文章目录
- 第一章
- 1.名词解释
- 2.简答题
- 第二章
- 第三章
- 第四章
- 第五章
- 第七章
- 第八章
第一章
1.名词解释
兼容性:兼容性是指硬件之间、软件之间或是软硬件组合系统之间的相互协调工作的程度。
指令集体系结构:指令集体系结构是机器语言程序所运行的计算机硬件和软件之间的一个“桥梁”,是软件和硬件之间接口的一个完整定义。
透明性:在计算机技术中,一个存在的事物或概念从某个角度看似乎不存在,也即,对实际存在的事务或概念感觉不到,则称为透明。
CPU执行时间:CPU 执行时间指 CPU 用于程序执行的时间,它又包括以下两部分: (1)用户 CPU 时间,指真正用于运行用户程序代码的时间; (2)系统 CPU 时间,指为了执行用户程序而需要 CPU 运行操作系统程序的时间。
CPI:CPI 表示执行一条指令所需的时钟周期数。
峰值MIPS:选取一组指令组合,使得得到的平均 CPI 最小,由此得到的 MIPS 就是峰值 MIPS(Peak MIPS)。
MFLOPS:它表示每秒所执行的浮点运算有多少百万次,它是基于所完成的操作次数而不是指令数来衡量的。
2.简答题
1.摩尔定律的主要内容是什么?
解:由于硅技术的不断改进,每 18 个月,集成度将翻一番,速度将提高一倍,而其价格将降低一半。
2.为什么说性能指标MIPS不能很好地反映计算机的性能?
解:MIPS 反映了机器执行定点指令的速度,但是,用 MIPS 来对不同的机器进行性能比较有时是不准确或不客观的。因为不同机器的指令集不同,而且指令的功能也不同,也许在机器 M1 上某一条指令的功 能,在机器 M2 上要用多条指令来完成,因此,同样的指令条数所完成的功能可能完全不同;另外,不 同机器的 CPI 和时钟周期也不同,因而同一条指令在不同机器上所用的时间也不同。
第二章
4.假定机器数为 8 位(1 位符号,7 位数值),写出下列各二进制数的原码表示。
+0.1001:0.1001000
–0.1001:1.1001000
+1.0:溢出
–1.0:溢出
+0.010100:0.0101000
–0.010100:1.0101000
+0:0.0000000
–0:1.0000000
6. 已知 [x]补,求 x
(1)[x]补=1.1100111 x=-0.0011001
(2)[x]补=10000000 x=-10000000
(3)[x]补=0.1010010 x=+0.1010010
(4)[x]补=11010011 x=-00101101
7.假定一台 32 位字长的机器中带符号整数用补码表示,浮点数用 IEEE 754 标准表示,寄存器 R1 和 R2 的内容分别为 R1:00 00 10 8BH,R2:80 80 10 8BH。不同指令对寄存器进行不同的操作,因 而,不同指令执行时寄存器内容对应的真值不同。假定执行下列运算指令时,操作数为寄存器 R1 和 R2 的内容,则 R1 和 R2 中操作数的真值分别为多少?
(1) 无符号数加法指令 R1:+108BH R2:+8080108BH
(2) 带符号整数乘法指令 R1:+108BH R2:-7F7FEF75H
(3) 单精度浮点数减法指令 R1:00000000000000000001000010001011=+0.0000000001000010001011B2-126
R2:10000000100000000001000010001011=-0.0000000001000010001011B2-126
9.以下是一个 C 语言程序,用来计算一个数组 a 中每个元素的和。当参数 len 为 0 时,返回值应该是 0,但是在机器上执行时,却发生了存储器访问异常。请问这是什么原因造成的,并说明程序应该 如何修改。
1 float sum_elements(float a[], unsigned len)
2 {
3 int i;
4 float result = 0;
5
6 for (i = 0; i <= len–1; i++)
7 result += a[i];
8
9 return result;
10 }
解:参数len的类型是unsigned,当len=0时,len-1的结果为11…1,因此循环体被不断执行,引起数组越界。
应将len修改为int型或者for循环条件改为i<len
11. 下列几种情况所能表示的数的范围是什么?
(1) 16 位无符号整数 0~216-1
(2) 16 位原码定点小数 -(1-2-15)~+(1-2-15)
(3) 16 位补码定点小数 -1~+(1-2-15)
(4) 16 位补码定点整数 -32768~+32767
(5) 下述格式的浮点数(基数为 2,移码的偏置常数为 128)

+0.0000012-128~+0.1111112127
-0.1111112127~-0.0000012-128
14.设一个变量的值为–2147483647,要求分别用 32 位补码整数和 IEEE754 单精度浮点格式表示该变 量(结果用十六进制表示),并说明哪种表示其值完全精确,哪种表示的是近似值。
解:-2147483647=-1111111111111111111111111111111110000000000000000000000000000001
32位补码形式:80000001H
IEEE745单精度格式:11001110111111111111111111111111B=CEFFFFFFH
32位补码表示的是精确值,IEEE745单精度格式表示的是近似值,低位被截断。
第三章
3.考虑以下C语言程序代码
int func1(unsigned word)
{
return (int)((word<<24)>>24);
}
int func2(unsigned word)
{
return ((int)word<<24)>>24;
}
假设在一个32位机器上执行这些函数,该机器使用二进制补码表示带符号整数。无符号数采用逻辑移位,带符号整数采用算术移位。请填写表3.3并说明函数func1和func2的功能。
解:
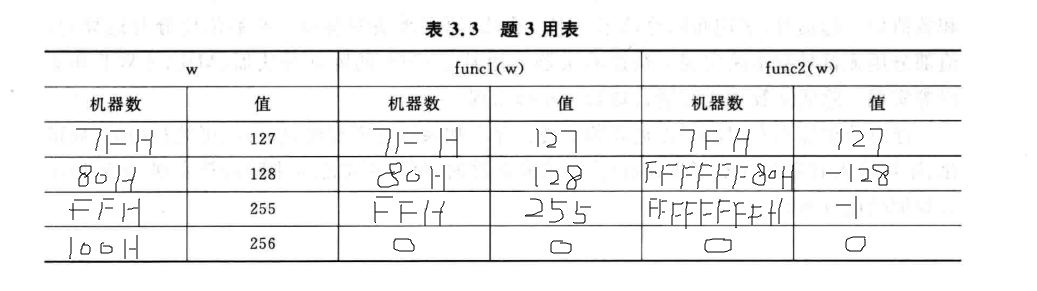
功能:func1函数是将一个无符号数先左移24位,再右移24位,然后将它转换为带符号整数。func2函数是将一个无符号数先左移24位,再将它转换为带符号整数,然后再右移24位。
5.以下是两段C语言代码,函数arith()是直接用C语言写的,而optarith()是对arith()函数以某个确定的M和N编译生成的机器代码反编译生成的。根据optarith()推断函数arith()中M和N的值各是多少。
#define M
#define N
int arith(int x,int y)
{
int result=0;
result=x*M+y/N;
return result;
}
int optarith(int x,int y)
{
int t=x;
x<<=4;
x-=t;
if(y<0) y+=3;
y>>=2;
return x+y;
}
解:
下面那段代码中,x左移4位*16,再减去x,所以M=15;
如果y小于0,则加上移去的两位,11b=3d;如果y大于等于0,则不需+3.
y再右移2位,/4,所以N=4;
M=15,N=4.
7.已知x=10,y=-6,采用6位机器数表示。请按如下要求计算,并把结果还原成真值。
(4)用不恢复余数法计算[x/y]补的商和余数。
解:
X=[x]补=001010,Y=[y]补=111010
对被除数进行符号扩展,即X=000000 001010,-Y=[-y]补=000110
| 余数寄存器R | 余数/商寄存器Q | 说明 |
|---|---|---|
| 000000 | 001010 | 开始R0=X |
| +111010 | R1=X+Y | |
| 111010 | 001010 | R1与Y同号,Q5=1 |
| 110100 | 010101 | 2R1 |
| +000110 | R2=2R1-Y | |
| 111010 | 010101 | R2与Y同号,Q4=1 |
| 110100 | 101011 | 2R2 |
| +000110 | R3=2R2-Y | |
| 111010 | 101011 | R3与Y同号,Q3=1 |
| 110101 | 010111 | 2R3 |
| +000110 | R4=2R3-Y | |
| 111011 | 010111 | R4与Y同号,Q2=1 |
| 110110 | 101111 | 2R4 |
| +000110 | R5=2R4-Y | |
| 111100 | 101111 | R5与Y同号,Q1=1 |
| 111001 | 011111 | 2R5 |
| +000110 | R6=2R5-Y | |
| 111111 | 011111 | R6与Y同号,Q0=1 |
| 111110 | 111111 | 2R6 |
| +000110 | R7=2R6-Y | |
| 000100 | 111110 | Q左移空出一位上商,R7与Y异号,Q0=0 |
| +1 | 余数不需修正,商+1修正 | |
| 000100 | 111111 |
商:-1,余数:4
11.假设浮点数格式为:阶码是4位移码,偏置常数为8,尾数是6位补码(采用双符号位)。用浮点运算规则分别计算在不采用任何附加位和采用两位附加位(保护位、舍入位)两种情况下的值。(假定对阶和右规时采用就近舍入到偶数方式。)
(1)(15/16)✖27+(2/16)✖25
解:
采用隐藏位
[x]浮= 00 1110 (1)111000
[y]浮=00 1010 (1)000000
Ex = 1110,Mx= 00 (1). 111000 ,Ey = 1010,My= 00(1).000000
[ΔE]补 = [Ex]移 + [–[Ey]移]补 (mod 2n) = 1110 + 0110 = 0100
对y进行对阶,Ey = Ex= 1110,My= 000.000100
没有附加位:
尾数相加:Mb= Mx + My = 001. 111000+ 000.000100 = 001.111100
两位符号相等,数值部分最高位为1,不需要进行规格化,所以最后结果为:E=1110,M=00(1).110100
有附加位:
尾数相加:Mb= Mx + My = 001. 11100000+ 000.00010000 = 001.11110000
两位符号相等,数值部分最高位为1,不需要进行规格化,附加位为0,无需舍入,所以最后结果为:E=1110,M=00(1).110100
12.采用IEEE单精度浮点数格式计算下列表达式的值。
(1)0.75+(-65.25)
解:
[x]浮=0 01111110 (1)100…00
[y]浮=1 10000101 (1)00000101…00
Ex = 01111110,Mx= 0 (1).1000…00 ,Ey = 10000101,My= 1(1).00000101…00
[ΔE]补 = [Ex]移 + [–[Ey]移]补 (mod 2n) = 01111110 + 01111011 = 11111001
对x进行对阶,Ex = Ey= 10000101,Mx= 0(0).000000110…00
位数相加:Mb=Mx+My=0(0).000000110…00+1(1).00000101…00=1(1).000010…00
不需进行规格化,所以最终结果为:E=10000101,M=1(1).000010…00
第四章
3.假定某计算机中有一条转移指令,采用相对寻址方式,共占两个字节,第一字节是操作码,第二字节是相对位移量(用补码表示)CPU每次从内存只能取一个字节。假设执行到某转移指令时PC的内容为200,执行该转移指令后要求转移到100开始的一段程序执行,则该转移指令第二字节的内容应该是多少?
解:
该转移指令占两个字节,执行完后,PC的内容为202,因此位移量应该是-102,则第二字节的内容应该是10011010.
4.假设地址为1200H的内存单元中的内容为12FCH,地址为12FCH的内存单元的内容为38B8H,而38B8H单元的内容为88F9H。说明以下个情况下操作数的有效地址是多少?
(1)操作数采用变址寻址,变址寄存器的内容为12,指令中给出的形式地址为1200H。
(2)操作数采用一次间接寻址,指令中给出的地址码为1200H。
(3)操作数采用寄存器间接寻址,指令中给出的寄存器编号为8,8号寄存器中的内容为1200H。
解:
(1)有效地址=000CH+1200H=120CH,操作数未知。
(2)有效地址=[1200H]=12FCH,操作数为38B8H。
(3)有效地址=1200H,操作数为12FCH。
6.某计算机指令系统采用定长指令字格式,指令字长16位,每个操作数的地址码长6位。指令分二地址、一地址和零地址三类。若二地址指令有K2条,零地址指令有K0条,则一地址指令最多有多少条?
解:
设一地址指令最多有K1条。
则((24-K2)✖26-K1)✖26=K0
解得K1=64✖(16-K2)-K0/64
9.以下程序段是某个过程对应的指令序列。入口参数int a和 int b分别置于$a0和$a1中,返回参数是该过程的结果。置于$ v0中。要求为以下MIPS指令序列加注释,并简单说明该过程的功能。
add $t0,$zero,$zero ;将t0初始化为0
loop: beq $a1,$zero,finish;如果a1的值为0则程序转移到finish
add $t0,$t0,$a0 ;将t0和a0相加存于t0
sub $a1,$a1,1 ;a1减1
j loop ;跳转到loop
finish: addi $t0,$t0,100 ;将t0加上100
add $v0,$t0,$zero ;将t0中的值存入v0
解:
loop循环中不断做+a0的操作,做b次,因此loop做的是a*b。
该程序的功能为:计算a×b+100
11.用一条MIPS指令或最短的MIPS指令序列实现以下C语言语句:b=25|a。假定编译器将a和b分别分配到$ t0 和 $t1中。如果把25换成65536,即b=65536|a,则用MIPS指令或指令序列如何实现?
解:
ori $t0,$t1,25
若把25换成65536则不能用一条指令实现,因为65536换成二进制是10000H,立即数存不进去,计算出错。lui:把一个16位的立即数填入到寄存器的高16位,低16位补零。可改为
lui $t1,1
or $t1,$t0,$t1
15.以下是一个计算阶乘的C语言递归过程,请按照MIPS过程调用协议写出该递归过程对应的MIPS汇编语言程序,要求目标代码尽量短(提示:乘法运算可用乘法指令“mul rd,rs,rt”来实现,功能为rd <-(rs)×(rt))。
int fact(int n)
{
if(n<1)
return (1);
else
return (n*fact(n-1));
}
解:
将入口参数n存放在$ a0中,将结果存放于$ v0中。
sub $v0,$a0,$zero
loop: subi $a0,$a0,1
mul $v0,$v0,$a0
beq $a0,1,exit
j loop
exit:
第五章
4.图5.40给出了某CPU内部结构的一部分,MAR和MDR直接连到存储器总线(图中省略)。在两个总线之间的所有数据传送都需经过算术逻辑部件ALU。ALU的部分控制信号及其功能如下:
mova: F=A; movb: F=B;
a+1: F=A+1; b+1: F=B+1;
a-1: F=A-1; b-1: F=B-1;
其中A和B是ALU的输入,F是ALU的输出。假定该CPU的指令系统中调用指令CALL占两个字,第一个字是操作码,第二个字给出子程序的起始地址,返回地址保存在主存的栈中,用SP(栈指示器)指向栈顶,存储器按字编址,每次按同步方式从主存读取一个字,请写出读取并执行CALL指令所要求的控制信号序列(提示:当前指令地址已在PC中)。
解:
取指令:
PCout, movb, MARin, Read, b+1, PCin
取地址:
PCout, movb, MARin, Read, b+1, Yin, MDRout, movb, PCin
保存返回地址:
SPout, movb, MARin, Yout, movb, MDRin, Write, SPout, b-1, SPin
6.假定图5.22单周期数据通路对应的控制逻辑发生错误,使得控制信号RegWr,RegDst,Branch,MemWr,ExtOp,R-type中某一个在任何情况下总是为0,则该控制信号为0时哪些指令不能正确执行?要求分别讨论。
解:
若RegWr为0,则所有R型指令如add,sub,subu,slt,sltu,ori,addiu,lw等指令都不能正确执行。
若RegDst为0,则add,sub,subu,slt,sltu指令不能正确执行。
若Branch为0,则beq指令不能正确执行。
若MemWr为0,则sw指令不能正确执行。
若ExtOp为0,则addiu,lw,sw指令不能正确执行。
若R-type为0,则所有非func字段控制的的指令如ori,addiu,lw,sw,beq,jump等指令都不能正确执行。
7.假定图5.22单周期数据通路对应的控制逻辑发生错误,使得控制信号RegWr,RegDst,Branch,MemWr,ExtOp,R-type中某一个在任何情况下总是为1,则该控制信号为1时哪些指令不能正确执行?要求分别讨论。
解:
若RegWr为1,则sw,beq,jump等指令不能正确执行。
若RegDst为1,则ori,addiu,lw等指令不能正确执行。
若Branch为1,则除beq外的所有指令都不能正确执行。
若MemWr为1,则除sw外的所有指令都不能正确运行。
若ExtOp为1,则ori指令不能正确执行。
若R-type为1,则所有需要func字段的R型指令都不能正确执行。
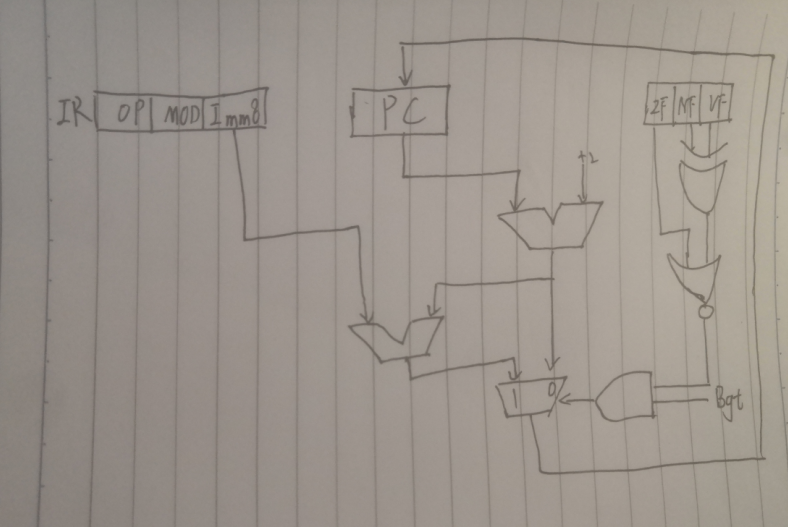
12.某计算机字长16位,标志寄存器Flag中的ZF、SF和OF分别是零标志、符号标志和溢出标志,采用双字节定长指令字。假定该计算机中有一条Bgt(大于零转移)指令,其指令格式为:第一个字节指明操作码和寻址方式,第二个字节为偏移地址imm8,其功能如下:
若(ZF+(SF⊕OF)=0),则PC=PC+2+imm8,否则PC=PC+2.
完成如下要求并回答问题:
(1)该计算机存储器的编址单位是什么?
(2)画出实现Bgt指令的数据通路。
解:
(1)该计算机的编制单位是字节。因为PC=PC+2,每条指令占两个字节。
(2)
第七章
4.假定用64K×1位的DRAM芯片256K×8位的存储器,要求回答下列问题。
(1)所需芯片数为多少?画出该存储器的逻辑框图。
(2)若采用异步刷新方式,每单元刷新间隔不超过2ms,则产生刷新信号的间隔是多少时间?若采用集中刷新方式,则存储器刷新一遍最少用多少个读写周期?
解:
(1)8块芯片进行位扩展,形成64K×8位的芯片组,然后在用4组这样的芯片组进行字扩展,形成256K×8位的存储器,因此需要32块芯片。
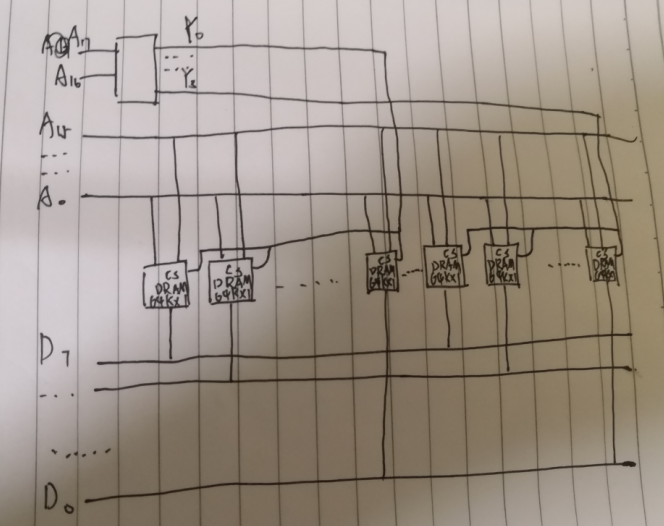
(2)因为每个单元的刷新间隔为2ms,所以在2ms内每行必须被刷新一次。64K=256×256,因此存储阵列为256行。因此,存储器控制器必须每隔2ms/256=7.8µs产生一次刷新信号。采用集中刷新方式时,整个存储器刷新一遍需要256个读写周期。
6.某计算机中已配有0000H~7FFFH的ROM区域,现在再用8K×4位的RAM芯片形成32K×8位的存储区域,CPU地址线为A0~A15,数据线为D0~D7,控制信号为R/W(读/写)、MREQ(访存)。要求说明地址译码方案。假定上述其他条件不变,只是CPU地址线改为24根,地址范围000000F~007FFFH为ROM区,剩下的所有地址空间都用8K×4位的RAM芯片配置,则需要多少个这样的RAM芯片?
解:
CPU地址线共16位,故存储器地址空间为0000H~FFFFH,其中,8000H~FFFFH为RAM区,共215=32K个单元。要形成32K×8位的存储区域,需要8K×4位的芯片数为4×2=8片。 因为ROM区在0000H~7FFFH,RAM区在8000H~FFFFH,所以可通过最高位地址A15来区分,当A15为0时选中ROM芯片;为1时选中RAM芯片,根据A14和A13进行译码,得到4个译码信号,分别用于4组字扩展芯片的片选信号。
若CPU地址线为24位,ROM区为000000H~007FFFH,则ROM区大小为32KB,总大小为16MB=214KB=512×32KB,所以RAM区大小为511×32KB,共需使用RAM芯片数为511×4×2=4088个芯片。
7.假定一个存储器系统支持四体交叉存取,某程序执行过程中访问地址序列为3,9,17,2,51,37,13,4,8,41,67,10,则哪些地址访问会发生体冲突?
解:
每个存储模块的地址分布:
B0: 0、4、8、12、16 … …
B1: 1、5、9、13、17 …37 …41…
B2: 2、6、10、14、18 …
B3: 3、7、11、15、19…51…67…
如果给定的访存地址在相邻的4次访问中出现在同一个模块内,就会发生冲突。所以,17和9、37和17、13和37、8和4会发生冲突。
10.假定某计算机主存地址空间大小为1GB,按字节编址cache的数据区(即不包括标记、有效位等存储区)有64KB,块大小为128字节,采用直接映射和直写方式,请问:
(1)主存地址如何划分?要求说明每个字段的含义,位数和在主存地址中的位置。
(2)cache的总容量为多少位?
解:
(1)主存空间大小为1GB=230B,按字节编址,那么主存地址为30位。64KB/128B=512行=29,因此cache内有512行,占用9位地址,而128=27,所以块内地址为7位;剩下的14位就是标记位。因此,30位主存地址中,高14位为标志;中间9位为行索引;低7位为块内地址。
(2)数据存储空间大小加上标志位和有效位的大小就是cache的总容量。所以,cache总容量为512×(128×8+14+1)=519.5K位。
11.假定某计算机的cache共16行,开始为空,块大小为1个字,采用直接映射方式,按字编址。CPU执行某程序时,依次访问以下地址序列:2,3,11,16,21,13,64,48,19,11,3,22,4,27,6和11,要求:
(1)说明每次访问是命中还是缺失,试计算访问上述地址序列的命中率。
(2)若cache数据区容量不变,而块大小改为4个字,则上述地址序列的命中情况又如何?
解:
(1)cache的数据区容量为16行×1字=16字。 开始cache为空,所以第一次都是miss。
2->2:miss
3->3:miss
11->11:miss
16->0:miss
21->5:miss
13->13:miss
64->0: miss,替换原来的16
48->0:miss,替换原来的64
19->3:miss,替换原来的3
11->11:命中
3->3:miss,替换原来的19
22->6:miss
4->4: miss
27->11:miss,替换原来的11
6->6:miss,替换原来的22
11->11: miss,替换原来的27
在16次访问中只有1次命中,因此命中率为1/16。
(2)cache采用直接映射方式,数据区容量不变,为16个字节,每块大小改为4个字,所以,cache共有4行。前面是地址,括号内为主存块号,右边是cache行号。
2(0)->0:miss
3(0)->0:命中
11(2)->2:miss
16(4)->0:miss,替换原来的0
21(5)->1:miss
13(3)->3:miss
64(16)->0:miss,替换原来的4
48(12)->0:miss,替换原来的16
19(4)->0:miss,替换原来的12
11(2)->2:命中
3(0)->0:miss,替换原来的4
22(5)->1:命中
4(1)->1:miss,替换原来的5
27(6)->2:miss,替换原来的2
6(1)->1:命中
11(2)->2:miss,替换原来的6
修改后命中4次,明显提高了命中率。
假定计算机系统主存空间大小为32Kx16位,且有一个4K字的4路组相联Cache,主存和Cache之间的数据交换块的大小为64字。假定Cache开始为空,处理器顺序地从存储单元0、1、…、4351中取数,一共重复10次。设Cache比主存快10倍。采用LRU算法。试分析Cache的结构和主存地址的划分。说明采用Cache后速度提高了多少?采用MRU算法后呢?
解:
假定主存按字编址,每字16位。
数据交换块的大小为64字,主存空间的大小为32K字,那么主存空间可以划分为32K字/64字=512块。而cache的容量为4K字,一行对应一块也就是64字,4行一组,可以分为4K/4/64=16组。
那么块内地址占6位,组号占4位,512/16=25.标志位占5位。
一块有64字,那么4352/64=68块,也就是对0、1、…67块重复访问10次。
若采用LRU算法:
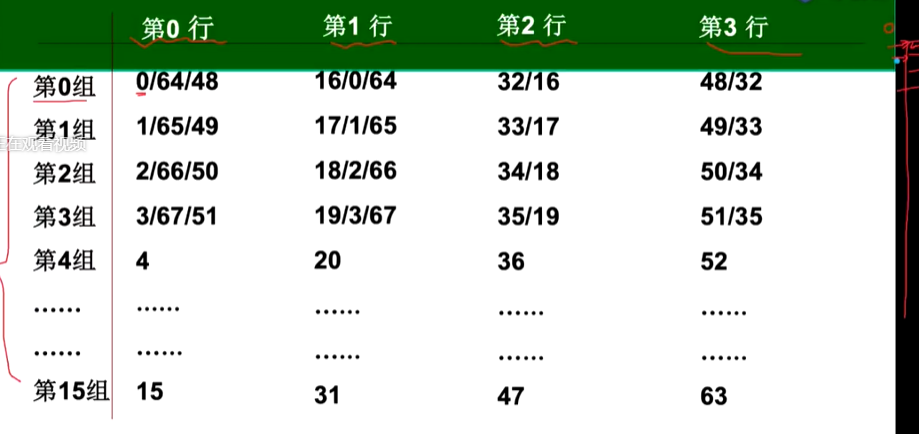
从示意图可以看出,第一次访问的时候,每一块只有第一字未命中,其余字都命中。在访问第63块后,cache数据区被填满,访问第64~67块时替换掉原来第0~3块的位置。进入第二遍循环时,第0~3组替换原来第16~19组的位置,只有每组第一字未命中。第16~19组替换掉原来第32~35组的位置,以此类推,每次循环有20组第一字未命中。
因此,命中率为(43520-68-9×20)/43520=99.43%
假设原先访存时间为t,那么命中部分耗时0.9943t*0.1,未命中部分耗时0.0057t,共耗时0.10513t,速度提高9.512倍。
若采用MRU算法:
第一轮访问中,同样每块只有第一字未命中,区别在于MRU算法中第64~67块替换了原来第63~60块的位置。那么在第二轮访问中,第0~59块全部命中,第60~63块替换原来第59~56块的位置。在后续的9次循环中,每次只有4块的第一字未命中。
因此,命中率为(43520-68-9×4)/43520=99.76%
同样的方法可以计算出速度提高了9.789倍,因此在这题的情境中,MRU算法优于LRU算法。
第八章
4.假定一个程序重复完成将磁盘上一个4KB的数据块读出,进行相应处理后,写回到磁盘的另外一个数据区。各数据块内信息在磁盘上连续存放,并随即地位于磁盘的一个磁道上。磁盘转速为7200rpm,平均寻道时间为10ms,磁盘最大数据传输率为40MBps,磁盘控制器的开销为2ms,没有其他程序使用磁盘和处理器,并且磁盘读写操作和磁盘数据的处理时间不重叠。若程序对磁盘数据的处理需要20000个时钟周期,处理器时钟频率为 500MHz,则该程序完成一次数据块“读出-处理-写回”操作所需的时间为多少?每秒钟可以完成多少次这样的数据块操作?
解:
磁盘转一圈的时间为103/(7200/60)=8.33ms,故平均等待时间为8.33/2=4.17ms。
数据传输时间为103 x 4KB/40MBps=0.1024ms
平均存取时间:控制器开销 + 寻道时间 + 旋转等待时间 + 数据传输时间 =2ms+10ms+4.17ms+0.1024ms=16.27ms
数据块的处理时间为20000/500MHz=0.038ms
因此完成一次数据块的“读出-处理-写回”操作时间为16.27ms x 2+0.038ms=32.578ms
每秒钟可以完成这样的数据块操作1000ms/32.578ms=30次
8.某终端通过RS-232串行通信接口与主机相连,采用起止式异步通信方式,若传输速率为1200baud,采用两相调制技术。通信协议为8位数据,无校验位,停止位为1位。则传送一个字节所需时间约为多少?若传输速度为2400baud,停止位为2位,其他不变,则传输一个字节的时间为多少?
解:
采用两相调制技术,波特率=比特率
若传输速率为1200baud,一个字符共占:1+8+1=10位,所以时间约为:10x(1/1200)s=8.3ms
若传输速率为2400baud,一个字符共占:1+8+2=11位,所以时间约为:11x(1/2400)s=4.6ms
10.假设有一个磁盘,每面有200个磁道,盘面总存储容量为1.6MB,磁盘旋转一周时间为25ms,每道有4个区,每两个区之间有一个间隙,磁头通过每个间隙需1.25ms。问:从该磁盘上读取数据时的最大数据传输率是多少(单位为字节/秒)?假如有人为该磁盘设计了一个与计算机之间的接口,如下图所示,磁盘每读出一位,串行送入一个移位寄存器,每当移满16位后向处理器发出一个请求交换数据的信号。在处理器响应该请求信号并读取移位寄存器的内容的同时,磁盘继续读出一位数据并串行送入移位寄存器,如此继续工作。已知处理器在接到请求交换的信号以后,最长响应时间是3微秒,这样设计的接口能否正确工作?若不能,则应如何改进?
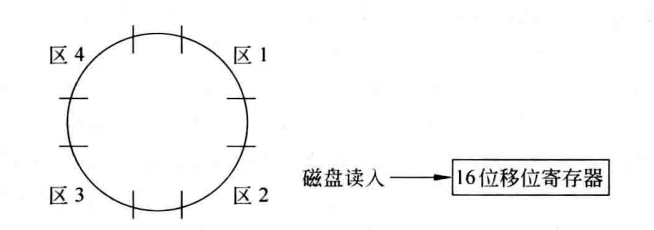
解:
每个磁道的存储容量:1.6x106B/200=8000B
区容量:8000B/4=2000B
区时间:(25-1.25x4)÷4 ms=5ms
最大数据传输率:2000B/5ms= 4x105Bps
因此,传送1位的时间为:1/(8x4x105) =0.31微秒
由于传送1位的时间远小于处理器相应时间,这样的设置不合理,不能正确工作。
传送一个字需2/(4x105) =5微秒>3微秒,所以可以增加一个16位数据缓冲器。当16位移位寄存器装满后,送入数据缓冲寄存器,在读出下一个16位数据期间(5微秒),上次读出的16位数据从数缓器中被取走(3微秒)。
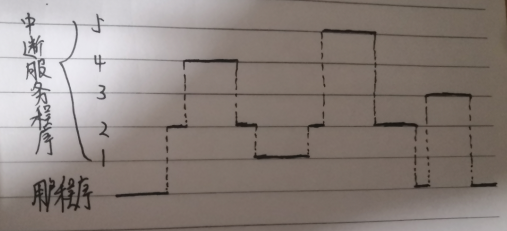
13.若某计算机有5个中断源,分别记为1,2,3,4,5。中断响应优先级为1>2>3>4>5,而中断处理优先级为1>4>5>2>3。要求:
(1)设置各种中断处理程序的中断屏蔽位(假设1为屏蔽,0为开放)。
(2)若在运行主程序时,同时出现第2、4号中断请求,而在处理第2号中断的过程中,又同时出现1、3、5号中断请求,试画出此程序运行过程示意图。
解:
(1)
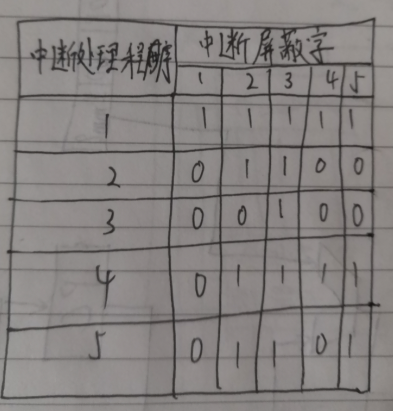
(2)根据中断程序的响应优先级顺序响应中断,在中断处理程序的准备阶段关中断,保护现场,保护旧屏蔽字,设置新屏蔽字,然后进入处理阶段之前开中断,这时要判断中断程序的处理优先级顺序,有可能优先处理别的中断。
14.假定某计算机字长16位,没有cache,运算器一次定点加法时间等于100ns,配置的磁盘旋转速度为每分钟3000转,每个磁道上记录两个数据块,每一块有8000个字节,两个数据块之间间隙的越过时间为2ms,主存周期为500ns,存储器总线宽度为16位,总线带宽为4MBps。
(1)磁盘读写数据时的最大数据传输率是多少?
(2)当磁盘按最大数据传输率与主机交换数据时,主存周期空闲百分比是多少?
(3)直接寻址的“存储器-存储器”SS型加法指令在无磁盘I/O操作打扰时的执行时间为多少?当磁盘I/O操作与一连串这种SS型加法指令执行同时进行时,则这种SS型加法指令的最快和最慢执行时间各是多少?(假定采用多周期处理器方式,CPU时钟周期等于主存周期)
解:
(1)磁盘旋转一周所需时间为60s/3000转/s=20ms,单个数据块的传输时间为(20ms/2)-2ms=8ms,所以最大数据传输速率为8000B/8ms=1MBps。
(2)每秒钟数据传输次数为1MBps/2B=512次,即每隔1s/512≈2000ns产生一个DMA请求,而主存周期为500ns,因此在4个主存周期种DMA占用一个,此时CPU没有访问主存,因此主存周期空闲百分比为75%。
(3)执行SS型加法指令时,分为取指令、取操作数1、取操作数2、执行、写结果5个步骤,每个步骤占用一个时钟周期,因此执行时间为5个时钟周期=2500ns。
若与I/O操作同时进行,由于I/O操作会在4个时钟周期内有一个时钟周期执行DMA请求访问主存,而执行SS型加法指令在5个时钟周期内会有4个时钟周期访问主存。因此,最好的情况就是CPU执行加法操作时DMA访问主存,而CPU不访问主存,速度最快,为2500ns;最坏的情况就是当CPU访问主存时与DMA冲突,而DMA优先级高于CPU,所以执行时间最慢,为2500+500=3000ns。
最后
以上就是积极狗最近收集整理的关于计算机组成原理课后习题的全部内容,更多相关计算机组成原理课后习题内容请搜索靠谱客的其他文章。








发表评论 取消回复