前言
继上篇博客:
- 掌握Mysql数据库SQL语言的基本操作
- MySQL数据备份与数据还原
该篇更为深入的了解MySQL的相关操作。
博客中所有代码在博客最后可见。
1. 事务
事务的概念就不详细解释了。。。
简单来说就是一个安全机制。
测试数据:
use test2;
create table account(
id int not null primary key auto_increment,
u_id varchar(3) not null unique key,
name varchar(20) not null,
money int default 0);
insert into account values(default, '100', 'tom', 1000),
(default, '101', 'jack', 2000);
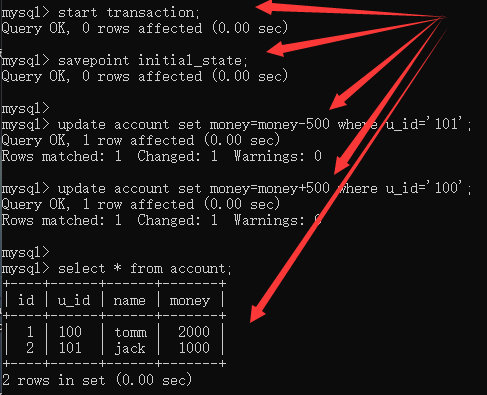
开启事务,设置保存点:
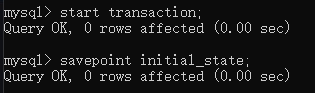
数据操作:
假如,用户101给用户100转账了500:
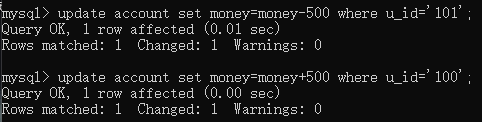
查询数据:
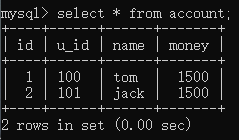
看样子是成功了。。。
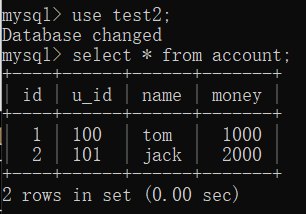
但是,再登陆第二个客户端查看:
显然,数据是初始状态,也就是说数据库中的数据是没有更新的。
而客户端能能够查看到,是因为开启了事务,操作目前保存在日志中,除非提交事务,否则是不会修改真正的数据。
那客户端二能够修改数据吗?
执行后,就卡在这个地方,会等待事务提交,过段时间就会超时。

现在提交事务:
客户端1执行:

查看客户端2:
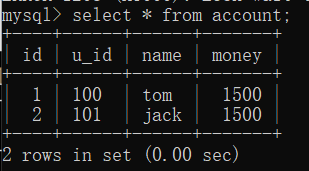
那现在客户端2能够修改数据吗?

因为,客户端2是自动提交事务,所以在客户端1是可以看到修改的:
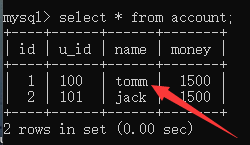
回滚:
因为上一个事务已经提交了,所以需要一个新的事物:
回滚:
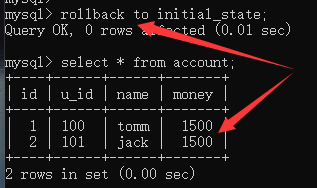
查看是否开启自动提交事务:
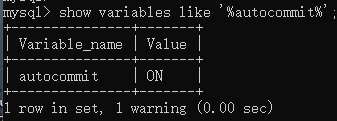
事务四大特性ACID:
A:Atomic 原子性,整个操作是一个整体,要么都成功,要么都失败。
C:Consistency 一致性, 数据表的数据符合能量守恒,比如101账户转出500,那必定有一个账户转入500(个人理解)。
I:Isolation 隔离性,事务与事务之间互不影响。
D:Durability 持久性,一旦提交事务,就是永久的修改数据。
2. 变量
系统变量:
系统变量是用来控制服务器的表现的,如autocommit、auto_increment等。
修改系统变量:
set global 变量=值;
这个修改时全局的,对所有的客户端都生效。
自定义变量
会话级别,当前会话有效。
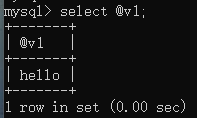
设置变量:

查看变量:
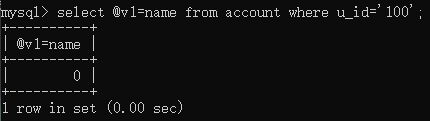
从查询结果中赋值:
你会发现返回结果是0,因为 = 在这里不是赋值,而是比较运算符。
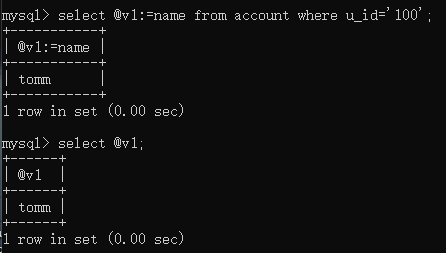
这种情况下,应该使用 := 来赋值:
另外,使用查询语句给变量赋值只能复制一行一列的数据,比如赋值一个一行两列的数据:
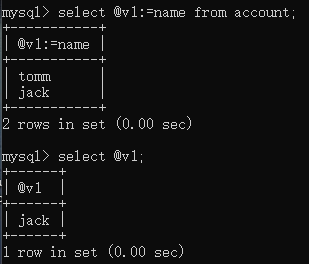
你会发现,会覆盖前面的数据。。。
3. 触发器
触发器:trigger,事先为某张表绑定好一段代码,当表中某些内容发生变化的时候(增删改)系统自动出发代码。
触发器有三个要素:
- 事件类型:增、删、改 - - insert、delete、update
- 触发时间:前、后 - - before、after
- 触发对象:表中的每一行记录 - - for each row
所以,事件类型 2 x 触发时间 3 = 6,一张表只能拥有一种类型,最多6个触发器。
触发器记录:不管触发器是否触发了,只要当某种操作准备执行,系统就会将当前要操作的记录状态和即将执行后的状态给分别保留下来,供触发器使用。其中,要操作的当前状态保持到old,操作之后的状态保存给new。
简单来说,old代表旧记录,new代表新纪录。
删除没有new,插入没有old。
使用方式: old.字段名 / new.字段名
语法:
delimiter $$
create trigger 名称 after/before insert/delete/update on for each row
begin
代码
end
delimiter ;
测试数据(直接复制粘贴即可):
use test2;
drop table if exists items;
drop table if exists stock;
-- 库存
create table stock(
id int not null primary key auto_increment,
item_id varchar(3) not null unique key,
name varchar(20) not null,
stocks int default 0);
-- 上架商品
create table items(
id int not null primary key auto_increment,
item_id varchar(3) not null,
count int default 0,
key key1 (item_id),
foreign key (item_id) references stock(item_id));
insert into stock values(default, '101', 'banana', 20),
(default, '102', 'apple', 20),
(default, '103', 'orange', 20);
insert into items values(default, '101', 3),
(default, '102', 3),
(default, '103', 3);
比如,现在需要实现一个场景。
items 表表示货架上的货物的情况,如果货架上的物品数量为0时,应该从stock 表取出对应的商品添加到货架上。
有两个重要点,1-在items 数量为0时,从仓库取货,但是对items表的增删改都会触发触发器,所以代码中会有判断语句。2-当items 数量为0时从 stock -5,items +5.。。。
触发器代码:
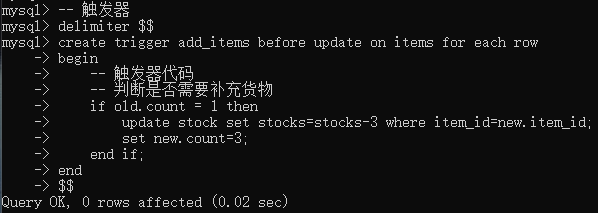
代码也有一定的BUG,如库存=0后,在添加会为负数,这里忽略这些BUG。。。
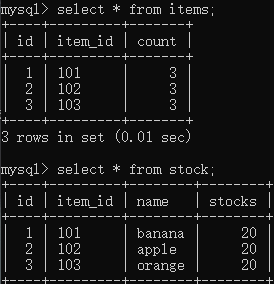
测试:
测试前数据:
购买商品:
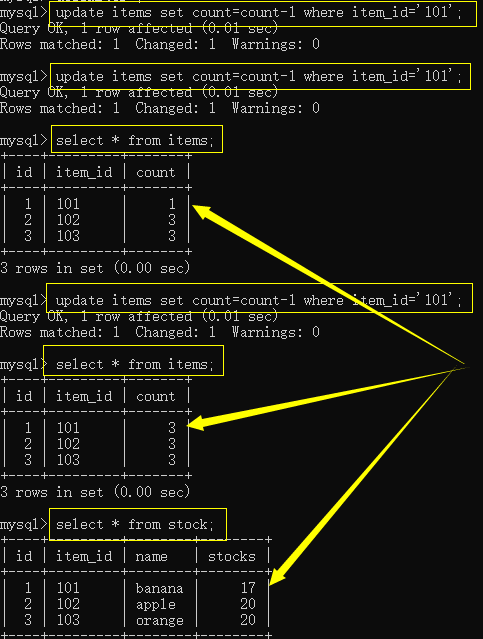
4. 分支结构和函数
if 分支
if 判断条件 then
满足条件的执行代码
else
不满足条件的执行代码
end if;
while 循环结构(其他循环请百度)
循环名:while 条件 do
满足条件的执行代码
if 条件
leave 循环名(相当于break) 或者 iterator 循环名(相当于continue)
end if
end while;
系统函数(只举例很少一部分):
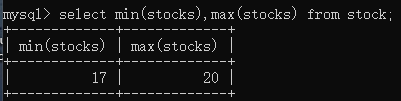
数学函数:
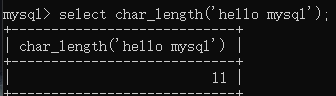
字符串函数:
自定义函数:
语法
delimiter $$
create function 函数名[(参数列表)] returns 返回类型
begin
代码
end
$$
delimiter ;
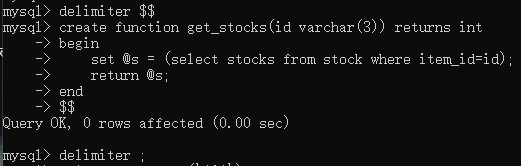
创建函数:
查询库存容量
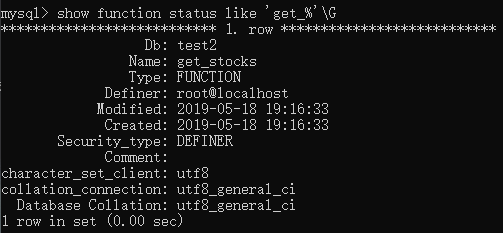
查看函数信息:
使用函数:
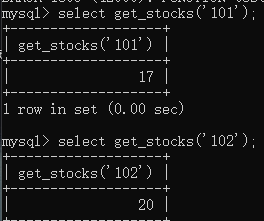
5. 存储过程
语法
delimiter $$
create procedure 过程名称([参数列表])
begin
代码
end
$$
delimiter ;
存储过程的参数有三种类型(这里不能理解的,百度下说明更详细的):
- in:数据从外部传入给内部使用,可以是值,也可以是变量。内部的改变,外部不可见。
- out:传入变量,清空原有的值。内部的改变,外部可见。
- inout:传入变量,不会清空原有的值。内部的改变,外部可见。
测试:
创建存储过程:
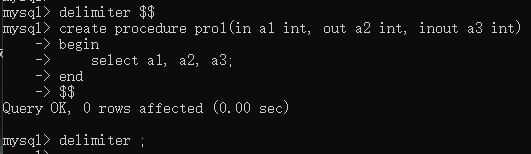
调用:
没有定义变量
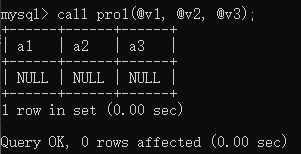
定义变量:
满足 out 类型会清空传进来变量的值
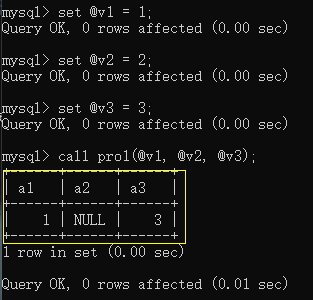
现在在存储过程中修改传进来变量的值,看外部有没有变化:
新的存储过程:
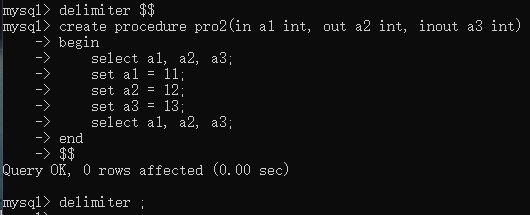
运行存储过程pro2:
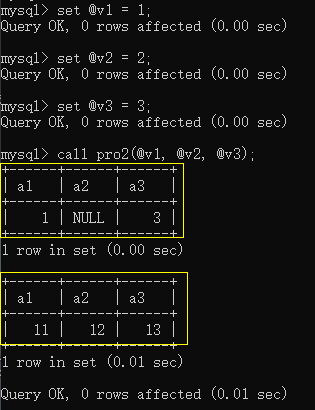
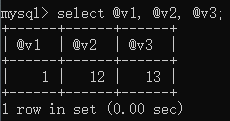
查看外部变量:
代码
# 1. 事务
use test2;
create table account(
id int not null primary key auto_increment,
u_id varchar(3) not null unique key,
name varchar(20) not null,
money int default 0);
insert into account values(default, '100', 'tom', 1000),
(default, '101', 'jack', 2000);
start transaction;
savepoint initial_state;
update account set money=money-500 where u_id='101';
update account set money=money+500 where u_id='100';
select * from account;
update account set name='tomm' where name='tom';
commit;
start transaction;
savepoint initial_state;
update account set money=money-500 where u_id='101';
update account set money=money+500 where u_id='100';
select * from account;
rollback to initial_state;
show variables like '%autocommit%';
############################################################################
# 2. 变量
set @v1 = 'hello';
select @v1=name from account where u_id='100';
select @v1:=name from account where u_id='100';
select @1;
select @v1:=name from account;
############################################################################
# 3. 触发器
use test2;
drop table if exists items;
drop table if exists stock;
-- 库存
create table stock(
id int not null primary key auto_increment,
item_id varchar(3) not null unique key,
name varchar(20) not null,
stocks int default 0);
-- 上架商品
create table items(
id int not null primary key auto_increment,
item_id varchar(3) not null,
count int default 0,
key key1 (item_id),
foreign key (item_id) references stock(item_id));
insert into stock values(default, '101', 'banana', 20),
(default, '102', 'apple', 20),
(default, '103', 'orange', 20);
insert into items values(default, '101', 3),
(default, '102', 3),
(default, '103', 3);
drop trigger if exists add_items;
-- 触发器
delimiter $$
create trigger add_items before update on items for each row
begin
-- 触发器代码
-- 判断是否需要补充货物
if old.count = 1 then
update stock set stocks=stocks-3 where item_id=new.item_id;
set new.count=3;
end if;
end
$$
delimiter ;
update items set count=count-1 where item_id='101';
select * from items;
select * from stock;
############################################################################
# 4. 分支结构函数
if 分支
if 判断条件 then
满足条件的执行代码
else
不满足条件的执行代码
end if;
while 循环结构(其他循环请百度)
循环名:while 条件 do
满足条件的执行代码
if 条件
leave 循环名(相当于break) 或者 iterator 循环名(相当于continue)
end if
end while;
select min(stocks),max(stocks) from stock;
select char_length('hello mysql');
语法
create function 函数名[(参数列表)] returns 返回类型
begin
代码
end
drop function if exists get_stocks;
delimiter $$
create function get_stocks(id varchar(3)) returns int
begin
set @s = (select stocks from stock where item_id=id);
return @s;
end
$$
delimiter ;
show function status like 'get_%'G
select get_stocks('101');
############################################################################
# 5. 存储过程
语法
delimiter $$
create procedure 过程名称([参数列表])
begin
代码
end
$$
delimiter ;
delimiter $$
create procedure pro1(in a1 int, out a2 int, inout a3 int)
begin
select a1, a2, a3;
end
$$
delimiter ;
call pro1(@v1, @v2, @v3);
set @v1 = 1;
set @v2 = 2;
set @v3 = 3;
delimiter $$
create procedure pro2(in a1 int, out a2 int, inout a3 int)
begin
select a1, a2, a3;
set a1 = 11;
set a2 = 12;
set a3 = 13;
select a1, a2, a3;
end
$$
delimiter ;
set @v1 = 1;
set @v2 = 2;
set @v3 = 3;
call pro2(@v1, @v2, @v3);
select @v1, @v2, @v3;
完!
最后
以上就是糊涂蚂蚁最近收集整理的关于MySQL深入--事务、变量、触发器、分支结构函数和存储过程的全部内容,更多相关MySQL深入--事务、变量、触发器、分支结构函数和存储过程内容请搜索靠谱客的其他文章。








发表评论 取消回复