tensorflow 常用函数
- 引言
- 1. 基本函数
- 1.1 tf.random_normal()函数
- 1.2 tf.Variable函数
- 1.3 tf.convert_to_tensor函数
- 1.4 tf.placeholder函数
- 1.5 tf.nn.conv2d 函数
- 1.6 tf.nn.relu函数
- 1.7 tf.nn.maxpool函数
- 2. tensorflow 的维度变换
- 2.1. Reshape
- 2.2. tf.transpose
- 2.3 tf.expand_dims
- 2.4 tf.squeeze
- 3 数据类型转换
- 3.1 tensor转化为ndarray
- 3.2 ndarray转化为tensor
引言
最近因为工作需要开始学习tensorflow,既然是学习就要从基本开始,这里参照机器学习界的“hello world”实例程序,对一些常用的tensorflow函数进行了整理归纳,主要参考了官方文档及csdn一些大神的学习资料,下面开始介绍常用函数
1. 基本函数
1.1 tf.random_normal()函数
用于从“服从指定正态分布的序列”中随机取出指定个数的值。
函数原型:
tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
参数:
- shape: 输出张量的形状,必选
- mean: 正态分布的均值,默认为0
- stddev: 正态分布的标准差,默认为1.0
- dtype: 输出的类型,默认为tf.float32
- seed: 随机数种子,是一个整数,当设置之后,每次生成的随机数都一样
- name: 操作的名称
1.2 tf.Variable函数
tf.Variable(initializer,name),参数initializer是初始化参数,name是可自定义的变量名称,在TensorFlow里,变量的定义和初始化是分开的,所有关于变量的赋值和计算都要通过tf.Session的run来进行。想要将所有变量进行集体初始化时应该使用tf.global_variables_initializer。
原型:
tf.Variable(initial_value=None,
trainable=True,
collections=None,
validate_shape=True,
caching_device=None,
name=None,
variable_def=None,
dtype=None,
expected_shape=None,
import_scope=None,
constraint=None):
常用参数说明:
- initial_value:默认为None,可以搭配tensorflow随机生成函数,如上例。
- trainable:默认为True,可以后期被算法优化的。如果不想该变量被优化,改为False。
- validate_shape:默认为True,形状不接受更改,如果需要更改,validate_shape=False。
- name:默认为None,给变量确定名称。
实例:
weights = {
'conv1': tf.Variable(tf.random_normal([5, 5, 1, 32]),name='conv1_w'),
'conv2': tf.Variable(tf.random_normal([5, 5, 32, 64]),name='conv2_w'),
'fc1': tf.Variable(tf.random_normal([7 * 7 * 64, 256]),name='fc1_w'),
'out': tf.Variable(tf.random_normal([256, n_classes]),name='out_w')
}
1.3 tf.convert_to_tensor函数
将python的数据类型转换成TensorFlow可用的tensor数据类型
原型:
convert_to_tensor(value, dtype=None, name=None, preferred_dtype=None)
参数:
- value:类型具有注册张量转换函数的对象。
- dtype:返回张量的可选元素类型。如果缺少,则从值的类型推断类型。
- name:创建新张量时使用的可选名称。
- preferred_dtype:返回张量的可选元素类型,当dtype为None时使用。在某些情况下,调用者在转换为张量时可能没有考虑到dtype,因此dtype_hint可以用作软首选项。如果不能转换为dtype_hint,则此参数没有效果。
实例:
weights0 = np.array([[[0, -1, 0],
[-1, 4, -1],
[0, -1, 0]],
[[1, 0, -1],
[1, 0, -1],
[1, 0, -1]],
[[1, 1, 1],
[0, 0, 0],
[-1, -1, -1]]
])
weights1 = tf.convert_to_tensor(weights0, tf.float32, name='t')
1.4 tf.placeholder函数
placeholder是占位符的意思,在tensorflow中类似于函数参数,在执行的时候再赋具体的值。
函数原型:
tf.placeholder(dtype,shape=None,name=None)
参数:
-
dtype:数据类型。常用的是tf.float32,tf.float64等数值类型
-
shape:数据形状。默认是None,就是一维值,也可以是多维(比如[2,3], [None, 3]表示列是3,行不确定)
-
name:名称
实例1:
import tensorflow as tf
import numpy as np
x = tf.placeholder(tf.float32, shape=(1024, 1024))
y = tf.matmul(x, x)
with tf.Session() as sess:
#print(sess.run(y)) # ERROR:此处x还没有赋值
rand_array = np.random.rand(1024, 1024)
print(sess.run(y, feed_dict={x: rand_array}))
x = tf.placeholder("float", , shape=(None, 1024))
1.5 tf.nn.conv2d 函数
tensorflow中的核心函数,用于进行卷积的计算
原型:
conv2d(input, filter, strides, padding, use_cudnn_on_gpu=True, data_format="NHWC", name=None):
参数定义:
- input : 输入的要做卷积的图片,要求为一个张量,shape为 [ batch, in_height, in_weight, in_channel ],其中batch为图片的数量,in_height 为图片高度,in_weight 为图片宽度,in_channel 为图片的通道数,灰度图该值为1,彩色图为3。(也可以用其它值,但是具体含义不是很理解)
- filter: 卷积核,要求也是一个张量,shape为 [ filter_height, filter_weight, in_channel, out_channels ],其中 filter_height 为卷积核高度,filter_weight 为卷积核宽度,in_channel 是图像通道数 ,和 input 的 in_channel 要保持一致,out_channel 是卷积核数量。
- strides: 卷积时在图像每一维的步长,这是一个一维的向量,[ 1, strides, strides, 1],第一位和最后一位固定必须是1
padding: string类型,值为“SAME” 和 “VALID”,表示的是卷积的形式,是否考虑边界。"SAME"是考虑边界,不足的时候用0去填充周围,"VALID"则不考虑 - use_cudnn_on_gpu: bool类型,是否使用cudnn加速,默认为true
data_format:默认值为 “NHWC”,也可以手动设置为 “NCHW”。这个参数规定了 input Tensor 和 output Tensor 的排列方式。 - data_format 设置为 “NHWC” 时,排列顺序为 [batch, height, width, channels];
设置为 “NCHW” 时,排列顺序为 [batch, channels, height, width]
参考网址:https://www.jianshu.com/p/d8a699745529
该函数执行如下操作:
this op performs the following:
1. Flattens the filter to a 2-D matrix with shape
`[filter_height * filter_width * in_channels, output_channels]`.
2. Extracts image patches from the input tensor to form a *virtual*
tensor of shape `[batch, out_height, out_width,
filter_height * filter_width * in_channels]`.
3. For each patch, right-multiplies the filter matrix and the image patch
vector.
实例:
import tensorflow as tf
# case 1
# 输入是1张 3*3 大小的图片,图像通道数是5,卷积核是 1*1 大小,数量是1
# 步长是[1,1,1,1]最后得到一个 3*3 的feature map
# 1张图最后输出就是一个 shape为[1,3,3,1] 的张量
input = tf.Variable(tf.random_normal([1,3,3,5]))
filter = tf.Variable(tf.random_normal([1,1,5,1]))
op1 = tf.nn.conv2d(input, filter, strides=[1,1,1,1], padding='SAME')
# case 2
# 输入是1张 3*3 大小的图片,图像通道数是5,卷积核是 2*2 大小,数量是1
# 步长是[1,1,1,1]最后得到一个 3*3 的feature map
# 1张图最后输出就是一个 shape为[1,3,3,1] 的张量
input = tf.Variable(tf.random_normal([1,3,3,5]))
filter = tf.Variable(tf.random_normal([2,2,5,1]))
op2 = tf.nn.conv2d(input, filter, strides=[1,1,1,1], padding='SAME')
# case 3
# 输入是1张 3*3 大小的图片,图像通道数是5,卷积核是 3*3 大小,数量是1
# 步长是[1,1,1,1]最后得到一个 1*1 的feature map (不考虑边界)
# 1张图最后输出就是一个 shape为[1,1,1,1] 的张量
input = tf.Variable(tf.random_normal([1,3,3,5]))
filter = tf.Variable(tf.random_normal([3,3,5,1]))
op3 = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='VALID')
# case 4
# 输入是1张 5*5 大小的图片,图像通道数是5,卷积核是 3*3 大小,数量是1
# 步长是[1,1,1,1]最后得到一个 3*3 的feature map (不考虑边界)
# 1张图最后输出就是一个 shape为[1,3,3,1] 的张量
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,1]))
op4 = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='VALID')
关于same和valid的理解和要点
参考https://blog.csdn.net/syyyy712/article/details/80272071
参考http://www.manongjc.com/article/46444.html
padding主要是防止丢掉图像边缘位置的许多信息。如果不用padding,会导致1、很明显,图像中间位置的数据会参与更多的运算,而边缘位置的数据参与运算的次数比中间位置的数据少。2、每一步卷积图像都会缩小,如果网络层数很多的话,那么图像最后会很小。
所以根据自己需要可以在卷积之前进行padding。padding的意思即填充边缘,扩大边缘,也就是Same卷积。而Valid卷积则意味着不填充。
在步长stride=1的前提下,如果用Valid卷积,一个n * n的图像,用一个f * f的过滤器卷积,则可以得到一个(n-f+1)*(n-f+1)维的输出。
在步长stride=1的前提下,如果用Same卷积,则输入大小和输出大小是一样的,也就是一个n * n的图像,不管使用什么大小的过滤器卷积,输出大小都还是n * n维。
tensorflow官网定义的padding如下:
padding = “SAME”输入和输出大小关系如下:
N
o
=
N
i
S
N_o=frac{N_i}{S}
No=SNi
输出大小
N
o
N_o
No等于输入大小
N
i
N_i
Ni除以步长向上取整,S是步长大小;
padding = “VALID”输入和输出大小关系如下:
N
o
=
N
i
−
W
+
1
S
N_o=frac{N_i-W+1}{S}
No=SNi−W+1
输出大小 N o N_o No等于输入 N i N_i Ni大小减去滤波器窗口大小加上1,最后再除以步长( W W W为滤波器的大小, S S S是步长大小)。
例如:对于输入尺寸为28x28,滤波器是3x3,padding= “SAME”,步长s = 2,因此根据公式输出是(28/2=14),14向上取整还是14,如果将padding的值改成“VALID”,则最后的输出结果是(28-3+1)/2=13,13向上取整还是13,因此输出应该是13x13。
1.6 tf.nn.relu函数
这个函数的作用是计算激活函数 relu,即 max(features, 0)。将大于0的保持不变,小于0的数置为0。
原型:
relu(features, name=None):
参数:
- features: 张量. 必须是如下的类型:
float32,float64,int32,int64,uint8,int16,int8,uint16,half. - name: 操作的名字(optional).
Returns:
返回同类型的张量
实例:
_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, weights['fc1'],name='matmul') + biases['fc1_b'],name='relu')
Relu函数的解析式:
R
e
l
u
=
m
a
x
(
0
,
x
)
Relu=max(0,x)
Relu=max(0,x)
Relu函数及其导数的图像如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OlK9RBq9-1589523229539)(/media/cetc11/185CF82F5CF80970/ubuntu/mydoc/DeeplearningNote/pic/relu_function_graph.png)]
ReLU函数其实就是一个取最大值函数,注意这并不是全区间可导的,但是我们可以取sub-gradient,如上图所示。ReLU虽然简单,但却是近几年的重要成果,有以下几大优点:
1) 解决了gradient vanishing问题 (在正区间)
2)计算速度非常快,只需要判断输入是否大于0
3)收敛速度远快于sigmoid和tanh
ReLU也有几个需要特别注意的问题:
1)ReLU的输出不是zero-centered
2)Dead ReLU Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。有两个主要原因可能导致这种情况产生: (1) 非常不幸的参数初始化,这种情况比较少见 (2) learning rate太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。解决方法是可以采用Xavier初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。
尽管存在这两个问题,ReLU目前仍是最常用的activation function,在搭建人工神经网络的时候推荐优先尝试!
Relu函数及其导数的图像如下图所示:
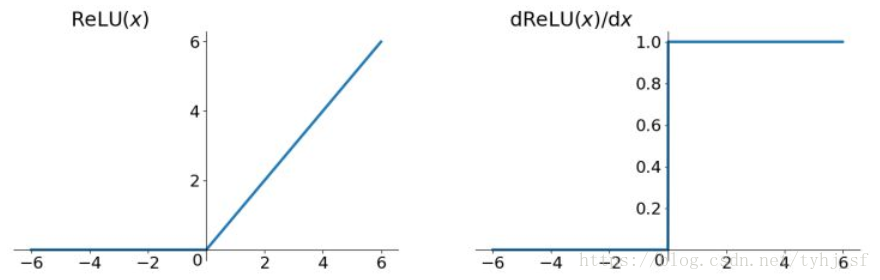
更多激活函数参考网页https://blog.csdn.net/tyhj_sf/article/details/79932893
1.7 tf.nn.maxpool函数
maxpool是CNN当中的最大值池化操作,其用法和卷积很类似
原型:
max_pool(value, ksize, strides, padding, data_format="NHWC", name=None):
参数含义:
- 第一个参数value:需要池化的输入,一般池化层接在卷积层后面,所以输入通常是feature map,依然是
[batch, height, width, channels]这样的shape - 第二个参数ksize:池化窗口的大小,取一个四维向量,一般是
[1, height, width, 1],因为我们不想在batch和channels上做池化,所以这两个维度设为了1 - 第三个参数strides:和卷积类似,窗口在每一个维度上滑动的步长,一般也是
[1, stride,stride, 1] - 第四个参数padding:和卷积类似,可以取’VALID’ 或者’SAME’
返回一个Tensor,类型不变,shape仍然是[batch, height, width, channels]这种形式
2. tensorflow 的维度变换
2.1. Reshape
函数的作用是将tensor变换为参数shape的形式,其中shape为一个列表形式,特殊的一点是列表中可以存在-1,-1代表的含义是不用我们自己指定这一维的大小,函数会自动计算,但列表只能存在一个-1。(如果存在多个-1,就是一个存在多解的方程)
a = tf.random.normal([4, 28,28, 3])
a.shape, a.ndim
Out[74]: (TensorShape([4, 28, 28, 3]), 4)
tf.reshape(a, [4, 784, 3]).shape
Out[76]: TensorShape([4, 784, 3])
tf.reshape(a, [4, -1]).shape
Out[79]: TensorShape([4, 2352])
2.2. tf.transpose
函数的作用是转置
tf.transpose
(
a,
perm=None,
name='transpose',
conjugate=False
)
并且根据perm参数重新排列输出维度
参数:
-
a - 表示的是需要变换的张量
-
perm - a的新的维度序列
-
name - 操作的名字,可选的
-
conjugate - 可选的,设置成True,那么就等于tf.conj(tf.transpose(input)),用的太少了
perm-控制转置的操作,perm = [0, 1, 3, 2]表示,把将要转置的第0和第1维度不变,将第2和第3维度进行转置
a = tf.random.normal((4,3,2,1))
a.shape
Out[96]: TensorShape([4, 3, 2, 1])
tf.transpose(a).shape
Out[98]: TensorShape([1, 2, 3, 4])
tf.transpose(a, perm = [0, 1, 3, 2]).shape
Out[100]: TensorShape([4, 3, 1, 2])
2.3 tf.expand_dims
函数的作用是在给定一个input时,在axis轴处给input增加一个维度。TensorFlow中,想要维度增加一维,可以使用该函数。当然,我们常用tf.reshape(input, shape=[])也可以达到相同效果,但是有些时候在构建图的过程中,placeholder没有被feed具体的值,这时就会报错,此时可以用此函数实现维度增加。
原型:
expand_dims(input, axis=None, name=None, dim=None):
参数:
- input是输入张量。
- axis是指定扩大输入张量形状的维度索引值。
- dim等同于轴,一般不推荐使用。
实例:
a = tf.random.normal([4, 3, 8])
tf.expand_dims(a, axis = 0).shape
Out[1]: TensorShape([1, 4, 3, 8])
tf.expand_dims(a, axis = 3).shape
Out[2]: TensorShape([4, 3, 8, 1])
tf.expand_dims(a, axis = -1).shape
Out[3]: TensorShape([4, 3, 8, 1])
tf.expand_dims(a, axis = -4).shape
Out[4]: TensorShape([1, 4, 3, 8])
2.4 tf.squeeze
函数的作用是在给定一个input时,在axis轴处给input减少一个维度,与tf.expand_dims相反
3 数据类型转换
Tensorflow 通过创建会话(session),将张量转化为Numpy中的ndarray,从而打印出张量的值。
3.1 tensor转化为ndarray
可以通过session.run方法直接转化为ndarray
# -*- coding: utf-8 -*-
import tensorflow as tf
# 创建张量
t = tf.constant([1, 2, 3, 4], tf.float32)
# 创建会话
session = tf.Session()
# 张量转化为ndarray
array = session.run(t)
# 打印其数据类型与其值
print(type(array))
print(array)
<class 'numpy.ndarray'>
也可以通过Tensor的成员函数eval
# -*- coding: utf-8 -*-
import tensorflow as tf
# 创建张量
t = tf.constant([1, 2, 3, 4], tf.float32)
# 创建会话
session = tf.Session()
# 张量转化为ndarray
array = t.eval(session=session)
# 打印其数据类型与其值
print(type(array))
print(array)
<class 'numpy.ndarray'>
[ 1. 2. 3. 4.]
原文链接:https://blog.csdn.net/a1786742005/java/article/details/84994700
3.2 ndarray转化为tensor
使用tf.convert_to_tensor函数
最后
以上就是辛勤往事最近收集整理的关于tensorflow 常用函数引言的全部内容,更多相关tensorflow内容请搜索靠谱客的其他文章。








发表评论 取消回复