一.学习目标
- 线性回归的原理
- 线性回归损失函数、代价函数、目标函数
- 优化方法(梯度下降法、牛顿法、拟牛顿法等)
- 线性回归的评估指标
- sklearn参数详解
二.学习内容
2.1线性回归原理
线性回归是机器学习中最简单的回归算法,多元线性回归指的就是一个样本有多个特征的线性回归问题。对于一个有n个特征的样本而言,它的回归结果可以写作一个几乎人人熟悉的方程:
y
^
i
=
w
0
+
w
1
x
i
1
+
w
2
x
i
2
+
…
+
w
n
x
i
n
hat{y}_{i}=w_{0}+w_{1} x_{i 1}+w_{2} x_{i 2}+ldots+w_{n} x_{i n}
y^i=w0+w1xi1+w2xi2+…+wnxin
也可以转化成为矩阵的形式
[
y
^
1
y
^
2
y
^
3
⋯
y
^
m
]
=
[
1
x
11
x
12
x
13
…
x
1
n
1
x
21
x
22
x
23
…
x
2
n
1
x
31
x
32
x
33
…
x
3
n
…
1
x
m
1
x
m
2
x
m
3
…
x
m
n
]
∗
[
w
0
w
1
w
2
…
w
n
]
left[begin{array}{l} hat{y}_{1} \ hat{y}_{2} \ hat{y}_{3} \ cdots \ hat{y}_{m} end{array}right]=left[begin{array}{cccccc} 1 & x_{11} & x_{12} & x_{13} & dots & x_{1 n} \ 1 & x_{21} & x_{22} & x_{23} & dots & x_{2 n} \ 1 & x_{31} & x_{32} & x_{33} & dots & x_{3 n} \ & & dots & & \ 1 & x_{m 1} & x_{m 2} & x_{m 3} & dots & x_{m n} end{array}right] *left[begin{array}{c} w_{0} \ w_{1} \ w_{2} \ dots \ w_{n} end{array}right]
⎣⎢⎢⎢⎢⎡y^1y^2y^3⋯y^m⎦⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎡1111x11x21x31xm1x12x22x32…xm2x13x23x33xm3…………x1nx2nx3nxmn⎦⎥⎥⎥⎥⎤∗⎣⎢⎢⎢⎢⎡w0w1w2…wn⎦⎥⎥⎥⎥⎤
线性回归的任务,就是构造一个预测函数来映射输入的特征矩阵
X
mathbf{X}
X和标签值
y
y
y的线性关系,这个预测函数在不同的教材上写法不同,可能写作
f
(
x
)
,
y
w
(
x
)
f(x), y_{w}(x)
f(x),yw(x)或者
h
(
x
)
h(x)
h(x)等等形式,但无论如何,这个预测函数的本质就是我们需要构建的模型,而构造预测函数的核心就是找出模型的参数向量
w
boldsymbol{w}
w。
样例
进入一家房产网,可以看到房价、面积、厅室呈现以下数据:
| 面积($x_1$) | 厅室数量($x_2)$ | 价格(万元)(y) |
|---|---|---|
| 64 | 3 | 225 |
| 59 | 3 | 185 |
| 65 | 3 | 208 |
| 116 | 4 | 508 |
| …… | …… | …… |
我们可以将价格和面积、厅室数量的关系习得为 f ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 f(x)=theta_0+theta_1x_1+theta_2x_2 f(x)=θ0+θ1x1+θ2x2,使得 f ( x ) ≈ y f(x)approx y f(x)≈y,这就是一个直观的线性回归的样式。
线性回归的一般形式:
有数据集
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
n
,
y
n
)
}
{(x_1,y_1),(x_2,y_2),...,(x_n,y_n)}
{(x1,y1),(x2,y2),...,(xn,yn)},其中,
x
i
=
(
x
i
1
;
x
i
2
;
x
i
3
;
.
.
.
;
x
i
d
)
,
y
i
∈
R
x_i = (x_{i1};x_{i2};x_{i3};...;x_{id}),y_iin R
xi=(xi1;xi2;xi3;...;xid),yi∈R 其中n表示变量的数量,d表示每个变量的维度。 可以用以下函数来描述y和x之间的关系:
f
(
x
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
+
…
+
θ
d
x
d
=
∑
i
=
0
d
θ
i
x
i
begin{aligned} f(x) &=theta_{0}+theta_{1} x_{1}+theta_{2} x_{2}+ldots+theta_{d} x_{d} \ &=sum_{i=0}^{d} theta_{i} x_{i} end{aligned}
f(x)=θ0+θ1x1+θ2x2+…+θdxd=i=0∑dθixi如何来确定
θ
theta
θ的值,使得
f
(
x
)
f(x)
f(x)尽可能接近y的值呢?均方误差是回归中常用的性能度量,即:
J
(
θ
)
=
1
2
∑
j
=
1
n
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
J(theta)=frac{1}{2}sum_{j=1}^{n}(h_{theta}(x^{(i)})-y^{(i)})^2
J(θ)=21j=1∑n(hθ(x(i))−y(i))2我们可以选择
θ
theta
θ,试图让均方误差最小化。
极大似然估计(概率角度的诠释)
下面我们用极大似然估计,来解释为什么要用均方误差作为性能度量,我们可以把目标值和变量写成如下等式:
y
(
i
)
=
θ
T
x
(
i
)
+
ϵ
(
i
)
y^{(i)} = theta^T x^{(i)}+epsilon^{(i)}
y(i)=θTx(i)+ϵ(i)
ϵ
epsilon
ϵ表示我们未观测到的变量的印象,即随机噪音。我们假定
ϵ
epsilon
ϵ是独立同分布,服从高斯分布。(根据中心极限定理)
p
(
ϵ
(
i
)
)
=
1
2
π
σ
e
x
p
(
−
(
ϵ
(
i
)
)
2
2
σ
2
)
p(epsilon^{(i)}) = frac{1}{sqrt{2pi}sigma}expleft(-frac{(epsilon^{(i)})^2}{2sigma^2}right)
p(ϵ(i))=2πσ1exp(−2σ2(ϵ(i))2)因此,
p
(
y
(
i
)
∣
x
(
i
)
;
θ
)
=
1
2
π
σ
e
x
p
(
−
(
y
(
i
)
−
θ
T
x
(
i
)
)
2
2
σ
2
)
p(y^{(i)}|x^{(i)};theta) = frac{1}{sqrt{2pi}sigma}expleft(-frac{(y^{(i)}-theta^T x^{(i)})^2}{2sigma^2}right)
p(y(i)∣x(i);θ)=2πσ1exp(−2σ2(y(i)−θTx(i))2)我们建立极大似然函数,即描述数据遵从当前样本分布的概率分布函数。由于样本的数据集独立同分布,因此可以写成
L
(
θ
)
=
p
(
y
⃗
∣
X
;
θ
)
=
∏
i
=
1
n
1
2
π
σ
e
x
p
(
−
(
y
(
i
)
−
θ
T
x
(
i
)
)
2
2
σ
2
)
L(theta) = p(vec y | X;theta) = prod^n_{i=1}frac{1}{sqrt{2pi}sigma}expleft(-frac{(y^{(i)}-theta^T x^{(i)})^2}{2sigma^2}right)
L(θ)=p(y∣X;θ)=i=1∏n2πσ1exp(−2σ2(y(i)−θTx(i))2)选择
θ
theta
θ,使得似然函数最大化,这就是极大似然估计的思想。为了方便计算,我们计算时通常对对数似然函数求最大值:
I
(
θ
)
=
log
L
(
θ
)
=
log
∏
i
=
1
n
1
2
π
σ
exp
(
−
(
y
(
i
)
−
θ
T
x
(
i
)
)
2
2
σ
2
)
=
∑
i
=
1
n
log
1
2
π
σ
exp
(
−
(
y
(
i
)
−
θ
T
x
(
i
)
)
2
2
σ
2
)
=
n
log
1
2
π
σ
−
1
σ
2
⋅
1
2
∑
i
=
1
n
(
(
y
(
i
)
−
θ
T
x
(
i
)
)
2
begin{aligned} I(theta) &=log L(theta)=log prod_{i=1}^{n} frac{1}{sqrt{2 pi} sigma} exp left(-frac{left(y^{(i)}-theta^{T} x^{(i)}right)^{2}}{2 sigma^{2}}right) \ &=sum_{i=1}^{n} log frac{1}{sqrt{2 pi} sigma} exp left(-frac{left(y^{(i)}-theta^{T} x^{(i)}right)^{2}}{2 sigma^{2}}right) \ &=n log frac{1}{sqrt{2 pi} sigma}-frac{1}{sigma^{2}} cdot frac{1}{2} sum_{i=1}^{n}left(left(y^{(i)}-theta^{T} x^{(i)}right)^{2}right. end{aligned}
I(θ)=logL(θ)=logi=1∏n2πσ1exp(−2σ2(y(i)−θTx(i))2)=i=1∑nlog2πσ1exp(−2σ2(y(i)−θTx(i))2)=nlog2πσ1−σ21⋅21i=1∑n((y(i)−θTx(i))2显然,最大化
l
(
θ
)
l(theta)
l(θ)即最小化
1
2
∑
i
=
1
n
(
(
y
(
i
)
−
θ
T
x
(
i
)
)
2
frac{1}{2}sum^n_{i=1}((y^{(i)}-theta^T x^{(i)})^2
21∑i=1n((y(i)−θTx(i))2。这一结果即均方误差,因此用这个值作为代价函数来优化模型在统计学的角度是合理的。
注:
在这里要提一下似然估计的概念,关于最大(极大)似然估计是以前概率论学过的,个人理解就是对于一个公式p(y|x;θ)=k,如果是将其看作关于y的函数,那就表示在参数已知为θ的情况下,不同的样本(x,y)出现的概率,而如果将其看作关于θ的函数,则该函数就表示对于一个已知样本(x*,y*),当θ取不同值时,该样本出现的概率。而因为该样本是一个已知样本,也就是已经出现了,那么它出现的概率应该是很大的,所以我们要计算每个样本出现的最大概率,也就是求每一个最大的k,即最大化 L ( θ ) L(theta) L(θ),那么就可以求使得该函数值最大的θ,这就是最大似然估计。
2.2线性回归损失函数、代价函数、目标函数
- 损失函数(Loss Function):度量单样本预测的错误程度,损失函数值越小,模型就越好。
- 代价函数(Cost Function):度量全部样本集的平均误差。
- 目标函数(Object Function):代价函数和正则化函数,最终要优化的函数。
常用的损失函数包括:0-1损失函数、平方损失函数、绝对损失函数、对数损失函数等;常用的代价函数包括均方误差、均方根误差、平均绝对误差等。
2.3线性回归的优化方法
1)、梯度下降法
设定初始参数
θ
theta
θ,不断迭代,使得
J
(
θ
)
J(theta)
J(θ)最小化:
θ
j
:
=
θ
j
−
α
∂
J
(
θ
)
∂
θ
theta_j:=theta_j-alphafrac{partial{J(theta)}}{partialtheta}
θj:=θj−α∂θ∂J(θ)
∂
J
(
θ
)
∂
θ
=
∂
∂
θ
j
1
2
∑
i
=
1
n
(
f
θ
(
x
)
(
i
)
−
y
(
i
)
)
2
=
2
∗
1
2
∑
i
=
1
n
(
f
θ
(
x
)
(
i
)
−
y
(
i
)
)
∗
∂
∂
θ
j
(
f
θ
(
x
)
(
i
)
−
y
(
i
)
)
=
∑
i
=
1
n
(
f
θ
(
x
)
(
i
)
−
y
(
i
)
)
∗
∂
∂
θ
j
(
∑
j
=
0
d
θ
j
x
j
(
i
)
−
y
(
i
)
)
)
=
∑
i
=
1
n
(
f
θ
(
x
)
(
i
)
−
y
(
i
)
)
x
j
(
i
)
begin{aligned} frac{partial J(theta)}{partial theta} &=frac{partial}{partial theta_{j}} frac{1}{2} sum_{i=1}^{n}left(f_{theta}(x)^{(i)}-y^{(i)}right)^{2} \ &=2 * frac{1}{2} sum_{i=1}^{n}left(f_{theta}(x)^{(i)}-y^{(i)}right) * frac{partial}{partial theta_{j}}left(f_{theta}(x)^{(i)}-y^{(i)}right) \ &left.=sum_{i=1}^{n}left(f_{theta}(x)^{(i)}-y^{(i)}right) * frac{partial}{partial theta_{j}}left(sum_{j=0}^{d} theta_{j} x_{j}^{(i)}-y^{(i)}right)right) \ &=sum_{i=1}^{n}left(f_{theta}(x)^{(i)}-y^{(i)}right) x_{j}^{(i)} end{aligned}
∂θ∂J(θ)=∂θj∂21i=1∑n(fθ(x)(i)−y(i))2=2∗21i=1∑n(fθ(x)(i)−y(i))∗∂θj∂(fθ(x)(i)−y(i))=i=1∑n(fθ(x)(i)−y(i))∗∂θj∂(j=0∑dθjxj(i)−y(i)))=i=1∑n(fθ(x)(i)−y(i))xj(i)
即:
θ
j
=
θ
j
+
α
∑
i
=
1
n
(
y
(
i
)
−
f
θ
(
x
)
(
i
)
)
x
j
(
i
)
theta_{j}=theta_{j}+alpha sum_{i=1}^{n}left(y^{(i)}-f_{theta}(x)^{(i)}right) x_{j}^{(i)}
θj=θj+αi=1∑n(y(i)−fθ(x)(i))xj(i)
注:下标j表示第j个参数,上标i表示第i个数据点。
将所有的参数以向量形式表示,可得:
θ
=
θ
+
α
∑
i
=
1
n
(
y
(
i
)
−
f
θ
(
x
)
(
i
)
)
x
(
i
)
theta = theta + alphasum_{i=1}^{n}(y^{(i)}-f_theta(x)^{(i)})x^{(i)}
θ=θ+αi=1∑n(y(i)−fθ(x)(i))x(i)
由于这个方法中,参数在每一个数据点上同时进行了移动,因此称为批梯度下降法,对应的,我们可以每一次让参数只针对一个数据点进行移动,即:
θ
=
θ
+
α
(
y
(
i
)
−
f
θ
(
x
)
(
i
)
)
x
(
i
)
theta = theta + alpha(y^{(i)}-f_theta(x)^{(i)})x^{(i)}
θ=θ+α(y(i)−fθ(x)(i))x(i)
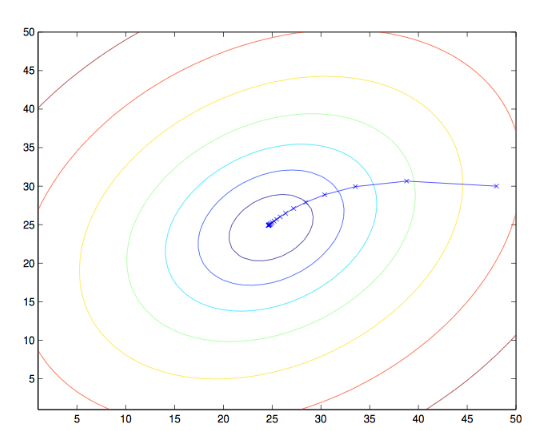
当J为凸函数时,梯度下降法相当于让参数
θ
theta
θ不断向J的最小值位置移动
梯度下降法的缺陷:如果函数为非凸函数,有可能找到的并非全局最优值,而是局部最优值。
2.4线性回归的评价指标
均方误差(MSE):
1
m
∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
frac{1}{m}sum^{m}_{i=1}(y^{(i)} - hat y^{(i)})^2
m1∑i=1m(y(i)−y^(i))2
均方根误差(RMSE):
M
S
E
=
1
m
∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
sqrt{MSE} = sqrt{frac{1}{m}sum^{m}_{i=1}(y^{(i)} - hat y^{(i)})^2}
MSE=m1∑i=1m(y(i)−y^(i))2
平均绝对误差(MAE):
1
m
∑
i
=
1
m
∣
(
y
(
i
)
−
y
^
(
i
)
∣
frac{1}{m}sum^{m}_{i=1} | (y^{(i)} - hat y^{(i)} |
m1i=1∑m∣(y(i)−y^(i)∣
但以上评价指标都无法消除量纲不一致而导致的误差值差别大的问题,最常用的指标是
R
2
R^2
R2,可以避免量纲不一致问题
R
2
:
=
1
−
∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
∑
i
=
1
m
(
y
ˉ
−
y
^
(
i
)
)
2
=
1
−
1
m
∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
1
m
∑
i
=
1
m
(
y
ˉ
−
y
^
(
i
)
)
2
=
1
−
M
S
E
V
A
R
R^2: = 1-frac{sum^{m}_{i=1}(y^{(i)} - hat y^{(i)})^2}{sum^{m}_{i=1}(bar y - hat y^{(i)})^2} =1-frac{frac{1}{m}sum^{m}_{i=1}(y^{(i)} - hat y^{(i)})^2}{frac{1}{m}sum^{m}_{i=1}(bar y - hat y^{(i)})^2} = 1-frac{MSE}{VAR}
R2:=1−∑i=1m(yˉ−y^(i))2∑i=1m(y(i)−y^(i))2=1−m1∑i=1m(yˉ−y^(i))2m1∑i=1m(y(i)−y^(i))2=1−VARMSE
我们可以把
R
2
R^2
R2理解为,回归模型可以成功解释的数据方差部分在数据固有方差中所占的比例,
R
2
R^2
R2越接近1,表示可解释力度越大,模型拟合的效果越好。
2.5sklearn.linear_model参数详解
fit_intercept : 默认为True,是否计算该模型的截距。如果使用中心化的数据,可以考虑设置为False,不考虑截距。注意这里是考虑,一般还是要考虑截距
normalize: 默认为false. 当fit_intercept设置为false的时候,这个参数会被自动忽略。如果为True,回归器会标准化输入参数:减去平均值,并且除以相应的二范数。当然啦,在这里还是建议将标准化的工作放在训练模型之前。通过设置sklearn.preprocessing.StandardScaler来实现,而在此处设置为false
copy_X : 默认为True, 否则X会被改写
n_jobs: int 默认为1. 当-1时默认使用全部CPUs ??(这个参数有待尝试)
可用属性:
coef_:训练后的输入端模型系数,如果label有两个,即y值有两列。那么是一个2D的array
intercept_: 截距
可用的methods:
fit(X,y,sample_weight=None):
X: array, 稀疏矩阵 [n_samples,n_features]
y: array [n_samples, n_targets]
sample_weight: 权重 array [n_samples]
在版本0.17后添加了sample_weight
get_params(deep=True): 返回对regressor 的设置值
predict(X): 预测 基于 R^2值
score: 评估
参考https://blog.csdn.net/weixin_39175124/article/details/79465558
2.6程序
#生成数据
import numpy as np
#生成随机数
np.random.seed(1234)
x = np.random.rand(500,3)
#构建映射关系,模拟真实的数据待预测值,映射关系为y = 4.2 + 5.7*x1 + 10.8*x2,可自行设置值进行尝试
y = x.dot(np.array([4.2,5.7,10.8]))
1)、先尝试调用sklearn的线性回归模型训练数据
import numpy as np
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
%matplotlib inline
# 调用模型
lr = LinearRegression(fit_intercept=True)
# 训练模型
lr.fit(x,y)
print("估计的参数值为:%s" %(lr.coef_))
# 计算R平方
print('R2:%s' %(lr.score(x,y)))
# 任意设定变量,预测目标值
x_test = np.array([2,4,5]).reshape(1,-1)
y_hat = lr.predict(x_test)
print("预测值为: %s" %(y_hat))
#估计的参数值为:[ 4.2 5.7 10.8]
#R2:1.0
#预测值为: [85.2]
2)、最小二乘法的矩阵求解
class LR_LS():
def __init__(self):
self.w = None
def fit(self, X, y):
# 最小二乘法矩阵求解
#============================= show me your code =======================
self.w = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)
#============================= show me your code =======================
def predict(self, X):
# 用已经拟合的参数值预测新自变量
#============================= show me your code =======================
y_pred = X.dot(self.w)
#============================= show me your code =======================
return y_pred
if __name__ == "__main__":
lr_ls = LR_LS()
lr_ls.fit(x,y)
print("估计的参数值:%s" %(lr_ls.w))
x_test = np.array([2,4,5]).reshape(1,-1)
print("预测值为: %s" %(lr_ls.predict(x_test)))
#估计的参数值:[ 4.2 5.7 10.8]
#预测值为: [85.2]
3、梯度下降法
class LR_GD():
def __init__(self):
self.w = None
def fit(self,X,y,alpha=0.02,loss = 1e-10): # 设定步长为0.002,判断是否收敛的条件为1e-10
y = y.reshape(-1,1) #重塑y值的维度以便矩阵运算
[m,d] = np.shape(X) #自变量的维度
self.w = np.zeros((d)) #将参数的初始值定为0
tol = 1e5
#============================= show me your code =======================
while tol > loss:
h_f = X.dot(self.w).reshape(-1,1)
theta = self.w + alpha*np.mean(X*(y - h_f),axis=0) #计算迭代的参数值
tol = np.sum(np.abs(theta - self.w))
self.w = theta
#============================= show me your code =======================
def predict(self, X):
# 用已经拟合的参数值预测新自变量
y_pred = X.dot(self.w)
return y_pred
if __name__ == "__main__":
lr_gd = LR_GD()
lr_gd.fit(x,y)
print("估计的参数值为:%s" %(lr_gd.w))
x_test = np.array([2,4,5]).reshape(1,-1)
print("预测值为:%s" %(lr_gd.predict(x_test)))
#估计的参数值为:[ 4.20000001 5.70000003 10.79999997]
#预测值为:[85.19999995]
三.参考
datawhale
吴恩达 CS229课程
周志华 《机器学习》
李航 《统计学习方法》
https://hangzhou.anjuke.com/
https://www.jianshu.com/p/e0eb4f4ccf3e
https://blog.csdn.net/qq_28448117/article/details/79199835
https://blog.csdn.net/weixin_39175124/article/details/79465558
最后
以上就是聪明小笼包最近收集整理的关于Datawhale-机器学习算法-Task1 Linear_regression一.学习目标二.学习内容三.参考的全部内容,更多相关Datawhale-机器学习算法-Task1内容请搜索靠谱客的其他文章。






![[kuangbin]数学训练四 数论 [Cloned]](https://www.shuijiaxian.com/files_image/reation/bcimg18.png)

发表评论 取消回复