激活函数 才能计算更有趣的网络
但是如果机器学习的是回归问题 那么可以用线性激活函数
P35 随机初始化参数
如果隐含层每个节点的激活函数都一样(完全对称) 隐含层对于输出的影响相同 不管计算多少次梯度下降 计算的函数都一样 对输出没什么用 因此需要随机初始化参数
初始化成比较小的值(*0.01) 因为如果权重太大 在tanh函数和sigmoid函数的梯度下降就不明显 减慢学习速度
P36 深层神经网络
突然忘了反向传播中的一步函数的推导过程,查的网络上的大佬推导如下:推导反向传播中的dZ=A - y
P40 使用深层的神经网络的原因
使用深层的神经网络:
- 对于图像识别而言 假设有三层隐含层 第一层先探测边缘 第二层把边缘像素组合成图像的一部分 最后把这些部分组合在一起 整个网络就可以识别同类型的图像了 每个探测器都很小 所以先从边缘入手 再慢慢扩展到整个图片的各个部分
- 对于语音识别 第一层先探测低层次的音频波形特征 第二层 把波形组合在一起 成为声音的基本单元 然后下一层把基本单元组合在一起形成单词 最后形成一个句子
- 如果层数不多 需要用指数倍的隐含层单元才能达到跟深层一样的计算结果
P41 搭建深层神经网络块
正向传播和反向传播过程:
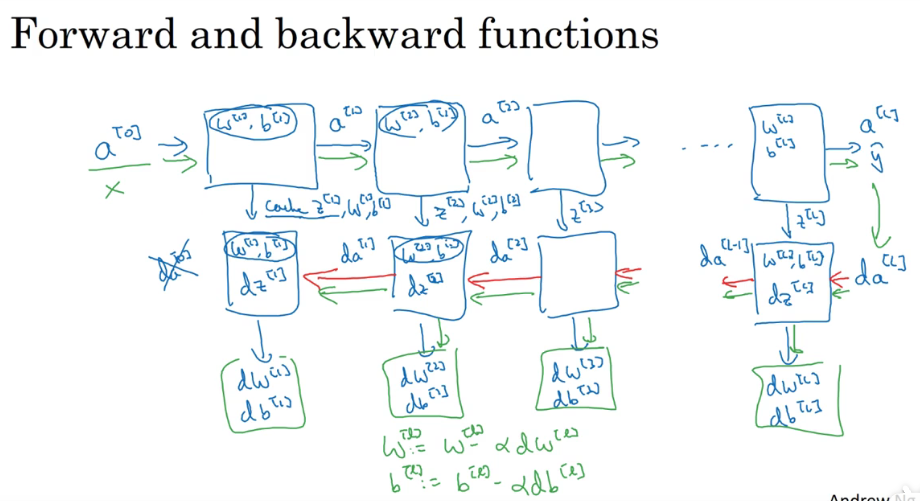
P42 超参数
超参数:程序员自己设置的 最终控制了实际参数的值 比如学习率、隐含层数、隐含层节点数等 常由经验可知
P47 训练集验证集测试集
创建一个神经网络需要考虑:隐含层数、隐含节点数、学习率、激活函数…
根据数据集选择合适的参数和超参数
将一个数据集划分成训练集-验证集-测试集或者验证集-测试集 一般(数据集较小的情况下)的比例为70/30或60/20/20 但是在现在的大数据(big data)环境下 可以将验证集和测试集所占的比例缩小 因为验证集的作用就是用来验证哪种算法更好 所以验证集要占比较多的比例才能准确验证10种甚至更多算法的有效性 但是在现实情况下 可能只需要验证1-2种算法 所以就不需要那么大的验证集 比如在百万级别的大量数据里 训练集-验证集-测试集的比例可以占到98/1/1甚至99.5/0.25/0.25就足够了
训练集和测试集验证集不匹配的情况(猫狗识别 训练集的清晰的网图 测试集是模糊的手机拍摄图)如何选择测试集和验证集?让验证集和测试集的数据来自同一分布
如果没有测试集也没关系 因为测试集就是对最终选定的神经网络做无偏评估 如果不需要这个步骤 也可以不要测试集 有时候可能把测试集过度拟合到验证集中
P48 偏差和方差
通过看训练集和验证集上的误差情况 可以判断算法/模型是否有高方差/高偏差:(训练集和验证集都来自同分布)
- 如果在训练集上的误差较小 在验证集上的误差较大 可以认为模型在训练集上过拟合了 这就产生了高方差
- 如果在训练集上的误差较大 验证集误差也大但是只比训练集大一点点 这时候就说明数据在训练集上欠拟合了 产生了高偏差
- 如果在训练集上误差较大 在验证集上的误差更大 这时候不但产生了高偏差 还有高方差
- 如果在训练集和验证集上的误差都很小 那么这时候就是低偏差和低方差
高偏差和高方差是什么样的?接近线性的分类器 数据拟合度低 会造成高偏差 灵活的曲线会过度拟合了中间某些活跃数据 就会导致高方差 在高维数据中就可能出现这种情况
P49 高偏差和高方差的解决方法(机器学习基础)
解决高偏差:换一个更大的神经网络 对原来的神经网络训练更长的时间 尝试更优算法(momentum、RMSprop、Adam) 不同的神经网络架构 更好的超参数
解决高方差:更多的数据 正则化 换一个网络框架
P50 正则化
逻辑回归正则化:在成本函数后面加上对参数w的正则化(因为w可以涵盖各种参数 而b只是一个数值 所以通常用w进行正则化) L2正则化:平方和?L1正则化:一个比例常量乘以所有w的和 如下图所示 其中λ是正则化的超参数
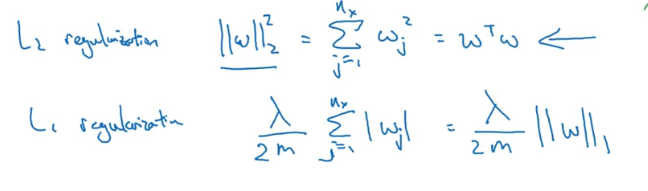
神经网络应用正则化:也是对w参数进行正则化操作 求的是w矩阵每个元素的平方和 然后再加到梯度下降的dw后面 这样会让原本的特征权重再减去一个正则化的值 降低某些特征的权重 来减小方差(减少无关因素的权值防止过拟合以减少方差) 所以也称为“权重衰减”

P51 正则化能防止过拟合的原因
参考解答:正则化为什么能防止过拟合(重点地方标红了)
正则化将高次项系数减小 避免因自变量的细微变化引起的函数值剧烈变化(这就是过拟合)
P52 dropout正则化
dropout正则化:随机选择一些节点删除(让这个节点的权值影响不到结果)
参考解答:吴恩达深度学习第二章第一周——Dropout正则化的个人理解
测试的时候不需要正则化 因为正则化就是为了防止在训练的时候过拟合而已
P53 dropout正则化2
dropout的keep_prob值设定:如果担心某些层比其他层更容易发生过拟合 就可以把那一层是keep_prob设置的小一点 但是缺点就是为了使用交叉验证 要搜索更多超参数(尝试更多k值?)
dropout主要用于计算机视觉领域 因为数据较少 经常过拟合
使用dropout的缺点之一就是无法计算代价函数J 因为每次都有被“删除”的节点 如果再三检查梯度下降效果并不能很好检查 因此代价函数J就不能被明确定义 因此通常先明确代价函数 再使用dropout
P54 其他正则化方法
其他正则化方法:
- 数据扩增:将原图翻转 放大 扭曲等创造出假的新数据
- 提前终止:随着不停迭代训练 代价函数的值会逐渐递减 但是验证集的误差可能会先降低到某个点再慢慢升高 这时候可能就让模型训练到验证集的误差最小点就提前终止训练以获得比较好的验证集误差 这样做的缺点就在于不会再优化代价函数
- L2正则化:会导致超参数搜索空间更容易分解 更容易搜索 但是缺点在于必须尝试更多正则化参数λ的值 导致计算代价增高 提前终止的办法很快就能找到终止点的w值
P55 归一化输入
加速训练神经网络的方法:归一化输入
步骤:
- 零均值化:求输入的平均值 再用样本值-平均值
- 归一化方差:求输入的标准差 再用刚刚计算出的样本值除以标准差
归一化输入原因:如果没有归一化输入 输入的取值范围相差很多 参数的范围或者比率也会非常不同 这样采用梯度下降找代价函数最小点的时候 学习率不大 要进行多次梯度下降 归一化后代价函数平均看起来更对称 在使用梯度下降算法的时候就能用更长的步长 更快找到最小点
只要让所有特征在相似范围内就可以了
P56 梯度爆炸/梯度消失
梯度爆炸/梯度消失:有时候导数或者梯度会变得非常大或者指数减小
举了一个例子:假设激活函数是线性 每层权重相同 那么只要权重比1大 多次迭代以后的代价函数就会以指数增长 反之 以指数递减 其他的情况下应该也会有导致这个现象的原因 因此对于很深的层数很多的神经网络 就会增大他的训练难度和代价
P57 神经网络权重初始化
神经网络权重初始化:根据不同的激活函数选择不同的初始化公式 让权重可以初始化一个合理值 既不会造成梯度爆炸 也不会造成梯度消失
P58 逐步实现梯度检验的前提-梯度数值逼近
使用双边误差比单边误差更能准确预估导数
P59 梯度检验
梯度检验仅仅是用来检验我们反向传播代码是不是正确,一旦确定了方向传播代码的正确性,梯度检验在神经网络训练中出来消耗更多的计算资源就毫无用处了。就像一座大桥我们在验收的时候会检测它的安全性,但不会每次有汽车经过之前都检测它的安全性。
P60 关于梯度检验
关于梯度检验:
- 只在调试的时候使用 不在训练时使用 会增加计算代价
- 如果检验失败 检查每一项元素
- 记得使用正则化
- 不能跟dropout同时使用 因为dropout会随机消除隐含层节点 这样就难以计算dropout在梯度下降上的代价函数
P61 小批量的梯度下降
小批量的梯度下降:将比较大量的数据划分成若干小批量 与批量梯度下降相比在梯度下降的时候是对每个小批量进行处理而不是全部样本 提高训练的计算速度
P62 小批量的梯度下降2
小批量梯度下降算法的批量选择:
- 批量数量=样本容量:变成批量梯度算法 每次迭代时间太长 但是很快找到最小值点
- 批量数量=1:变成随机梯度下降算法 随机梯度下降算法是一次用一个样本进行参数更新 如果要用全部样本进行更新参数 则要更新样本数量次 迭代次数多 噪声大 最终可能在最小值附近一直震荡 只要减小学习率 噪声会被改善 但是一次只用一个样本会失去向量化的优势 效率低下
- 批量数量在1~样本容量之间:既可以用到向量化的 又不用迭代太长时间 也会有一点噪声 但是不会像随机梯度下降算法一直在最小值附近震荡
- 如果是小数据集:批量梯度下降算法;大数据集:小批量梯度下降算法(小批量值:64,128,256…)
参考文章:小批量梯度下降是怎么更新参数的?
批量梯度下降(BGD)、随机梯度下降(SGD)以及小批量梯度下降(MBGD)的理解
P66 动量梯度下降
63-66都是讲关于动量梯度下降的知识 在这边统一记录
指数加权平均的超参数β 比如取0.9 那么就是计算近10次的迭代平均 越远离当前权重越小 根据公式 0.9的10次方大约为1/e 当多项式的系数减小到这种地步之后 对当前权重的影响就可以忽略 因此β是多少 大概就是计算1/1-β次迭代的指数加权平均
指数加权平均数在刚开始的几个数据上可能会有比较大的偏差 可以选择偏差修正 或者不管 反正到后面也会正常
momentum梯度下降就是用到了指数加权平均 在更新参数的时候将原来与学习率相乘的值换成指数平均计算过的梯度 这样会让在梯度下降的时候在纵轴上的不那么剧烈 减少震荡 但是在横轴上的梯度下降还是跟原来差不多 这样使得梯度下降更平稳(与普通梯度下降对比)
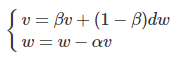
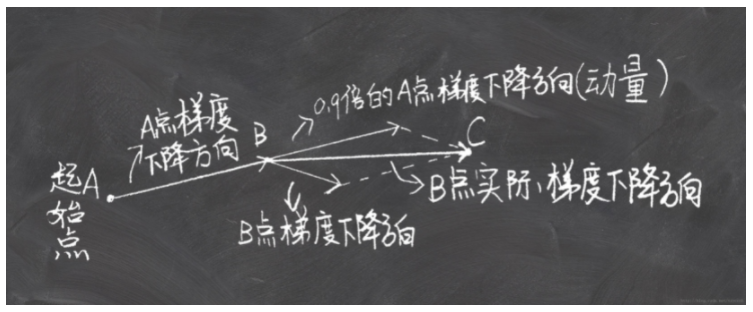
参考解答:机器学习优化方法:Momentum动量梯度下降+动量梯度下降法 Momentum
P67 RMSprop算法
RMSprop算法跟momentum类似 都是消除(可能是纵轴上的)摆动 RMSprop是将原来的微分除以一个平方根
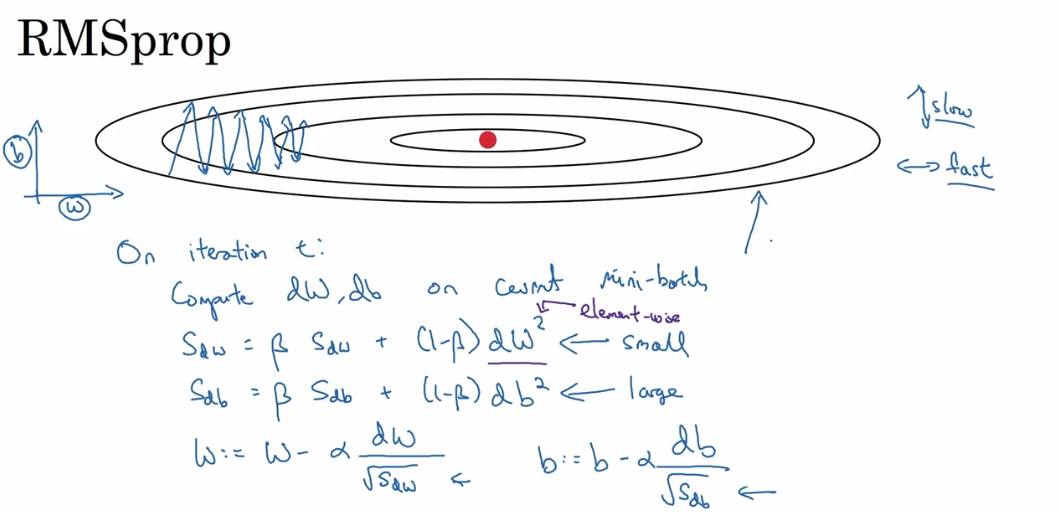
P68 adam算法
adam算法:结合了momentum算法和RMSprop算法 并对这两个算法在横轴和竖轴上的改变进行了一些修正 让算法的表现更优

修正的V和S 是用原来的V和S除以(1-对应超参数的迭代次数次方) 分母上加上一个sigma是为了防止除以一个太接近0的数
超参数:alpha、beta1、beta2、sigma
参考文章:深度学习优化算法解析(Momentum, RMSProp, Adam)
P69 学习率衰减
在训练刚开始的时候学习率可以比较大 这样会以比较大的步长向最小值迭代 但是到了快收敛的地方 如果学习率还很大 就会一直在最小值附近震荡 因此要让学习率随着迭代次数的增加而减小 可以用1/1+衰减率*迭代次数 来进行学习率衰减
P70 局部最优问题
局部最优和鞍点 有时候导数为0的点不是最优点 而是鞍点 鞍点:在一些维度上是下凸函数的最小点 在一些维度上是上凹函数的最大点 因此局部最优问题就是如何在找到鞍点之后度过那一段平稳再向下找更优解(动量梯度下降?RMSprop?Adam?)
参考解答:如何区分局部最优点和鞍点? 训练神经网络时如何确定batch的大小?
P71 超参数调试
选择调试的超参数:比如:学习率、动量梯度下降中的β、adma算法中的三个超参数、隐含层数、隐含层节点数、学习率衰减率、小批量的批量大小…其中,将学习率看作是第一需要调试的超参数 动量梯度下降中的β、隐含层节点数、小批量的批量大小是第二需要的 隐含层数、学习率衰减率是第三需要的 adma算法中的三个超参数通常很少调试 一般用经验直接赋值
调试方法:
- 将两个待调试的超参数画出一个网格 取这个网格上的点调试
- 不画网格 随机取点调试
- 随机取点调试 然后选择最优表现的一块区域 将那个区域放大再在区域里取值调试
P72 选取超参数的取值范围
选取超参数的取值范围 注意最好不要直接在一个线性轴上均匀随机取值 这样会使得靠近最小的小的区间内的值不容易被取到(10%) 可以试着对区间的端点取对数 在对数范围内取随机值再做指数运算(好像是这样就能让取值尽量平均 较小的那个范围里也能取到值了 概率论的问题 暂时还不太理解 不过问题不大 吧?)
P73 超参数的训练
超参数的训练方式:
- 只训练一个模型 每次训练一点点观察结果 然后再慢慢改变参数等等
- 同时训练多个模型 最后选取最好的那个
P74 Batch Normalization
批量归一化 就是把隐含层计算之前的输入值归一化 利用当前批量样本的数据的均值和方差 跟两个可以学习的参数 会纠正隐含层的输出
参考解答:Batch Normalization的通俗解释
P75 在神经网络里使用batch norm
在神经网络里使用batch norm的时候 可以不用考虑b这个参数 因为bn的时候需要将隐含层输入-样本均值 就会把b减掉
小批量梯度下降中算法过程如下:
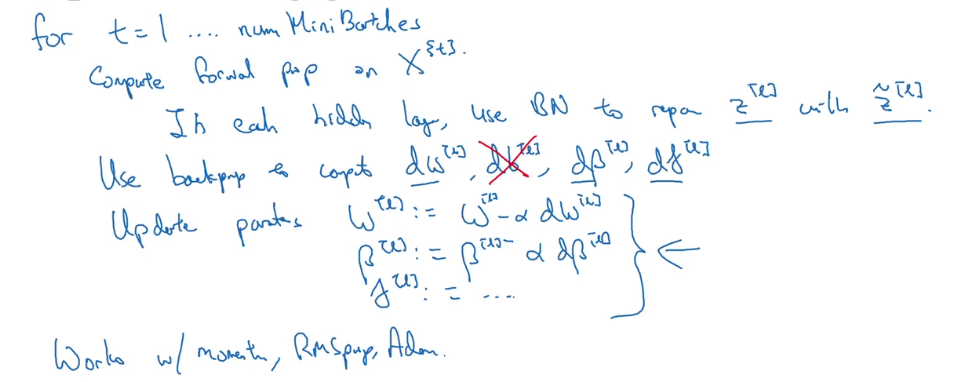
参考文章:神经网络为什么要进行batch norm?
P76 batch norm有效的原因
为什么batch norm有效?batch norm是对每个隐含层的输入进行归一化 使得前面的隐含层计算的结果不太会影响到后面的计算

参考解答:BatchNorm 为什么起作用? (Why does Batch Norm work?)
Covariate shift:样本点x的变化。我们希望样本点变化的时候对应的模型也能发生改变 即使一开始就训练出了能适应变化的模型
BN可以让每一层的输入都保持相同均值和方差 即使值不一样
BN还有轻微的正则化作用 在每个mini-batch上进行BN 为每个样本附上了轻微噪音 使后面的单元不过分依赖某一个单元(正则化就是为了防止过拟合 所以加上一点噪音也可以)
P77 测试时的BN
测试时使用BN 方差和均值就要计算整个数据集的
参考文章:深度学习(六)——BN算法(Batch Normalization)的原理和作用
P78 softmax回归
softmax回归:针对分类问题 就是在输出之前加上一层 计算每一类的概率
P85 正交化
深度学习中的正交化:找到需要调整的效果对应的参数进行调整 每个不同的效果对应不同的参数
P86 选择一个数字作为评价指标-F1
选择一个数字作为评价指标:可以选查全率、查准率 但是有点时候A的查准率比B的高 但是查全率就比B的低 这时候应该比较F1分数 F1分是两者的调和平均数 相当于平均
P87 满足和优化指标
有时候单个的数字做评价指标也不太准确 这时候可以根据训练集或者验证集或者测试集算出满足和优化指标(可能是一个公式)对模型加以评估
P89 训练集、验证集、测试集的划分
大数据时代下 最好把数据分成训练集、验证集、测试集
验证集:帮助判断哪个模型更好
测试集:帮助判断最终的成本偏差
P92 可避免偏差
在计算机视觉中,可以将人类的误差看作贝叶斯误差(最小误差) 因为在计算机视觉领域人类的误差可以称得上最小了 但是贝叶斯误差还是理论上限 训练出的误差跟贝叶斯误差之间的差距称为可避免偏差 训练误差和验证误差之间的差距成为方差 看哪个差的多就从消除哪个误差入手改进算法
P96 误差分析
可以根据产生误差的不同原因对误差进行分类 找出产生误差最大的原因并加以改进 通常会对模型或者算法有较大的改进
P97 清除错误标记
有些误差来源于标记数据时的人工错误 这时候需要清除这些错误标记 或者在改进误差的时候从别的角度入手 而不是消除了半天误差 才发现是原来的数据标错了 另外要注意如果在验证集上修正了误差 在测试集上也要做相同的修正 因为验证集和测试集必须来自同一分布 但是训练集和测试集的分布可以有轻微的不同
P99 在不同划分上进行训练和测试
在生活中的一些例子里 可能会出现训练集和测试集或者验证集分布不同的状况 这时候我们需要将验证集或者测试集设置成我们真实关心的数据 训练集可以训练比较好看的数据再加一点我们真实关心的数据(比如猫狗识别 网图就是比较好看的数据 但是我们真实要识别的是没那么清晰或者拍的不好的照片)
P100 不匹配数据划分的偏差和方差
将训练集中再取出一小块数据做训练-验证集 这些数据用来衡量模型方差 因为在之前说过 我们要让验证集和测试集的数据都来源于真实关心的数据(比如猫狗识别中手机拍的照片) 这个时候 训练集和贝叶斯误差的差距就是可避免偏差 训练集和训练-验证集的差距就是方差 训练-验证集和验证集/测试集的差距就是数据不匹配的差距(之前说过分布可能不同)
P101 解决数据不匹配
解决数据不匹配的带来的问题 可以稍微将训练集数据改造的像验证集数据 比如将一些验证集里才有的噪声合成加入到训练集中
P102 迁移学习
迁移学习:学习了一个数据量大的任务 把结果运用到数据量较小的任务上
迁移学习适用场景:
- 任务A和任务B有相同类型的输入
- 任务A的数据比B多的多
- 任务A的低层次特征可以帮助训练B
P103 多任务学习
多任务学习:比如说图像识别 单任务就是只识别一个东西 多任务就是可以同时识别这个图里的多个物体
多任务学习适用场景:
- 任务有相同的低层次特征
- 其他任务的训练结果可以帮助单个任务
- 有比较大的神经网络 这样多任务学习的性能会比单任务更好
P105 端到端学习
端到端学习:直接让输入一个数据 输出想要的结果 非端到端学习就是将任务拆解成若干步骤逐步训练
端到端学习的优缺点:
优点:
- 可以让模型直接训练数据 让模型或者网络自己发现数据特点 而不是引入人类的想法
- 减少人工设计
缺点:
- 需要大量数据 只有有大量数据的时候才适合使用端到端学习 否则很难让模型或者网络进行学习
- 排除了可能有用的手工设计
P110 边缘检测
选择特殊的滤波器可以检测出图像中的边缘信息 还可以看出这个图像边缘是由明变暗还是由暗变明的
对于复杂边缘的图像可以用不同参数的滤波器 这时候使用神经网络反向传播学习不同3×3滤波器的9个参数
补充:滤波器的大小可以根据经验判断 如果太大可能增加性能 也可能增加计算复杂度 一般是3×3 最多5×5 7×7
卷积神经网络的卷积核大小、卷积层数、每层map个数都是如何确定下来的呢?
P111 padding
原图像是n×n大小 滤波器是f×f大小 经过卷积以后的图像大小为(n-f+1)×(n-f+1)
为什么要引入padding(在图像边缘再填充像素点):原图像经过卷积后大小变小 原图像的边缘信息没有得到利用(只被滤波器扫描了一次)有可能边缘信息比较关键
padding:在图像边缘增加p层像素 这样经过卷积以后的图像大小为(n+2p-f+1)×(n+2p-f+1)
P112 卷积步长
卷积步长:通过设置可以让滤波器跳着对原图进行卷积 加入步长以后卷积结果图像大小为((n+2p-f)/s+1)×((n+2p-f)/s+1)
注:数学中的卷积包括镜像翻转(如下图) 但是深度学习或者机器学习的卷积仅仅是对每个元素相乘求和
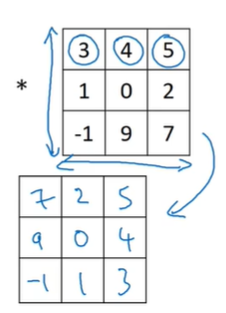
P113 三维卷积
三维卷积 需要用到跟输入图像相同通道数的过滤器 输出的还是一个二维的图像 这是在只关心一种特征的情况下 如果想要关注多个特征 可以用多个过滤器 卷积的结果再拼成多通道的图片输出
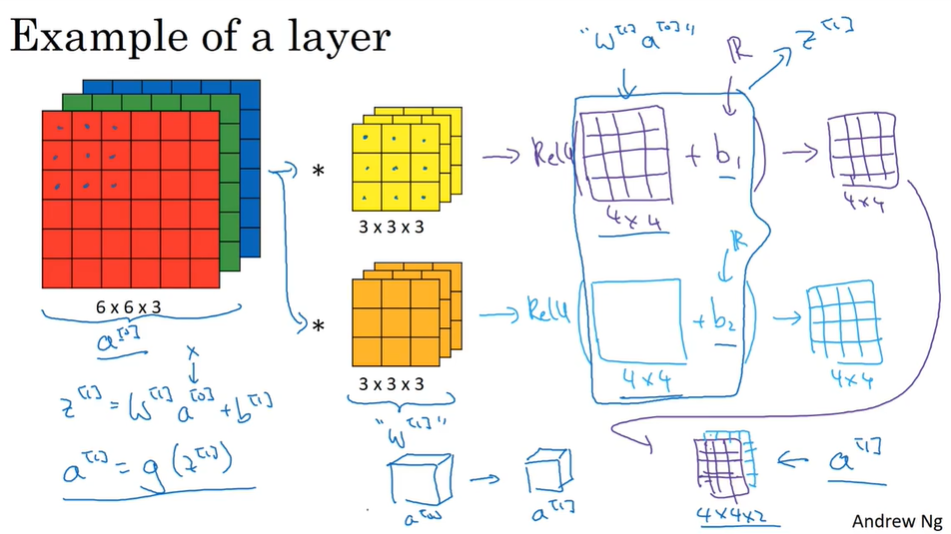
P114 单层卷积层
创建一个单层卷积层

P116 池化层
池化层:减小模型大小 提高计算速度 提高所提取特征的鲁棒性 常用最大池化 还有平均池化
在池化层中一般不用padding 超参数分别为过滤器大小和步长

池化是对每一个通道都池化 最终池化结果与输入的通道数相同 但是卷积结果是一个二维的结果 除非使用多个过滤器提取不同特征 卷积的结果的通道数是与过滤器个数相关的
池化后的尺寸计算方式和卷积相同
P117 卷积网络示例
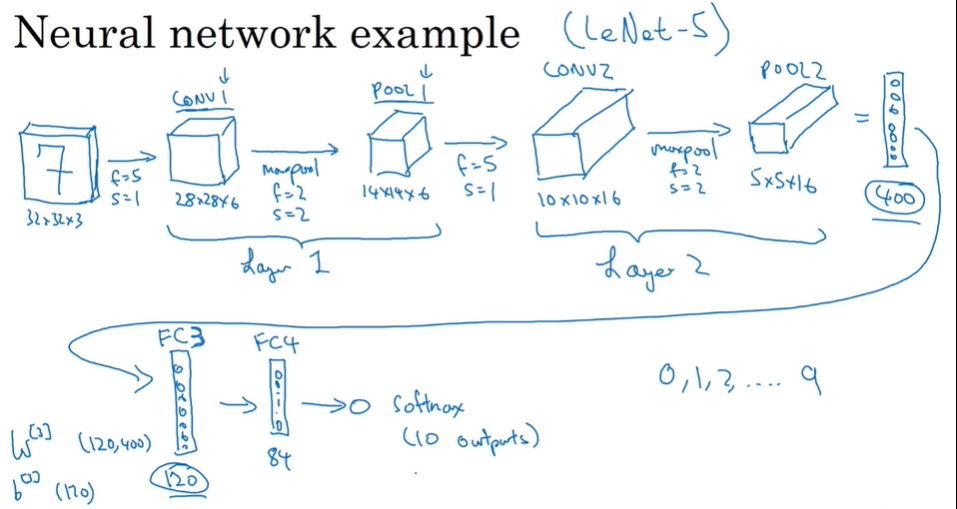
图片的宽度和高度会减小 通道数会增加
计算每一层的激活值大小以及待学习(让神经网络自己学习)参数个数
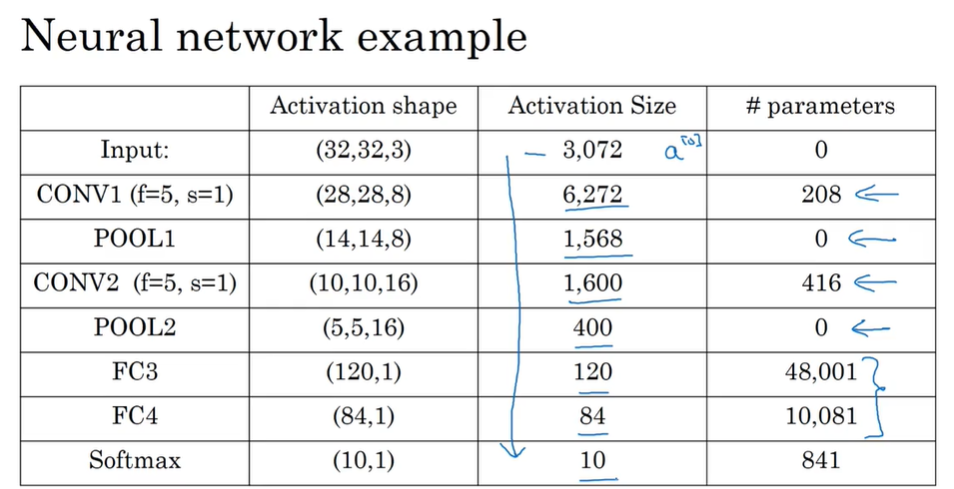
激活值大小都是激活值形状各分量的乘积 输入和池化层没有要学习的参数 卷积层和全连接层都要学习权重w和偏差b 卷积层的每一个过滤器大小都看作一个w 每个过滤器再加上一个偏差b 最后记得要乘上过滤器的个数 全连接层(如下图)的w就是上一层和全连接层一共有多少条线就对应多少个w 然后最后再加上一个b
P118 使用卷积的原因
使用卷积的原因:
- 参数共享:使用同一个过滤器遍历一整个输入
- 稀疏连接:输出的每一个值只与过滤器覆盖到的那几个点有关 跟其他地方的特征无关
这两个特点使卷积需要学习的参数比全连接少 因此也更高效了
P122 残差网络与其作用
残差块:将前面的激活值直接传递到几层以后的输入上
为什么ResNet和DenseNet可以这么深?一文详解残差块为何能解决梯度弥散问题。
残差网络:利用残差块 可以设计更深层的神经网络 减少梯度消失或者梯度爆炸带来的不利影响
残差网络解决了什么,为什么有效?
P123 1×1卷积核
1×1卷积核的作用:加深或者降维原输入的信道深度 因为1×1无法改变输入的长和宽 但是利用不同数量的卷积核可以加深或者降维信道深度
P124 inception网络
inception网络:让网络自己选择中间是用什么样的卷积层或者是用池化层 相比较于一般直接指定一个3×3或者5×5的卷积层 将好多不同的层的选择丢给inception模块 让他自己学习选择用哪个
e.g.inception模块可以先用1×1卷积核(瓶颈层)对信道深度降维 然后再连上有3×3或者5×5卷积核的卷积层 这样会大大减少计算成本
1×1卷积核只对信道深度做出改变
P127 迁移学习
迁移学习:利用别人已经训练好的网络 可能只要修改最后一层输出的维度 或者重新学习最后几层网络的参数(网络层数多的情况下) 而不用重新训练前面层的权重之类的 利用这样的方式对自己的数据集进行训练 更加方便
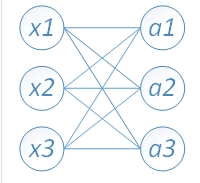
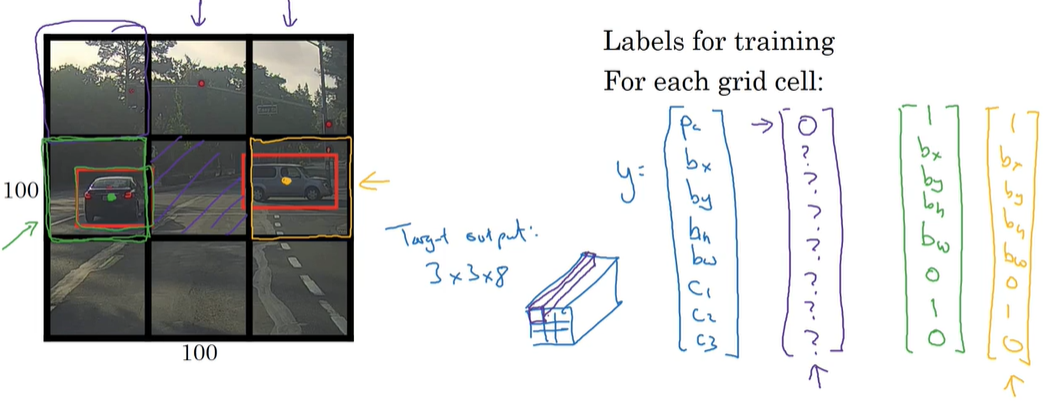
P130 目标定位
目标定位的标签y:
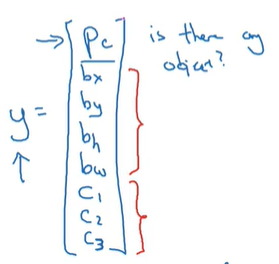
pc表示这个地方有没有物体 bx by记录物体框的左上角坐标 bh bw记录物体框的高度和宽度 c1 c2 c3表示这个物体是哪一类的 只有一个能是1
损失函数:
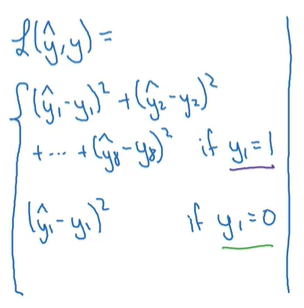
pc为1的时候表示检测到物体 这时候按照第一个公式计算损失函数 pc为0的时候表示没有检测到物体 这时候除了pc以外的几个分量都不重要了
这是利用神经网络进行目标定位的基础
P133 滑动窗口的卷积实现
滑动窗口的卷积实现:
- 用卷积层代替全连接层
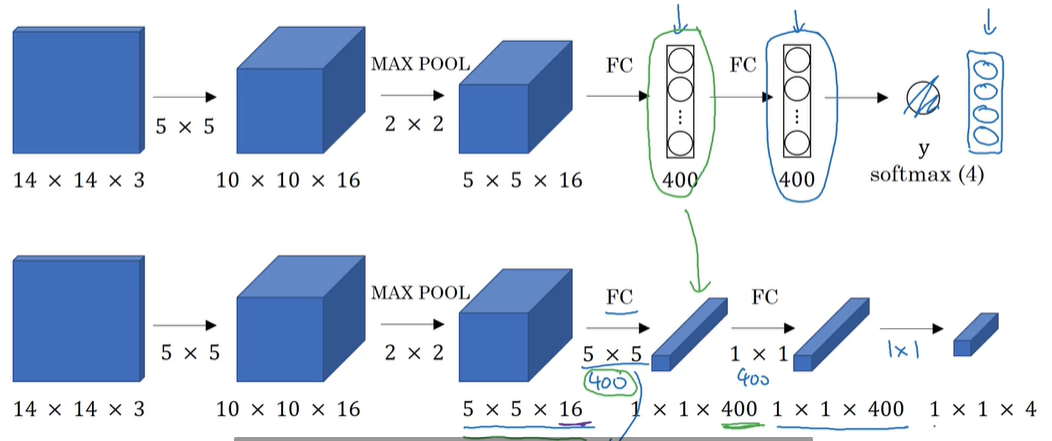
由于卷积的特殊操作 许多计算可以共享 减少了计算成本 - 用卷积实现滑动窗口
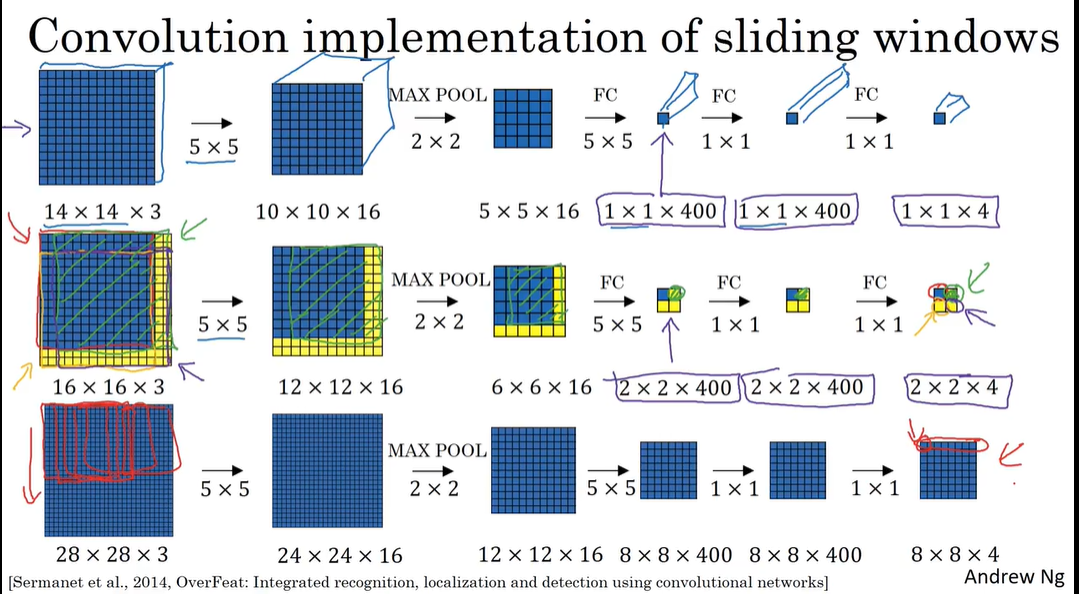
每个卷积核运算后都对应最终结果的一小格(第二行图) - 在对一个图片进行目标检测时 可以对一个图片进行滑动窗口卷积运算 就能一次性找到目标所在窗口 原来是先划出窗口然后对那一个窗口进行滑动窗口卷积运算
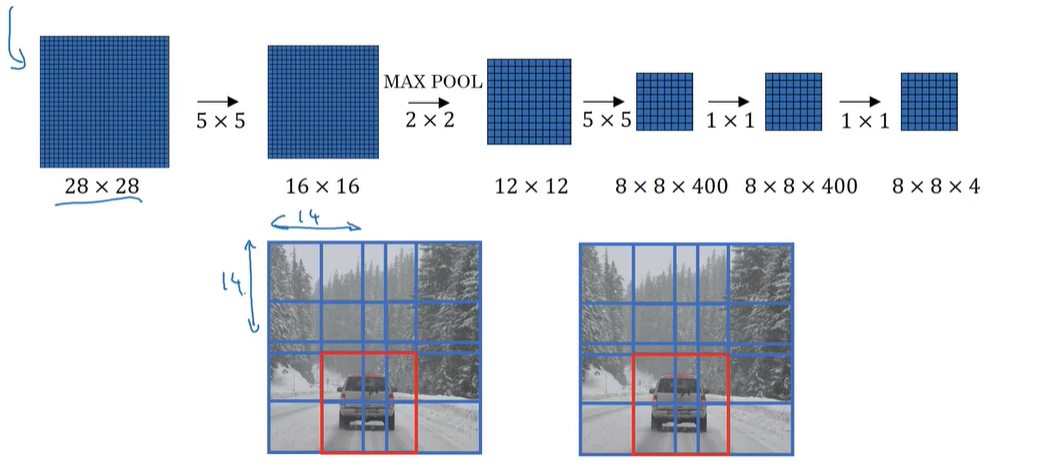
P134 bounding box
bounding box(yolo算法):将一张图分为n×n的格子 然后用滑动窗口卷积实现 选择目标的中点所在的格子作为目标格子
优点:划分的格子可以指定任意大小 也可以利用卷积减少重复计算
P135 交并比
交并比:实际目标的框和算法给出的目标的框的交集和并集的比值 用于衡量目标检测的结果好坏
P136 非最大值抑制
非最大值抑制:目标检测算法可能对一个对象做出多次检测 因此我们要保证对一个对象只做出一次检测
输出的y向量中的pc分量表示检测到物体的概率
非最大值抑制算法:
- 去掉pc小于某个阈值的边框
- 然后选择pc最大的边框 把其他边框隐藏

这只是针对检测一个对象 若想检测多个对象 就要重复进行这个算法
P137 anchor box
anchor box:可以检测出同一个格子里的两个目标对象 用两个交叉的框 通过增加输出变量y的维度 将y的维度扩充成原来的两倍 前8个对应一个目标 后7个对应另一个目标 看目标跟哪种anchor box的交并比高就让哪个anchor box对应的分量表示哪个目标
但是如果两个目标都对应同一个格子里相同形状的anchor box 或者有更多数量的目标在同一个格子里的时候 这时候检测效果不好
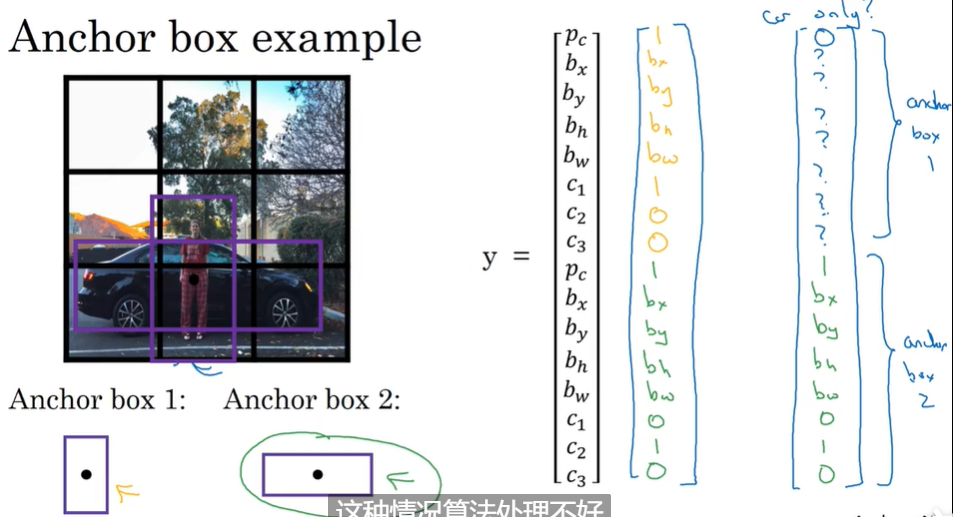
可能在现实中出现两个目标在同一个格子里的情况很少 但是还是要设立anchor box 防止数据集中有高高瘦瘦的行人或者长条的汽车之类的…可以对这类数据做针对性的处理
也可以人为的指定更多种以及不同形状的anchor box以适应不同的情况
P138 YOLO算法
YOLO算法
- 训练:设定划分的格子数(e.g.3) 设定使用的anchor box数量(e.g.2) 设定分的类别(e.g.3) 最后设计出输出的向量y的大小和维度:3×3×2×(5+3)
- 预测:每个格子都有一个输出向量y 观察每个格子的输出向量 如果里面有目标 对应向量的对应部分就会有值
- 使用非最大值抑制输出最后的结果 对于不同目标要分别使用非最大值抑制
P139 R-CNN
R-CNN:原来的目标检测算法会在明显没有目标的格子也进行计算 这样就会产生额外的成本 R-CNN是让算法在可能有目标的区域进行检测 方法是对图像进行分割 选取可能有目标的区域再在上面进行目标检测算法 提升效率
但是仍然不如YOLO算法
P141 一次(One-Hot)学习
在人脸识别场景中 如果按照原来的办法:将一张测试图片放到神经网络里 然后经过卷积和softmax函数输出若干类别的概率 但是这种算法在类别数发生变化的时候需要重新训练网络设定输出的维度 所以我们要对此加以改进
一次学习:设定一个函数d 使得在输入一张图片以后判断这张图片与原数据库里的图片的差异值 差异值越大说明越不是同一个人 最后判断差异值小于某个阈值的时候就是同一个人 这样如果数据库新增了人 也不用重新训练网络 达到一次学习的目的
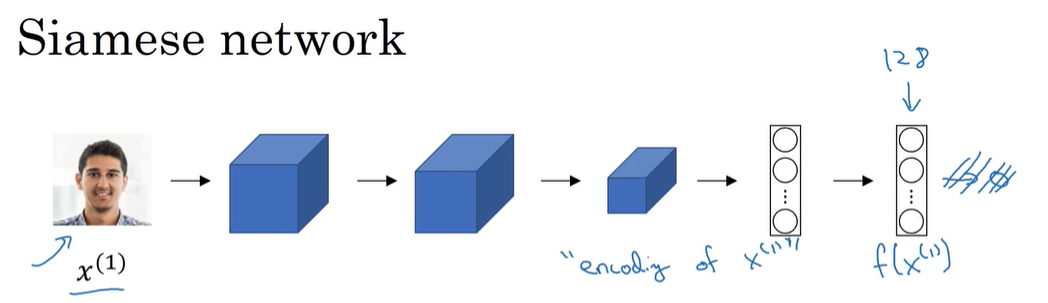
P142 Siamese网络
Siamese网络:将一个图片输入 然后经过一些卷积或者全连接之类的 最后经过一个全连接层输出一个“编码”
P143 三元组损失值
三元组损失值:选取数据库中的一个人脸图像(anchor A) 然后再找一张跟这个人一样的图片(positive P) 再找一个不是这个人的图片(negative N) 计算A和P的差异值 A和N的差异值 做这两个值的差就是损失值 但是为了防止这两个值相差的不多 需要加上一个间隔 让网络把这两个值训练的尽量相差很多 才能准确的识别
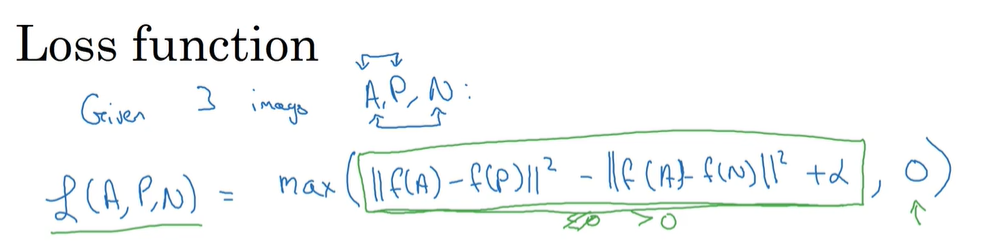
可以看到 当两个差异值之差(再加上间隔)小于0时 我们就认为这个损失值为0 大于0时就取这个差异值为损失值 然后要让这个损失值尽量小
代价函数就是这些三元组损失值之和
选择A P N图片 要尽量选择“看起来像”“相差不大”的图片 才能训练出比较健壮的模型
通过学习三元组损失是一个学习网络参数的好方法
P144 面部识别与二分类
学习网络参数的其他方法:将两张图片分别输入到两个相同的Siamese网络中 将最后两个图片“编码”输入到sigmoid函数里进行预测 这样就将人脸识别问题变成了一个二分类问题:这两个图片是不是(0/1)同一个人
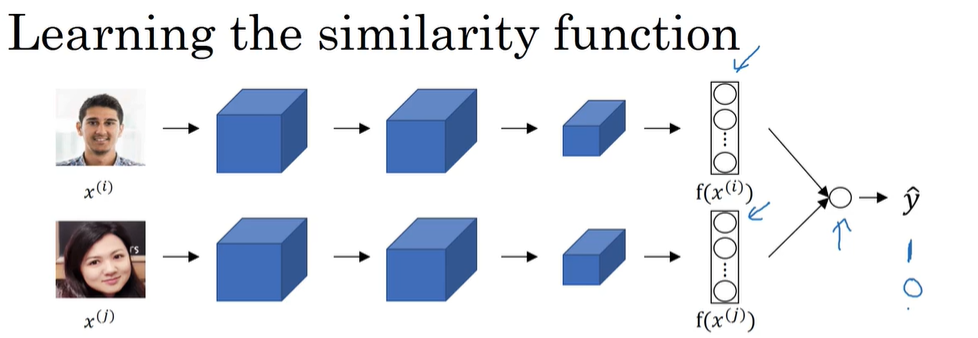
最后的逻辑回归单元函数:

小技巧:我们可以将数据库里的图片编码提前算好 这样来了一个新图片需要识别的时候就可以只计算一次 然后进行二分类 减少计算
P147 风格转换的代价函数
风格转换的代价函数:是对生成图像的每个像素点做代价函数 取内容图片的代价函数和风格图片的代价函数的和
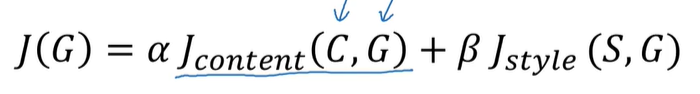
先随机生成一个生成图像 然后计算 让代价函数最小 得出的生成图像越好 因为每次计算完代价函数以后都是对图像的每个像素点进行更新 而不是像之前那样对神经网络参数更新

P148 内容代价函数
内容代价函数:计算生成图像的l层激活值是否与内容图像的l层激活值相似 越相似表示生成图像的内容与原来的内容图像越相似
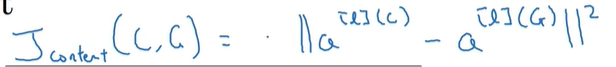
P149 风格代价函数
风格代价函数:与内容代价函数计算方式不同 风格代价函数是通过分别计算风格图像和生成图像各通道的相关性(激活值的协方差 相乘相加)来进行风格迁移 计算出来的相关性是矩阵的形式 最后算差值 如果风格图片各通道相关性和生成图像各通道相关性差不多 说明两个图像风格类似 就完成了风格迁移
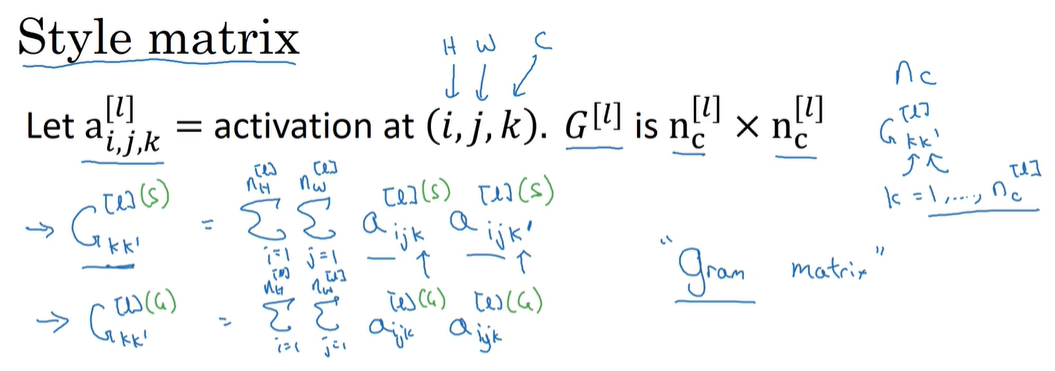

最后将各通道的代价函数加起来就是整个图片的代价函数
P153 RNN
为什么不用之前的神经网络对序列数据做处理?首先 不同样本的输入输出长度不同 其次 不能共享在不同位置学到的特征
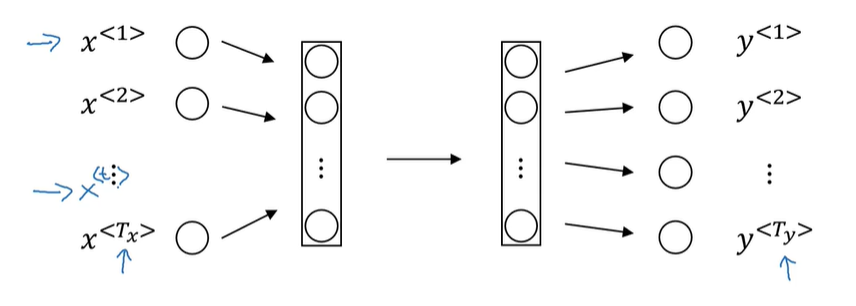
引入RNN网络
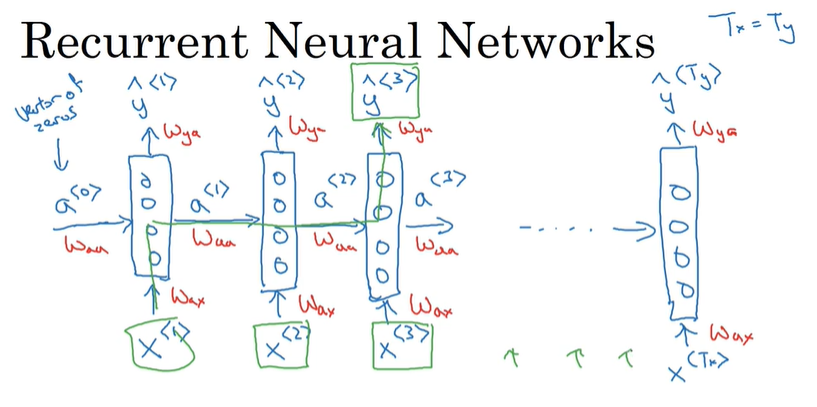
RNN网络的输出不仅跟对应输入有关 还跟之前的输入有关 前面的输入通过a传递给后面 a0是初始化的零向量(也可以自己设定)
但是也有不好 每个输出只跟前面的输入有关 不能跟后面的输入产生关系(BRNN可解决)
RNN的前向传播
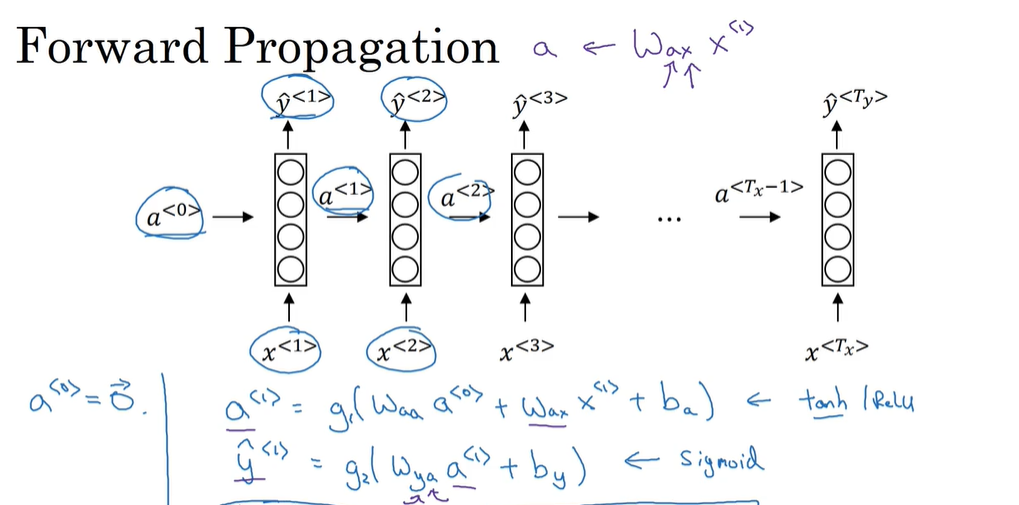
激活值a所用的函数一般是tanh或者ReLU 输出值y如果是二分类的话用sigmoid 多分类用softmax输出不同的概率
前向传播公式简化:
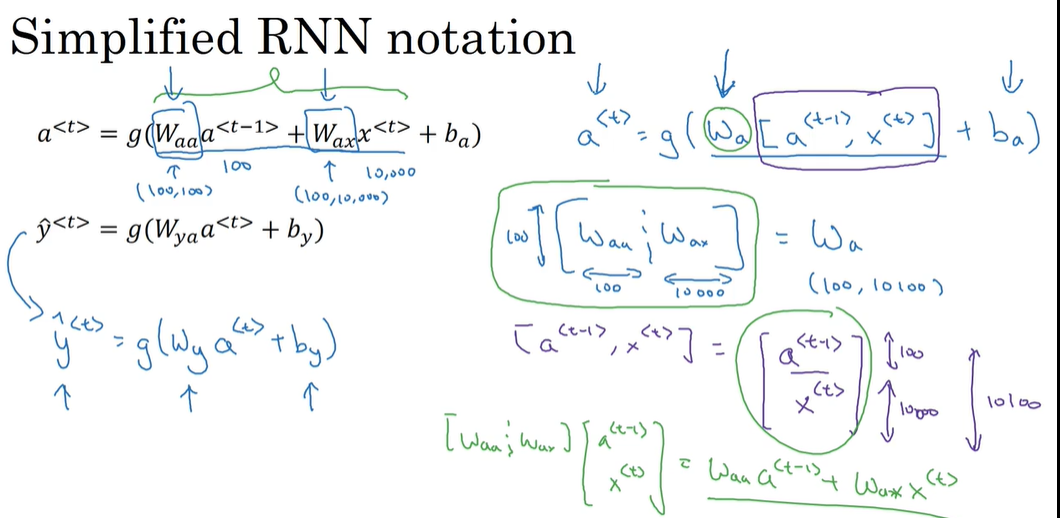
P154 RNN的反向传播
RNN的反向传播
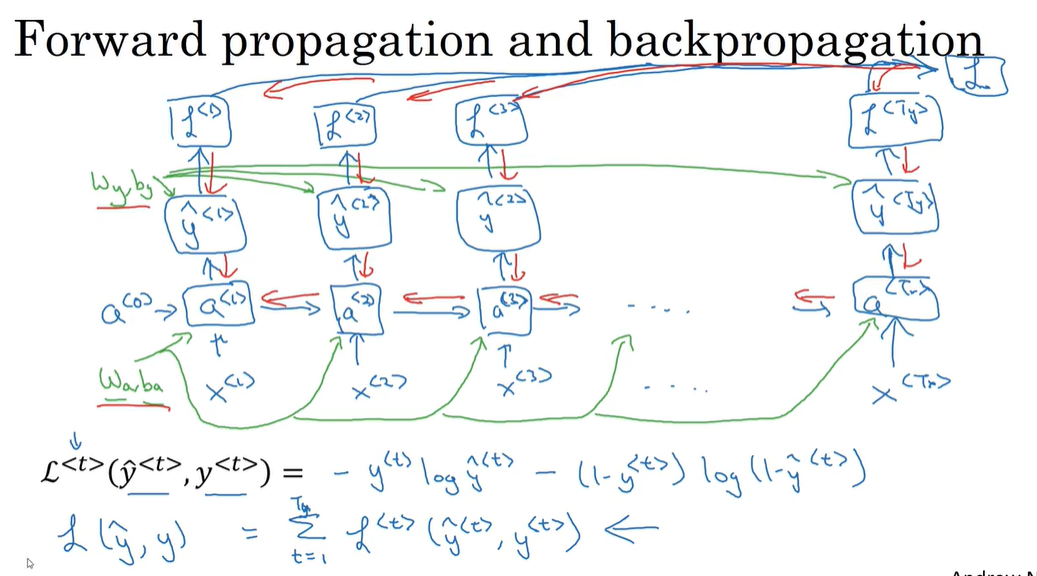
通过导数相关的参数 利用梯度下降算法更新参数
P155 不同类型的RNN
不同类型的RNN
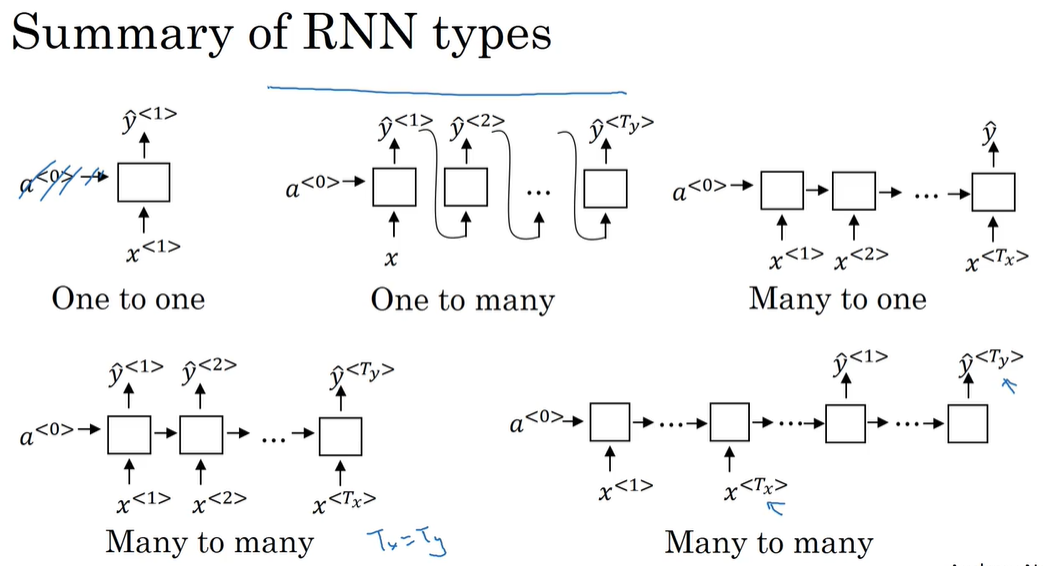
一对一:输入一个输出一个
一对多:输入一个输出很多个 比如给网络一个音符或者空值 可以输出一段旋律
多对一:输入很多输出一个 比如给网络一段影评(有很多字) 判断是好评还是差评(0/1)
多对多:有输入和输出长度相同的 也有不同的 对应网络结构不同
P156 语言模型与序列生成
语言模型:将句子中的每个词语作为一个输出分量 计算这些分量同时出现的概率(乘积)作为最后句子的概率输出
用RNN训练语言模型:选取很长的 数量众多的英文句子组成的文本做训练集 设计一个词语字典 将一个句子的每个词语根据字典设计出独热码作为输出的真实值y(句子的结尾是EOS 字典里没有的单词记为UNK) 输入x是上一个预测输出y x0是零向量
训练过程:
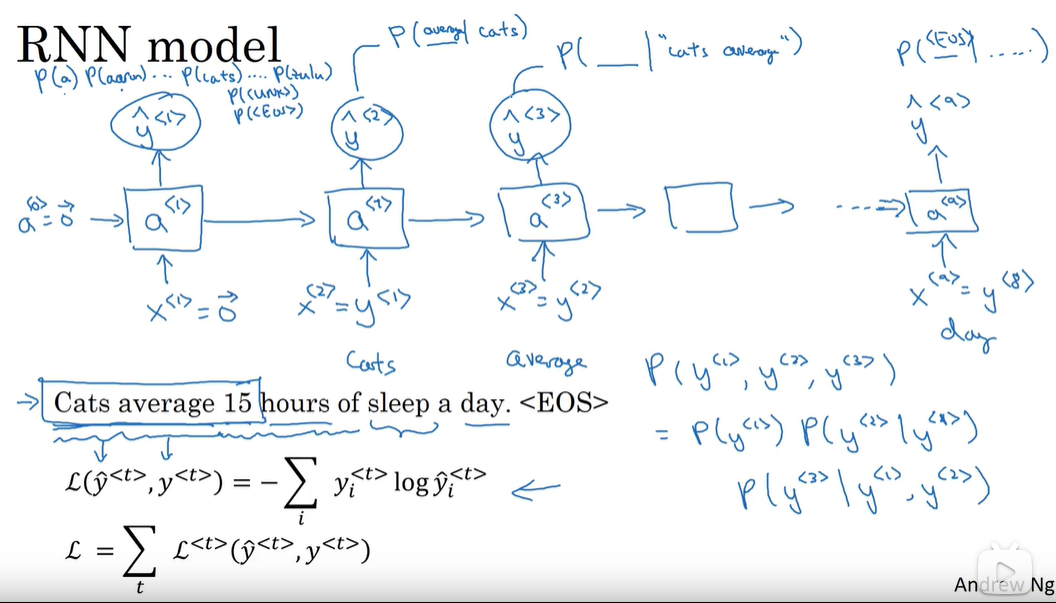
P157 新序列采样
新序列采样:用训练好的RNN模型生成一个新序列
吴恩达深度学习-序列模型 1.7 对新序列进行采样
1.7 对新序列采样-深度学习第五课《序列模型》-Stanford吴恩达教授
P158 梯度消失与梯度爆炸
梯度消失:会让RNN没法处理长期的依赖关系 让前面的影响传递不到后面 使用GRU处理这个问题
梯度爆炸:很好看出来 因为参数会变得很大 这时候可以直接判断参数是否大于一个阈值 如果大于 就对梯度向量进行缩放 来进行梯度修剪
P159 GRU单元
GRU单元:通过一个记忆单元把前面的影响因素“记住” 然后在后面要用到的时候不会被梯度消失掉 具体设计如下:
简易版GRU:

c’代表记忆单元 在这里先令c=a(a是激活值) c波浪线表示c的一个候选值 gamma表示门控单元 作用是选择新的记忆单元是还要记住之前的内容还是新的候选值
在实际设计中 c c波浪线 gamma都是与输入相同维度的向量 (因此*表示对应元素相乘) 向量的每个元素都对应不同输入 比如门控的不同分量就代表对不同记忆单元的设置 可能有些单元是记住之前的内容 有些是要用新的候选值 其他同理
完整的GRU:
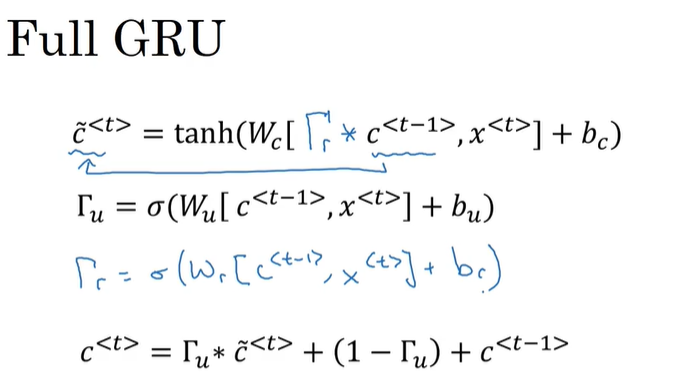
完整的GRU加上了新的门控单位 表示过去的记忆单元的值对新的候选值的相关性有多大 r表示相关性
P160 LSTM

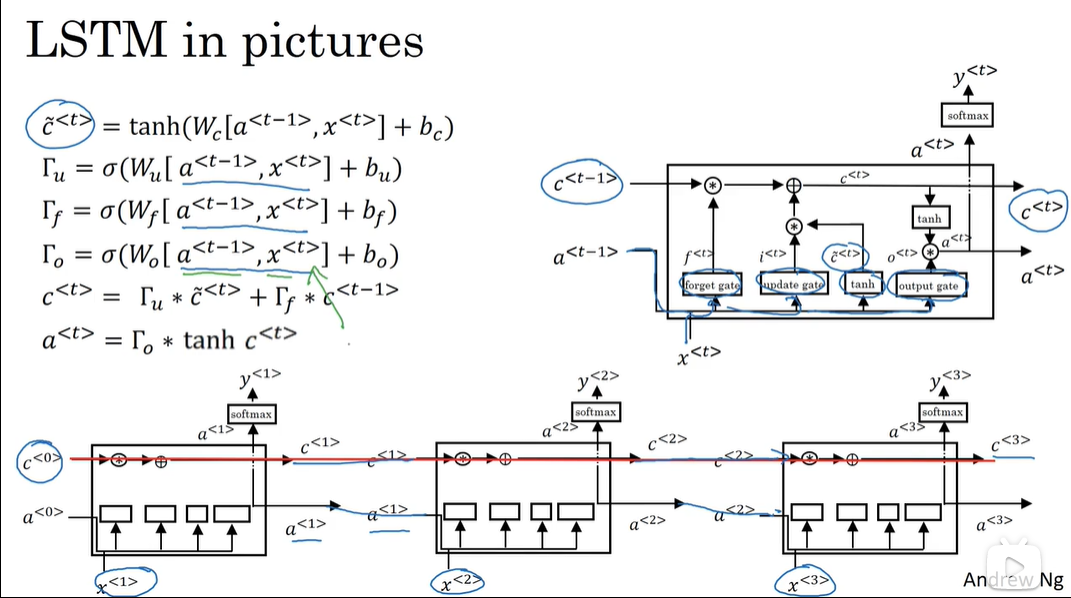
跟GRU比,
1)C跟a分开了,可以说是在C的基础上,另外创建了一个a,a为 C经过再次tanh激活值乘以一个output gate
2)C的候选值的生成由Ct-1改为了a,且将此处的udpate gate去掉
3)C值更新时,update gate直接对C候选值作用
在LSTM中,C值(memory cell)的update gate设置合理时,比较容易保存很长时间。 常用的LSTM中,上图中的3个gate还包括C值,这叫peephole connection窥视孔连接.
C值有100维时,每个维度单独影响自己这个维度的更新;
LSTM比GRU早提出,更powerful灵活点,效果好点,是更多人的选择,GRU是一种LSTM的简化,简单点,可以构建和适应更大的网络
引用自吴恩达深度学习课程脉络(五)序列建模
可以看到每个单元输出的c值是作为下个单元的输入 只要设置好对应门控单元的值 在网络深处也可以受到网络前面的单元的值的影响 这就避免梯度消失带来的负面影响
P161 双向循环神经网络
双向循环神经网络:不仅定义了一套正向的参数 还定义了一套反向的参数(与正向传播和反向传播不同 正向传播传播的是参数 反向传播传播的是参数的梯度 用于进行梯度下降算法寻找最优参数的) 这样做的目的是为了让中间的一个预测值不但能收到前面的输入的影响 也能受到后面的输入的影响 这样更好
缺点:必须确定一个完整的输入 比如说必须输入一个完整的句子 在现实情况中可能不能等到获取了完整输入以后才对句子成分进行判断或者预测 所以根据不同的情况会有不同的更精细的模型设计
但是如果能获取到一个完整的输入的话 双向循环神经网络的效率也比较高
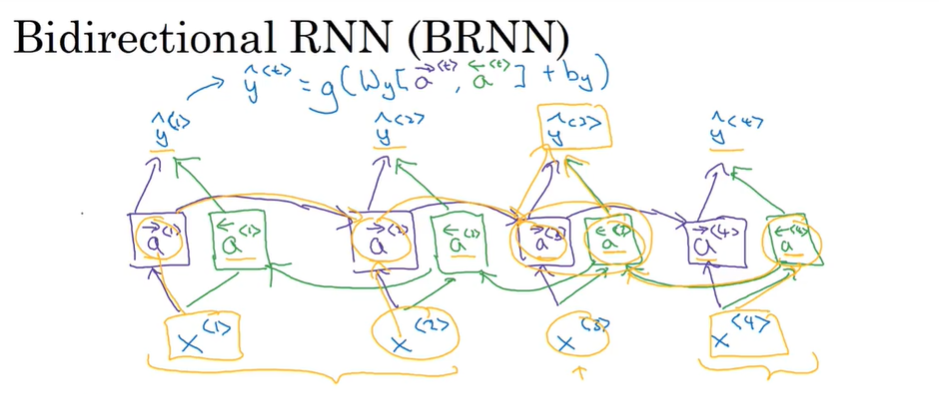
P162 深层的RNN
深层的RNN其实就是把各种RNN网络叠在一起 来实现更加复杂的函数
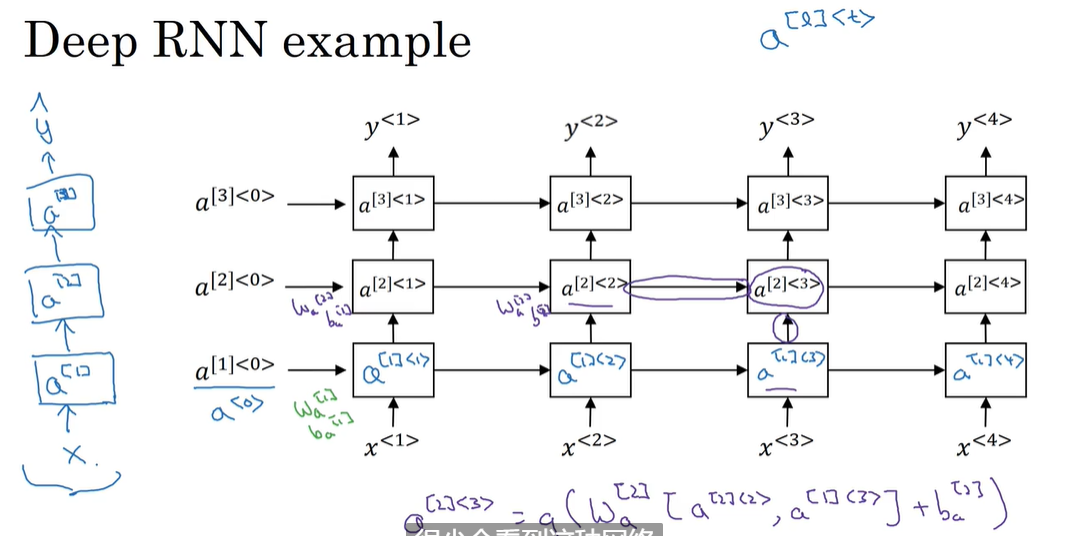
RNN与前面的卷积神经网络不同 因为与时间相关 因此就算很少的层数也会随着时间的推移产生大量的计算成本 因此深层RNN一般也不会很深 不然计算成本太大了
P163 词汇表征
之前说到的只是用独热码表示每个单词 这样难以确认单词之间的关系 如果要预测一句话其中的一个词 单词之间没有关系的话就很难预测 这时候就引入了词嵌入的概念 同特征化的方法来表示每个词

计算两个分量的差值 如果两对词的差值相近或者相同说明这两对词有相似的关系 比如第一行的Man和Woman King和Queen
P164 使用词嵌入
使用迁移学习和词嵌入:
- 用很大的数据集学习词嵌入 或者可以直接从网上下载训练好的模型
- 将刚刚训练好的结果迁移到更小的模型上
- 别忘了当有新数据的时候微调模型
在人脸识别领域也可以用同样的方法 训练了海量的人脸图像以后 就可以很快判断再输入的是不是人脸
P165 词嵌入特性
词嵌入也可以帮助进行类比推理

比如说 问你man对woman 那么king对什么?这时候计算两两词不同特征之间的差值 找到跟man和woman差值一样或相近的就说明可以配对上(还要不为0)
想要找到这个值 可以用cos相似计算 公式如下

当这个公式值最大时 说明对应词和king的差值与man和woman的差值最接近 即为所求解
用cos相似刚好可以利用余弦函数的特点 若值为1说明差值相等 值为0说明正交 差值完全不等 类似还可以用两个向量之间的距离等等来算两组词的相似度
P166 嵌入矩阵
用独热码找到对应的嵌入值:嵌入矩阵是由字典里所有的单词组成的 有了待求单词的独热码之后就能知道这个单词在字典中是什么位置 然后用函数取出嵌入矩阵的某一列就是他的嵌入值
P167 学习词嵌入
学习词嵌入:将每个词的独热码乘上嵌入矩阵得到嵌入值(嵌入向量) 将整个句子所有的嵌入值都放到神经网络中进行训练 最后用一个softmax函数输出对应预测概率
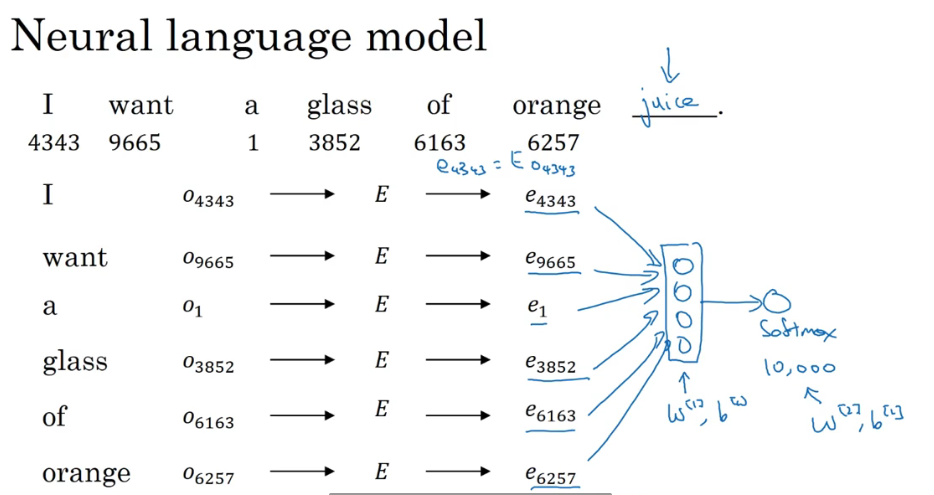
但是这样有一个问题就是网络中训练的向量太多了 会带来很大的计算成本 这时候可以采取简化的方法 设置固定的窗口大小 只让待预测值的前几个单词输入到网络里进行预测 刚好待预测词的前几个词跟这个词一般来说都有比较大的相关性 这样既降低计算成本又能准确
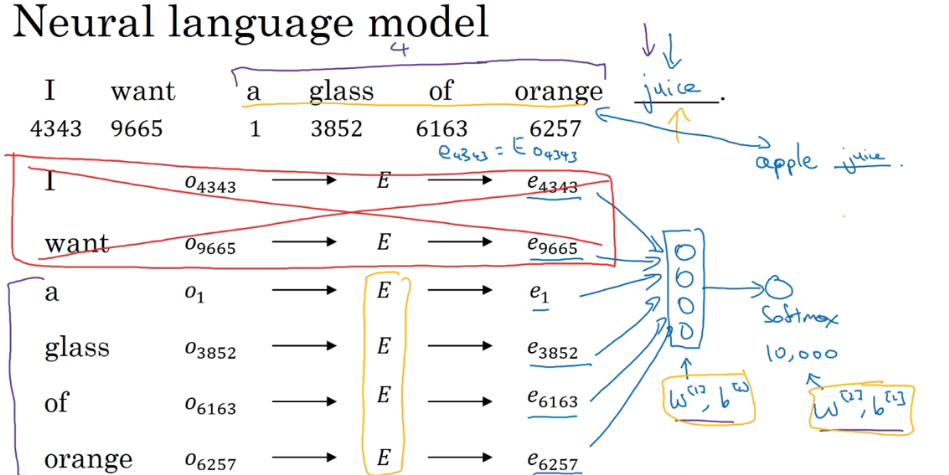
如果要学习预测某个词的话 可以只选择待预测词的前几个单词 但是如果要学习词嵌入的话 需要选择待预测词的前后几个单词同时进行训练分析
P168 word2vec
word2vec之skip-gram:是一个监督学习问题 给定一个上下文词 然后要求预测在这个上下文词的正负10或5或其他数量的词距的某个目标词是什么 这个方法的目标是学习到一个比较好的词嵌入模型
模型细节:将上下文词的独热码乘上嵌入矩阵 得到对应的嵌入值 然后传给一个softmax 得出预测结果 softmax和损失值公式如下:
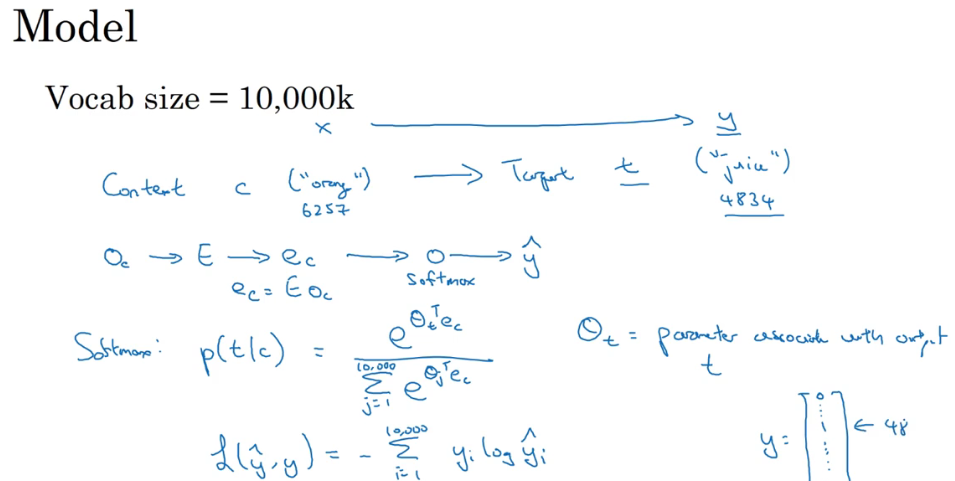
其中theta t是输出t和标签的相符的概率
可阅读:理解 Word2Vec 之 Skip-Gram 模型
P169 负采样
负采样:减少训练的计算成本 不但将正确的分类传入网络 还会根据一定的概率选择上下文词附近的其他词语作为错误的样本跟正确的样本一起传入网络进行训练 这样不用把上下文词和句子中的每个词都配对传入网络 大大减少训练的计算成本
当数据量小的时候 传入的负采样个数为5-20个 大的时候传入2-5个
根据如下概率公式选择负采样的样本:
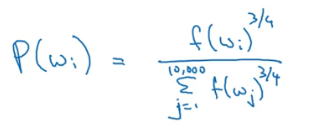
P170 GloVe
看不懂
P171 情绪分类
情绪分类:给一个句子 判断对方在说这个句子的时候的情绪 先用词嵌入 可以对相近意思的词语先做一个训练学习 因为表达相同情绪的词可以有很多不同的表达 然后将句子放入到一个多对一的RNN中 这样可以根据若干词语判断出某种情绪
P172 词嵌入去偏
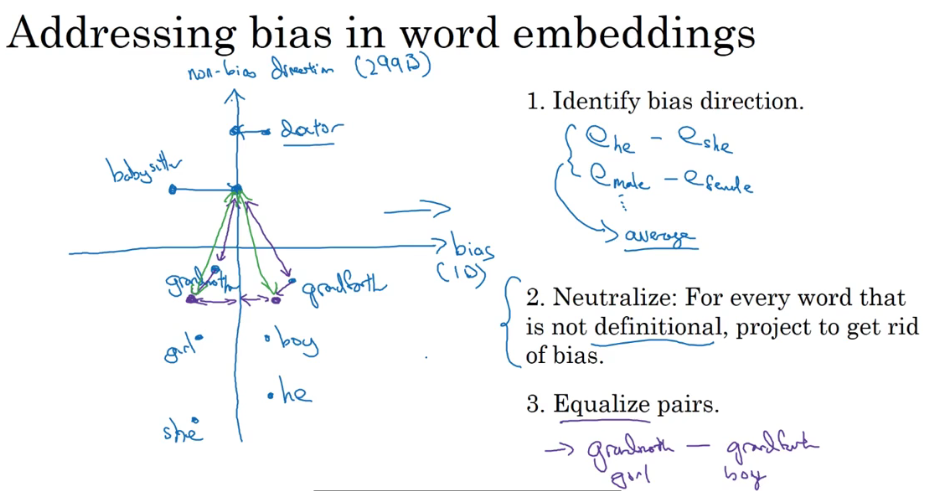
词嵌入去偏:去除类似于性别歧视或者其他带有偏见的词语关系
- 定义偏见的趋势
- 中和:对于定义不明确的词 处理一下避免偏见 也就是说有些词没有那么明显的偏见定义 就要对他们进行处理 让他们成为中性词
- 均衡:修正某些词在坐标上的位置 比如修改grandmother和grandfather的位置 让这两个词和babysister的距离一致 因为babysister是我们定义的中性词 如果距离不一致很有可能导致偏见
P173 基础模型
模型1:输入一个法语句子 翻译成英语
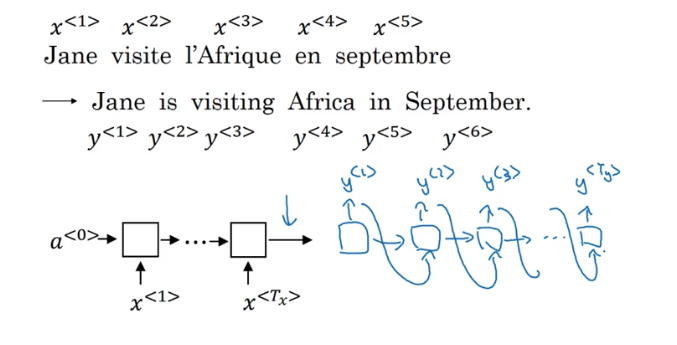
用到RNN模型(不一样长度的多对多) 将这个待翻译的句子逐字输入到网络里 然后再逐字预测
模型2:输入一个图片 输出对应图片的描述
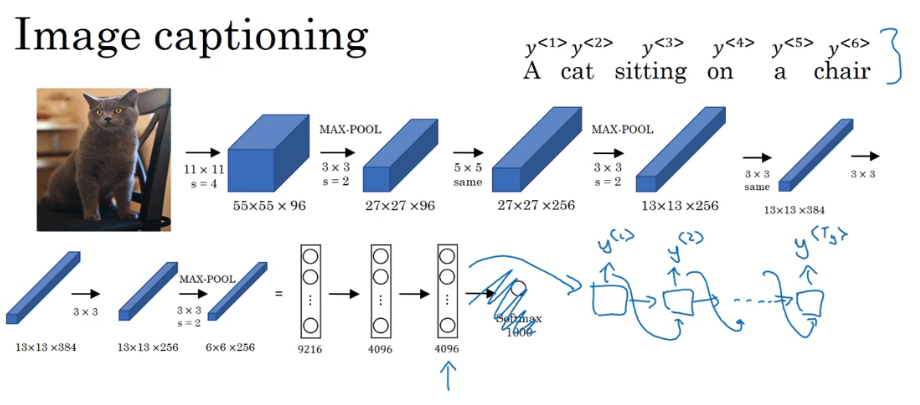
将这个图片放到AlaxNet里训练 将最后的softmax层去掉 连接上类似于RNN的结构 利用最后得到的4096个向量连上RNN的输出 逐字预测对应的描述
P174 贪心搜索
通过计算英文翻译对应输入的法语句子的可能性概率值来判断这个翻译好不好(找最大值)
贪心搜索:生成第一次词语以后 他会根据你的条件语言模型挑选出最有可能的一个词进入机器翻译模型中…每次都挑出最有可能的一个词 然而我们的目标是挑选出单词序列使得整个句子的概率最大 有可能每次都选最大概率的词 最后组成的句子的概率不如别人
P175 集束搜索
集束搜索:通过设置一个集束宽(eg.3) 每次计算后选择最大概率的3个单词继续计算 该算法只是使生成目标函数最大化 找到最好的翻译 并没有改变网络模型
第一步:
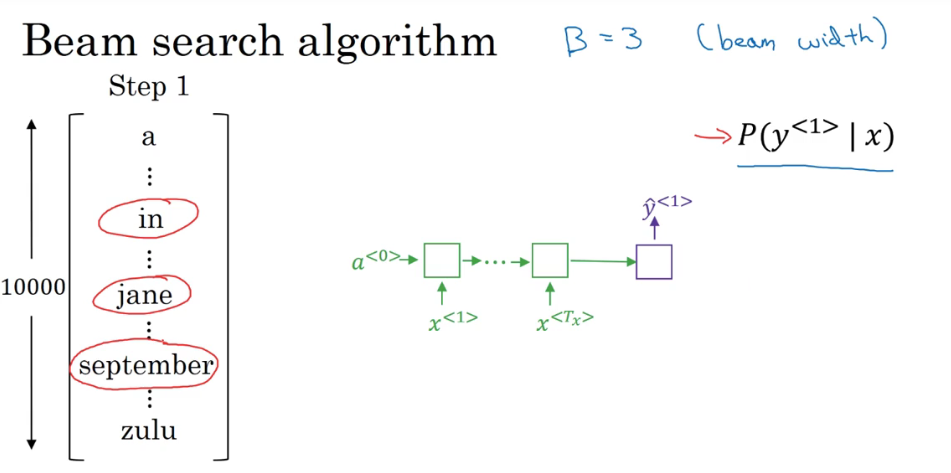
第一步找出了每个单词的条件概率 保留最高的三个进入下一步
第二步:
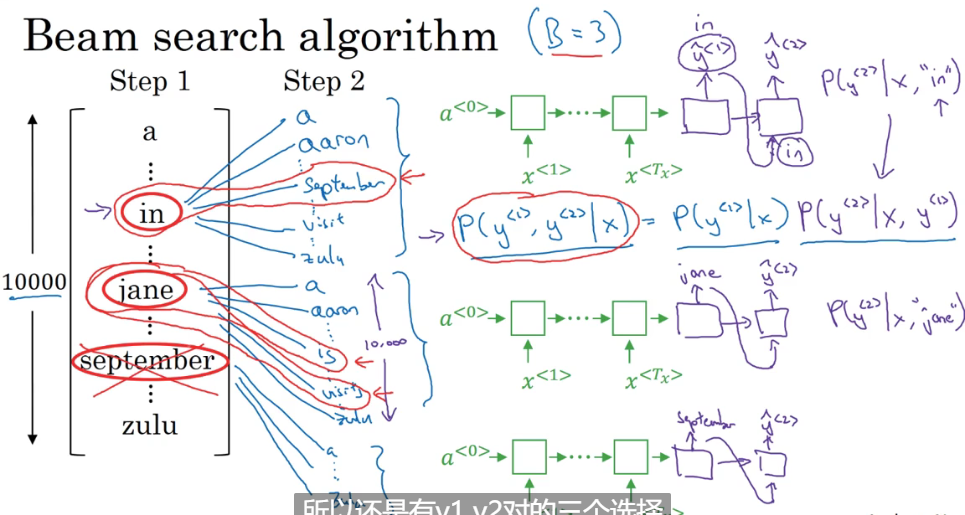
对于刚刚第一步选出来的三个单词 再找这三个单词的下一个单词 并计算每组单词组合的条件概率 同样选出最大概率的三个(不是每个单词选最多的一个组成三个 是所有单词组合选出最大的三个 所以有可能刚刚第一步选的某个单词在这一步被抛弃了 比如September) 再进入下一步
第三步:
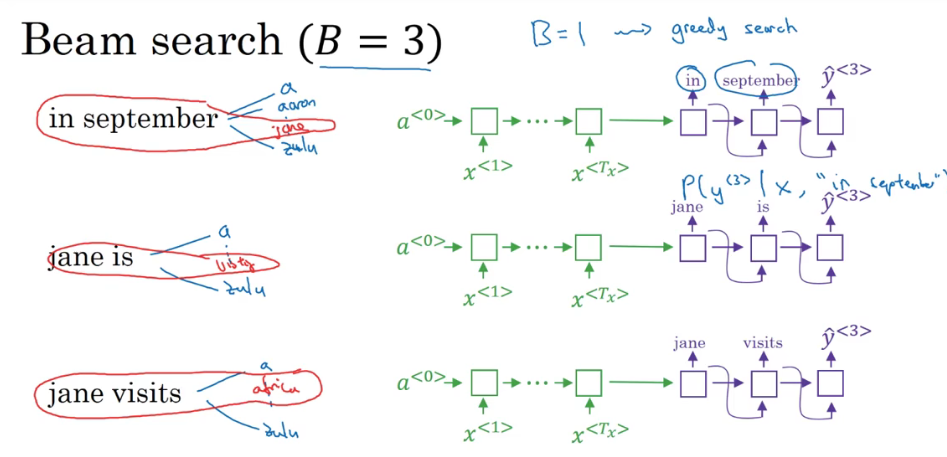
其实过程同前两步 然后就一直搜索单词 直到句尾符号
P176 对于集束搜索的一些改进
对于集束搜索的一些改进:长度归一化

由于原来的概率计算是相乘的 每个概率都小于1 这样相乘出来的结果会很小 有可能导致数值下溢 因此对原函数进行取对数 这样乘积就变成了累加和 然后再通过除以翻译结果的单词数量进行归一化操作 这样减少了输出长结果带来的负面影响(可能数值会变得很小) 为了更加柔和 对单词数量再加上一个指数幂alpha(超参数) alpha可以取0-1之间的数 一般取0.7 如果alpha=1 则完全归一化 如果alpha=0 则不归一化
对于集束宽:越大 搜索出来的结果越优 但是计算代价越大 运行时间越久 越小 计算速度越快 计算代价越小 但是搜索出来的结果就越差 当宽度为1时 退化为贪婪搜索 一般取10(小型)100(大型) 当宽度从3改进到10时 效果明显 如果是从1000-3000 效果不明显
相比较于深度优先、广度优先算法 集束搜索速度更快 但是不一定能搜到准确的最大值
P177 集束搜索的误差分析
集束搜索的误差分析:误差分析是为了找出待优化的算法/结构
在构建好RNN网络之后 利用集束算法找到最优的结果 将结果设为y^ 将人类翻译的结果设为y* 默认人类翻译的都比机器翻译的好(也就是条件概率更高)将两个结果分别放入训练好的RNN里求条件概率 比较这两个结果计算出来的条件概率 就可以知道是集束算法待优化还是RNN网络结构待优化
可以通过增加宽度改进集束算法 也可以通过增加训练数据或者增加正则化调整RNN网络结构甚至改变网络结构

如果人类的概率比机器翻译的高(正常) 说明应该改进算法让机器翻译的概率更接近人类翻译
如果人类的概率比机器翻译的低 那么说明RNN模型出错了 因为正常人类的应该更高
P178 Bleu得分
Bleu得分:评估机器翻译准确性的指标
看不懂
剩下的暂时没看懂
P180 注意力机制
注意力机制:更加关注到需要注意的部分(分配权重) 与LSTM和RNN有点不同 前者更关注时间上的前后关系 而注意力机制不一定只关注前后时间上发生的事情
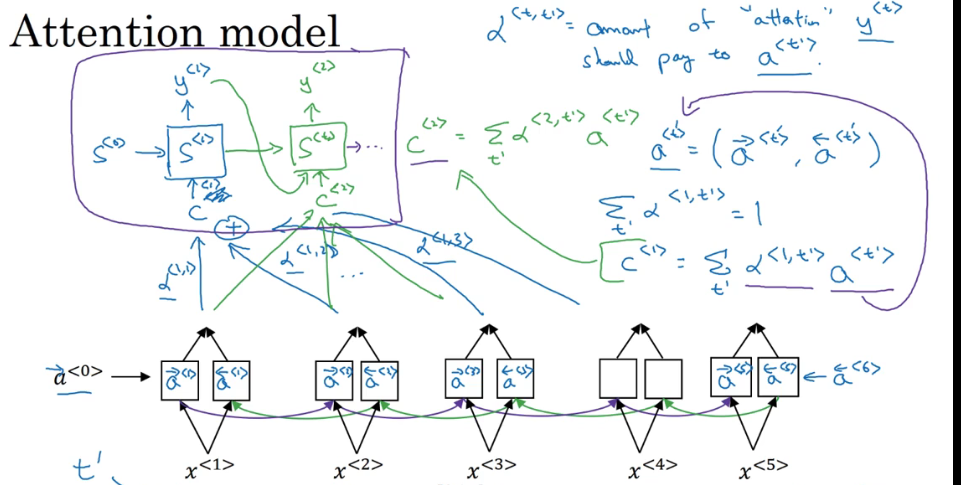
用一个双向RNN针对输入计算出正向和反向的激活值 输出的部分也类似于一个RNN网络结构 设置输出y所需要对每个激活值有多少的注意力alpha 用alpha×激活值可以得到一个上下文值 将这个上下文值输入到翻译的网络结构中 输出最终的翻译内容
计算注意力参数alpha:
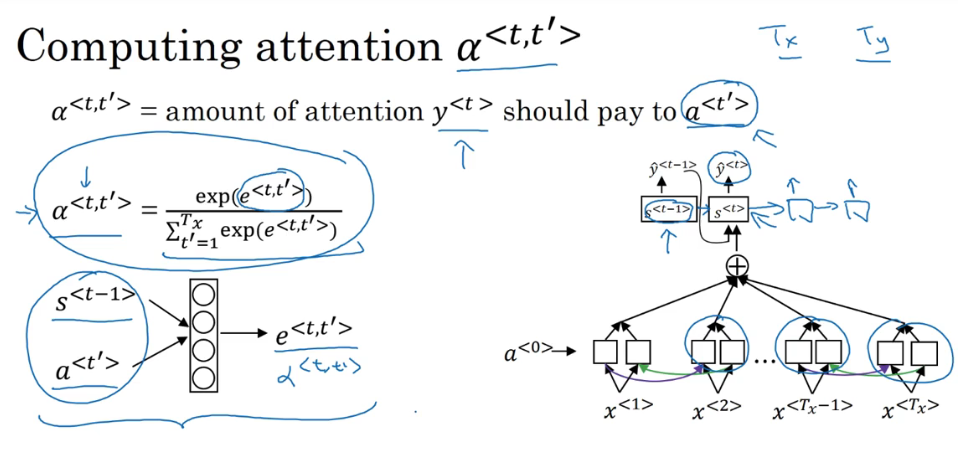
通过计算一个e来计算alpha 可以看到所有分量的注意力值之和为1 这个e是与之前的翻译s和当前输入的激活值a有关的 但是具体的函数关系未知 因此将s和a放入一个很小神经网络中进行训练 通过反向传播算法和梯度下降算法找到对应的函数关系
这个机制的一个缺点是会产生二次方的消耗 当输入为Tx个单词 输出为Ty个单词时 复杂度为Tx×Ty 但是一般输入输出的句子都不长 因此这样的消耗在某些时候是可以接受的
P181 语音识别
建立语音识别系统:
- 利用注意力机制:在输入的音频的不同时间帧上用一个注意力模型
- CTC函数做语音识别:
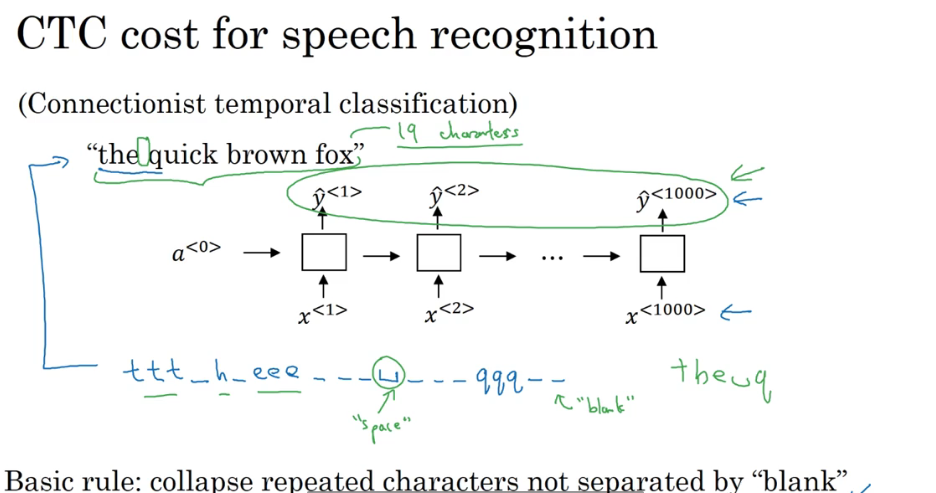
建立一个简单的单向RNN模型 输入和输出的个数一样 这时候输入的个数会很多 比如说有一段10秒的音频 每秒有100个样本 所以一共就有1000个样本 但是真实说的语句只有4个单词 这时候可以让RNN输出相同的重复字母或者空白字符 空白字符不等于空格 这时候CTC就是将重复的单词或者空白的字符折叠起来 折叠完以后就会得到正确的输出的句子了
P182 触发字检测
触发字检测:
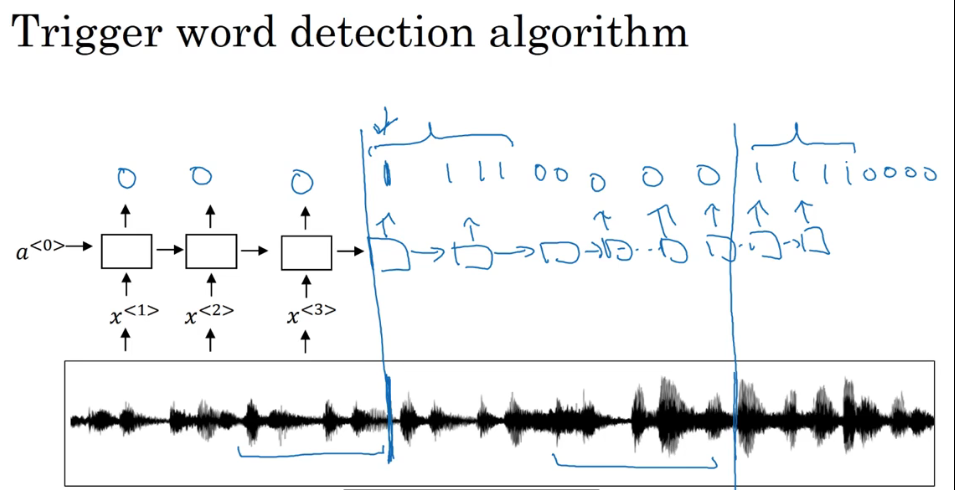
构建一个RNN模型 在没有检测到触发字的时候让RNN的输出都为0 检测到触发字以后输出为1 但是这样的话0会比1多很多 所以可以在检测到触发字以后的一小段时间内都输出1 这样简单粗暴的短暂提高1和0的比例
P183 完结撒花
完结 撒花

最后
以上就是平淡自行车最近收集整理的关于吴恩达深度学习笔记P3 用神经网络进行监督学习P4 深度学习的兴起P7 二分分类P8 logistic回归P10 梯度下降法P14 使用计算图求导P16 批量梯度下降P17 向量化P21 广播机制P22 关于numpyP24 logistics损失函数P26 神经网络的表示P28 多个样本向量化P30 激活函数P31 使用非线性激活函数的原因P35 随机初始化参数P36 深层神经网络P40 使用深层的神经网络的原因P41 搭建深层神经网络块P42 超参数P47 训练集验证集测试集P48 偏差和方的全部内容,更多相关吴恩达深度学习笔记P3内容请搜索靠谱客的其他文章。








发表评论 取消回复